TopicModel主题模型 - LSA(隐性语义分析)模型和其实现的早期方法SVD
2015-01-09 20:40
495 查看
http://blog.csdn.net/pipisorry/article/details/42560331
传统方法向量空间模型(VSM)的缺点
传统向量空间模型使用精确的词匹配,即精确匹配用户输入的词与向量空间中存在的词。由于一词多义(polysemy)和一义多词(synonymy)的存在,使得该模型无法提供给用户语义层面的检索。比如用户搜索”automobile”,即汽车,传统向量空间模型仅仅会返回包含”automobile”单词的页面,而实际上包含”car”单词的页面也可能是用户所需要的。
下面是LDA原始Paper[Deerwester,
S., Dumais, S. T., Furnas, G. W., Landauer, T. K., & Harshman, R.(1990). Indexing By Latent Semantic Analysis. Journal of the American Society For Information Science, 41, 391-407. 10]里举的一个例子:

上图是一个Term-Document矩阵,X代表该单词出现在对应的文件里,星号表示该词出现在查询(Query)中,当用户输入查询”IDF
in computer-based information look up” 时,用户是希望查找与信息检索中IDF(文档频率)相关的网页,按照精确词匹配的话,文档2和3分别包含查询中的两个词,因此应该被返回,而文档1不包含任何查询中的词,因此不会被返回。但我们仔细看看会发现,文档1中的access, retrieval, indexing, database这些词都是和查询相似度十分高的,其中retrieval和look up是同义词。显然,从用户的角度看,文档1应该是相关文档,应该被返回。再来看文档2:computer
information theory,虽然包含查询中的一次词information,但文档2和IDF或信息检索无关,不是用户需要的文档,不应该被返回。从以上分析可以看出,在本次检索中,和查询相关的文档1并未返回给用户,而无查询无关的文档2却返回给了用户。这就是同义词和多义词如何导致传统向量空间模型检索精确度的下降。
LSA and SVD
LSA(latent semantic analysis)潜在语义分析,也被称为LSI(latent semantic index),是Scott Deerwester, Susan T. Dumais等人在1990年提出来的一种新的索引和检索方法。该方法和传统向量空间模型(vector space model)一样使用向量来表示词(terms)和文档(documents),并通过向量间的关系(如夹角)来判断词及文档间的关系;而不同的是,LSA将词和文档映射到潜在语义空间,从而去除了原始向量空间中的一些“噪音”,提高了信息检索的精确度。LSA的基本思想就是把高维的文档降到低维空间,那个空间被称为潜在语义空间。这个映射必须是严格线性的而且是基于共现表(就是那个矩阵啦)的奇异值分解。
LSA(隐性语义分析)的目的是要从文本中发现隐含的语义维度-即“Topic”或者“Concept”。LSA的目标就是要寻找到能够很好解决实体间词法和语义关系的数据映射。我们知道,在文档的空间向量模型(VSM)中,文档被表示成由特征词出现概率组成的多维向量,这种方法的好处是可以将query和文档转化成同一空间下的向量计算相似度,可以对不同词项赋予不同的权重,在文本检索、分类、聚类问题中都得到了广泛应用,在基于贝叶斯算法及KNN算法的newsgroup18828文本分类器的J***A实现和基于Kmeans算法、MBSAS算法及DBSCAN算法的newsgroup18828文本聚类器的J***A实现系列文章中的分类聚类算法大多都是采用向量空间模型。然而,向量空间模型没有能力处理一词多义和一义多词问题,例如同义词也分别被表示成独立的一维,计算向量的余弦相似度时会低估用户期望的相似度;而某个词项有多个词义时,始终对应同一维度,因此计算的结果会高估用户期望的相似度。
原理:LSA潜在语义分析的目的,就是要找出词(terms)在文档和查询中真正的含义,也就是潜在语义,从而解决上节所描述的问题。具体说来就是对一个大型的文档集合使用一个合理的维度建模,并将词和文档都表示到该空间,比如有2000个文档,包含7000个索引词,LSA使用一个维度为100的向量空间将文档和词表示到该空间,进而在该空间进行信息检索。而将文档表示到此空间的过程就是SVD奇异值分解和降维的过程。降维是LSA分析中最重要的一步,通过降维,去除了文档中的“噪音”,也就是无关信息(比如词的误用或不相关的词偶尔出现在一起),语义结构逐渐呈现。相比传统向量空间,潜在语义空间的维度更小,语义关系更明确。
LSA方法的引入就可以减轻类似的问题。基于SVD分解,我们可以构造一个原始向量矩阵的一个低秩逼近矩阵,具体的做法是将词项文档矩阵做SVD分解

其中

是以词项(terms)为行,
文档(documents)为列做一个大矩阵. 设一共有t行d列, 矩阵的元素为词项的tf-idf值。然后把

的r个对角元素的前k个保留(最大的k个保留),
后面最小的r-k个奇异值置0, 得到

;最后计算一个近似的分解矩阵

则

在最小二乘意义下是
的最佳逼近。由于
最多包含k个非零元素,所以
的秩不超过k。通过在SVD分解近似,我们将原始的向量转化成一个低维隐含语义空间中,起到了特征降维的作用。每个奇异值对应的是每个“语义”维度的权重,将不太重要的权重置为0,只保留最重要的维度信息,去掉一些信息“nosie”,因而可以得到文档的一种更优表示形式。
/article/1368066.html
LSA的步骤:
1.
分析文档集合,建立Term-Document矩阵。
2.
对Term-Document矩阵进行奇异值分解。
3.
对SVD分解后的矩阵进行降维,也就是奇异值分解一节所提到的低阶近似。
4.
使用降维后的矩阵构建潜在语义空间,或重建Term-Document矩阵。
{这时,一个项(term)其实就是K维向量空间的的一个向量。把意义相同的项(term)做同一映射。到这里就很清楚的看出来,LSA没有建立统计学基础}
一个例子:【Introduction
to Latent Semantic Analysis】
假设文档集合如下:
Technical Memo Example
Titles:
c1: Human machine interface for Lab ABC computer applications
c2: A survey of user opinion of computer system response time
c3: The EPS user interface management system
c4: System and human system engineering testing of EPS
c5: Relation of user-perceived response time to error measurement
m1: The generation of random, binary, unordered trees
m2: The intersection graph of paths in trees
m3: Graph minors IV: Widths of trees and well-quasi-ordering
m4: Graph minors: A survey
原始的Term-Document矩阵如下:
Terms
Documents
c1 c2 c3 c4 c5 m1 m2 m3 m4
__ __ __ __ __ __ __ __ __
human 1 0 0 1 0 0 0 0 0
interface 1 0 1 0 0 0 0 0 0
computer 1 1 0 0 0 0 0 0 0
user 0 1 1 0 1 0 0 0 0
system 0 1 1 2 0 0 0 0 0
response 0 1 0 0 1 0 0 0 0
time 0 1 0 0 1 0 0 0 0
EPS 0 0 1 1 0 0 0 0 0
survey 0 1 0 0 0 0 0 0 1
trees 0 0 0 0 0 1 1 1 0
graph 0 0 0 0 0 0 1 1 1
minors 0 0 0 0 0 0 0 1 1

对其进行奇异值分解:

然后对分解后的矩阵降维,这里保留{S}的最大两个奇异值,相应的{W}{P}矩阵如图,注意{P}在公式中需要转置。(只有阴影部分需要保留,减少存储容量)
到了这一步后,我们有两种处理方法,论文Introduction
to Latent Semantic Analysis是将降维后的三个矩阵再乘起来,重新构建了{X}矩阵如下:

观察{X}矩阵和{X^}矩阵可以发现:
LSA的效果显示:{X}中human-C2值为0,因为C2中并不包含human单词,但是{X^}中human-C2为0.40,表明human和C2有一定的关系,为什么呢?因为C2:”A
survey of user opinion of computer system response time”中包含user单词,和human是近似词,因此human-C2的值被提高了。同理还可以分析其他在{X^}中数值改变了的词。以上分析方法清晰的把LSA的效果显示出来了,也就是在{X^}中呈现出了潜在语义,然后希望能创建潜在语义空间,并在该空间中检索信息。
文档和单词在潜在语义空间的坐标:这里以比较两个单词为例:设奇异值分解形式为:X
= T S DT,T代表term,s代表single
value矩阵,D代表Document,DT表示D的转置。X的两个行向量点乘的值代表了两个词在文档中共同出现的程度。
比如T1在D1中出现10词,T2在D1中出现5次,T3在D1中出现0词,那么只考虑在D1维度上的值,T1(dot)T2=50,T1(dot)T2=0,显然T1与T2更相似,T1与T3就不那么相似。那么用矩阵X(dot)XT就可以求出所有词与词的相似程度。而由奇异值分解的公式的:
X(dot)XT =
T(dot)S2(dot)TT =
TS(dot)(TS)T
上面公式表明了,我们想求X(dot)XT的(i,j)个元素时,可以点乘TS矩阵的第i和j列来表示。因此我们可以把TS矩阵的行看作是term的坐标,这个坐标就是潜在语义空间的坐标。
同理我们还可以推出XT(dot)X
= D(dot)S2(dot)DT,从而DS的行表示了文档的坐标。这时我们就可以通过向量间的夹角来判断两个对象的相似程度,方法和传统向量空间模型相同。
三个矩阵的物理含义:
A is doc-term(row-col) matrix:

第一个矩阵X中的每一列表示一类主题,其中的每个非零元素表示一个主题与一篇文章的相关性,数值越大越相关。中间的矩阵表示文章主题和keyword之间的相关性。最后一个矩阵Y中的每一列表示100个关键词,每个key
word与500,000个词的相关性。因此,我们只要对关联矩阵A进行一次奇异值分解,w 我们就可以同时完成了近义词分类和文章的分类。(同时得到每类文章和每类词的相关性)。{PS:100是A的SVD分解中的奇异值部分,也就是说有100个奇异值,物理解释为latent项数}
LSA Tutorial [LSA
Tutorial]

这就是一个矩阵,不过不太一样的是,这里的一行表示一个词在哪些title中出现了(一行就是之前说的一维feature),一列表示一个title中有哪些词,(这个矩阵其实是我们之前说的那种一行是一个sample的形式的一种转置,这个会使得我们的左右奇异向量的意义产生变化,但是不会影响我们计算的过程)。比如说T1这个title中就有guide、investing、market、stock四个词,各出现了一次,我们将这个矩阵进行SVD,得到下面的矩阵:

左奇异向量表示词的一些特性,右奇异向量表示文档的一些特性,中间的奇异值矩阵表示左奇异向量的一行与右奇异向量的一列的重要程序,数字越大越重要。
继续看这个矩阵还可以发现一些有意思的东西,首先,左奇异向量的第一列表示每一个词的出现频繁程度,虽然不是线性的,但是可以认为是一个大概的描述,比如book是0.15对应文档中出现的2次,investing是0.74对应了文档中出现了9次,rich是0.36对应文档中出现了3次;
其次,右奇异向量中一的第一行表示每一篇文档中的出现词的个数的近似,比如说,T6是0.49,出现了5个词,T2是0.22,出现了2个词。
然后我们反过头来看,我们可以将左奇异向量和右奇异向量都取后2维(之前是3维的矩阵),投影到一个平面上,可以得到:

在图上,每一个红色的点,都表示一个词,每一个蓝色的点,都表示一篇文档,这样我们可以对这些词和文档进行聚类,比如说stock 和 market可以放在一类,因为他们老是出现在一起,real和estate可以放在一类,dads,guide这种词就看起来有点孤立了,我们就不对他们进行合并了。按这样聚类出现的效果,可以提取文档集合中的近义词,这样当用户检索文档的时候,是用语义级别(近义词集合)去检索了,而不是之前的词的级别。这样一减少我们的检索、存储量,因为这样压缩的文档集合和PCA是异曲同工的,二可以提高我们的用户体验,用户输入一个词,我们可以在这个词的近义词的集合中去找,这是传统的索引无法做到的。
【强大的矩阵奇异值分解(SVD)及其应用】
【奇异值分解SVD应用——LSI】
检索文本的步骤:
用户输入的检索语句被称为伪文本,因为它也是有多个词汇构成,和文本相似。所以很自然的想法就是将该伪文本转换为文档坐标,然后通过比较该伪文档与每个文档的空间夹角,检索出该伪文本的相关文档。
设Xq表示伪文本的列向量,其中该列代表文档集合的索引词,该列的值代表伪文本中该索引词出现的次数。比如一个文档集合有索引词{T1,T2,T3},伪文本为t1,t3,t2,t1,则Xq={2,1,1}。获得Xq后,通过公式
Dq =
XqT T
S-1计算伪文档的文档坐标。其中T和S分别代表奇异分解中得到的矩阵(X
= T S DT).
Dq计算出来后,就可以迭代比较Dq和文档集合中所有文档,计算两者个cosine夹角

关键字查询
可以将查询的字符串看着一个document,后面称为查询文档,同样可以将其转换为了Term-Document矩阵,不过对此有两种方案可以选择。
方案一:根据邮件样本训练出的Term-Document矩阵,将查询文档映射成其中一列,然后利用奇异值分解的方程,计算得到其潜在因子的数值,再利用相似度算法,找出前十个最相似的邮件。
方案二:简单处理得到查询文档的Term-Document矩阵,然后根据查询文档中Term在u中找到对应的潜在因子,根据Term和Document的潜在因子的相似度进行加权,找到前十个最相似的邮件。
【Indexing by Latent Semantic Analysis - 4.2.4 Finding representations for pseudo-documents】
【基于LSA的邮件关键词查找】
LSA的python实现:
Latent Semantic Analysis in Python
Porter Stemmer - http://tartarus.org/~martin/PorterStemmer/python.txt English stop list - ftp://ftp.cs.cornell.edu/pub/smart/english.stop
LSA的C++实现:
环境Linux
gcc,使用了GNU Scientific Library【http://www.gnu.org/software/gsl/manual/html_node/】。代码http://code.google.com/p/lsa-lda/。
1.
创建Term-Document矩阵
LSA是基于向量空间模型的,因此首先需要创建一个M
x N的Term-Document矩阵,其中行表示每一个词,列表示每一个文档。而矩阵的值等于相应词的TF*IDF值。待检索的文档集合放在程序根目录下的corpus文件夹,每一个文档一个文件。首先需要创建语料的单词列表,作为T-D矩阵的列向量,每一个单词对应一个id。
循环读入每个文档,在循环的过程中,识别每一个单词,并判断该单词是否为stop
word。
接下来需要处理单词,由于英文单词有前缀和后缀,如单词的单复数(book->books),过去时(like->liked),这些词虽然形式不同但含义相同,因此要将它们处理为同一的形式,也就是单词的原型。相关的算法为Porter
Stemming[6]算法。
获得单词列表后,就可以构造T-D矩阵了,过程是依次读入每个文档,遇到单词列表中存在的词,相应的矩阵单元加1。这里用到了GSL的几个函数,用法可参考GSL手册【http://www.gnu.org/software/gsl/manual/html_node/】。
T-D矩阵创建完成。
现在已经创建了T-D矩阵,但是矩阵单元值为单词在文档中出现的频率,因此下一步是求每个单词的TF*IDF值[7]。TF代表单词在某一文档中出现的频率,IDF为inverse
document frequency,代表的含义是如果一个单词在很多文档中都出现了,那么用它来区分文档的价值就降低。具体公式:

2.
SVD分解
SVD分解使用GSL库中的gsl_linalg_SV_decomp函数
3.
降维
降维在程序你实现十分简单,也就是给矩阵(由于是对角矩阵,因此程序里表示为向量)赋值零。
4.
查询
SVD分解完成后,我们就已经获得了潜在语义空间,接下来就可以接受用户的输入,将伪文本转换到文档坐标,然后通过比较向量的夹角,找出相关文档。
奇异值SVD分解说明图例:

例如Data是32*32图像矩阵,经过SVD分解后
U\VT都是3 2*2 的矩阵,有两个奇异值。因此总数字数目是64+64+2=130。
和原数目1024=32*32相比,我们获得了几乎10倍的压缩比。
【Peter Harrington - Machine Learning in Action】
【We Recommend a Singular Value Decomposition】【我们推荐奇异值分解(SVD)】
应用:
将SVD分解降维应用到文档聚类的J***A实现数据挖掘-基于Kmeans算法、MBSAS算法及DBSCAN算法的newsgroup18828文本聚类器的J***A实现
PS:
尽管基于SVD的LSA取得了一定的成功,但是其缺乏严谨的数理统计基础,而且SVD分解非常耗时。
LSA对一词多义问题依然没有解决,仅仅解决了一义多词。因为LSA将每一个词表示为潜在语义空间中的一个点,因此一个词的多个意义在空间中对于的是一个点,没有被区分。
Problems LSA assumes the
LSA通过对潜在语义空间的建模,提高的信息检索的精确度。
而后又有人提出了PLSA(Probabilistic
latent semantic analysis)和LDA(Latent Dirichlet allocation),将LSA的思想带入到概率统计模型中:Hofmann在SIGIR’99上提出了基于概率统计的PLSA模型,并且用EM算法学习模型参数。
SVD TUTORIAL:
SVD(Singular value decomposition奇异值分解),而SVD的作用不仅仅局限于LSI,在很多地方都能见到其身影,SVD自诞生之后,其应用领域不断被发掘,可以不夸张的说如果学了线性代数而不明白SVD,基本上等于没学。快速了解或复习SVD参考这个英文tutorail:Singular
Value Decomposition Tutorial , 更推荐MIT教授Gilbert Strang的线性代数公开课和相关书籍,可以直接在网易公开课看相关章节的视频。
from:/article/1368066.html
ref:http://www.52nlp.cn/%E6%A6%82%E7%8E%87%E8%AF%AD%E8%A8%80%E6%A8%A1%E5%9E%8B%E5%8F%8A%E5%85%B6%E5%8F%98%E5%BD%A2%E7%B3%BB%E5%88%971-plsa%E5%8F%8Aem%E7%AE%97%E6%B3%95
Latent semantic analysis note(LSA)
http://www.52nlp.cn/%E5%A6%82%E4%BD%95%E8%AE%A1%E7%AE%97%E4%B8%A4%E4%B8%AA%E6%96%87%E6%A1%A3%E7%9A%84%E7%9B%B8%E4%BC%BC%E5%BA%A6%E4%B8%80
传统方法向量空间模型(VSM)的缺点
传统向量空间模型使用精确的词匹配,即精确匹配用户输入的词与向量空间中存在的词。由于一词多义(polysemy)和一义多词(synonymy)的存在,使得该模型无法提供给用户语义层面的检索。比如用户搜索”automobile”,即汽车,传统向量空间模型仅仅会返回包含”automobile”单词的页面,而实际上包含”car”单词的页面也可能是用户所需要的。
下面是LDA原始Paper[Deerwester,
S., Dumais, S. T., Furnas, G. W., Landauer, T. K., & Harshman, R.(1990). Indexing By Latent Semantic Analysis. Journal of the American Society For Information Science, 41, 391-407. 10]里举的一个例子:

上图是一个Term-Document矩阵,X代表该单词出现在对应的文件里,星号表示该词出现在查询(Query)中,当用户输入查询”IDF
in computer-based information look up” 时,用户是希望查找与信息检索中IDF(文档频率)相关的网页,按照精确词匹配的话,文档2和3分别包含查询中的两个词,因此应该被返回,而文档1不包含任何查询中的词,因此不会被返回。但我们仔细看看会发现,文档1中的access, retrieval, indexing, database这些词都是和查询相似度十分高的,其中retrieval和look up是同义词。显然,从用户的角度看,文档1应该是相关文档,应该被返回。再来看文档2:computer
information theory,虽然包含查询中的一次词information,但文档2和IDF或信息检索无关,不是用户需要的文档,不应该被返回。从以上分析可以看出,在本次检索中,和查询相关的文档1并未返回给用户,而无查询无关的文档2却返回给了用户。这就是同义词和多义词如何导致传统向量空间模型检索精确度的下降。
LSA and SVD
LSA(latent semantic analysis)潜在语义分析,也被称为LSI(latent semantic index),是Scott Deerwester, Susan T. Dumais等人在1990年提出来的一种新的索引和检索方法。该方法和传统向量空间模型(vector space model)一样使用向量来表示词(terms)和文档(documents),并通过向量间的关系(如夹角)来判断词及文档间的关系;而不同的是,LSA将词和文档映射到潜在语义空间,从而去除了原始向量空间中的一些“噪音”,提高了信息检索的精确度。LSA的基本思想就是把高维的文档降到低维空间,那个空间被称为潜在语义空间。这个映射必须是严格线性的而且是基于共现表(就是那个矩阵啦)的奇异值分解。
LSA(隐性语义分析)的目的是要从文本中发现隐含的语义维度-即“Topic”或者“Concept”。LSA的目标就是要寻找到能够很好解决实体间词法和语义关系的数据映射。我们知道,在文档的空间向量模型(VSM)中,文档被表示成由特征词出现概率组成的多维向量,这种方法的好处是可以将query和文档转化成同一空间下的向量计算相似度,可以对不同词项赋予不同的权重,在文本检索、分类、聚类问题中都得到了广泛应用,在基于贝叶斯算法及KNN算法的newsgroup18828文本分类器的J***A实现和基于Kmeans算法、MBSAS算法及DBSCAN算法的newsgroup18828文本聚类器的J***A实现系列文章中的分类聚类算法大多都是采用向量空间模型。然而,向量空间模型没有能力处理一词多义和一义多词问题,例如同义词也分别被表示成独立的一维,计算向量的余弦相似度时会低估用户期望的相似度;而某个词项有多个词义时,始终对应同一维度,因此计算的结果会高估用户期望的相似度。
原理:LSA潜在语义分析的目的,就是要找出词(terms)在文档和查询中真正的含义,也就是潜在语义,从而解决上节所描述的问题。具体说来就是对一个大型的文档集合使用一个合理的维度建模,并将词和文档都表示到该空间,比如有2000个文档,包含7000个索引词,LSA使用一个维度为100的向量空间将文档和词表示到该空间,进而在该空间进行信息检索。而将文档表示到此空间的过程就是SVD奇异值分解和降维的过程。降维是LSA分析中最重要的一步,通过降维,去除了文档中的“噪音”,也就是无关信息(比如词的误用或不相关的词偶尔出现在一起),语义结构逐渐呈现。相比传统向量空间,潜在语义空间的维度更小,语义关系更明确。
LSA方法的引入就可以减轻类似的问题。基于SVD分解,我们可以构造一个原始向量矩阵的一个低秩逼近矩阵,具体的做法是将词项文档矩阵做SVD分解
其中
是以词项(terms)为行,
文档(documents)为列做一个大矩阵. 设一共有t行d列, 矩阵的元素为词项的tf-idf值。然后把
的r个对角元素的前k个保留(最大的k个保留),
后面最小的r-k个奇异值置0, 得到
;最后计算一个近似的分解矩阵
则
在最小二乘意义下是
的最佳逼近。由于
最多包含k个非零元素,所以
的秩不超过k。通过在SVD分解近似,我们将原始的向量转化成一个低维隐含语义空间中,起到了特征降维的作用。每个奇异值对应的是每个“语义”维度的权重,将不太重要的权重置为0,只保留最重要的维度信息,去掉一些信息“nosie”,因而可以得到文档的一种更优表示形式。
/article/1368066.html
LSA的步骤:
1.
分析文档集合,建立Term-Document矩阵。
2.
对Term-Document矩阵进行奇异值分解。
3.
对SVD分解后的矩阵进行降维,也就是奇异值分解一节所提到的低阶近似。
4.
使用降维后的矩阵构建潜在语义空间,或重建Term-Document矩阵。
{这时,一个项(term)其实就是K维向量空间的的一个向量。把意义相同的项(term)做同一映射。到这里就很清楚的看出来,LSA没有建立统计学基础}
一个例子:【Introduction
to Latent Semantic Analysis】
假设文档集合如下:
Technical Memo Example
Titles:
c1: Human machine interface for Lab ABC computer applications
c2: A survey of user opinion of computer system response time
c3: The EPS user interface management system
c4: System and human system engineering testing of EPS
c5: Relation of user-perceived response time to error measurement
m1: The generation of random, binary, unordered trees
m2: The intersection graph of paths in trees
m3: Graph minors IV: Widths of trees and well-quasi-ordering
m4: Graph minors: A survey
原始的Term-Document矩阵如下:
Terms
Documents
c1 c2 c3 c4 c5 m1 m2 m3 m4
__ __ __ __ __ __ __ __ __
human 1 0 0 1 0 0 0 0 0
interface 1 0 1 0 0 0 0 0 0
computer 1 1 0 0 0 0 0 0 0
user 0 1 1 0 1 0 0 0 0
system 0 1 1 2 0 0 0 0 0
response 0 1 0 0 1 0 0 0 0
time 0 1 0 0 1 0 0 0 0
EPS 0 0 1 1 0 0 0 0 0
survey 0 1 0 0 0 0 0 0 1
trees 0 0 0 0 0 1 1 1 0
graph 0 0 0 0 0 0 1 1 1
minors 0 0 0 0 0 0 0 1 1

对其进行奇异值分解:

然后对分解后的矩阵降维,这里保留{S}的最大两个奇异值,相应的{W}{P}矩阵如图,注意{P}在公式中需要转置。(只有阴影部分需要保留,减少存储容量)
到了这一步后,我们有两种处理方法,论文Introduction
to Latent Semantic Analysis是将降维后的三个矩阵再乘起来,重新构建了{X}矩阵如下:

观察{X}矩阵和{X^}矩阵可以发现:
LSA的效果显示:{X}中human-C2值为0,因为C2中并不包含human单词,但是{X^}中human-C2为0.40,表明human和C2有一定的关系,为什么呢?因为C2:”A
survey of user opinion of computer system response time”中包含user单词,和human是近似词,因此human-C2的值被提高了。同理还可以分析其他在{X^}中数值改变了的词。以上分析方法清晰的把LSA的效果显示出来了,也就是在{X^}中呈现出了潜在语义,然后希望能创建潜在语义空间,并在该空间中检索信息。
文档和单词在潜在语义空间的坐标:这里以比较两个单词为例:设奇异值分解形式为:X
= T S DT,T代表term,s代表single
value矩阵,D代表Document,DT表示D的转置。X的两个行向量点乘的值代表了两个词在文档中共同出现的程度。
比如T1在D1中出现10词,T2在D1中出现5次,T3在D1中出现0词,那么只考虑在D1维度上的值,T1(dot)T2=50,T1(dot)T2=0,显然T1与T2更相似,T1与T3就不那么相似。那么用矩阵X(dot)XT就可以求出所有词与词的相似程度。而由奇异值分解的公式的:
X(dot)XT =
T(dot)S2(dot)TT =
TS(dot)(TS)T
上面公式表明了,我们想求X(dot)XT的(i,j)个元素时,可以点乘TS矩阵的第i和j列来表示。因此我们可以把TS矩阵的行看作是term的坐标,这个坐标就是潜在语义空间的坐标。
同理我们还可以推出XT(dot)X
= D(dot)S2(dot)DT,从而DS的行表示了文档的坐标。这时我们就可以通过向量间的夹角来判断两个对象的相似程度,方法和传统向量空间模型相同。
三个矩阵的物理含义:
A is doc-term(row-col) matrix:
第一个矩阵X中的每一列表示一类主题,其中的每个非零元素表示一个主题与一篇文章的相关性,数值越大越相关。中间的矩阵表示文章主题和keyword之间的相关性。最后一个矩阵Y中的每一列表示100个关键词,每个key
word与500,000个词的相关性。因此,我们只要对关联矩阵A进行一次奇异值分解,w 我们就可以同时完成了近义词分类和文章的分类。(同时得到每类文章和每类词的相关性)。{PS:100是A的SVD分解中的奇异值部分,也就是说有100个奇异值,物理解释为latent项数}
LSA Tutorial [LSA
Tutorial]

这就是一个矩阵,不过不太一样的是,这里的一行表示一个词在哪些title中出现了(一行就是之前说的一维feature),一列表示一个title中有哪些词,(这个矩阵其实是我们之前说的那种一行是一个sample的形式的一种转置,这个会使得我们的左右奇异向量的意义产生变化,但是不会影响我们计算的过程)。比如说T1这个title中就有guide、investing、market、stock四个词,各出现了一次,我们将这个矩阵进行SVD,得到下面的矩阵:
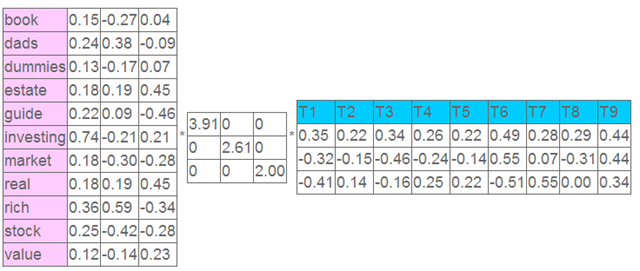
左奇异向量表示词的一些特性,右奇异向量表示文档的一些特性,中间的奇异值矩阵表示左奇异向量的一行与右奇异向量的一列的重要程序,数字越大越重要。
继续看这个矩阵还可以发现一些有意思的东西,首先,左奇异向量的第一列表示每一个词的出现频繁程度,虽然不是线性的,但是可以认为是一个大概的描述,比如book是0.15对应文档中出现的2次,investing是0.74对应了文档中出现了9次,rich是0.36对应文档中出现了3次;
其次,右奇异向量中一的第一行表示每一篇文档中的出现词的个数的近似,比如说,T6是0.49,出现了5个词,T2是0.22,出现了2个词。
然后我们反过头来看,我们可以将左奇异向量和右奇异向量都取后2维(之前是3维的矩阵),投影到一个平面上,可以得到:

在图上,每一个红色的点,都表示一个词,每一个蓝色的点,都表示一篇文档,这样我们可以对这些词和文档进行聚类,比如说stock 和 market可以放在一类,因为他们老是出现在一起,real和estate可以放在一类,dads,guide这种词就看起来有点孤立了,我们就不对他们进行合并了。按这样聚类出现的效果,可以提取文档集合中的近义词,这样当用户检索文档的时候,是用语义级别(近义词集合)去检索了,而不是之前的词的级别。这样一减少我们的检索、存储量,因为这样压缩的文档集合和PCA是异曲同工的,二可以提高我们的用户体验,用户输入一个词,我们可以在这个词的近义词的集合中去找,这是传统的索引无法做到的。
【强大的矩阵奇异值分解(SVD)及其应用】
【奇异值分解SVD应用——LSI】
检索文本的步骤:
用户输入的检索语句被称为伪文本,因为它也是有多个词汇构成,和文本相似。所以很自然的想法就是将该伪文本转换为文档坐标,然后通过比较该伪文档与每个文档的空间夹角,检索出该伪文本的相关文档。
设Xq表示伪文本的列向量,其中该列代表文档集合的索引词,该列的值代表伪文本中该索引词出现的次数。比如一个文档集合有索引词{T1,T2,T3},伪文本为t1,t3,t2,t1,则Xq={2,1,1}。获得Xq后,通过公式
Dq =
XqT T
S-1计算伪文档的文档坐标。其中T和S分别代表奇异分解中得到的矩阵(X
= T S DT).
Dq计算出来后,就可以迭代比较Dq和文档集合中所有文档,计算两者个cosine夹角

关键字查询
可以将查询的字符串看着一个document,后面称为查询文档,同样可以将其转换为了Term-Document矩阵,不过对此有两种方案可以选择。
方案一:根据邮件样本训练出的Term-Document矩阵,将查询文档映射成其中一列,然后利用奇异值分解的方程,计算得到其潜在因子的数值,再利用相似度算法,找出前十个最相似的邮件。
方案二:简单处理得到查询文档的Term-Document矩阵,然后根据查询文档中Term在u中找到对应的潜在因子,根据Term和Document的潜在因子的相似度进行加权,找到前十个最相似的邮件。
【Indexing by Latent Semantic Analysis - 4.2.4 Finding representations for pseudo-documents】
【基于LSA的邮件关键词查找】
LSA的python实现:
Latent Semantic Analysis in Python
Porter Stemmer - http://tartarus.org/~martin/PorterStemmer/python.txt English stop list - ftp://ftp.cs.cornell.edu/pub/smart/english.stop
LSA的C++实现:
环境Linux
gcc,使用了GNU Scientific Library【http://www.gnu.org/software/gsl/manual/html_node/】。代码http://code.google.com/p/lsa-lda/。
1.
创建Term-Document矩阵
LSA是基于向量空间模型的,因此首先需要创建一个M
x N的Term-Document矩阵,其中行表示每一个词,列表示每一个文档。而矩阵的值等于相应词的TF*IDF值。待检索的文档集合放在程序根目录下的corpus文件夹,每一个文档一个文件。首先需要创建语料的单词列表,作为T-D矩阵的列向量,每一个单词对应一个id。
循环读入每个文档,在循环的过程中,识别每一个单词,并判断该单词是否为stop
word。
接下来需要处理单词,由于英文单词有前缀和后缀,如单词的单复数(book->books),过去时(like->liked),这些词虽然形式不同但含义相同,因此要将它们处理为同一的形式,也就是单词的原型。相关的算法为Porter
Stemming[6]算法。
获得单词列表后,就可以构造T-D矩阵了,过程是依次读入每个文档,遇到单词列表中存在的词,相应的矩阵单元加1。这里用到了GSL的几个函数,用法可参考GSL手册【http://www.gnu.org/software/gsl/manual/html_node/】。
T-D矩阵创建完成。
现在已经创建了T-D矩阵,但是矩阵单元值为单词在文档中出现的频率,因此下一步是求每个单词的TF*IDF值[7]。TF代表单词在某一文档中出现的频率,IDF为inverse
document frequency,代表的含义是如果一个单词在很多文档中都出现了,那么用它来区分文档的价值就降低。具体公式:

2.
SVD分解
SVD分解使用GSL库中的gsl_linalg_SV_decomp函数
3.
降维
降维在程序你实现十分简单,也就是给矩阵(由于是对角矩阵,因此程序里表示为向量)赋值零。
4.
查询
SVD分解完成后,我们就已经获得了潜在语义空间,接下来就可以接受用户的输入,将伪文本转换到文档坐标,然后通过比较向量的夹角,找出相关文档。
奇异值SVD分解说明图例:
例如Data是32*32图像矩阵,经过SVD分解后
U\VT都是3 2*2 的矩阵,有两个奇异值。因此总数字数目是64+64+2=130。
和原数目1024=32*32相比,我们获得了几乎10倍的压缩比。
【Peter Harrington - Machine Learning in Action】
【We Recommend a Singular Value Decomposition】【我们推荐奇异值分解(SVD)】
应用:
将SVD分解降维应用到文档聚类的J***A实现数据挖掘-基于Kmeans算法、MBSAS算法及DBSCAN算法的newsgroup18828文本聚类器的J***A实现
PS:
尽管基于SVD的LSA取得了一定的成功,但是其缺乏严谨的数理统计基础,而且SVD分解非常耗时。
LSA对一词多义问题依然没有解决,仅仅解决了一义多词。因为LSA将每一个词表示为潜在语义空间中的一个点,因此一个词的多个意义在空间中对于的是一个点,没有被区分。
Problems LSA assumes the
Normal distribution where the
Poisson distribution has actually been observed.
LSA通过对潜在语义空间的建模,提高的信息检索的精确度。而后又有人提出了PLSA(Probabilistic
latent semantic analysis)和LDA(Latent Dirichlet allocation),将LSA的思想带入到概率统计模型中:Hofmann在SIGIR’99上提出了基于概率统计的PLSA模型,并且用EM算法学习模型参数。
SVD TUTORIAL:
SVD(Singular value decomposition奇异值分解),而SVD的作用不仅仅局限于LSI,在很多地方都能见到其身影,SVD自诞生之后,其应用领域不断被发掘,可以不夸张的说如果学了线性代数而不明白SVD,基本上等于没学。快速了解或复习SVD参考这个英文tutorail:Singular
Value Decomposition Tutorial , 更推荐MIT教授Gilbert Strang的线性代数公开课和相关书籍,可以直接在网易公开课看相关章节的视频。
from:/article/1368066.html
ref:http://www.52nlp.cn/%E6%A6%82%E7%8E%87%E8%AF%AD%E8%A8%80%E6%A8%A1%E5%9E%8B%E5%8F%8A%E5%85%B6%E5%8F%98%E5%BD%A2%E7%B3%BB%E5%88%971-plsa%E5%8F%8Aem%E7%AE%97%E6%B3%95
Latent semantic analysis note(LSA)
http://www.52nlp.cn/%E5%A6%82%E4%BD%95%E8%AE%A1%E7%AE%97%E4%B8%A4%E4%B8%AA%E6%96%87%E6%A1%A3%E7%9A%84%E7%9B%B8%E4%BC%BC%E5%BA%A6%E4%B8%80

相关文章推荐
- 主题模型TopicModel:LSA(隐性语义分析)模型和其实现的早期方法SVD
- scikit-learn:通过Non-negative matrix factorization (NMF or NNMF)实现LSA(隐含语义分析)
- 主题模型TopicModel:通过gensim实现LDA
- 利用Python gensim基于中文语料建立LSA隐性语义模型
- TopicModel主题模型 - LDA的python实现及参数选择
- scikit-learn:通过Non-negative matrix factorization (NMF or NNMF)实现LSA(隐含语义分析)
- NLP —— 图模型(三)pLSA(Probabilistic latent semantic analysis,概率隐性语义分析)模型
- 主题模型TopicModel:通过gensim实现LDA
- R语言实现LDA主题模型分析知乎话题
- 主题模型TopicModel:LDA编程实现
- 浅析机器学习的主题模型和语义分析
- scikit-learn:通过TruncatedSVD实现LSA(隐含语义分析)
- 分析的精髓之二:抽样实现“随机”的两个便捷方法
- 数组排序方法的性能比较(2):Array.Sort<T>实现分析
- 关于SPCAVIEW获取JPEG图片实现方法的分析
- 数据仓库数据库设计方法---关系模型和多维模型比较分析
- 转: VB.Net 中实现延迟的几种方法分析