深入了解webkit内核第一篇:JavaScript引擎深度解析
2015-03-31 11:09
573 查看
看到HorkeyChen写的文章《[WebKit] JavaScriptCore解析--基础篇(三)从脚本代码到JIT编译的代码实现》,写的很好,深受启发。想补充一些Horkey没有写到的细节比如字节码是如何生成的等等,为此成文。
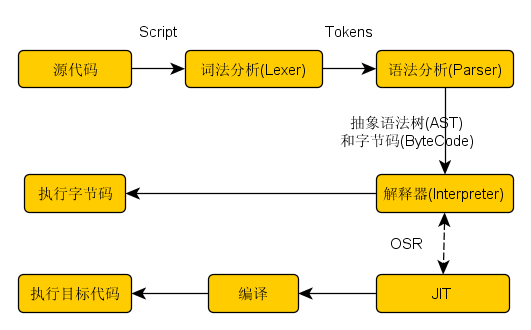
JSC对JavaScript的处理,其实与Webkit对CSS的处理许多地方是类似的,它这么几个部分:
(1)词法分析->出来词语(Token);
(2)语法分析->出来抽象语法树(AST:Abstract Syntax Tree);
(3)遍历抽象语法树->生成字节码(Bytecode);
(4)用解释器(LLInt:Low Level Interpreter)执行字节码;
(5)如果性能不够好就用Baseline JIT编译字节码生成机器码、然后执行此机器码;
(6)如果性能还不够好,就用DFG JIT重新编译字节码生成更好的机器码、然后执行此机器码;
(7)最后,如果还不好,就祭出重器--虚拟器(LLVM:Low Level Virtual Machine)来编译DFG的中间表示代码、生成更高优化的机器码并执行。接下来,我将会用一下系列文章描述此过程。
其中,步骤1、2是类似的,3、4、5步的思想,CSS JIT也是采用类似方法,请参考[1]。想写写JSC的文章,用菜鸟和愚公移山的方式,敲开JSC的冰山一角。
本篇主要描述词法和语法解析的细节。
一、 JavaScriptCore的词法分析器工作流程分析
W3C是这么解释词法和语法工作流程的:

词法器Tokenizer的工作过程如下,就是不断从字符串中寻找一个个的词(Token),比如找到连续的“true”字符串,就创建一个TokenTrue。词法器工作过程如下:
JavaScriptCore/interpreter/interpreter.cpp:
template <typename CharType>
?
?
经过此过程,一个完整的JSC世界的Token就生成了。然后,再进行语法分析,生成抽象语法树.

JavaScriptCore/parser/parser.cpp:
?
?
UString Parser<LexerType>::parseInner()
?
}
举例说来,根据Token的类型,JSC认为输入的Token是一个常量声明,就会使用如下的模板函数生成语法节点(Node),然后放入ASTBuilder里面:
接下来,就会调用BytecodeGenerator::generate生成字节码,具体分下节分析。我们先看看下面来自JavaScript的一个个语法树节点生成字节码的过程:
JavaScriptCore/bytecompiler/NodeCodeGen.cpp:
RegisterID* BooleanNode::emitBytecode(BytecodeGenerator& generator, RegisterID* dst)
第一时间获得博客更新提醒,以及更多技术信息分享,欢迎关注个人微信公众平台:程序员互动联盟(coder_online)
1.直接帮你解答wekit技术疑点
2.第一时间获得业内十多个领域技术文章
3.针对文章内疑点提出问题,第一时间回复你,帮你耐心解答
4.让你和原创作者成为很好的朋友,拓展自己的人脉资源
扫一扫下方二维码或搜索微信号coder_online即可关注,我们可以在线交流。

引用:
1 https://www.webkit.org/blog/3271/webkit-css-selector-jit-compiler/
2 http://blog.csdn.net/horkychen/article/details/8928578
JSC对JavaScript的处理,其实与Webkit对CSS的处理许多地方是类似的,它这么几个部分:
(1)词法分析->出来词语(Token);
(2)语法分析->出来抽象语法树(AST:Abstract Syntax Tree);
(3)遍历抽象语法树->生成字节码(Bytecode);
(4)用解释器(LLInt:Low Level Interpreter)执行字节码;
(5)如果性能不够好就用Baseline JIT编译字节码生成机器码、然后执行此机器码;
(6)如果性能还不够好,就用DFG JIT重新编译字节码生成更好的机器码、然后执行此机器码;
(7)最后,如果还不好,就祭出重器--虚拟器(LLVM:Low Level Virtual Machine)来编译DFG的中间表示代码、生成更高优化的机器码并执行。接下来,我将会用一下系列文章描述此过程。
其中,步骤1、2是类似的,3、4、5步的思想,CSS JIT也是采用类似方法,请参考[1]。想写写JSC的文章,用菜鸟和愚公移山的方式,敲开JSC的冰山一角。
本篇主要描述词法和语法解析的细节。
一、 JavaScriptCore的词法分析器工作流程分析
W3C是这么解释词法和语法工作流程的:
词法器Tokenizer的工作过程如下,就是不断从字符串中寻找一个个的词(Token),比如找到连续的“true”字符串,就创建一个TokenTrue。词法器工作过程如下:
JavaScriptCore/interpreter/interpreter.cpp:
template <typename CharType>
?
JavaScriptCore/parser/parser.cpp:
?
?
举例说来,根据Token的类型,JSC认为输入的Token是一个常量声明,就会使用如下的模板函数生成语法节点(Node),然后放入ASTBuilder里面:
接下来,就会调用BytecodeGenerator::generate生成字节码,具体分下节分析。我们先看看下面来自JavaScript的一个个语法树节点生成字节码的过程:
JavaScriptCore/bytecompiler/NodeCodeGen.cpp:
RegisterID* BooleanNode::emitBytecode(BytecodeGenerator& generator, RegisterID* dst)
第一时间获得博客更新提醒,以及更多技术信息分享,欢迎关注个人微信公众平台:程序员互动联盟(coder_online)
1.直接帮你解答wekit技术疑点
2.第一时间获得业内十多个领域技术文章
3.针对文章内疑点提出问题,第一时间回复你,帮你耐心解答
4.让你和原创作者成为很好的朋友,拓展自己的人脉资源
扫一扫下方二维码或搜索微信号coder_online即可关注,我们可以在线交流。
引用:
1 https://www.webkit.org/blog/3271/webkit-css-selector-jit-compiler/
2 http://blog.csdn.net/horkychen/article/details/8928578

相关文章推荐
- 深入了解webkit内核第一篇:JavaScript引擎深度解析
- 深入了解webkit内核第一篇:JavaScript引擎深度解析
- 深入了解webkit内核第一篇:JavaScript引擎深度解析
- 深入理解webkit内核系列第二篇:JavaScript引擎深度解析
- [WebKit内核] JavaScript引擎深度解析--基础篇(一)字节码生成及语法树的构建详情分析
- [WebKit内核] JavaScriptCore深度解析--基础篇(一)字节码生成及语法树的构建详情分析
- [WebKit内核]JavaScriptCore深度解析-基础篇(一)字节码生成及语法树构建详情分析
- [WebKit内核] JavaScriptCore深度解析--基础篇(一)字节码生成及语法树的构建详情分析
- [WebKit内核] JavaScriptCore深度解析--基础篇(一)字节码生成及语法树的构建详情分析
- [WebKit内核] JavaScriptCore深度解析--基础篇(一)字节码生成及语法树的构建详情分析
- [WebKit内核] JavaScriptCore深度解析--基础篇(一)字节码生成及语法树的构建
- [WebKit内核] JavaScriptCore深度解析--基础篇(一)字节码生成及语法树的构建详情分析
- 深入理解webkit内核系列第一篇:如何快速编译
- MySQL存储引擎之Spider内核深度解析
- MySQL存储引擎之Spider内核深度解析
- MySQL存储引擎之Spider内核深度解析
- MySQL存储引擎之Spider内核深度解析
- MySQL存储引擎之Spider内核深度解析
- 深入解析JavaScript一:你真的了解作用域?
- 深入解析windows XP/2003:内核模式和用户模式