关于做人工智能—五子棋的总结
2015-05-28 15:38
357 查看
前言:
刚学玩C一个月,院里有个程序设计的比赛,于是就动手写了这玩意儿。
正文:
首先,对于每一盘棋都有很多种下法,当黑方落下第一颗棋子的时候,白方有254种下法,白方在这254种下法中选择其一后,黑方又有253中下法。如此,将所有的下法都考虑,全部列出来就构成了一颗巨大的博弈树,也称搜索数。这颗博弈树的根节点便是黑方下的第一颗棋子,紧接着的下一层便是白方下棋的所有情况,依次下去,直到结束。而电脑要做的是从下面的子节点中找出最有利于电脑方的节点,也就是最佳走法。谁想得深远,预测的步数越多,棋局了解到位,就越厉害。如果能将未来的所有情况都考虑到位,那必定处于不败之地。
在选择最佳走法中,我们要用到极小极大搜索算法。我们先假设有个对棋局的评价函数,即可以对任何一个局面对电脑方打分,分越高越对电脑有利,分越低却对玩家有利,也就是说这个评价函数是对电脑方而言的,计算机赢则为无穷大,输则无穷小。其它所有情况都在这之间。
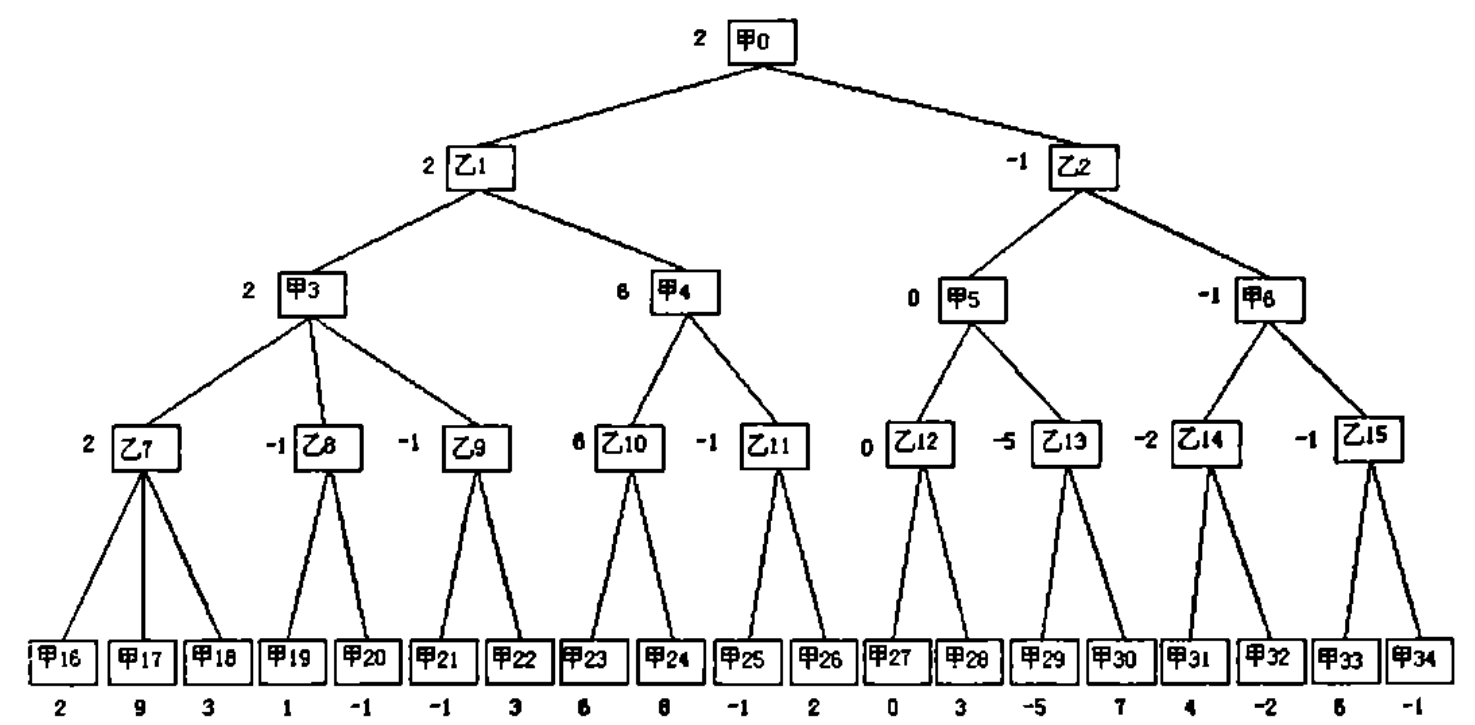
如上图就是所谓的博弈树,假如:甲对应电脑方,乙对应玩家。当前该电脑方下棋,即甲0节点,下一层的子节点即该玩家下。双方都希望在未来的局势中,往最有利于己方的方向进行。计算机当然想自己的分高,所以会选子节点分值最大的乙1,分值为2,所以甲0分值为2。而乙1想分值低,于是,他会选甲3-4中分值最小的甲3,分值为2,乙1的值因此为2。所以,在极小极大搜索算法中,称想要最大值的甲的节点为极大值点,想要最小值的乙的节点为极小值点。在这个极大值极小值的搜索过程为极小极大搜索算法。
前面所说的,都是理论上可行的方法,因为在这复杂度指数级增长的过程中,想要搜索完这么庞大的博弈树是不可能的。我们只能往后预测几步,就用静态估值函数算出分数,然后一步步倒推上去,而到当前最佳的走法。这时,我们就需要一个对任意局面评分的评价函数。如果给评估函数打分呢?我是把把棋面分成72路,横15 + 竖15 + 左斜21 + 右斜21 = 72(因为斜着的共有16路形成不了五子)。为72路是为了收集具有形成5子可能性的特征。一个棋局具有电脑方的这些特征越多,棋局分数便越高,具有玩家方特征越多,分值便越低,因此玩家的特征是记负分的。当然不同的特征分值也不同。我将电脑方棋子抽象为1,空格抽象为0。例如:遇到11111便赋值9999999,011110赋值300000,011100或001110赋值为3000等等。如果是玩家的棋就赋相应的负分。最后把72路的分数加起来,黑白双方的总分相加就得到整个棋局的分数。其实,我把每一路的情况分成一个个长度为6的字符串,一一跟原来预定的16个特征做比较,留下每一路分值最大的特征。然而,在没一次判断下那一步的时候,要预测的情况数是巨大的,而没一种情况都要调用静态估值函数,进行大概7000次特征的匹配。为了减少匹配的次数,我用了哈夫曼树编码的思想,把所有的特征编成了一个哈夫曼树(如下图,当时的草稿),每个节点都由0、1组成,这也是我之前把棋子抽象为1,空格抽象为0的原因。具体就不在详述,哈夫曼树编码的思想我是参考的《算法与数据结构》151页。如此,每一个长度为6个字符就不必跟16个特征一一线性的比较,这样就大大的减少了计算量。
光凭上面的还远远不够,我实验过,仅预测三步的时候,电脑下一步,需要等待近半个小时。因此,我在极小极大搜索算法中还加入了Alpha-Beta剪枝剪枝法,可以叫它为Alpha-Beta搜索算法。如下图:

上述的极小极大值搜索过程中,遍历了整棵的博弈树,每一个节点都访问了一次,这样的搜索算法粗糙,效率低下,搜索量非常大。假如将叶节点的评估,计算倒推值与树的产生同时进行,就可能大量减少所需搜索的节点数目,而且保持搜索效果不变。具体思路如下:
Alpha剪枝:
如图:极大值点甲3及下面所有节点
1.因为乙7为2,因此甲三大于或等于2;
2.甲19为1,则乙8小于或等于1;
3.既然甲2是取最大的,暂且等于2,就不用考虑小于或等于1的乙 8了。
因此,甲20不需要考虑,把它剪掉。
Beta剪枝:
同理,如图:极小值点乙1及下面所有节点,一样分析。
这样,就减少了不少分支,剪掉的分部,既不用创建合法的走法,也不用在评估时大量的计算,在一定程度上优化了许多。但是,Alpha-Beta剪枝剪枝法在减枝过程搜索效率与节点的排列顺序有很大关系。因此,可以在产生走法的时候对它进行排序来达到进一步的优化。按理说,对极小节点按从小到大的顺序排序,对极大节点按从大到小的顺序排序是最理想的,但是在最后的节点没产生之前,不可能得到评估值。所以,排序的时候可以根据威胁性大的点周围进行优先搜索的办法达到优化的效果。
最后便是我在最后两天想出来的优化办法,在开头的几十步里,它的优化效果比Alpha-Beta剪枝剪枝法好上几十倍。这里我用到的是缩小搜索范围算法,其实是我瞎起的一个名字。前面的Alpha-Beta剪枝剪枝法是在产生一定子节点后剪掉部分枝节而达到优化效果,而缩小搜索范围算法则是从根节点处直接砍掉分支,从顶端砍下来的话,完全舍弃了其下庞大的分支。具体思路如下:我们在下棋的时候,基本都是在已有的棋子周围下子,所以还有很多空位是完全不需要搜索的。就是基于这一点,我们就能可以确定搜索范围,先判断已下了的棋子最大对角线,在此对角线的基础上画矩形,然后在向外围扩大一两格,这样就在根节点上减少了分支,更不需要考虑在其范围外的以后几步的情况了。不过,在预测的过程中,我们要假设下了某子,这些预测的下子会很快的将范围扩大到边界,而当预测完一个父节点及以下子节点的所有情况后,与前面父节点同一深度的节点并不需要那么大的搜索范围,因此理想的搜索范围应和预测前同样的。这里,我们可以采用堆栈的结构,用入栈操作就可将一方下的棋子存入栈中,得到新的搜索范围,当搜索过程的回溯发生时用出栈操作退出一子,即可恢复到前一搜索范围。这样就能步步为营,有进有退,尽可能的减少不必要的计算。
展望未来:
前面讲的改进搜索算法的目标在于将不必搜索的(冗余)分枝从搜索的过程中尽量剔除,以达到尽量搜索少的分枝束降低运算量的目的。但是仍然在有限时间内预测几步而已,想要让电脑达到世界级水平还是不够的。开头我提过中原大学的硕士学位论文《五子棋棋略的演化学习法》中核心讲的“基因演算法”,也称遗传算法,是让程序具有学习功能,在大量的实践中,程序会不段的更改评估函数特征的权值,这样便克服了人为主观因素的片面性。而在启发式搜索过程中,其实有很多局面是重复的,就增加了很多不必要的重复计算,为了解决这个问题,可以使用基于哈希表的置换表搜索算法,将搜索过的局面存如数据,不需要了就清除,遇到相同的局面只需调用前面计算得出的数据,就避免重算。另外,现在的超线程技术和多核技术也能达到进一步的优化。
感想:
这此做人工智能五子棋,多少也有点收获,相对以前更加懂得怎么在有限的时间内完成自己看似不可能或很难完成的任务,此类任务最好的方法便是证比求易。当中肯定有自己不曾具备的知识,当处于当今这个时代,我们需要的这点知识还是很轻易的找到。然而最关键的还是自己以最快的方法消化弄懂它,让前人或大师研究过的宝贵成果迅速成为自己的技能。作为一名程序员,这次经历给我的感受是,完成一个程序,最重要的绝对是算法,这此做五子棋,人工智能模块的算法我也弄了几天才搞清楚,也许只有某一个点有疑惑,它也可以让你一个下午也弄不明白。当算法完成之后,就可以立即开始组织编码,从数据结构入手,理清程序流程,然后把各个子模块一一攻破。算法花了几天,而编码一天内便能完成,我们日后的重点也因在构思这块。码农于软件工程师的共同点是都会编程,而软件工程师之所以不同是因为他能以程序化思想解决问题本身,而编码是码农们的事了。
刚学玩C一个月,院里有个程序设计的比赛,于是就动手写了这玩意儿。
正文:
首先,对于每一盘棋都有很多种下法,当黑方落下第一颗棋子的时候,白方有254种下法,白方在这254种下法中选择其一后,黑方又有253中下法。如此,将所有的下法都考虑,全部列出来就构成了一颗巨大的博弈树,也称搜索数。这颗博弈树的根节点便是黑方下的第一颗棋子,紧接着的下一层便是白方下棋的所有情况,依次下去,直到结束。而电脑要做的是从下面的子节点中找出最有利于电脑方的节点,也就是最佳走法。谁想得深远,预测的步数越多,棋局了解到位,就越厉害。如果能将未来的所有情况都考虑到位,那必定处于不败之地。
在选择最佳走法中,我们要用到极小极大搜索算法。我们先假设有个对棋局的评价函数,即可以对任何一个局面对电脑方打分,分越高越对电脑有利,分越低却对玩家有利,也就是说这个评价函数是对电脑方而言的,计算机赢则为无穷大,输则无穷小。其它所有情况都在这之间。
如上图就是所谓的博弈树,假如:甲对应电脑方,乙对应玩家。当前该电脑方下棋,即甲0节点,下一层的子节点即该玩家下。双方都希望在未来的局势中,往最有利于己方的方向进行。计算机当然想自己的分高,所以会选子节点分值最大的乙1,分值为2,所以甲0分值为2。而乙1想分值低,于是,他会选甲3-4中分值最小的甲3,分值为2,乙1的值因此为2。所以,在极小极大搜索算法中,称想要最大值的甲的节点为极大值点,想要最小值的乙的节点为极小值点。在这个极大值极小值的搜索过程为极小极大搜索算法。
前面所说的,都是理论上可行的方法,因为在这复杂度指数级增长的过程中,想要搜索完这么庞大的博弈树是不可能的。我们只能往后预测几步,就用静态估值函数算出分数,然后一步步倒推上去,而到当前最佳的走法。这时,我们就需要一个对任意局面评分的评价函数。如果给评估函数打分呢?我是把把棋面分成72路,横15 + 竖15 + 左斜21 + 右斜21 = 72(因为斜着的共有16路形成不了五子)。为72路是为了收集具有形成5子可能性的特征。一个棋局具有电脑方的这些特征越多,棋局分数便越高,具有玩家方特征越多,分值便越低,因此玩家的特征是记负分的。当然不同的特征分值也不同。我将电脑方棋子抽象为1,空格抽象为0。例如:遇到11111便赋值9999999,011110赋值300000,011100或001110赋值为3000等等。如果是玩家的棋就赋相应的负分。最后把72路的分数加起来,黑白双方的总分相加就得到整个棋局的分数。其实,我把每一路的情况分成一个个长度为6的字符串,一一跟原来预定的16个特征做比较,留下每一路分值最大的特征。然而,在没一次判断下那一步的时候,要预测的情况数是巨大的,而没一种情况都要调用静态估值函数,进行大概7000次特征的匹配。为了减少匹配的次数,我用了哈夫曼树编码的思想,把所有的特征编成了一个哈夫曼树(如下图,当时的草稿),每个节点都由0、1组成,这也是我之前把棋子抽象为1,空格抽象为0的原因。具体就不在详述,哈夫曼树编码的思想我是参考的《算法与数据结构》151页。如此,每一个长度为6个字符就不必跟16个特征一一线性的比较,这样就大大的减少了计算量。
光凭上面的还远远不够,我实验过,仅预测三步的时候,电脑下一步,需要等待近半个小时。因此,我在极小极大搜索算法中还加入了Alpha-Beta剪枝剪枝法,可以叫它为Alpha-Beta搜索算法。如下图:
上述的极小极大值搜索过程中,遍历了整棵的博弈树,每一个节点都访问了一次,这样的搜索算法粗糙,效率低下,搜索量非常大。假如将叶节点的评估,计算倒推值与树的产生同时进行,就可能大量减少所需搜索的节点数目,而且保持搜索效果不变。具体思路如下:
Alpha剪枝:
如图:极大值点甲3及下面所有节点
1.因为乙7为2,因此甲三大于或等于2;
2.甲19为1,则乙8小于或等于1;
3.既然甲2是取最大的,暂且等于2,就不用考虑小于或等于1的乙 8了。
因此,甲20不需要考虑,把它剪掉。
Beta剪枝:
同理,如图:极小值点乙1及下面所有节点,一样分析。
这样,就减少了不少分支,剪掉的分部,既不用创建合法的走法,也不用在评估时大量的计算,在一定程度上优化了许多。但是,Alpha-Beta剪枝剪枝法在减枝过程搜索效率与节点的排列顺序有很大关系。因此,可以在产生走法的时候对它进行排序来达到进一步的优化。按理说,对极小节点按从小到大的顺序排序,对极大节点按从大到小的顺序排序是最理想的,但是在最后的节点没产生之前,不可能得到评估值。所以,排序的时候可以根据威胁性大的点周围进行优先搜索的办法达到优化的效果。
最后便是我在最后两天想出来的优化办法,在开头的几十步里,它的优化效果比Alpha-Beta剪枝剪枝法好上几十倍。这里我用到的是缩小搜索范围算法,其实是我瞎起的一个名字。前面的Alpha-Beta剪枝剪枝法是在产生一定子节点后剪掉部分枝节而达到优化效果,而缩小搜索范围算法则是从根节点处直接砍掉分支,从顶端砍下来的话,完全舍弃了其下庞大的分支。具体思路如下:我们在下棋的时候,基本都是在已有的棋子周围下子,所以还有很多空位是完全不需要搜索的。就是基于这一点,我们就能可以确定搜索范围,先判断已下了的棋子最大对角线,在此对角线的基础上画矩形,然后在向外围扩大一两格,这样就在根节点上减少了分支,更不需要考虑在其范围外的以后几步的情况了。不过,在预测的过程中,我们要假设下了某子,这些预测的下子会很快的将范围扩大到边界,而当预测完一个父节点及以下子节点的所有情况后,与前面父节点同一深度的节点并不需要那么大的搜索范围,因此理想的搜索范围应和预测前同样的。这里,我们可以采用堆栈的结构,用入栈操作就可将一方下的棋子存入栈中,得到新的搜索范围,当搜索过程的回溯发生时用出栈操作退出一子,即可恢复到前一搜索范围。这样就能步步为营,有进有退,尽可能的减少不必要的计算。
展望未来:
前面讲的改进搜索算法的目标在于将不必搜索的(冗余)分枝从搜索的过程中尽量剔除,以达到尽量搜索少的分枝束降低运算量的目的。但是仍然在有限时间内预测几步而已,想要让电脑达到世界级水平还是不够的。开头我提过中原大学的硕士学位论文《五子棋棋略的演化学习法》中核心讲的“基因演算法”,也称遗传算法,是让程序具有学习功能,在大量的实践中,程序会不段的更改评估函数特征的权值,这样便克服了人为主观因素的片面性。而在启发式搜索过程中,其实有很多局面是重复的,就增加了很多不必要的重复计算,为了解决这个问题,可以使用基于哈希表的置换表搜索算法,将搜索过的局面存如数据,不需要了就清除,遇到相同的局面只需调用前面计算得出的数据,就避免重算。另外,现在的超线程技术和多核技术也能达到进一步的优化。
感想:
这此做人工智能五子棋,多少也有点收获,相对以前更加懂得怎么在有限的时间内完成自己看似不可能或很难完成的任务,此类任务最好的方法便是证比求易。当中肯定有自己不曾具备的知识,当处于当今这个时代,我们需要的这点知识还是很轻易的找到。然而最关键的还是自己以最快的方法消化弄懂它,让前人或大师研究过的宝贵成果迅速成为自己的技能。作为一名程序员,这次经历给我的感受是,完成一个程序,最重要的绝对是算法,这此做五子棋,人工智能模块的算法我也弄了几天才搞清楚,也许只有某一个点有疑惑,它也可以让你一个下午也弄不明白。当算法完成之后,就可以立即开始组织编码,从数据结构入手,理清程序流程,然后把各个子模块一一攻破。算法花了几天,而编码一天内便能完成,我们日后的重点也因在构思这块。码农于软件工程师的共同点是都会编程,而软件工程师之所以不同是因为他能以程序化思想解决问题本身,而编码是码农们的事了。

相关文章推荐
- 关于人工智能在滴滴调度中的应用总结
- 关于人工智能的小知识总结
- 【2013】实习收获4:关于python中利用ctypes调用c++代码的学习总结
- 关于undo机制的总结[收集中]
- 关于C++中的友元函数的总结
- 关于NorFlash的一点总结
- 关于HttpClient的总结
- 关于Jquery中ajax方法data参数用法的总结
- [转] 关于ASP.NET页面打印技术的总结
- (十一)黑马程序员——关于字符串和数组的习题总结(补充)
- PHP中关于foreach的简单的用法总结
- 关于使用DFS,BFS的一些思考总结
- 关于CDaoDataBase的总结
- 关于vs2005、vs2008和vs2010项目互转的总结(转)
- 关于中小企业信息化命题的阶段性总结(转)
- 2016.7.20学习总结,关于屏幕适配
- 10个关于人工智能和机器学习的有趣开源项目
- 关于链表的一些总结和代码,java实现
- js-关于异步原理的理解和总结
- 关于Eclipse中一个错误排查总结