散列表---算法导论第十一章 Hash Tables
2015-06-07 15:32
573 查看
一、散列表概念
1、 直接寻址表
直接将关键字作为数组下标。复杂度O(1)
2、 散列表
k->h(k)
降低了空间开销,会产生碰撞,解决碰撞的简单方法是链接法。
对链接法散列,平均情况下,复杂度也是O(1)
3、 散列函数
1) 除法散列法
h(k)=k mod m,m最好选取与2的整数幂不太接近的质数
2) 乘法散列法
h(k)=[m(kA mod 1)], A为一个常数(0 < A < 1)。
乘法方法的优点是对m的选择没有什么特别的要求,一般选择它为2的某个幂次。
3) 全域散列(universal hashing)
在执行开始时,从一族仔细设计的函数中,随机地选择一个作为散列函数。这里的随机选择针对的是一次对散列表的应用,而不是一次简单的插入或查找操作。散列函数的确定性,是查找操作正确执行的保证。全域散列法确保,当k!=l时,两者发生碰撞的概率不大于1/m。设计一个全域散列函数类的方法如下,该方法中,散列表大小m的大小是任意的。
4、 完全散列
一种两级的散列方案
每一级上都采用全域散列。
第一级将n个关键字散列到m个槽中,每个槽j中有一个较小的二次散列表Sj。通过仔细的选择第二级散列函数,可以确保在第二级上不出现碰撞。
期望使用的总体存储空间为O(n)
二、散列函数构造方法
1、散列函数的选择有两条标准:简单和均匀。
简单指散列函数的计算简单快速;均匀指对于关键字集合中的任一关键字,散列函数能以等概率将其映射到表空间的任何一个位置上。也就是说,散列函数能将子集K随机均匀地分布在表的地址集{0,1,…,m-1}上,以使冲突最小化。
2、常用散列函数
为简单起见,假定关键字是定义在自然数集合上。其它关键字可以转换到自然数集合上。
(1)平方取中法
具体方法:先通过求关键字的平方值扩大相近数的差别,然后根据表长度取中间的几位数作为散列函数值。又因为一个乘积的中间几位数和乘数的每一位都相关,所以由此产生的散列地址较为均匀。
【例】将一组关键字(0100,0110,1010,1001,0111)平方后得 (0010000,0012100,1020100,1002001,0012321) ,若取表长为1000,则可取中间的三位数作为散列地址集:(100,121,201,020,123)。
相应的散列函数用C实现很简单:
int Hash(int key){ //假设key是4位整数
key *= key; key /= 100; //先求平方值,后去掉末尾的两位数
return key%1000; //取中间三位数作为散列地址返回
}
(2)除余法
该方法是最为简单常用的一种方法。它是以表长m来除关键字,取其余数作为散列地址,即 h(key)=key%m。该方法的关键是选取m。选取的m应使得散列函数值尽可能与关键字的各位相关。m最好为素数。
【例】若选m是关键字的基数的幂次,则就等于是选择关键字的最后若干位数字作为地址,而与高位无关。于是高位不同而低位相同的关键字均互为同义词。
【例】若关键字是十进制整数,其基为10,则当m=100时,159,259,359,…,等均互为同义词。
(3)相乘取整法
。。。
三 、解决冲突方法
通常有两类方法处理冲突:开放寻址(Open Addressing)法和链接(Chaining)法。前者是将所有结点均存放在散列表T[0..m-1]中;后者通常是将互为同义词的结点链成一个单链表,而将此链表的头指针放在散列表T[0..m-1]中。
1、 开放寻址法
开放寻址法指所有的元素都存放在散列表里。
在开放寻址法里,当要插入一个元素时,可以连续地检查散列表的各项,直到遇到一个空槽存放待插入的关键字。对每一个关键字k,探查序列 < h(k,0),h(k,1),…h(k,m-1) > 必须是< 0,1,..,m-1 >的一个排列。
伪代码
伪代码
按照形成探查序列的方法不同,可将开放寻址法区分为线性探查法、二次探查法、双重散列法等。
1) 线性探查Linear Probing
h(k,i)=(h’(k)+i) mod m, i=0,1,…,m-1
初始探查位置确定了整个序列,只有m种不同的探查序列。
该方法的基本思想是:将散列表T[0..m-1]看成是一个循环向量,若初始探查的地址为d(即h(key)=d),则最长的探查序列为:d,d+l,d+2,…,m-1,0,1,…,d-1 .即:探查时从地址d开始,首先探查T[d],然后依次探查T[d+1],…,直到T[m-1],此后又循环到T[0],T[1],…,直到探查到T[d-1]为止。探查过程终止于三种情况:
(1)若当前探查的单元为空,则表示查找失败(若是插入则将key写入其中);
(2)若当前探查的单元中含有key,则查找成功,但对于插入意味着失败;
(3)若探查到T[d-1]时仍未发现空单元也未找到key,则无论是查找还是插入均意味着失败(此时表满)。
存在问题,一次群集,即随着时间的推移,连续被占用的槽不断增加,平均查找时间也随着不断增加。
【例9.1】已知一组关键字为(26,36,41,38,44,15,68,12,06,51),用除余法构造散列函数,用线性探查法解决冲突构造这组关键字的散列表。
解答:为了减少冲突,通常令装填因子α < l。这里关键字个数n=10,不妨取m=13,此时α≈0.77,散列表为T[0..12],散列函数为:h(key)=key%13。由除余法的散列函数计算出的上述关键字序列的散列地址为(0,10,2,12,5,2,3,12,6,12)。前5个关键字插入时,其相应的地址均为开放地址,故将它们直接插入T[0],T[10),T[2],T[12]和T[5]中。当插入第6个关键字15时,其散列地址2(即h(15)=15%13=2)已被关键字41(15和41互为同义词)占用。故探查h1=(2+1)%13=3,此地址开放,所以将15放入T[3]中。当插入第7个关键字68时,其散列地址3已被非同义词15先占用,故将其插入到T[4]中。当插入第8个关键字12时,散列地址12已被同义词38占用,故探查hl=(12+1)%13=0,而T[0]亦被26占用,再探查h2=(12+2)%13=1,此地址开放,可将12插入其中。类似地,第9个关键字06直接插入T[6]中;而最后一个关键字51插人时,因探查的地址12,0,1,…,6均非空,故51插入T[7]中。
用线性探查法解决冲突时,当表中i,i+1,…,i+k的位置上已有结点时,一个散列地址为i,i+1,…,i+k+1的结点都将插入在位置i+k+1上。把这种散列地址不同的结点争夺同一个后继散列地址的现象称为聚集或堆积(Clustering)。这将造成不是同义词的结点也处在同一个探查序列之中,从而增加了探查序列的长度,即增加了查找时间。若散列函数不好或装填因子过大,都会使堆积现象加剧。
【例】上例中,h(15)=2,h(68)=3,即15和68不是同义词。但由于处理15和同义词41的冲突时,15抢先占用了T[3],这就使得插入68时,这两个本来不应该发生冲突的非同义词之间也会发生冲突。
为了减少堆积的发生,不能像线性探查法那样探查一个顺序的地址序列(相当于顺序查找),而应使探查序列跳跃式地散列在整个散列表中。
2) 二次探查Quadratic Probing
该方法是开放定址法中最好的方法之一,它的探查序列是
h(k,i)=(h’(k)+a*i+b*i^2) mod m
初始探查位置确定了整个序列,只有m种不同的探查序列。
存在问题,程度较轻的群集现象,二次群集
3) 双重散列Double Hashing
该方法是开放定址法中最好的方法之一,它的探查序列是:
h(k,i)=(h1(k)+i*h2(k)) mod m
为能查找整个散列表,h2(k)要与表的大小m互质。
【例】若m为素数,则h2(key)取1到m-1之间的任何数均与m互素,因此,我们可以简单地将它定义为:h2(key)=key%(m-2)+1
【例】对例9.1,我们可取h1(key)=key%13,而h2(key)=key%11+1。
【例】若m是2的方幂,则h2(key)可取1到m-1之间的任何奇数。
用了O(m^2)种探查序列
2、链接法
(1)链接法解决冲突的方法
链接法解决冲突的做法是:将所有关键字为同义词的结点链接在同一个单链表中。若选定的散列表长度为m,则可将散列表定义为一个由m个头指针组成的指针数组T[0..m-1]。凡是散列地址为i的结点,均插入到以T[i]为头指针的单链表中。T中各分量的初值均应为空指针。在链接法中,装填因子α可以大于1,但一般均取α≤1。
链接法示意图:
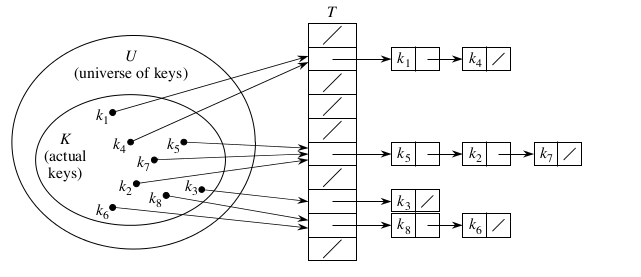
【例9.2】已知一组关键字和选定的散列函数和例9.1相同,用链接法解决冲突构造这组关键字的散列表。
解答:不妨和例9.1类似,取表长为13,故散列函数为h(key)=key%13,散列表为T[0..12]。 注意:当把h(key)=i的关键字插入第i个单链表时,既可插入在链表的头上,也可以插在链表的尾上。这是因为必须确定key不在第i个链表时,才能将它插入表中,所以也就知道链尾结点的地址。
(2)链接法的优点
与开放定址法相比,链接法有如下几个优点:(1)链接法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;(2)由于链接法中各链表上的结点空间是动态申请的,故它更适合于造表前无法确定表长的情况;(3)开放定址法为减少冲突,要求装填因子α较小,故当结点规模较大时会浪费很多空间。而链接法中可取α≥1,且结点较大时,链接法中增加的指针域可忽略不计,因此节省空间;(4)在用链接法构造的散列表中,删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。而对开放地址法构造的散列表,删除结点不能简单地将被删结点的空间置为空,否则将截断在它之后填人散列表的同义词结点的查找路径。这是因为各种开放地址法中,空地址单元(即开放地址)都是查找失败的条件。因此在用开放地址法处理冲突的散列表上执行删除操作,只能在被删结点上做删除标记,而不能真正删除结点。
(3)链接法的缺点
链接法的缺点是:指针需要额外的空间,故当结点规模较小时,开放定址法较为节省空间,而若将节省的指针空间用来扩大散列表的规模,可使装填因子变小,这又减少了开放定址法中的冲突,从而提高平均查找速度。
参考:http://www.cnblogs.com/zhanglanyun/archive/2011/09/01/2161729.html
1、 直接寻址表
直接将关键字作为数组下标。复杂度O(1)
2、 散列表
k->h(k)
降低了空间开销,会产生碰撞,解决碰撞的简单方法是链接法。
对链接法散列,平均情况下,复杂度也是O(1)
3、 散列函数
1) 除法散列法
h(k)=k mod m,m最好选取与2的整数幂不太接近的质数
2) 乘法散列法
h(k)=[m(kA mod 1)], A为一个常数(0 < A < 1)。
乘法方法的优点是对m的选择没有什么特别的要求,一般选择它为2的某个幂次。
3) 全域散列(universal hashing)
在执行开始时,从一族仔细设计的函数中,随机地选择一个作为散列函数。这里的随机选择针对的是一次对散列表的应用,而不是一次简单的插入或查找操作。散列函数的确定性,是查找操作正确执行的保证。全域散列法确保,当k!=l时,两者发生碰撞的概率不大于1/m。设计一个全域散列函数类的方法如下,该方法中,散列表大小m的大小是任意的。
选择一个足够大的质数p,使得每一个可能的关键字都落在0到p-1的范围内。设Zp表示集合{0,
1, …, p-1},Zp*表示集合{1, 2, …, p-1}。假定关键字全域的大小大于散列表中的槽
数,故有p>m。对于任何a∈Zp*和任何b∈Zp,定义散列函数ha,b(k):
ha,b(k) = ((ak+b) mod p) mod m
所有这样的散列函数构成的函数族为:
Hp,m = {ha,b : a∈Zp*和b∈Zp}
每一个散列函数ha,b都将Zp映射到Zm。由于对a来说有p-1种选择,对于b来说有p种选择,因
而,Hp,m中共有p(p-1)个散列函数。
在一次散列表应用中,a、b是随机生成的在一定范围的数。举个例子:若p=17,m=6,此次散列
应用中随机生成a=3,b=4.则h3,4(8)=54、 完全散列
一种两级的散列方案
每一级上都采用全域散列。
第一级将n个关键字散列到m个槽中,每个槽j中有一个较小的二次散列表Sj。通过仔细的选择第二级散列函数,可以确保在第二级上不出现碰撞。
期望使用的总体存储空间为O(n)
二、散列函数构造方法
1、散列函数的选择有两条标准:简单和均匀。
简单指散列函数的计算简单快速;均匀指对于关键字集合中的任一关键字,散列函数能以等概率将其映射到表空间的任何一个位置上。也就是说,散列函数能将子集K随机均匀地分布在表的地址集{0,1,…,m-1}上,以使冲突最小化。
2、常用散列函数
为简单起见,假定关键字是定义在自然数集合上。其它关键字可以转换到自然数集合上。
(1)平方取中法
具体方法:先通过求关键字的平方值扩大相近数的差别,然后根据表长度取中间的几位数作为散列函数值。又因为一个乘积的中间几位数和乘数的每一位都相关,所以由此产生的散列地址较为均匀。
【例】将一组关键字(0100,0110,1010,1001,0111)平方后得 (0010000,0012100,1020100,1002001,0012321) ,若取表长为1000,则可取中间的三位数作为散列地址集:(100,121,201,020,123)。
相应的散列函数用C实现很简单:
int Hash(int key){ //假设key是4位整数
key *= key; key /= 100; //先求平方值,后去掉末尾的两位数
return key%1000; //取中间三位数作为散列地址返回
}
(2)除余法
该方法是最为简单常用的一种方法。它是以表长m来除关键字,取其余数作为散列地址,即 h(key)=key%m。该方法的关键是选取m。选取的m应使得散列函数值尽可能与关键字的各位相关。m最好为素数。
【例】若选m是关键字的基数的幂次,则就等于是选择关键字的最后若干位数字作为地址,而与高位无关。于是高位不同而低位相同的关键字均互为同义词。
【例】若关键字是十进制整数,其基为10,则当m=100时,159,259,359,…,等均互为同义词。
(3)相乘取整法
。。。
三 、解决冲突方法
通常有两类方法处理冲突:开放寻址(Open Addressing)法和链接(Chaining)法。前者是将所有结点均存放在散列表T[0..m-1]中;后者通常是将互为同义词的结点链成一个单链表,而将此链表的头指针放在散列表T[0..m-1]中。
1、 开放寻址法
开放寻址法指所有的元素都存放在散列表里。
在开放寻址法里,当要插入一个元素时,可以连续地检查散列表的各项,直到遇到一个空槽存放待插入的关键字。对每一个关键字k,探查序列 < h(k,0),h(k,1),…h(k,m-1) > 必须是< 0,1,..,m-1 >的一个排列。
伪代码
HASH-INSERT(T,k) i <- 0 repeat j <- h(k,i) if T[j] = NIL then T[j] <- k return j else i <- i+1 until i=m error “hash table overflow”
伪代码
HASH-SEARCH(T,k) i <- 0 repeat j <- h(k,i) if T[j] = k then return j i <- i+1 until i =m or T[j]=NIL return NIL
按照形成探查序列的方法不同,可将开放寻址法区分为线性探查法、二次探查法、双重散列法等。
1) 线性探查Linear Probing
h(k,i)=(h’(k)+i) mod m, i=0,1,…,m-1
初始探查位置确定了整个序列,只有m种不同的探查序列。
该方法的基本思想是:将散列表T[0..m-1]看成是一个循环向量,若初始探查的地址为d(即h(key)=d),则最长的探查序列为:d,d+l,d+2,…,m-1,0,1,…,d-1 .即:探查时从地址d开始,首先探查T[d],然后依次探查T[d+1],…,直到T[m-1],此后又循环到T[0],T[1],…,直到探查到T[d-1]为止。探查过程终止于三种情况:
(1)若当前探查的单元为空,则表示查找失败(若是插入则将key写入其中);
(2)若当前探查的单元中含有key,则查找成功,但对于插入意味着失败;
(3)若探查到T[d-1]时仍未发现空单元也未找到key,则无论是查找还是插入均意味着失败(此时表满)。
存在问题,一次群集,即随着时间的推移,连续被占用的槽不断增加,平均查找时间也随着不断增加。
【例9.1】已知一组关键字为(26,36,41,38,44,15,68,12,06,51),用除余法构造散列函数,用线性探查法解决冲突构造这组关键字的散列表。
解答:为了减少冲突,通常令装填因子α < l。这里关键字个数n=10,不妨取m=13,此时α≈0.77,散列表为T[0..12],散列函数为:h(key)=key%13。由除余法的散列函数计算出的上述关键字序列的散列地址为(0,10,2,12,5,2,3,12,6,12)。前5个关键字插入时,其相应的地址均为开放地址,故将它们直接插入T[0],T[10),T[2],T[12]和T[5]中。当插入第6个关键字15时,其散列地址2(即h(15)=15%13=2)已被关键字41(15和41互为同义词)占用。故探查h1=(2+1)%13=3,此地址开放,所以将15放入T[3]中。当插入第7个关键字68时,其散列地址3已被非同义词15先占用,故将其插入到T[4]中。当插入第8个关键字12时,散列地址12已被同义词38占用,故探查hl=(12+1)%13=0,而T[0]亦被26占用,再探查h2=(12+2)%13=1,此地址开放,可将12插入其中。类似地,第9个关键字06直接插入T[6]中;而最后一个关键字51插人时,因探查的地址12,0,1,…,6均非空,故51插入T[7]中。
用线性探查法解决冲突时,当表中i,i+1,…,i+k的位置上已有结点时,一个散列地址为i,i+1,…,i+k+1的结点都将插入在位置i+k+1上。把这种散列地址不同的结点争夺同一个后继散列地址的现象称为聚集或堆积(Clustering)。这将造成不是同义词的结点也处在同一个探查序列之中,从而增加了探查序列的长度,即增加了查找时间。若散列函数不好或装填因子过大,都会使堆积现象加剧。
【例】上例中,h(15)=2,h(68)=3,即15和68不是同义词。但由于处理15和同义词41的冲突时,15抢先占用了T[3],这就使得插入68时,这两个本来不应该发生冲突的非同义词之间也会发生冲突。
为了减少堆积的发生,不能像线性探查法那样探查一个顺序的地址序列(相当于顺序查找),而应使探查序列跳跃式地散列在整个散列表中。
2) 二次探查Quadratic Probing
该方法是开放定址法中最好的方法之一,它的探查序列是
h(k,i)=(h’(k)+a*i+b*i^2) mod m
初始探查位置确定了整个序列,只有m种不同的探查序列。
存在问题,程度较轻的群集现象,二次群集
3) 双重散列Double Hashing
该方法是开放定址法中最好的方法之一,它的探查序列是:
h(k,i)=(h1(k)+i*h2(k)) mod m
为能查找整个散列表,h2(k)要与表的大小m互质。
【例】若m为素数,则h2(key)取1到m-1之间的任何数均与m互素,因此,我们可以简单地将它定义为:h2(key)=key%(m-2)+1
【例】对例9.1,我们可取h1(key)=key%13,而h2(key)=key%11+1。
【例】若m是2的方幂,则h2(key)可取1到m-1之间的任何奇数。
用了O(m^2)种探查序列
2、链接法
(1)链接法解决冲突的方法
链接法解决冲突的做法是:将所有关键字为同义词的结点链接在同一个单链表中。若选定的散列表长度为m,则可将散列表定义为一个由m个头指针组成的指针数组T[0..m-1]。凡是散列地址为i的结点,均插入到以T[i]为头指针的单链表中。T中各分量的初值均应为空指针。在链接法中,装填因子α可以大于1,但一般均取α≤1。
链接法示意图:
【例9.2】已知一组关键字和选定的散列函数和例9.1相同,用链接法解决冲突构造这组关键字的散列表。
解答:不妨和例9.1类似,取表长为13,故散列函数为h(key)=key%13,散列表为T[0..12]。 注意:当把h(key)=i的关键字插入第i个单链表时,既可插入在链表的头上,也可以插在链表的尾上。这是因为必须确定key不在第i个链表时,才能将它插入表中,所以也就知道链尾结点的地址。
(2)链接法的优点
与开放定址法相比,链接法有如下几个优点:(1)链接法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;(2)由于链接法中各链表上的结点空间是动态申请的,故它更适合于造表前无法确定表长的情况;(3)开放定址法为减少冲突,要求装填因子α较小,故当结点规模较大时会浪费很多空间。而链接法中可取α≥1,且结点较大时,链接法中增加的指针域可忽略不计,因此节省空间;(4)在用链接法构造的散列表中,删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。而对开放地址法构造的散列表,删除结点不能简单地将被删结点的空间置为空,否则将截断在它之后填人散列表的同义词结点的查找路径。这是因为各种开放地址法中,空地址单元(即开放地址)都是查找失败的条件。因此在用开放地址法处理冲突的散列表上执行删除操作,只能在被删结点上做删除标记,而不能真正删除结点。
(3)链接法的缺点
链接法的缺点是:指针需要额外的空间,故当结点规模较小时,开放定址法较为节省空间,而若将节省的指针空间用来扩大散列表的规模,可使装填因子变小,这又减少了开放定址法中的冲突,从而提高平均查找速度。
参考:http://www.cnblogs.com/zhanglanyun/archive/2011/09/01/2161729.html

相关文章推荐
- c语言实现hashmap(转载)
- Ruby中Hash的11个问题解答
- Ruby简明教程之数组和Hash介绍
- 在C#中生成与PHP一样的MD5 Hash Code的方法
- js中hash和ico的关联分析
- Javascript SHA-1:Secure Hash Algorithm
- mysql下普通用户备份数据库时无lock tables权限的解决方法
- 理解php Hash函数,增强密码安全
- PHP利用hash冲突漏洞进行DDoS攻击的方法分析
- PowerShell中定义哈希散列(Hash)和调用例子
- php操作redis中的hash和zset类型数据的方法和代码例子
- Perl 哈希Hash用法之入门教程
- perl哈希hash的常见用法介绍
- php自定义hash函数实例
- php对文件进行hash运算的方法
- php常用hash加密函数
- PHP Hash算法:Times33算法代码实例
- php的hash算法介绍
- memcache一致性hash的php实现方法
- Mysql中的Btree与Hash索引比较