局部加权线性回归及岭回归之Python实现
2015-05-28 21:12
661 查看
经常在网上搜索学习资料的童鞋会发现CSDN是个很不错的网站(IT领域),里面有很多大牛共享的技术类博客,本人虽然是初学小白,但还是想共享下自己的学习心得与经验,权当交流。好了,废话不多说让我们进入正题吧!
这里主要讨论下广义回归中的经典算法~局部加权线性回归和岭回归以及如何用Python代码实现算法。内容上虽然不是学术论文,但同样遵循学术的严谨性,因此可能会有部分数理知识。本人也很讨厌成篇的理论推导,不过在这里我们只使用结论部分,并注重如何使用Python一步一步实现算法。提到回归,只要是学过统计学或者概率论的同学估计不会太陌生,“回归”一词最早是由达尔文的表兄弟在19世纪提出的,最初的目的是为了研究人的身高,通过回归分析,他发现了子代的身高会向着平均身高回退,这正是“回归”一词的来源。
最经典最简单的回归是线性回归。回归的目的是根据因变量预测数值型目标变量,最直接的办法是依据输入值写出一个目标计算公式,就像函数映射一样,没错,回归本质上就是函数映射。比如你要预测男友汽车功率的大小,可能会这么计算:HorsePower=0.0015*annualSalary-0.99*hoursListeningToPublicRadio,这里的关键是你如何求出该方程的系数(0.0015,-0.99)。求解该系数要用到统计上所谓的最小二乘法,该方法的思想很简单,就是要找到一条最“恰当”的直线去拟合因变量与自变量之间的散点(二维情况下),这里的恰当指的是能够使得拟合的误差最小,即如下公式取得最小值:
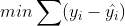
[align=left] [/align]
其中
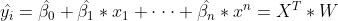
这里y一尖表示多个自变量对应的因变量的估计值,β一尖为权重或者系数的估计值。对于最小值的求解可以采用求导的方法,即对每个参数求偏导并令导数为零,得到所谓的正规方程组,解出所有的参数或者说是系数
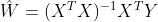
其中X为已知样本的数据矩阵,Y为对应样本的因变量取值。注意这个权重估计值的矩阵表达式,下面的编程中会用到该表达式求系数,需要注意的另一点是表达式中有求矩阵逆这一过程,因此在编程中要先用if条件做出判断,即如果矩阵可逆继续向下执行程序,否则抛出一条提示信息:"This matrix is singular, cannot doinverse"。下面我们用Python中numpy线性代数库来实现求系数的过程。
def lm_pred(X,ws):
yhat=X.dot(ws.A)
return yhat
短短几行代码便实现了系数的求解,这完全得益于numpy库对线性代数运算的支持。具体来说,第一行代码引入外援库numpy,第二行开始定义函数,函数中有两个形参,X为已知样本的数据,Y为对应样本的因变量取值。注意:这里是以数组形式输入X,Y的,故要将数据转化为矩阵格式以便支持下面的线性代数运算,接下来的三行代码是对求逆过程的可行性做判断,如果行列式为0,则抛出不可逆提示,并返回空值。如果可逆,则继续执行下面的求系数公式,最后函数返回了系数的估计值 ws。第二个函数是对新数据进行预测的函数,代码非常简单,就是让求出的系数与输入的数据矩阵相乘,这样得到的结果就是y的预测值。如果y的真实值已知,我们还以计算真实值与预测值之间的误差,以衡量模型的拟合效果。
线性回归的一个问题是有可能出现欠拟合,因为它求的是具有最小均方误差的无偏估计。如果欠拟合可能导致对未知数据预测能力下降,故统计学家提出了允许在估计中引入一些偏差,从而降低预测的均方误差,这一方法叫做局部加权线性回归。关于这一块的数理背景,有兴趣的朋友可以查阅更多的书籍。
局部加权线性回归,这种算法会给待测点附近的已知样本点赋予一定的权重,距离待测点近的样本权重大,反之则权重小。该算法求解回归系数的公式如下:
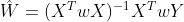
其中W是一个矩阵,用来给每个训练样本点赋予权重,除了这一点之外该公式与之前的求解系数公式毫无差异,这里的权重矩阵W是依据测试点和训练样本事先求出来的。求解公式如下
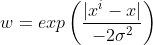
[align=left] [/align]
该公式实际上是高斯核函数。该公式可以构建一个只含对角元素的权重矩阵w,并且点x与x(i)越近(这里的远近用欧式距离衡量),w(i,i)的权重越大,该公式还包含用户需要指定的的衰减参数sigma。下面继续用numpy库实现该算法。
该函数根据测试数据的样本大小先生成了一个备用数组(zeros(m)),然后利用循环每次取一个测试点并调用事先编好的求系数函数lwlm(),将测试点与对应的系数相乘并传入备用矩阵,循环结束后,求出了所有测试点的预测预测值。同样如果测点的y值是已知的,我们可以计算预测值yhat与y之间的误差,以衡量模型的拟合效果。值得注意的是,该函数的参数K需要用户自己确定,如果K值较大可能会出现欠拟合,如果K值较小则会出现过拟合,k值也可理解为光滑参数(一个非参数回归中的概念)。
不要以为到此就万事大吉了,该算法大大增加了计算量,分析代码就可以知道了,它在对每个点做预测时都必须遍历整个训练集,这样很大程度的增加了程序的运行时间,对几百条小样本数据集还可以,但是对于上亿的数据量就不行了。下面介绍另一种提高预测精度的方法:岭回归。
如果自变量的个数比样本点还多(n>m),这样的数据也叫高维数据,这样的数据对应的矩阵X是非满秩的,非满秩矩阵是不可求逆矩阵的。为了解决这个问题统计学家引入了岭回归(ridge regression)的概念,这是一种缩减技术,它能够将某些不重要的自变量的系数压缩到零、从而提高预测的精度。岭回归中求解系数的公式如下:
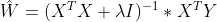
该公式与前两种求系数的公式也没太大变化,只是在矩阵XTX上加了一个lambda单位矩阵从而使得矩阵非奇异(可逆),其中lambda是用户自定义参数。同样我们来编写该公式的函数如下:
def ridge_regs(xArr,yArr,numTestPts = 30):
yMean = mean(yArr)
yArr =yArr - yMean
xMeans = mean(xArr,0)
xVar = var(xArr,0)
xArr = (xArr - xMeans)/xVar
wMat =zeros((numTestPts,shape(xArr)[1]))
for i in range(numTestPts):
ws =ridge_reg(xArr,yArr,exp(i-10))
wMat[i,:]=ws.T
return wMat
第一函数和前面的函数没有太多的差异,我就不啰嗦了。第二个函数是多次运行求系数的函数,并且在求系数之前将数据进行标准化处理了一下,其中每次运行求系数的函数时,参数lam都不同,lam=exp(i-10))以指数级变化。整个过程是通过循环实现,循环的次数由用户决定,默认值为30次,最后函数返回了包含多组系数的wMat数组。
到此,三种回归方法已经介绍完毕,不明白数理原理的朋友可以查阅更多的书籍来学习。
第一次写博客,希望路过的大牛多多指点,谢谢!
[align=left] [/align]
这里主要讨论下广义回归中的经典算法~局部加权线性回归和岭回归以及如何用Python代码实现算法。内容上虽然不是学术论文,但同样遵循学术的严谨性,因此可能会有部分数理知识。本人也很讨厌成篇的理论推导,不过在这里我们只使用结论部分,并注重如何使用Python一步一步实现算法。提到回归,只要是学过统计学或者概率论的同学估计不会太陌生,“回归”一词最早是由达尔文的表兄弟在19世纪提出的,最初的目的是为了研究人的身高,通过回归分析,他发现了子代的身高会向着平均身高回退,这正是“回归”一词的来源。
最经典最简单的回归是线性回归。回归的目的是根据因变量预测数值型目标变量,最直接的办法是依据输入值写出一个目标计算公式,就像函数映射一样,没错,回归本质上就是函数映射。比如你要预测男友汽车功率的大小,可能会这么计算:HorsePower=0.0015*annualSalary-0.99*hoursListeningToPublicRadio,这里的关键是你如何求出该方程的系数(0.0015,-0.99)。求解该系数要用到统计上所谓的最小二乘法,该方法的思想很简单,就是要找到一条最“恰当”的直线去拟合因变量与自变量之间的散点(二维情况下),这里的恰当指的是能够使得拟合的误差最小,即如下公式取得最小值:
[align=left] [/align]
其中
这里y一尖表示多个自变量对应的因变量的估计值,β一尖为权重或者系数的估计值。对于最小值的求解可以采用求导的方法,即对每个参数求偏导并令导数为零,得到所谓的正规方程组,解出所有的参数或者说是系数
其中X为已知样本的数据矩阵,Y为对应样本的因变量取值。注意这个权重估计值的矩阵表达式,下面的编程中会用到该表达式求系数,需要注意的另一点是表达式中有求矩阵逆这一过程,因此在编程中要先用if条件做出判断,即如果矩阵可逆继续向下执行程序,否则抛出一条提示信息:"This matrix is singular, cannot doinverse"。下面我们用Python中numpy线性代数库来实现求系数的过程。
from numpy import *
<p align="left" style="background: rgb(240, 240, 240);">def lm(X,Y):</p>
X= mat(X);Y= mat(Y).T
if linalg.det(X.T*X) ==0.0:
print "This matrix is singular,cannot do inverse"
return
ws = (X.T*X).I*(X.T*Y)
return ws
def lm_pred(X,ws):
yhat=X.dot(ws.A)
return yhat
短短几行代码便实现了系数的求解,这完全得益于numpy库对线性代数运算的支持。具体来说,第一行代码引入外援库numpy,第二行开始定义函数,函数中有两个形参,X为已知样本的数据,Y为对应样本的因变量取值。注意:这里是以数组形式输入X,Y的,故要将数据转化为矩阵格式以便支持下面的线性代数运算,接下来的三行代码是对求逆过程的可行性做判断,如果行列式为0,则抛出不可逆提示,并返回空值。如果可逆,则继续执行下面的求系数公式,最后函数返回了系数的估计值 ws。第二个函数是对新数据进行预测的函数,代码非常简单,就是让求出的系数与输入的数据矩阵相乘,这样得到的结果就是y的预测值。如果y的真实值已知,我们还以计算真实值与预测值之间的误差,以衡量模型的拟合效果。
线性回归的一个问题是有可能出现欠拟合,因为它求的是具有最小均方误差的无偏估计。如果欠拟合可能导致对未知数据预测能力下降,故统计学家提出了允许在估计中引入一些偏差,从而降低预测的均方误差,这一方法叫做局部加权线性回归。关于这一块的数理背景,有兴趣的朋友可以查阅更多的书籍。
局部加权线性回归,这种算法会给待测点附近的已知样本点赋予一定的权重,距离待测点近的样本权重大,反之则权重小。该算法求解回归系数的公式如下:
其中W是一个矩阵,用来给每个训练样本点赋予权重,除了这一点之外该公式与之前的求解系数公式毫无差异,这里的权重矩阵W是依据测试点和训练样本事先求出来的。求解公式如下
[align=left] [/align]
该公式实际上是高斯核函数。该公式可以构建一个只含对角元素的权重矩阵w,并且点x与x(i)越近(这里的远近用欧式距离衡量),w(i,i)的权重越大,该公式还包含用户需要指定的的衰减参数sigma。下面继续用numpy库实现该算法。
<p align="left" style="background: rgb(240, 240, 240);">def lwlm(testPoint,X,Y,k=1.0):</p>
X = mat(X); Y=mat(Y).T
m = shape(X)[0]
weights = mat(eye((m)))
for j in range(m):
d= testPoint - X[j,:]
weights[j,j] =exp(d*d.T/(-2.0*k**2))
if linalg.det(X.T*weights*X) == 0.0:
print "This matrix issingular, cannot do inverse"
return
ws = (X.T*weights *X).I*(X.T*(weights*Y))
return ws
<p align="left" style="background: rgb(240, 240, 240);">#注意:该函数求出的是一个测试点的回归系数,实际上局部加权线性回归方法给出了所有测试点的专属系数,即每个测试点对应一个自己的回归系数。预测函数如下:</p>
<p align="left" style="background: rgb(240, 240, 240);">def lwlm_pred(testX,X,Y,k=1.0): #loops over all the data points and applieslwlr to each one</p>
m = shape(testX)[0]
yHat = zeros(m)
for i in range(m):
yHat[i] =testX[i]*lwlm(testX[i],X,Y,k)
return yHat
该函数根据测试数据的样本大小先生成了一个备用数组(zeros(m)),然后利用循环每次取一个测试点并调用事先编好的求系数函数lwlm(),将测试点与对应的系数相乘并传入备用矩阵,循环结束后,求出了所有测试点的预测预测值。同样如果测点的y值是已知的,我们可以计算预测值yhat与y之间的误差,以衡量模型的拟合效果。值得注意的是,该函数的参数K需要用户自己确定,如果K值较大可能会出现欠拟合,如果K值较小则会出现过拟合,k值也可理解为光滑参数(一个非参数回归中的概念)。
不要以为到此就万事大吉了,该算法大大增加了计算量,分析代码就可以知道了,它在对每个点做预测时都必须遍历整个训练集,这样很大程度的增加了程序的运行时间,对几百条小样本数据集还可以,但是对于上亿的数据量就不行了。下面介绍另一种提高预测精度的方法:岭回归。
如果自变量的个数比样本点还多(n>m),这样的数据也叫高维数据,这样的数据对应的矩阵X是非满秩的,非满秩矩阵是不可求逆矩阵的。为了解决这个问题统计学家引入了岭回归(ridge regression)的概念,这是一种缩减技术,它能够将某些不重要的自变量的系数压缩到零、从而提高预测的精度。岭回归中求解系数的公式如下:
该公式与前两种求系数的公式也没太大变化,只是在矩阵XTX上加了一个lambda单位矩阵从而使得矩阵非奇异(可逆),其中lambda是用户自定义参数。同样我们来编写该公式的函数如下:
def ridge_reg(X,Y,lam=0.2):
X = mat(X)
Y = mat(Y).T
denom = X.T*X +eye(shape(X)[1])*lam
if linalg.det(denom) ==0.0:
print "This matrix issingular, cannot do inverse"
return
w= denom.I * (X.T*Y)
return w=
def ridge_regs(xArr,yArr,numTestPts = 30):
yMean = mean(yArr)
yArr =yArr - yMean
xMeans = mean(xArr,0)
xVar = var(xArr,0)
xArr = (xArr - xMeans)/xVar
wMat =zeros((numTestPts,shape(xArr)[1]))
for i in range(numTestPts):
ws =ridge_reg(xArr,yArr,exp(i-10))
wMat[i,:]=ws.T
return wMat
第一函数和前面的函数没有太多的差异,我就不啰嗦了。第二个函数是多次运行求系数的函数,并且在求系数之前将数据进行标准化处理了一下,其中每次运行求系数的函数时,参数lam都不同,lam=exp(i-10))以指数级变化。整个过程是通过循环实现,循环的次数由用户决定,默认值为30次,最后函数返回了包含多组系数的wMat数组。
到此,三种回归方法已经介绍完毕,不明白数理原理的朋友可以查阅更多的书籍来学习。
第一次写博客,希望路过的大牛多多指点,谢谢!
[align=left] [/align]

相关文章推荐
- 动易2006序列号破解算法公布
- Ruby实现的矩阵连乘算法
- C#插入法排序算法实例分析
- C#数据结构与算法揭秘二
- 算法练习之从String.indexOf的模拟实现开始
- C#算法之关于大牛生小牛的问题
- C#实现的算24点游戏算法实例分析
- c语言实现的带通配符匹配算法
- 浅析STL中的常用算法
- 算法之排列算法与组合算法详解
- C++实现一维向量旋转算法
- Ruby实现的合并排序算法
- C#折半插入排序算法实现方法
- 基于C++实现的各种内部排序算法汇总
- C++线性时间的排序算法分析
- C++实现汉诺塔算法经典实例
- PHP实现克鲁斯卡尔算法实例解析
- C#常见算法面试题小结
- JavaScript 组件之旅(二)编码实现和算法
- JavaScript数据结构和算法之图和图算法