Spark-1.3.1集群环境搭建
2015-05-13 16:32
267 查看
一、实践环境
Ubuntu14.04 + JDK1.8.0_25 + Hadoop2.5.1+Scala2.11.6+Spark1.3.1
一共三台linux机器(virtualbox虚拟机,桥接网络配置静态ip),已经部署好hadoop完全分布式环境。
二、安装scala
1.下载scala-2.11.6.tgz
2.将scala-2.11.6.tgz解压到/home/jsj/scala目录下。
3.配置环境变量
sudo gedit /etc/profile

source /etc/profile
验证:
scala –version
三、安装spark
1.下载spark-1.3.1-bin-hadoop2.4.tgz
2.将spark-1.3.1-bin-hadoop2.4.tgz解压到/home/jsj/spark目录下。
3.配置环境变量
sudo gedit /etc/profile

source /etc/profile
4.修改/home/jsj/spark/spark-1.3.1-bin-hadoop2.4/conf目录下的配置文件
修改spark-env.sh如下:
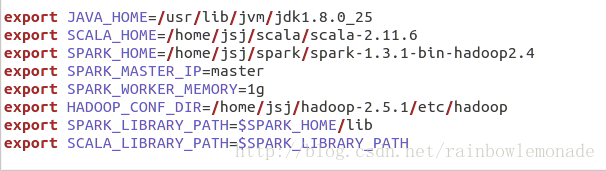
修改slaves文件如下:

四、复制到其他节点
将master节点上的scala和spark复制到其他节点,使用命令:
scp –r /home/jsj/scalajsj@slave1:/home/jsj/scala
scp –r /home/jsj/scalajsj@slave2:/home/jsj/scala
scp –r /home/jsj/sparkjsj@slave1:/home/jsj/spark
scp –r /home/jsj/sparkjsj@slave2:/home/jsj/spark
五、启动Hadoop和Spark
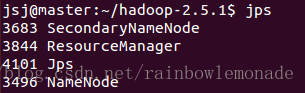
1.在hadoop目录下执行命令sbin/start-all.sh启动hadoop,jps命令查看运行状态:
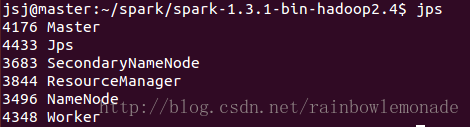
2.在spark目录下执行命令sbin/start-all.sh启动spark,jps命令查看运行状态:
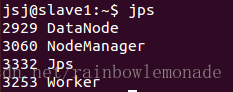
3.在slave节点上使用jps命令查看运行状态:
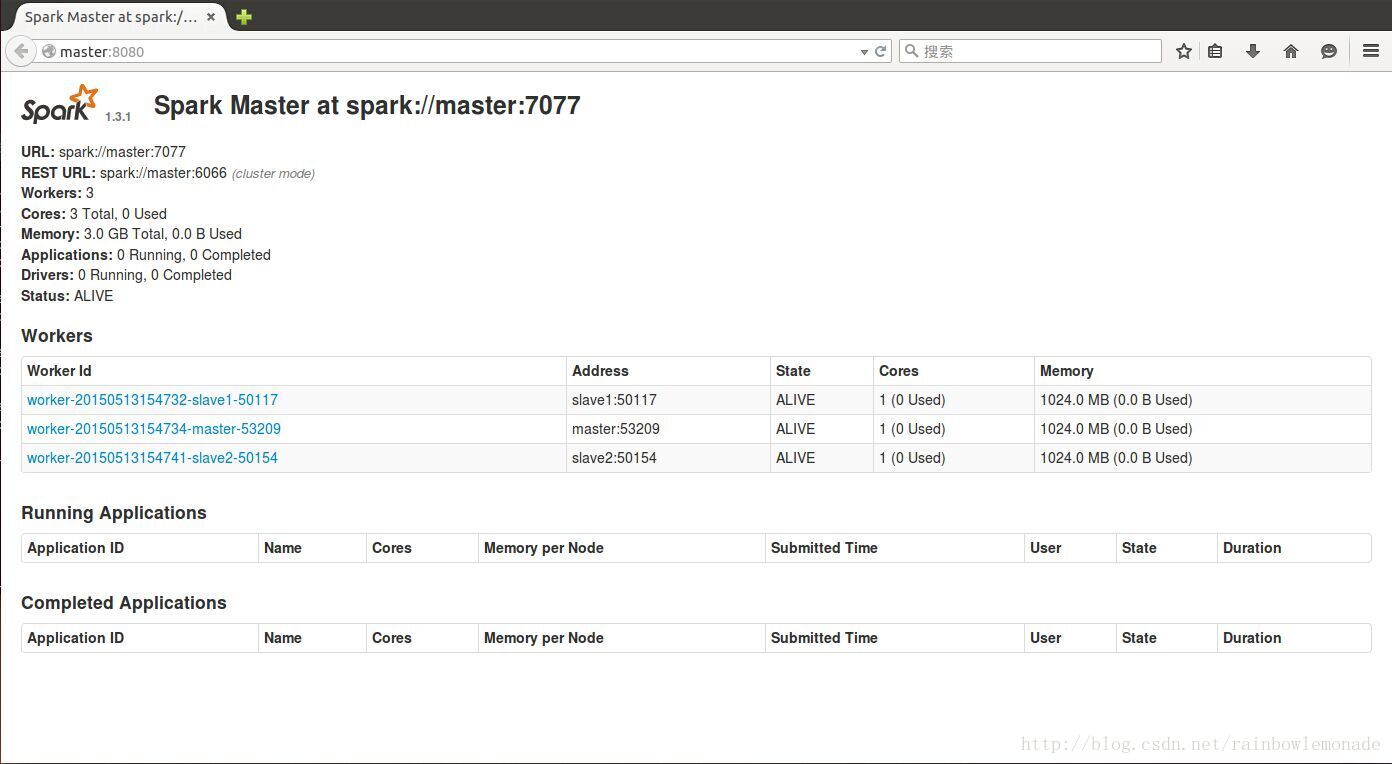
4.打开浏览器查看集群状况:
Ubuntu14.04 + JDK1.8.0_25 + Hadoop2.5.1+Scala2.11.6+Spark1.3.1
一共三台linux机器(virtualbox虚拟机,桥接网络配置静态ip),已经部署好hadoop完全分布式环境。
二、安装scala
1.下载scala-2.11.6.tgz
2.将scala-2.11.6.tgz解压到/home/jsj/scala目录下。
3.配置环境变量
sudo gedit /etc/profile
source /etc/profile
验证:
scala –version
三、安装spark
1.下载spark-1.3.1-bin-hadoop2.4.tgz
2.将spark-1.3.1-bin-hadoop2.4.tgz解压到/home/jsj/spark目录下。
3.配置环境变量
sudo gedit /etc/profile
source /etc/profile
4.修改/home/jsj/spark/spark-1.3.1-bin-hadoop2.4/conf目录下的配置文件
修改spark-env.sh如下:
修改slaves文件如下:
四、复制到其他节点
将master节点上的scala和spark复制到其他节点,使用命令:
scp –r /home/jsj/scalajsj@slave1:/home/jsj/scala
scp –r /home/jsj/scalajsj@slave2:/home/jsj/scala
scp –r /home/jsj/sparkjsj@slave1:/home/jsj/spark
scp –r /home/jsj/sparkjsj@slave2:/home/jsj/spark
五、启动Hadoop和Spark
1.在hadoop目录下执行命令sbin/start-all.sh启动hadoop,jps命令查看运行状态:
2.在spark目录下执行命令sbin/start-all.sh启动spark,jps命令查看运行状态:
3.在slave节点上使用jps命令查看运行状态:
4.打开浏览器查看集群状况:

相关文章推荐
- spark1.3.1安装和集群的搭建
- hadoop spark 大数据集群环境搭建(一)
- Spark1.2集群环境搭建(Standalone+HA) 4G内存5个节点也是蛮拼的
- Spark 1.6.1分布式集群环境搭建
- spark2.2.0集群环境搭建
- spark 1.3.1以上的集群搭建流程
- Spark集群环境搭建
- Spark 分布式集群环境搭建
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十二)Spark Streaming接收流数据及使用窗口函数
- Spark1.2集群环境搭建(Standalone+HA) 4G内存5个节点也是蛮拼的
- CentOS7下 Hadoop2.7.3+Spark2.1.0 集群环境搭建(1NN+2DN)
- spark1.3.0-hadoop2.4集群环境搭建(Standalone)
- hadoop-2.7.4+hbase-1.3.1+zookeeper-3.4.9搭建分布式集群环境
- spark standalone 集群环境搭建
- 基于虚拟机的spark集群开发环境的搭建
- spark-1.2.0 集群环境搭建
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十六)Structured Streaming:WARN clients.NetworkClient: Error while fetching metadata with correlation id 1 : {my-topic=LEADER_NOT_AVAILABLE}
- CentOS7下 Hadoop2.7.3+Spark2.1.0 集群环境搭建(1NN+2DN)
- 6,数据挖掘环境搭建-Spark集群搭建
- hadoop-2.7.4+hbase-1.3.1+zookeeper-3.4.9搭建分布式集群环境