快速排序 优化 详细分析
2015-03-07 09:30
204 查看
目录(?)[+]
看了编程珠玑Programming Perls第11章关于快速排序的讨论,发现自己长年用库函数,已经忘了快排怎么写。于是整理下思路和资料,把至今所了解的快排的方方面面记录与此。
时间复杂度分析
具体实现细节
划分
选取枢纽元
固定位置
随机选取
三数取中
分割
单向扫描
双向扫描
Hoare的双向扫描
改进的双向扫描
双向扫描的其他问题
分治
尾递归
参考文献
首先选取一个枢纽元(pivot),然后将数据划分成左右两部分,左边的大于(或等于)枢纽元,右边的小于(或等于枢纽元),最后递归处理左右两部分。
分治算法一般分成三个部分:分解、解决以及合并。快排是就地排序,所以就不需要合并了。只需要划分(partition)和解决(递归)两个步骤。因为划分的结果决定递归的位置,所以Partition是整个算法的核心。
对数组S排序的形式化的描述如下(REF[1]):
如果S中的元素个数是0或1,则返回
取S中任意一元素v,称之为枢纽元
将S-{v}(S中其余元素),划分成两个不相交的集合:S1={x∈S-{v}|x<=v} 和 S2={x∈S-{v}|x>=v}
返回{quicksort(S1) , v , quicksort(S2)}
选取枢纽元的不同, 决定了快排算法时间复杂度的数量级;
划分方法的划分方法总是O(n), 所以其具体实现的不同只影响算法时间复杂度的系数。
所以诉时间复杂度的分析都是围绕枢纽元的位置展开讨论的。

划分又分成两个步骤:选取枢纽元
和按枢纽元将数组分成左右两部
同样是为了方便,将选取枢纽元单独提出来成一个函数:select_pivot(T A[], int p, int q),该函数从A[p...q]中选取一个枢纽元并返回,且枢纽元放置在左端(A[p]的位置)。
对于完全随机的数据,枢纽元的选取不是很重要,往往直接取左端的元素作为枢纽元。

但是实际应用中,数据往往是部分有序的,如果仍用两端的元素最为枢纽元,则会产生很不好的划分,使算法退化成O(n^2)。所以要采用一些手段避免这种情况,我知道的有“随机选取法”和“三数取中法”。
随机选取
顾名思义就是从A[p...q]中随机选择一个枢纽元,这个用库函数可以很容易实现

其中randInt(p, q)随机返回[p, q]中的一个数,C/C++里可由stdlib.h中的rand函数模拟。
三数取中
即取三个元素的中间数作为枢纽元,一般是取左端、右断和中间三个数,也可以随机选取。(REF[1])

常见的分割方法有三种:
单向扫描
单向扫描代码非常简单,只有短短的几行,思路也比较清晰。该算法由N.Lomuto提出,算法导论上也采用了这种算法。对于数组A[p...q], 该算法用一个循环扫描整个区间,并维护一个标志m,使得循环不变量(loop invariant)A[p+1...m] < A[p] && A[m+1, i-1] >= x[l]始终成立。(REF[2],REF[3])

顺便废话几句,在看国外的书的时候,发现老外在分析和测试算法尤其是循环时,非常重视不变量(invariant)的使用。确立一个不变量,在循环开始之前和结束之后检查这个不变量,是一个很好的保持算法正确性的手段。
事实上第一种算法需要的交换次数比较多,而且如果采用选取左端元素作为枢纽元的方法,该算法在输入数组中元素全部相同时退化成O(n^2)。第二种方法可以避免这个问题。
双向扫描
双向扫描用两个标志i、j,分别初始化成数组的两端。主循环里嵌套两个内循环:第一个内循环i从左向右移过小于枢纽元的元素,遇到大元素时停止;第二个循环j从右向左移过大于枢纽元的元素,遇到小元素时停止。然后主循环检查i、j是否相交并交换A[i]、A[j]。

双向扫描可以正常处理所有元素相同的情况,而且交换次数比单向扫描要少。
Hoare的双向扫描
这种方法是Hoare在62年最初提出快速排序采用的方法,与前面的双向扫描基本相同,但是更难理解,手算了几组数据才搞明白:(REF[2])

需要注意的是,返回值j并不是枢纽元的位置,但是仍然保证了A[p..j] <= A[j+1...q]。这种方法在效率上于双向扫描差别甚微,只是代码相对更为紧凑,并且用A[p]做哨兵元素减少了内层循环的一个if测试。
http://www.see2say.com/channel/music/player.aspx?v_album_id=9804
改进的双向扫描
枢纽元保存在一个临时变量中,这样左端的位置可视为空闲。j从右向左扫描,直到A[j]小于等于枢纽元,检查i、j是否相交并将A[j]赋给空闲位 置A[i],这时A[j]变成空闲位置;i从左向右扫描,直到A[i]大于等于枢纽元,检查i、j是否相交并将A[i]赋给空闲位置A[j],然后 A[i]变成空闲位置。重复上述过程,最后直到i、j相交跳出循环。最后把枢纽元放到空闲位置上。

这种类似迭代的方法,每次只需一次赋值,减少了内存读写次数,而前面几种的方法一次交换需要三次赋值操作。由于没有哨兵元素,不得不在内层循环里判 断i、j是否相交,实际上反而增加了很多内存读取操作。但是由于循环计数器往往被放在寄存器了,而如果待排数组很大,访问其元素会频繁的cache miss,所以用计数器的访问次数换取待排数组的访存是值得的。
关于双向扫描的几个问题
1.内层循环中的while测试是用“严格大于/小于”还是”大于等于/小于等于”。
一般的想法是用大于等于/小于等于,忽略与枢纽元相同的元素,这样可以减少不必要的交换,因为这些元素无论放在哪一边都是一样的。但是如果遇到所有 元素都一样的情况,这种方法每次都会产生最坏的划分,也就是一边1个元素,令一边n-1个元素,使得时间复杂度变成O(N^2)。而如果用严格大于/小 于,虽然两边指针每此只挪动1位,但是它们会在正中间相遇,产生一个最好的划分,时间复杂度为log(2,n)。
另一个因素是,如果将枢纽元放在数组两端,用严格大于/小于就可以将枢纽元作为一个哨兵元素,从而减少内层循环的一个测试。
由以上两点,内层循环中的while测试一般用“严格大于/小于”。
2.对于小数组特殊处理
按照上面的方法,递归会持续到分区只有一个元素。而事实上,当分割到一定大小后,继续分割的效率比插入排序要差。由统计方法得到的数值是50左右(REF[3]),也有采用20的(REF[1]), 这样原先的QuickSort就可以写成这样。
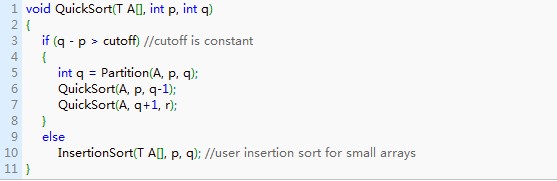
采用这种方法可以缩减堆栈深度,由原来的O(n)缩减为O(logn)。

目录(?)[+]
看了编程珠玑Programming Perls第11章关于快速排序的讨论,发现自己长年用库函数,已经忘了快排怎么写。于是整理下思路和资料,把至今所了解的快排的方方面面记录与此。
时间复杂度分析
具体实现细节
划分
选取枢纽元
固定位置
随机选取
三数取中
分割
单向扫描
双向扫描
Hoare的双向扫描
改进的双向扫描
双向扫描的其他问题
分治
尾递归
参考文献
首先选取一个枢纽元(pivot),然后将数据划分成左右两部分,左边的大于(或等于)枢纽元,右边的小于(或等于枢纽元),最后递归处理左右两部分。
分治算法一般分成三个部分:分解、解决以及合并。快排是就地排序,所以就不需要合并了。只需要划分(partition)和解决(递归)两个步骤。因为划分的结果决定递归的位置,所以Partition是整个算法的核心。
对数组S排序的形式化的描述如下(REF[1]):
如果S中的元素个数是0或1,则返回
取S中任意一元素v,称之为枢纽元
将S-{v}(S中其余元素),划分成两个不相交的集合:S1={x∈S-{v}|x<=v} 和 S2={x∈S-{v}|x>=v}
返回{quicksort(S1) , v , quicksort(S2)}
选取枢纽元的不同, 决定了快排算法时间复杂度的数量级;
划分方法的划分方法总是O(n), 所以其具体实现的不同只影响算法时间复杂度的系数。
所以诉时间复杂度的分析都是围绕枢纽元的位置展开讨论的。
划分又分成两个步骤:选取枢纽元
和按枢纽元将数组分成左右两部
同样是为了方便,将选取枢纽元单独提出来成一个函数:select_pivot(T A[], int p, int q),该函数从A[p...q]中选取一个枢纽元并返回,且枢纽元放置在左端(A[p]的位置)。
对于完全随机的数据,枢纽元的选取不是很重要,往往直接取左端的元素作为枢纽元。
但是实际应用中,数据往往是部分有序的,如果仍用两端的元素最为枢纽元,则会产生很不好的划分,使算法退化成O(n^2)。所以要采用一些手段避免这种情况,我知道的有“随机选取法”和“三数取中法”。
随机选取
顾名思义就是从A[p...q]中随机选择一个枢纽元,这个用库函数可以很容易实现
其中randInt(p, q)随机返回[p, q]中的一个数,C/C++里可由stdlib.h中的rand函数模拟。
三数取中
即取三个元素的中间数作为枢纽元,一般是取左端、右断和中间三个数,也可以随机选取。(REF[1])
常见的分割方法有三种:
单向扫描
单向扫描代码非常简单,只有短短的几行,思路也比较清晰。该算法由N.Lomuto提出,算法导论上也采用了这种算法。对于数组A[p...q], 该算法用一个循环扫描整个区间,并维护一个标志m,使得循环不变量(loop invariant)A[p+1...m] < A[p] && A[m+1, i-1] >= x[l]始终成立。(REF[2],REF[3])
顺便废话几句,在看国外的书的时候,发现老外在分析和测试算法尤其是循环时,非常重视不变量(invariant)的使用。确立一个不变量,在循环开始之前和结束之后检查这个不变量,是一个很好的保持算法正确性的手段。
事实上第一种算法需要的交换次数比较多,而且如果采用选取左端元素作为枢纽元的方法,该算法在输入数组中元素全部相同时退化成O(n^2)。第二种方法可以避免这个问题。
双向扫描
双向扫描用两个标志i、j,分别初始化成数组的两端。主循环里嵌套两个内循环:第一个内循环i从左向右移过小于枢纽元的元素,遇到大元素时停止;第二个循环j从右向左移过大于枢纽元的元素,遇到小元素时停止。然后主循环检查i、j是否相交并交换A[i]、A[j]。
双向扫描可以正常处理所有元素相同的情况,而且交换次数比单向扫描要少。
Hoare的双向扫描
这种方法是Hoare在62年最初提出快速排序采用的方法,与前面的双向扫描基本相同,但是更难理解,手算了几组数据才搞明白:(REF[2])
需要注意的是,返回值j并不是枢纽元的位置,但是仍然保证了A[p..j] <= A[j+1...q]。这种方法在效率上于双向扫描差别甚微,只是代码相对更为紧凑,并且用A[p]做哨兵元素减少了内层循环的一个if测试。
http://www.see2say.com/channel/music/player.aspx?v_album_id=9804
改进的双向扫描
枢纽元保存在一个临时变量中,这样左端的位置可视为空闲。j从右向左扫描,直到A[j]小于等于枢纽元,检查i、j是否相交并将A[j]赋给空闲位 置A[i],这时A[j]变成空闲位置;i从左向右扫描,直到A[i]大于等于枢纽元,检查i、j是否相交并将A[i]赋给空闲位置A[j],然后 A[i]变成空闲位置。重复上述过程,最后直到i、j相交跳出循环。最后把枢纽元放到空闲位置上。
这种类似迭代的方法,每次只需一次赋值,减少了内存读写次数,而前面几种的方法一次交换需要三次赋值操作。由于没有哨兵元素,不得不在内层循环里判 断i、j是否相交,实际上反而增加了很多内存读取操作。但是由于循环计数器往往被放在寄存器了,而如果待排数组很大,访问其元素会频繁的cache miss,所以用计数器的访问次数换取待排数组的访存是值得的。
关于双向扫描的几个问题
1.内层循环中的while测试是用“严格大于/小于”还是”大于等于/小于等于”。
一般的想法是用大于等于/小于等于,忽略与枢纽元相同的元素,这样可以减少不必要的交换,因为这些元素无论放在哪一边都是一样的。但是如果遇到所有 元素都一样的情况,这种方法每次都会产生最坏的划分,也就是一边1个元素,令一边n-1个元素,使得时间复杂度变成O(N^2)。而如果用严格大于/小 于,虽然两边指针每此只挪动1位,但是它们会在正中间相遇,产生一个最好的划分,时间复杂度为log(2,n)。
另一个因素是,如果将枢纽元放在数组两端,用严格大于/小于就可以将枢纽元作为一个哨兵元素,从而减少内层循环的一个测试。
由以上两点,内层循环中的while测试一般用“严格大于/小于”。
2.对于小数组特殊处理
按照上面的方法,递归会持续到分区只有一个元素。而事实上,当分割到一定大小后,继续分割的效率比插入排序要差。由统计方法得到的数值是50左右(REF[3]),也有采用20的(REF[1]), 这样原先的QuickSort就可以写成这样。
采用这种方法可以缩减堆栈深度,由原来的O(n)缩减为O(logn)。
看了编程珠玑Programming Perls第11章关于快速排序的讨论,发现自己长年用库函数,已经忘了快排怎么写。于是整理下思路和资料,把至今所了解的快排的方方面面记录与此。
纲要
算法描述时间复杂度分析
具体实现细节
划分
选取枢纽元
固定位置
随机选取
三数取中
分割
单向扫描
双向扫描
Hoare的双向扫描
改进的双向扫描
双向扫描的其他问题
分治
尾递归
参考文献
一、算法描述(Algorithm Description)
快速排序由C.A.R.Hoare于1962年提出,算法相当简单精炼,基本策略是随机分治。首先选取一个枢纽元(pivot),然后将数据划分成左右两部分,左边的大于(或等于)枢纽元,右边的小于(或等于枢纽元),最后递归处理左右两部分。
分治算法一般分成三个部分:分解、解决以及合并。快排是就地排序,所以就不需要合并了。只需要划分(partition)和解决(递归)两个步骤。因为划分的结果决定递归的位置,所以Partition是整个算法的核心。
对数组S排序的形式化的描述如下(REF[1]):
如果S中的元素个数是0或1,则返回
取S中任意一元素v,称之为枢纽元
将S-{v}(S中其余元素),划分成两个不相交的集合:S1={x∈S-{v}|x<=v} 和 S2={x∈S-{v}|x>=v}
返回{quicksort(S1) , v , quicksort(S2)}
二、时间复杂度分析(Time Complexity)
快速排序最佳运行时间O(nlogn),最坏运行时间O(N^2),随机化以后期望运行时间O(nlogn),关于这些任何一本算法数据结构书上都有证明,就不写在这了,一下两点很重要:选取枢纽元的不同, 决定了快排算法时间复杂度的数量级;
划分方法的划分方法总是O(n), 所以其具体实现的不同只影响算法时间复杂度的系数。
所以诉时间复杂度的分析都是围绕枢纽元的位置展开讨论的。
三、具体实现细节(Details of Implementaion)
1、划分(Partirion)
为了方便讨论,将Partition从QuickSort函数里提出来,就像算法导论里一样。实际实现时我更倾向于合并在一起,就一个函数,减少了函数调用次数。划分又分成两个步骤:选取枢纽元
和按枢纽元将数组分成左右两部
a.选取枢纽元(Pivot Selection)
固定位置同样是为了方便,将选取枢纽元单独提出来成一个函数:select_pivot(T A[], int p, int q),该函数从A[p...q]中选取一个枢纽元并返回,且枢纽元放置在左端(A[p]的位置)。
对于完全随机的数据,枢纽元的选取不是很重要,往往直接取左端的元素作为枢纽元。
但是实际应用中,数据往往是部分有序的,如果仍用两端的元素最为枢纽元,则会产生很不好的划分,使算法退化成O(n^2)。所以要采用一些手段避免这种情况,我知道的有“随机选取法”和“三数取中法”。
随机选取
顾名思义就是从A[p...q]中随机选择一个枢纽元,这个用库函数可以很容易实现
其中randInt(p, q)随机返回[p, q]中的一个数,C/C++里可由stdlib.h中的rand函数模拟。
三数取中
即取三个元素的中间数作为枢纽元,一般是取左端、右断和中间三个数,也可以随机选取。(REF[1])
b.按枢纽元将数组分成左右两部分
虽然说分割方法只影响算法时间复杂度的系数,但是一个好系数也是比较重要的。这也就是为什么实际应用中宁愿选择可能退化成O(n^2)的快速排序,也不用稳定的堆排序(堆排序交换次数太多,导致系数很大)。常见的分割方法有三种:
单向扫描
单向扫描代码非常简单,只有短短的几行,思路也比较清晰。该算法由N.Lomuto提出,算法导论上也采用了这种算法。对于数组A[p...q], 该算法用一个循环扫描整个区间,并维护一个标志m,使得循环不变量(loop invariant)A[p+1...m] < A[p] && A[m+1, i-1] >= x[l]始终成立。(REF[2],REF[3])
顺便废话几句,在看国外的书的时候,发现老外在分析和测试算法尤其是循环时,非常重视不变量(invariant)的使用。确立一个不变量,在循环开始之前和结束之后检查这个不变量,是一个很好的保持算法正确性的手段。
事实上第一种算法需要的交换次数比较多,而且如果采用选取左端元素作为枢纽元的方法,该算法在输入数组中元素全部相同时退化成O(n^2)。第二种方法可以避免这个问题。
双向扫描
双向扫描用两个标志i、j,分别初始化成数组的两端。主循环里嵌套两个内循环:第一个内循环i从左向右移过小于枢纽元的元素,遇到大元素时停止;第二个循环j从右向左移过大于枢纽元的元素,遇到小元素时停止。然后主循环检查i、j是否相交并交换A[i]、A[j]。
双向扫描可以正常处理所有元素相同的情况,而且交换次数比单向扫描要少。
Hoare的双向扫描
这种方法是Hoare在62年最初提出快速排序采用的方法,与前面的双向扫描基本相同,但是更难理解,手算了几组数据才搞明白:(REF[2])
需要注意的是,返回值j并不是枢纽元的位置,但是仍然保证了A[p..j] <= A[j+1...q]。这种方法在效率上于双向扫描差别甚微,只是代码相对更为紧凑,并且用A[p]做哨兵元素减少了内层循环的一个if测试。
http://www.see2say.com/channel/music/player.aspx?v_album_id=9804
改进的双向扫描
枢纽元保存在一个临时变量中,这样左端的位置可视为空闲。j从右向左扫描,直到A[j]小于等于枢纽元,检查i、j是否相交并将A[j]赋给空闲位 置A[i],这时A[j]变成空闲位置;i从左向右扫描,直到A[i]大于等于枢纽元,检查i、j是否相交并将A[i]赋给空闲位置A[j],然后 A[i]变成空闲位置。重复上述过程,最后直到i、j相交跳出循环。最后把枢纽元放到空闲位置上。
这种类似迭代的方法,每次只需一次赋值,减少了内存读写次数,而前面几种的方法一次交换需要三次赋值操作。由于没有哨兵元素,不得不在内层循环里判 断i、j是否相交,实际上反而增加了很多内存读取操作。但是由于循环计数器往往被放在寄存器了,而如果待排数组很大,访问其元素会频繁的cache miss,所以用计数器的访问次数换取待排数组的访存是值得的。
关于双向扫描的几个问题
1.内层循环中的while测试是用“严格大于/小于”还是”大于等于/小于等于”。
一般的想法是用大于等于/小于等于,忽略与枢纽元相同的元素,这样可以减少不必要的交换,因为这些元素无论放在哪一边都是一样的。但是如果遇到所有 元素都一样的情况,这种方法每次都会产生最坏的划分,也就是一边1个元素,令一边n-1个元素,使得时间复杂度变成O(N^2)。而如果用严格大于/小 于,虽然两边指针每此只挪动1位,但是它们会在正中间相遇,产生一个最好的划分,时间复杂度为log(2,n)。
另一个因素是,如果将枢纽元放在数组两端,用严格大于/小于就可以将枢纽元作为一个哨兵元素,从而减少内层循环的一个测试。
由以上两点,内层循环中的while测试一般用“严格大于/小于”。
2.对于小数组特殊处理
按照上面的方法,递归会持续到分区只有一个元素。而事实上,当分割到一定大小后,继续分割的效率比插入排序要差。由统计方法得到的数值是50左右(REF[3]),也有采用20的(REF[1]), 这样原先的QuickSort就可以写成这样。
二、分治
分治这里看起来没什么可说的,就是一枢纽元为中心,左右递归,实际上也有一些技巧。1.尾递归(Tail recursion)
快排算法和大多数分治排序算法一样,都有两次递归调用。但是快排与归并排序不同,归并的递归则在函数一开始, 快排的递归在函数尾部,这就使得快排代码可以实施尾递归优化。第一次递归以后,变量p就没有用处了, 也就是说第二次递归可以用迭代控制结构代替。虽然这种优化一般是有编译器实施,但是也可以人为的模拟:采用这种方法可以缩减堆栈深度,由原来的O(n)缩减为O(logn)。
目录(?)[+]
看了编程珠玑Programming Perls第11章关于快速排序的讨论,发现自己长年用库函数,已经忘了快排怎么写。于是整理下思路和资料,把至今所了解的快排的方方面面记录与此。
纲要
算法描述时间复杂度分析
具体实现细节
划分
选取枢纽元
固定位置
随机选取
三数取中
分割
单向扫描
双向扫描
Hoare的双向扫描
改进的双向扫描
双向扫描的其他问题
分治
尾递归
参考文献
一、算法描述(Algorithm Description)
快速排序由C.A.R.Hoare于1962年提出,算法相当简单精炼,基本策略是随机分治。首先选取一个枢纽元(pivot),然后将数据划分成左右两部分,左边的大于(或等于)枢纽元,右边的小于(或等于枢纽元),最后递归处理左右两部分。
分治算法一般分成三个部分:分解、解决以及合并。快排是就地排序,所以就不需要合并了。只需要划分(partition)和解决(递归)两个步骤。因为划分的结果决定递归的位置,所以Partition是整个算法的核心。
对数组S排序的形式化的描述如下(REF[1]):
如果S中的元素个数是0或1,则返回
取S中任意一元素v,称之为枢纽元
将S-{v}(S中其余元素),划分成两个不相交的集合:S1={x∈S-{v}|x<=v} 和 S2={x∈S-{v}|x>=v}
返回{quicksort(S1) , v , quicksort(S2)}
二、时间复杂度分析(Time Complexity)
快速排序最佳运行时间O(nlogn),最坏运行时间O(N^2),随机化以后期望运行时间O(nlogn),关于这些任何一本算法数据结构书上都有证明,就不写在这了,一下两点很重要:选取枢纽元的不同, 决定了快排算法时间复杂度的数量级;
划分方法的划分方法总是O(n), 所以其具体实现的不同只影响算法时间复杂度的系数。
所以诉时间复杂度的分析都是围绕枢纽元的位置展开讨论的。
三、具体实现细节(Details of Implementaion)
1、划分(Partirion)
为了方便讨论,将Partition从QuickSort函数里提出来,就像算法导论里一样。实际实现时我更倾向于合并在一起,就一个函数,减少了函数调用次数。划分又分成两个步骤:选取枢纽元
和按枢纽元将数组分成左右两部
a.选取枢纽元(Pivot Selection)
固定位置同样是为了方便,将选取枢纽元单独提出来成一个函数:select_pivot(T A[], int p, int q),该函数从A[p...q]中选取一个枢纽元并返回,且枢纽元放置在左端(A[p]的位置)。
对于完全随机的数据,枢纽元的选取不是很重要,往往直接取左端的元素作为枢纽元。
但是实际应用中,数据往往是部分有序的,如果仍用两端的元素最为枢纽元,则会产生很不好的划分,使算法退化成O(n^2)。所以要采用一些手段避免这种情况,我知道的有“随机选取法”和“三数取中法”。
随机选取
顾名思义就是从A[p...q]中随机选择一个枢纽元,这个用库函数可以很容易实现
其中randInt(p, q)随机返回[p, q]中的一个数,C/C++里可由stdlib.h中的rand函数模拟。
三数取中
即取三个元素的中间数作为枢纽元,一般是取左端、右断和中间三个数,也可以随机选取。(REF[1])
b.按枢纽元将数组分成左右两部分
虽然说分割方法只影响算法时间复杂度的系数,但是一个好系数也是比较重要的。这也就是为什么实际应用中宁愿选择可能退化成O(n^2)的快速排序,也不用稳定的堆排序(堆排序交换次数太多,导致系数很大)。常见的分割方法有三种:
单向扫描
单向扫描代码非常简单,只有短短的几行,思路也比较清晰。该算法由N.Lomuto提出,算法导论上也采用了这种算法。对于数组A[p...q], 该算法用一个循环扫描整个区间,并维护一个标志m,使得循环不变量(loop invariant)A[p+1...m] < A[p] && A[m+1, i-1] >= x[l]始终成立。(REF[2],REF[3])
顺便废话几句,在看国外的书的时候,发现老外在分析和测试算法尤其是循环时,非常重视不变量(invariant)的使用。确立一个不变量,在循环开始之前和结束之后检查这个不变量,是一个很好的保持算法正确性的手段。
事实上第一种算法需要的交换次数比较多,而且如果采用选取左端元素作为枢纽元的方法,该算法在输入数组中元素全部相同时退化成O(n^2)。第二种方法可以避免这个问题。
双向扫描
双向扫描用两个标志i、j,分别初始化成数组的两端。主循环里嵌套两个内循环:第一个内循环i从左向右移过小于枢纽元的元素,遇到大元素时停止;第二个循环j从右向左移过大于枢纽元的元素,遇到小元素时停止。然后主循环检查i、j是否相交并交换A[i]、A[j]。
双向扫描可以正常处理所有元素相同的情况,而且交换次数比单向扫描要少。
Hoare的双向扫描
这种方法是Hoare在62年最初提出快速排序采用的方法,与前面的双向扫描基本相同,但是更难理解,手算了几组数据才搞明白:(REF[2])
需要注意的是,返回值j并不是枢纽元的位置,但是仍然保证了A[p..j] <= A[j+1...q]。这种方法在效率上于双向扫描差别甚微,只是代码相对更为紧凑,并且用A[p]做哨兵元素减少了内层循环的一个if测试。
http://www.see2say.com/channel/music/player.aspx?v_album_id=9804
改进的双向扫描
枢纽元保存在一个临时变量中,这样左端的位置可视为空闲。j从右向左扫描,直到A[j]小于等于枢纽元,检查i、j是否相交并将A[j]赋给空闲位 置A[i],这时A[j]变成空闲位置;i从左向右扫描,直到A[i]大于等于枢纽元,检查i、j是否相交并将A[i]赋给空闲位置A[j],然后 A[i]变成空闲位置。重复上述过程,最后直到i、j相交跳出循环。最后把枢纽元放到空闲位置上。
这种类似迭代的方法,每次只需一次赋值,减少了内存读写次数,而前面几种的方法一次交换需要三次赋值操作。由于没有哨兵元素,不得不在内层循环里判 断i、j是否相交,实际上反而增加了很多内存读取操作。但是由于循环计数器往往被放在寄存器了,而如果待排数组很大,访问其元素会频繁的cache miss,所以用计数器的访问次数换取待排数组的访存是值得的。
关于双向扫描的几个问题
1.内层循环中的while测试是用“严格大于/小于”还是”大于等于/小于等于”。
一般的想法是用大于等于/小于等于,忽略与枢纽元相同的元素,这样可以减少不必要的交换,因为这些元素无论放在哪一边都是一样的。但是如果遇到所有 元素都一样的情况,这种方法每次都会产生最坏的划分,也就是一边1个元素,令一边n-1个元素,使得时间复杂度变成O(N^2)。而如果用严格大于/小 于,虽然两边指针每此只挪动1位,但是它们会在正中间相遇,产生一个最好的划分,时间复杂度为log(2,n)。
另一个因素是,如果将枢纽元放在数组两端,用严格大于/小于就可以将枢纽元作为一个哨兵元素,从而减少内层循环的一个测试。
由以上两点,内层循环中的while测试一般用“严格大于/小于”。
2.对于小数组特殊处理
按照上面的方法,递归会持续到分区只有一个元素。而事实上,当分割到一定大小后,继续分割的效率比插入排序要差。由统计方法得到的数值是50左右(REF[3]),也有采用20的(REF[1]), 这样原先的QuickSort就可以写成这样。
二、分治
分治这里看起来没什么可说的,就是一枢纽元为中心,左右递归,实际上也有一些技巧。1.尾递归(Tail recursion)
快排算法和大多数分治排序算法一样,都有两次递归调用。但是快排与归并排序不同,归并的递归则在函数一开始, 快排的递归在函数尾部,这就使得快排代码可以实施尾递归优化。第一次递归以后,变量p就没有用处了, 也就是说第二次递归可以用迭代控制结构代替。虽然这种优化一般是有编译器实施,但是也可以人为的模拟:采用这种方法可以缩减堆栈深度,由原来的O(n)缩减为O(logn)。

相关文章推荐
- 快速排序 优化 详细分析
- 快速排序 优化 详细分析
- 快速排序详细分析
- 排序--快速排序--详细分析
- 快速排序的分析与优化
- 快速排序的分析与优化
- 快速排序的分析与优化
- 快速排序的复杂度分析以及使用插入排序优化的快速排序
- 快速排序优化分析
- 快速排序详细分析--单向扫描和双向扫描
- 几种常用的排序算法的分析及java实现(希尔排序,堆排序,归并排序,快速排序,选择排序,插入排序,冒泡排序)
- 快速排序不同输入规模时间复杂度分析
- 【jiasuba】笔者分析:快速优化Wi-Fi 发挥网络极致性能
- 快速排序优化
- 快速排序的性能分析
- 服务器tcp连接timewait过多优化及详细分析
- (优化处理)详细剖析Android Traceview 效率检视工具!分析程序运行速度!并讲解两种创建SDcard方式! .
- 【数据结构】 MergeSort与QuickSort的详细分析 - 归并排序、快速排序
- 【手写排序算法及优化】快速排序
- 10—(优化处理)详细剖析Android Traceview 效率检视工具!分析程序运行速度!并讲解两种创建SDcard方式!