python学习笔记之――函数模块
2015-05-30 23:25
489 查看
1、函数参数说明:
def login(name,info,passwd = '123456')
函数参数可以有默认值,调用函数时:
1、如果只传二个参数,则有默认值的一定要放到最后;
def login(name,passwd = '123456',info='welcome to you')
2、如果传二个参数,一定要指明形参;
login(user)
login(user,passwd)
login(user,info='欢迎')
login(user,info='欢迎',passwd='123456')
def login(*arg) 函数参数个数不定,传参数的时候可以多个,包装为列表;例:
def list_show(*args):
for name in args:
print(name)
list_show('a','b','c','d',1,2,3,4) #传多个参数
list_show(['a','b','c',1,2,3]) #直接传个列表参数
def login(**arg) 函数参数个数不定,传参数的时候可以多个,包装为字典;例:
def dict_show(**args):
for name in args.items():
print(name)
dict_show(name='kevin',age=23) #传多个参数时,格式为key=value
print('##################')
dict = {'name':'kevin','age':23}
dict_show(**dict) #直接传个字典参数时,字典前加二个**
2、生成器yield:
seek = 0
while True:
with open('D:/eclipse/workspace/python27/first_python27/file/file.txt','r') as f: #with打开文件无需使用close来结束读取文件
f.seek(seek)
data = f.readline()
if data:
seek = f.tell()
yield data
else:
return #直接返回,退出函数
for line in kevin_readlines():
print(line)yeild生成器需要用循环来一行一行读取。yeild经常用于读取函数的中间值,适合用于多线程之类的情况。使用next来一次一次调用函数值。
3、函数介绍:
★ lamba
python lambda是在python中使用lambda来创建匿名函数,而用def创建的方法是有名称的,除了从表面上的方法名不一样外,python lambda还有哪些和def不一样呢?
1 python lambda会创建一个函数对象,但不会把这个函数对象赋给一个标识符,而def则会把函数对象赋值给一个变量。
2 python lambda它只是一个表达式,而def则是一个语句。
lambda语句中,冒号前是参数,可以有多个,用逗号隔开,冒号右边的返回值。lambda语句构建的其实是一个函数对象。
例:
m = lambda x,y,z: (x-y)*z
print m(234,122,5)
也经常用于生成列表,例:
list = [i ** i for i in range(10)]
print(list)
list_lambda = map(lambda x:x**x,range(10))
print(list_lambda)
★ enumerate(iterable,[start]) iterable为一个可迭代的对象;
enumerate(iterable[, start]) -> iterator for index, value of iterable Return an enumerate object. iterable must be another object that supports iteration. The enumerate object yields pairs containing a count (from start, which defaults to zero) and a value yielded by the iterable
argument. enumerate is useful for obtaining an indexed list: (0, seq[0]), (1, seq[1]), (2, seq[2]), ...
例:
for k,v in enumerate(['a','b','c',1,2,3],10):
print k,v
★S.format(*args, **kwargs) -> string 字符串的格式输出,类似于格式化输出%s
Return a formatted version of S, using substitutions from args and kwargs.
The substitutions are identified by braces ('{' and '}').
s = 'i am {0},{1}'
print(s.format('wang',1))
★map(function,sequence) 将squence每一项做为参数传给函数,并返回值
例:
def add(arg):
return arg + 101
print(map(add,[12,23,34,56]))
★filter(function or None, sequence) -> list, tuple, or string 返还true的序列
Return those items of sequence for which function(item) is true. If
function is None, return the items that are true. If sequence is a tuple
or string, return the same type, else return a list.
例:
def comp(arg):
if arg < 8:
return True
else:
return False
print(filter(comp,[1,19,21,8,5]))
print(filter(lambda x:x % 2,[1,19,20,8,5]))
print(filter(lambda x:x % 2,(1,19,20,8,5)))
print(filter(lambda x:x > 'a','AbcdE'))
★reduce(function, sequence[, initial]) -> value 对二个参数进行计算
Apply a function of two arguments cumulatively to the items of a sequence,
from left to right, so as to reduce the sequence to a single value.For example, reduce(lambda x, y: x+y, [1, 2, 3, 4, 5]) calculates((((1+2)+3)+4)+5). If initial is present, it is placed before the
items of the sequence in the calculation, and serves as a default when the sequence is empty.
例:
print(reduce(lambda x,y:x*y,[22,11,8]))
print(reduce(lambda x,y:x*y,[3],10))
print(reduce(lambda x,y:x*y,[],5))
★zip(seq1 [, seq2 [...]]) -> [(seq1[0], seq2[0] ...), (...)] 将多个序列转化为新元祖的序列
Return a list of tuples, where each tuple contains the i-th element from each of the argument sequences. The returned list is truncated in length to the length of the shortest argument sequence.
例:
a = [1,2,3,4,5,6]
b = [11,22,33,44,55]
c = [111,222,333,444]
print(zip(a,b,c))
★eval(source[, globals[, locals]]) -> value 将表达式字符串执行为值,其中globals为全局命名空间,locals为局部命名空间,从指字的命名空间中执行表达式,
Evaluate the source in the context of globals and locals. The source may be a string representing a Python expression or a code object as returned by compile(). The globals must be a dictionary and locals can be any mapping, defaulting to the current globals and locals. If only globals is given, locals defaults to it.
例:
a = '8*(8+20-5%12*23'
print(eval(a))
d = {'a':5,'b':4}
print(eval('a*b',d))
★exec(source[, globals[, locals]]) 语句用来执行储存在字符串或文件中的Python语句
例:
a = 'print("nihao")'
b = 'for i in range(10): print i'
exec(a)
exec(b)
★execfile(filename[, globals[, locals]])
Read and execute a Python script from a file.The globals and locals are dictionaries, defaulting to the currentglobals and locals. If only globals is given, locals defaults to it.
4、常用模块:★random 生成随机数
print random.random() 生成0-1之间的小数
print random.randint(1,3) 生成整数,包含endpoint
print random.randrange(1,3,2) 生成整数,不包含endpoint
randrange(self, start, stop=None, step=?)
生成5位随机数,例:
import random
a = []
for i in range(5):
if i == random.randint(1,5):
a.append(str(i))
else:
a.append(chr(random.randint(65,90)))
else:
print(''.join(a))
★生成MD5码
例:
一. 使用md5包
import md5
src = 'this is a md5 test.'
m1 = md5.new()
m1.update(src)
print m1.hexdigest()
二. 使用hashlib
import hashlib
hash = hashlib.md5()
hash.update('this is a md5 test.')
hash.update('admin')
print(hash.digest())
print(hash.hexdigest())
推荐使用第二种方法。
对以上代码的说明:
1.首先从python直接导入hashlib模块
2.调用hashlib里的md5()生成一个md5 hash对象
3.生成hash对象后,就可以用update方法对字符串进行md5加密的更新处理
4.继续调用update方法会在前面加密的基础上更新加密
5.加密后的二进制结果
6.十六进制结果
如果只需对一条字符串进行加密处理,也可以用一条语句的方式:
print(hashlib.new("md5", "Nobody inspects the spammish repetition").hexdigest())
5、python对象与文件之间的序列化和反序列化(pickle和json)
★pickle模块用来实现python对象的序列化和反序列化。通常地pickle将python对象序列化为二进制流或文件。
python对象与文件之间的序列化和反序列化:
pickle.dump()
pickle.load()
如果要实现python对象和字符串间的序列化和反序列化,则使用:
pickle.dumps()
pickle.loads()
可以被序列化的类型有:
* None,True 和 False;
* 整数,浮点数,复数;
* 字符串,字节流,字节数组;
* 包含可pickle对象的tuples,lists,sets和dictionaries;
* 定义在module顶层的函数:
* 定义在module顶层的内置函数;
* 定义在module顶层的类;
* 拥有__dict__()或__setstate__()的自定义类型;
注意:对于函数或类的序列化是以名字来识别的,所以需要import相应的module。
例:
import pickle
data = {
'a': [1, 2.0, 3, 4+6j],
'b': ("character string", "byte string"),
'c': set([None, True, False])
}
du = pickle.dumps(data)
print(pickle.loads(du))
print(du)
with open('data.pickle', 'wb') as f:
pickle.dump(data, f)
with open('data.pickle', 'rb') as f:
data = pickle.load(f)
print(str(data))
★JSON(JavaScript Object Notation):一种轻量级数据交换格式,相对于XML而言更简单,也易于阅读和编写,机器也方便解析和生成,Json是JavaScript中的一个子集。
Python的Json模块序列化与反序列化的过程分别是 encoding和 decoding
encoding:把一个Python对象编码转换成Json字符串
decoding:把Json格式字符串解码转换成Python对象
具体的转化对照如下:
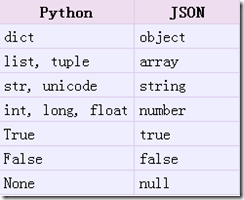
loads方法返回了原始的对象,但是仍然发生了一些数据类型的转化。比如,上例中‘abc’转化为了unicode类型。从json到python的类型转化对照如下:
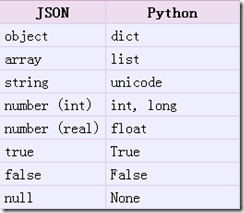
例:
import json
data = { 'a': [1, 2.0, 3, 4], 'b': ("character string", "byte string"), 'c': 'abc'}
du = json.dumps(data)
print(du)
print(json.loads(du,encoding='ASCII'))
with open('data.json','wb') as f:
json.dump(data,f)
with open('data.json','rb') as f:
data = json.load(f)
print(repr(data))
经测试,2.7版本导出的json文件,3.4版本导入会报错:TypeError: the JSON object must be str, not 'bytes'
6、正则表达式模块
★re.match的函数原型为:re.match(pattern, string, flags)
第一个参数是正则表达式,这里为"(\w+)\s",如果匹配成功,则返回一个Match,否则返回一个None;第二个参数表示要匹配的字符串;第三个参数是标致位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
★re.search的函数原型为: re.search(pattern, string, flags)
每个参数的含意与re.match一样。 re.match与re.search的区别:re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
★re.findall可以获取字符串中所有匹配的字符串。如:re.findall(r'\w*oo\w*', text);获取字符串中,包含'oo'的所有单词。
★re.sub的函数原型为:re.sub(pattern, repl, string, count)
其中第二个函数是替换后的字符串;本例中为'-'第四个参数指替换个数。默认为0,表示每个匹配项都替换。re.sub还允许使用函数对匹配项的替换进行复杂的处理。如:re.sub(r'\s', lambda m: '[' + m.group(0) + ']', text, 0);将字符串中的空格' '替换为'[ ]'。
★re.split可以使用re.split来分割字符串,如:re.split(r'\s+', text);将字符串按空格分割成一个单词列表。
★re.compile可以把正则表达式编译成一个正则表达式对象。可以把那些经常使用的正则表达式编译成正则表达式对象,这样可以提高一定的效率。下面是一个正则表达式对象的一个例子:
例:
import re
r = re.compile('\d+')
r1 = r.match('adfaf123asdf1asf1123aa')
if r1:
print(r1.group())
else:
print('no match')
r2 = r.search('adfaf123asdf1asf1123aa')
if r2:
print(r2.group())
print(r2.groups())
else:
print('no match')
r3 = r.findall('adfaf123asdf1asf1123aa')
if r3:
print(r3)
else:
print('no match')
r4 = r.sub('###','adfaf123asdf1asf1123aa')
print(r4)
r5 = r.subn('###','adfaf123asdf1asf1123aa')
print(r5)
r6 = r.split('adfaf123asdf1asf1123aa',maxsplit=2)
print(r6)
注:re执行分二步:首先编译,然后执行。故先使用re.compile进行查询的字符串进行编译,之后的操作无需在次编译,可以提高效率。
匹配IP具体实例:
ip = '12aa13.12.15aasdfa12.32aasdf192.168.12.13asdfafasf12abadaf12.13'
res = re.findall('(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})',ip)
print(res)
res1 = re.findall('(?:\d{1,3}\.){3}\d{1,3}',ip)
print(res1)
而group,groups 主要是针对查询的字符串是否分组,一般只是针对search和match,即'\d+' 和('\d+') 输出结果为:
123 和('123',)。
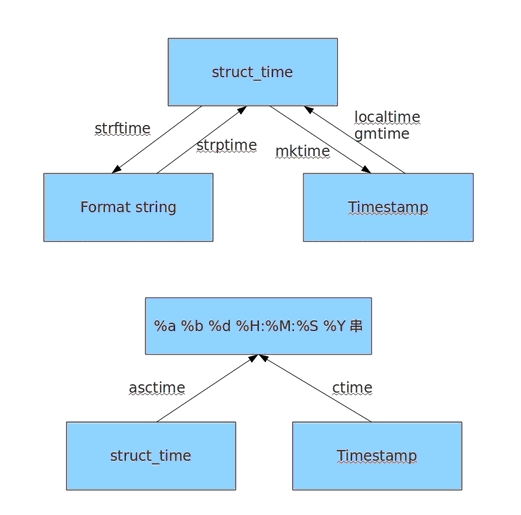
7、time模块
time模块提供各种操作时间的函数
import time
#1、时间戳 1970年1月1日之后的秒
#3、元组 包含了:年、日、星期等... time.struct_time
#4、格式化的字符串 2014-11-11 11:11
print time.time()
print time.mktime(time.localtime())
print time.gmtime() #可加时间戳参数
print time.localtime() #可加时间戳参数
print time.strptime('2014-11-11', '%Y-%m-%d')
print time.strftime('%Y-%m-%d') #默认当前时间
print time.strftime('%Y-%m-%d',time.localtime()) #默认当前时间
print time.asctime()
print time.asctime(time.localtime())
print time.ctime(time.time())
import datetime
'''
datetime.date:表示日期的类。常用的属性有year, month, day
datetime.time:表示时间的类。常用的属性有hour, minute, second, microsecond
datetime.datetime:表示日期时间
datetime.timedelta:表示时间间隔,即两个时间点之间的长度
timedelta([days[, seconds[, microseconds[, milliseconds[, minutes[, hours[, weeks]]]]]]])
strftime("%Y-%m-%d")
'''
import datetime
print datetime.datetime.now()
print datetime.datetime.now() - datetime.timedelta(days=5)
本文出自 “秋天的童话” 博客,请务必保留此出处http://wushank.blog.51cto.com/3489095/1656730
def login(name,info,passwd = '123456')
函数参数可以有默认值,调用函数时:
1、如果只传二个参数,则有默认值的一定要放到最后;
def login(name,passwd = '123456',info='welcome to you')
2、如果传二个参数,一定要指明形参;
login(user)
login(user,passwd)
login(user,info='欢迎')
login(user,info='欢迎',passwd='123456')
def login(*arg) 函数参数个数不定,传参数的时候可以多个,包装为列表;例:
def list_show(*args):
for name in args:
print(name)
list_show('a','b','c','d',1,2,3,4) #传多个参数
list_show(['a','b','c',1,2,3]) #直接传个列表参数
def login(**arg) 函数参数个数不定,传参数的时候可以多个,包装为字典;例:
def dict_show(**args):
for name in args.items():
print(name)
dict_show(name='kevin',age=23) #传多个参数时,格式为key=value
print('##################')
dict = {'name':'kevin','age':23}
dict_show(**dict) #直接传个字典参数时,字典前加二个**
2、生成器yield:
for i in range(1000): pass会导致生成一个 1000 个元素的 List,而代码:
for i in xrange(1000): pass则不会生成一个 1000 个元素的 List,而是在每次迭代中返回下一个数值,内存空间占用很小。因为 xrange 不返回 List,而是返回一个 iterable 对象。同样类似于文件读行的readlines和xreadlines。带有 yield 的函数在 Python 中被称之为 generator(生成器),例:def kevin_readlines():
seek = 0
while True:
with open('D:/eclipse/workspace/python27/first_python27/file/file.txt','r') as f: #with打开文件无需使用close来结束读取文件
f.seek(seek)
data = f.readline()
if data:
seek = f.tell()
yield data
else:
return #直接返回,退出函数
for line in kevin_readlines():
print(line)yeild生成器需要用循环来一行一行读取。yeild经常用于读取函数的中间值,适合用于多线程之类的情况。使用next来一次一次调用函数值。
3、函数介绍:
★ lamba
python lambda是在python中使用lambda来创建匿名函数,而用def创建的方法是有名称的,除了从表面上的方法名不一样外,python lambda还有哪些和def不一样呢?
1 python lambda会创建一个函数对象,但不会把这个函数对象赋给一个标识符,而def则会把函数对象赋值给一个变量。
2 python lambda它只是一个表达式,而def则是一个语句。
lambda语句中,冒号前是参数,可以有多个,用逗号隔开,冒号右边的返回值。lambda语句构建的其实是一个函数对象。
例:
m = lambda x,y,z: (x-y)*z
print m(234,122,5)
也经常用于生成列表,例:
list = [i ** i for i in range(10)]
print(list)
list_lambda = map(lambda x:x**x,range(10))
print(list_lambda)
★ enumerate(iterable,[start]) iterable为一个可迭代的对象;
enumerate(iterable[, start]) -> iterator for index, value of iterable Return an enumerate object. iterable must be another object that supports iteration. The enumerate object yields pairs containing a count (from start, which defaults to zero) and a value yielded by the iterable
argument. enumerate is useful for obtaining an indexed list: (0, seq[0]), (1, seq[1]), (2, seq[2]), ...
例:
for k,v in enumerate(['a','b','c',1,2,3],10):
print k,v
★S.format(*args, **kwargs) -> string 字符串的格式输出,类似于格式化输出%s
Return a formatted version of S, using substitutions from args and kwargs.
The substitutions are identified by braces ('{' and '}').
s = 'i am {0},{1}'
print(s.format('wang',1))
★map(function,sequence) 将squence每一项做为参数传给函数,并返回值
例:
def add(arg):
return arg + 101
print(map(add,[12,23,34,56]))
★filter(function or None, sequence) -> list, tuple, or string 返还true的序列
Return those items of sequence for which function(item) is true. If
function is None, return the items that are true. If sequence is a tuple
or string, return the same type, else return a list.
例:
def comp(arg):
if arg < 8:
return True
else:
return False
print(filter(comp,[1,19,21,8,5]))
print(filter(lambda x:x % 2,[1,19,20,8,5]))
print(filter(lambda x:x % 2,(1,19,20,8,5)))
print(filter(lambda x:x > 'a','AbcdE'))
★reduce(function, sequence[, initial]) -> value 对二个参数进行计算
Apply a function of two arguments cumulatively to the items of a sequence,
from left to right, so as to reduce the sequence to a single value.For example, reduce(lambda x, y: x+y, [1, 2, 3, 4, 5]) calculates((((1+2)+3)+4)+5). If initial is present, it is placed before the
items of the sequence in the calculation, and serves as a default when the sequence is empty.
例:
print(reduce(lambda x,y:x*y,[22,11,8]))
print(reduce(lambda x,y:x*y,[3],10))
print(reduce(lambda x,y:x*y,[],5))
★zip(seq1 [, seq2 [...]]) -> [(seq1[0], seq2[0] ...), (...)] 将多个序列转化为新元祖的序列
Return a list of tuples, where each tuple contains the i-th element from each of the argument sequences. The returned list is truncated in length to the length of the shortest argument sequence.
例:
a = [1,2,3,4,5,6]
b = [11,22,33,44,55]
c = [111,222,333,444]
print(zip(a,b,c))
★eval(source[, globals[, locals]]) -> value 将表达式字符串执行为值,其中globals为全局命名空间,locals为局部命名空间,从指字的命名空间中执行表达式,
Evaluate the source in the context of globals and locals. The source may be a string representing a Python expression or a code object as returned by compile(). The globals must be a dictionary and locals can be any mapping, defaulting to the current globals and locals. If only globals is given, locals defaults to it.
例:
a = '8*(8+20-5%12*23'
print(eval(a))
d = {'a':5,'b':4}
print(eval('a*b',d))
★exec(source[, globals[, locals]]) 语句用来执行储存在字符串或文件中的Python语句
例:
a = 'print("nihao")'
b = 'for i in range(10): print i'
exec(a)
exec(b)
★execfile(filename[, globals[, locals]])
Read and execute a Python script from a file.The globals and locals are dictionaries, defaulting to the currentglobals and locals. If only globals is given, locals defaults to it.
4、常用模块:★random 生成随机数
print random.random() 生成0-1之间的小数
print random.randint(1,3) 生成整数,包含endpoint
print random.randrange(1,3,2) 生成整数,不包含endpoint
randrange(self, start, stop=None, step=?)
生成5位随机数,例:
import random
a = []
for i in range(5):
if i == random.randint(1,5):
a.append(str(i))
else:
a.append(chr(random.randint(65,90)))
else:
print(''.join(a))
★生成MD5码
例:
一. 使用md5包
import md5
src = 'this is a md5 test.'
m1 = md5.new()
m1.update(src)
print m1.hexdigest()
二. 使用hashlib
import hashlib
hash = hashlib.md5()
hash.update('this is a md5 test.')
hash.update('admin')
print(hash.digest())
print(hash.hexdigest())
推荐使用第二种方法。
对以上代码的说明:
1.首先从python直接导入hashlib模块
2.调用hashlib里的md5()生成一个md5 hash对象
3.生成hash对象后,就可以用update方法对字符串进行md5加密的更新处理
4.继续调用update方法会在前面加密的基础上更新加密
5.加密后的二进制结果
6.十六进制结果
如果只需对一条字符串进行加密处理,也可以用一条语句的方式:
print(hashlib.new("md5", "Nobody inspects the spammish repetition").hexdigest())
5、python对象与文件之间的序列化和反序列化(pickle和json)
★pickle模块用来实现python对象的序列化和反序列化。通常地pickle将python对象序列化为二进制流或文件。
python对象与文件之间的序列化和反序列化:
pickle.dump()
pickle.load()
如果要实现python对象和字符串间的序列化和反序列化,则使用:
pickle.dumps()
pickle.loads()
可以被序列化的类型有:
* None,True 和 False;
* 整数,浮点数,复数;
* 字符串,字节流,字节数组;
* 包含可pickle对象的tuples,lists,sets和dictionaries;
* 定义在module顶层的函数:
* 定义在module顶层的内置函数;
* 定义在module顶层的类;
* 拥有__dict__()或__setstate__()的自定义类型;
注意:对于函数或类的序列化是以名字来识别的,所以需要import相应的module。
例:
import pickle
data = {
'a': [1, 2.0, 3, 4+6j],
'b': ("character string", "byte string"),
'c': set([None, True, False])
}
du = pickle.dumps(data)
print(pickle.loads(du))
print(du)
with open('data.pickle', 'wb') as f:
pickle.dump(data, f)
with open('data.pickle', 'rb') as f:
data = pickle.load(f)
print(str(data))
★JSON(JavaScript Object Notation):一种轻量级数据交换格式,相对于XML而言更简单,也易于阅读和编写,机器也方便解析和生成,Json是JavaScript中的一个子集。
Python的Json模块序列化与反序列化的过程分别是 encoding和 decoding
encoding:把一个Python对象编码转换成Json字符串
decoding:把Json格式字符串解码转换成Python对象
具体的转化对照如下:
loads方法返回了原始的对象,但是仍然发生了一些数据类型的转化。比如,上例中‘abc’转化为了unicode类型。从json到python的类型转化对照如下:
例:
import json
data = { 'a': [1, 2.0, 3, 4], 'b': ("character string", "byte string"), 'c': 'abc'}
du = json.dumps(data)
print(du)
print(json.loads(du,encoding='ASCII'))
with open('data.json','wb') as f:
json.dump(data,f)
with open('data.json','rb') as f:
data = json.load(f)
print(repr(data))
经测试,2.7版本导出的json文件,3.4版本导入会报错:TypeError: the JSON object must be str, not 'bytes'
6、正则表达式模块
★re.match的函数原型为:re.match(pattern, string, flags)
第一个参数是正则表达式,这里为"(\w+)\s",如果匹配成功,则返回一个Match,否则返回一个None;第二个参数表示要匹配的字符串;第三个参数是标致位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
★re.search的函数原型为: re.search(pattern, string, flags)
每个参数的含意与re.match一样。 re.match与re.search的区别:re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
★re.findall可以获取字符串中所有匹配的字符串。如:re.findall(r'\w*oo\w*', text);获取字符串中,包含'oo'的所有单词。
★re.sub的函数原型为:re.sub(pattern, repl, string, count)
其中第二个函数是替换后的字符串;本例中为'-'第四个参数指替换个数。默认为0,表示每个匹配项都替换。re.sub还允许使用函数对匹配项的替换进行复杂的处理。如:re.sub(r'\s', lambda m: '[' + m.group(0) + ']', text, 0);将字符串中的空格' '替换为'[ ]'。
★re.split可以使用re.split来分割字符串,如:re.split(r'\s+', text);将字符串按空格分割成一个单词列表。
★re.compile可以把正则表达式编译成一个正则表达式对象。可以把那些经常使用的正则表达式编译成正则表达式对象,这样可以提高一定的效率。下面是一个正则表达式对象的一个例子:
例:
import re
r = re.compile('\d+')
r1 = r.match('adfaf123asdf1asf1123aa')
if r1:
print(r1.group())
else:
print('no match')
r2 = r.search('adfaf123asdf1asf1123aa')
if r2:
print(r2.group())
print(r2.groups())
else:
print('no match')
r3 = r.findall('adfaf123asdf1asf1123aa')
if r3:
print(r3)
else:
print('no match')
r4 = r.sub('###','adfaf123asdf1asf1123aa')
print(r4)
r5 = r.subn('###','adfaf123asdf1asf1123aa')
print(r5)
r6 = r.split('adfaf123asdf1asf1123aa',maxsplit=2)
print(r6)
注:re执行分二步:首先编译,然后执行。故先使用re.compile进行查询的字符串进行编译,之后的操作无需在次编译,可以提高效率。
匹配IP具体实例:
ip = '12aa13.12.15aasdfa12.32aasdf192.168.12.13asdfafasf12abadaf12.13'
res = re.findall('(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})',ip)
print(res)
res1 = re.findall('(?:\d{1,3}\.){3}\d{1,3}',ip)
print(res1)
而group,groups 主要是针对查询的字符串是否分组,一般只是针对search和match,即'\d+' 和('\d+') 输出结果为:
123 和('123',)。
7、time模块
time模块提供各种操作时间的函数
import time
#1、时间戳 1970年1月1日之后的秒
#3、元组 包含了:年、日、星期等... time.struct_time
#4、格式化的字符串 2014-11-11 11:11
print time.time()
print time.mktime(time.localtime())
print time.gmtime() #可加时间戳参数
print time.localtime() #可加时间戳参数
print time.strptime('2014-11-11', '%Y-%m-%d')
print time.strftime('%Y-%m-%d') #默认当前时间
print time.strftime('%Y-%m-%d',time.localtime()) #默认当前时间
print time.asctime()
print time.asctime(time.localtime())
print time.ctime(time.time())
import datetime
'''
datetime.date:表示日期的类。常用的属性有year, month, day
datetime.time:表示时间的类。常用的属性有hour, minute, second, microsecond
datetime.datetime:表示日期时间
datetime.timedelta:表示时间间隔,即两个时间点之间的长度
timedelta([days[, seconds[, microseconds[, milliseconds[, minutes[, hours[, weeks]]]]]]])
strftime("%Y-%m-%d")
'''
import datetime
print datetime.datetime.now()
print datetime.datetime.now() - datetime.timedelta(days=5)
本文出自 “秋天的童话” 博客,请务必保留此出处http://wushank.blog.51cto.com/3489095/1656730

相关文章推荐
- 【python】数据库操作
- Python删除列表重复数据以及效率问题
- 从底层理解Python的执行
- win32系统 python3.4 安装matplotlib
- Python进行中文注释
- python 轻量级邮件发送库
- 测试python awk sed 读取文件指定位置时的性能
- Python学习之路二
- 测试python awk sed 读取文件指定位置时的性能
- Python Template 错误
- 基于python的机器学习(一)
- Python2.7-异常和工具
- python学习笔记第一课_Phoenix-晶
- [笔记]python的os库
- Effective Python 条目二:遵循PEP8风格规约
- Python 中有关中文编码解码小记
- 在Python的Django框架下使用django-tagging的教程
- python 3 最简单的小爬虫
- 使用url_helper简化Python中Django框架的url配置教程
- 在Python的Django框架中simple-todo工具的简单使用