图的邻接表表示、广度优先、深度优先搜索
2015-05-18 21:58
666 查看
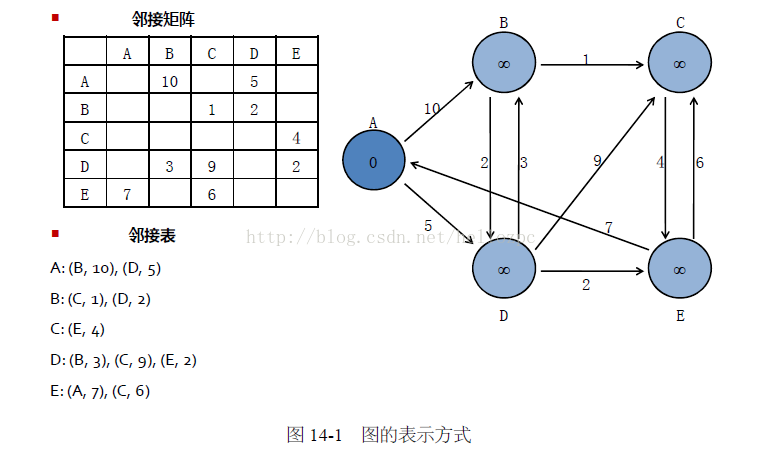
图,就是我们在数据结构中学到的图,它是一种存储信息的结构。图是一类在实际应用中非常常见的数据结构,当数据规模大到一定程度时,如何对其进行高效计算即成为迫切需要解决的问题。最常见的大规模图数据的例子就是互联网网页数据,网页之间通过链接指向形成规模超过500 亿节点的巨型网页图。再如,Facebook 社交网络也是规模巨大的图,仅好友关系已经形成超过10 亿节点、千亿边的巨型图,考虑到Facebook 正在将所有的实体数据节点都构建成网状结构,其最终形成的巨型网络数据规模可以想见其规模。要处理如此规模的图数据,传统的单机处理方式显然已经无能为力,必须采用由大规模机器集群构成的并行图数据库。在处理图数据时,其内部存储结构往往采用邻接矩阵或邻接表的方式,在大规模并行图数据库场景下,邻接表的方式更加常用,大部分图数据库和处理框架都采用了这一存储结构。
本程序是基于图的邻接表存储方式实现的。遗憾的是没有实现带权图,有实现带权图的朋友欢迎留言指教!或加Q:374741295
package linkListGraph;
import java.util.ArrayList;
import java.util.Iterator;
/**
* @ClassName: Graph
* @Description: 图结构实现,封装了图的dfs、bfs遍历算法
* @author zhoupengcheng
* @version 2015年5月17日下午5:07:34
*/
public class Graph {
private ArrayList<Vertex> vertexList;// 用一个ArrayList保存图中的所有结点
private boolean isDirected = false;// 标记是否为有向图
private int nVerts = 0;// 保存总的顶点数
private StackX theStack;// 深度优先搜寻时使用
private Queue theQueue; // 广度优先搜索时使用
private ArrayList<Vertex> bfs;// 在bfs函数中使用,保存bfs得到的结果序列
private ArrayList<Vertex> dfs;// 在dfs函数中使用,保存dfs得到的结果序列
public Graph() {
vertexList = new ArrayList<Vertex>();
dfs = new ArrayList<Vertex>();
bfs = new ArrayList<Vertex>();
}
public Graph(boolean is) {
this();
this.isDirected = is;
}
public boolean isDirected() {
return this.isDirected;
}
public ArrayList<Vertex> getVertexList() {
return vertexList;
}
public ArrayList<Vertex> getDFS() {
return dfs;
}
public ArrayList<Vertex> getBFS() {
return bfs;
}
public void addVertex(Vertex vertex) {
vertex.setIndex(nVerts);
vertexList.add(vertex);
nVerts++;
}
public void addEdge(int start, int end) {
vertexList.get(start).addAdj(vertexList.get(end));
if (!isDirected) {
vertexList.get(end).addAdj(vertexList.get(start));
}
}
public int getVertsCount() {
return nVerts;
}
//深度优先迭代器
public Iterator dfsIterator(){
dfs();
return new DfsIterator();
}
//广度优先迭代器
public Iterator bfsIterator(){
bfs();
return new BfsIterator();
}
// 打印邻接表
public void displayGraph() {
for (int i = 0; i < vertexList.size(); i++) {
printVertx(vertexList.get(i));
}
}
public void printVertx(Vertex vertex) {
ArrayList<Vertex> next = vertex.getAdj();
if (next == null) {
System.out.println(vertex.toString() + " 无邻接点!");
} else {
System.out.print(vertex.toString() + "邻接表:");
for (int i = 0; i < next.size(); i++) {
System.out.print(next.get(i).label + " ");
}
System.out.println();
}
}
// 深度优先遍历
public void dfs() {
theStack = new StackX(nVerts);
vertexList.get(0).wasVisted = true;
dfs.add(vertexList.get(0));
theStack.push(vertexList.get(0));
Vertex vertex;
while (!theStack.isEmpty()) {
vertex = getAdjVertex((Vertex) theStack.peek());
if (vertex == null) {
theStack.pop();
} else {
vertex.wasVisted = true;
dfs.add(vertex);
theStack.push(vertex);
}
}
// ------遍历完成,清除所有访问标志位--------
for (int i = 0; i < getVertsCount(); i++) {
vertexList.get(i).wasVisted = false;
}
}
// 广度优先遍历
public void bfs() {
theQueue = new Queue(nVerts);
vertexList.get(0).wasVisted = true;
bfs.add(vertexList.get(0));
theQueue.insert(vertexList.get(0));
Vertex vertex1;
while (!theQueue.isEmpty()) {
Vertex vertex2 = (Vertex) theQueue.remove();
while ((vertex1 = getAdjVertex(vertex2)) != null) {
vertex1.wasVisted = true;
bfs.add(vertex1);
theQueue.insert(vertex1);
}
}
// ------遍历完成,清除所有访问标志位--------
for (int i = 0; i < getVertsCount(); i++) {
vertexList.get(i).wasVisted = false;
}
}
// 返回vertex顶点的一个未曾访问过的邻接点
public Vertex getAdjVertex(Vertex vertex) {
ArrayList<Vertex> adjVertexs = vertex.getAdj();
for (int i = 0; i < adjVertexs.size(); i++) {
if (!adjVertexs.get(i).wasVisted) {
return adjVertexs.get(i);
}
}
return null;
}
//专门写个迭代器来遍历结果
private abstract class GraphIterator implements Iterator {
int count = 0;
public GraphIterator() {
}
public boolean hasNext() {
return count != getVertsCount() ;
}
public Object next() {
// TODO Auto-generated method stub
return null;
}
public void remove() {
// TODO Auto-generated method stub
}
}
// 深度优先迭代
private class DfsIterator extends GraphIterator {
public DfsIterator() {
super();
}
public Vertex next() {
return dfs.get(count++);
}
}
// 广度优先迭代
private class BfsIterator extends GraphIterator {
public BfsIterator() {
super();
}
public Object next() {
return bfs.get(count++);
}
}
}
package linkListGraph;
/*
* 深度优先遍历需要借助栈保存当前访问过的顶点
*/
public class StackX {
//private int size=20;
private Vertex[] stackArray;//用数组实现栈的存储(理论上链栈效率更高)
private int top;
public StackX(int size){
stackArray=new Vertex[size];
top=-1;
}
public Vertex pop(){
return stackArray[top--];
}
public Vertex peek(){
return stackArray[top];
}
public boolean isEmpty(){
return top==-1;
}
public void push(Vertex vertex) {
// TODO Auto-generated method stub
stackArray[++top]=vertex;
}
}
本程序是基于图的邻接表存储方式实现的。遗憾的是没有实现带权图,有实现带权图的朋友欢迎留言指教!或加Q:374741295
package linkListGraph;
import java.util.ArrayList;
import java.util.Iterator;
/**
* @ClassName: Graph
* @Description: 图结构实现,封装了图的dfs、bfs遍历算法
* @author zhoupengcheng
* @version 2015年5月17日下午5:07:34
*/
public class Graph {
private ArrayList<Vertex> vertexList;// 用一个ArrayList保存图中的所有结点
private boolean isDirected = false;// 标记是否为有向图
private int nVerts = 0;// 保存总的顶点数
private StackX theStack;// 深度优先搜寻时使用
private Queue theQueue; // 广度优先搜索时使用
private ArrayList<Vertex> bfs;// 在bfs函数中使用,保存bfs得到的结果序列
private ArrayList<Vertex> dfs;// 在dfs函数中使用,保存dfs得到的结果序列
public Graph() {
vertexList = new ArrayList<Vertex>();
dfs = new ArrayList<Vertex>();
bfs = new ArrayList<Vertex>();
}
public Graph(boolean is) {
this();
this.isDirected = is;
}
public boolean isDirected() {
return this.isDirected;
}
public ArrayList<Vertex> getVertexList() {
return vertexList;
}
public ArrayList<Vertex> getDFS() {
return dfs;
}
public ArrayList<Vertex> getBFS() {
return bfs;
}
public void addVertex(Vertex vertex) {
vertex.setIndex(nVerts);
vertexList.add(vertex);
nVerts++;
}
public void addEdge(int start, int end) {
vertexList.get(start).addAdj(vertexList.get(end));
if (!isDirected) {
vertexList.get(end).addAdj(vertexList.get(start));
}
}
public int getVertsCount() {
return nVerts;
}
//深度优先迭代器
public Iterator dfsIterator(){
dfs();
return new DfsIterator();
}
//广度优先迭代器
public Iterator bfsIterator(){
bfs();
return new BfsIterator();
}
// 打印邻接表
public void displayGraph() {
for (int i = 0; i < vertexList.size(); i++) {
printVertx(vertexList.get(i));
}
}
public void printVertx(Vertex vertex) {
ArrayList<Vertex> next = vertex.getAdj();
if (next == null) {
System.out.println(vertex.toString() + " 无邻接点!");
} else {
System.out.print(vertex.toString() + "邻接表:");
for (int i = 0; i < next.size(); i++) {
System.out.print(next.get(i).label + " ");
}
System.out.println();
}
}
// 深度优先遍历
public void dfs() {
theStack = new StackX(nVerts);
vertexList.get(0).wasVisted = true;
dfs.add(vertexList.get(0));
theStack.push(vertexList.get(0));
Vertex vertex;
while (!theStack.isEmpty()) {
vertex = getAdjVertex((Vertex) theStack.peek());
if (vertex == null) {
theStack.pop();
} else {
vertex.wasVisted = true;
dfs.add(vertex);
theStack.push(vertex);
}
}
// ------遍历完成,清除所有访问标志位--------
for (int i = 0; i < getVertsCount(); i++) {
vertexList.get(i).wasVisted = false;
}
}
// 广度优先遍历
public void bfs() {
theQueue = new Queue(nVerts);
vertexList.get(0).wasVisted = true;
bfs.add(vertexList.get(0));
theQueue.insert(vertexList.get(0));
Vertex vertex1;
while (!theQueue.isEmpty()) {
Vertex vertex2 = (Vertex) theQueue.remove();
while ((vertex1 = getAdjVertex(vertex2)) != null) {
vertex1.wasVisted = true;
bfs.add(vertex1);
theQueue.insert(vertex1);
}
}
// ------遍历完成,清除所有访问标志位--------
for (int i = 0; i < getVertsCount(); i++) {
vertexList.get(i).wasVisted = false;
}
}
// 返回vertex顶点的一个未曾访问过的邻接点
public Vertex getAdjVertex(Vertex vertex) {
ArrayList<Vertex> adjVertexs = vertex.getAdj();
for (int i = 0; i < adjVertexs.size(); i++) {
if (!adjVertexs.get(i).wasVisted) {
return adjVertexs.get(i);
}
}
return null;
}
//专门写个迭代器来遍历结果
private abstract class GraphIterator implements Iterator {
int count = 0;
public GraphIterator() {
}
public boolean hasNext() {
return count != getVertsCount() ;
}
public Object next() {
// TODO Auto-generated method stub
return null;
}
public void remove() {
// TODO Auto-generated method stub
}
}
// 深度优先迭代
private class DfsIterator extends GraphIterator {
public DfsIterator() {
super();
}
public Vertex next() {
return dfs.get(count++);
}
}
// 广度优先迭代
private class BfsIterator extends GraphIterator {
public BfsIterator() {
super();
}
public Object next() {
return bfs.get(count++);
}
}
}
package linkListGraph;
import java.util.Iterator;
public class GraphApp {
public static void main(String[] args) {
Graph myGraph = new Graph();
Vertex vertex;
myGraph.addVertex(new Vertex('A'));//位置为0
myGraph.addVertex(new Vertex('B'));//位置为1
myGraph.addVertex(new Vertex('C'));//位置为2
myGraph.addVertex(new Vertex('D'));//位置为3
myGraph.addVertex(new Vertex('E'));//位置为4
myGraph.addVertex(new Vertex('F'));//位置为5
myGraph.addVertex(new Vertex('G'));//位置为6
myGraph.addVertex(new Vertex('H'));//位置为7
myGraph.addVertex(new Vertex('I'));//位置为8
myGraph.addVertex(new Vertex('J'));//位置为9
myGraph.addVertex(new Vertex('K'));//位置为10
myGraph.addEdge(0, 1);
myGraph.addEdge(0, 2);
myGraph.addEdge(0, 3);
myGraph.addEdge(1, 4);
myGraph.addEdge(1, 5);
myGraph.addEdge(3, 7);
myGraph.addEdge(3, 10);
myGraph.addEdge(4, 6);
myGraph.addEdge(5, 6);
myGraph.addEdge(5, 9);
myGraph.addEdge(7, 8);
myGraph.addEdge(8, 10);
myGraph.displayGraph();
System.out.println("深度优先迭代遍历:");
for (Iterator iterator = myGraph.dfsIterator(); iterator.hasNext();) {
vertex = (Vertex) iterator.next();
System.out.println(vertex.toString());
}
System.out.println("广度优先迭代遍历:");
for (Iterator iterator = myGraph.bfsIterator(); iterator.hasNext();) {
vertex = (Vertex) iterator.next();
System.out.println(vertex.toString());
}
}
}package linkListGraph;
import java.util.ArrayList;
/**
* @ClassName: Vertex
* @Description: 顶点类,表示图中存储的顶点
* @author zhoupengcheng
* @version 2015年5月17日下午4:31:54
*/
public class Vertex {
public char label;
public boolean wasVisted;
public int indexId;//顶点的标号
//由于采用"邻接表"方式表示图,所以每个顶点对象持有一个邻接表adjList
private ArrayList<Vertex> adjacentList = null;
public Vertex(char lab) // constructor
{
this.label = lab;
this.wasVisted = false;
}
// 为节点添加邻接点
public void addAdj(Vertex ver) {
if (adjacentList == null)
adjacentList = new ArrayList<Vertex>();
adjacentList.add(ver);
}
//返回一个顶点的邻接表,在遍历图时需根据邻接表找下一个节点
public ArrayList<Vertex> getAdj() {
return this.adjacentList;
}
public void setIndex(int index) {
this.indexId = index;
}
public String toString() {
return "顶点 :" + label+" ";
}
}package linkListGraph;
/*
* 深度优先遍历需要借助栈保存当前访问过的顶点
*/
public class StackX {
//private int size=20;
private Vertex[] stackArray;//用数组实现栈的存储(理论上链栈效率更高)
private int top;
public StackX(int size){
stackArray=new Vertex[size];
top=-1;
}
public Vertex pop(){
return stackArray[top--];
}
public Vertex peek(){
return stackArray[top];
}
public boolean isEmpty(){
return top==-1;
}
public void push(Vertex vertex) {
// TODO Auto-generated method stub
stackArray[++top]=vertex;
}
}
package linkListGraph;
/*
* 广度优先需要借助队列保存当前已经访问过的顶点
*/
public class Queue {
private int maxSize=20;
private int front;//队头指针
private int rear;//队尾指针
private Vertex[] queArray;//用数组实现队列的存储(理论上链队列效率更高)
public Queue(int size) {
this.maxSize=size;
queArray = new Vertex[maxSize];
front = 0;
rear = -1;
}
public void insert(Vertex value) {
if (rear == maxSize - 1)
rear = -1;
queArray[++rear] = value;
}
// 返回被删除的元素
public Vertex remove() {
if (front == maxSize)
front = 0;
Vertex temp = queArray[front++];
return temp;
}
public boolean isEmpty() {
return (rear+1==front||(front+maxSize-1==rear));
}
}

相关文章推荐
- 22.基于 邻接表 表示的 深度优先搜索dfs 和 广度优先搜索bfs
- 广度优先搜索BFS——图邻接表表示
- 【数据结构】邻接表表示法的图的深度广度优先遍历递归和非递归遍历
- DFS--深度优先搜索--图的邻接表表示
- DFS--深度优先搜索--图的邻接表表示
- 图——广度优先遍历和深度优先遍历——邻接表表示法
- 图的邻接表表示法及深度搜索与广度搜索
- 基于C++ STL图的邻接表表示及深度、广度搜索实现
- 图基本算法 图搜索基于邻接表的(广度优先、深度优先)
- 图的深度优先和广度优先遍历(图以邻接表表示,由C++面向对象实现)
- 数据结构--图--图的数组存储表示,深度优先搜索遍历和广度优先搜索遍历
- 深度优先搜索DFS——图邻接表表示
- 邻接矩阵的广度优先搜索和深度优先搜索
- 广度优先搜索求树的深度
- 图邻接表存储 深度优先和广度优先遍历
- 数据结构——图的邻接表的广度优先搜索
- matlab练习程序(广度优先搜索BFS、深度优先搜索DFS)
- 算法——基本的图算法:广度优先搜索、深度优先搜索
- [置顶] 图:图的邻接表创建、深度优先遍历和广度优先遍历代码实现
- 深度优先搜索和广度优先搜索的比较与分析