Cart文本分类算法原理和例子
2014-12-05 11:30
204 查看
ID3使用信息增益作为属性选择标准,c4.5使用信息增益率作为属性选择标准。Cart算法使用GIni系数来度量对某个属性变量测试输出的狼族取值的差异性,理想的分组应该尽量使两组中样本输出变量的差异性总和达到最小,即“纯度”最大,也就是是两组输出变量取值的差异性下降最快,“纯度”增加最快。
设t为分类回归树中的某个节点,称函数
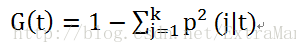
为Gini系数,k为当前属性下测试输出的类别数,p(j|t)为节点t中样本测试输出取类别j的概率。对节点t而言,G(t)越小,意味着该节点中所包含的样本越集中在某一类上,即该节点越纯,否则说明越不纯,差异性就越大。当节点样本的测试输出均取同一类别值时,输出变量取值的差异性最小,Gini系数为0,而当各类别取概率值相等时,测试输出取值的差异性最大,GIni系数也最大,为1-(1/k),其中k为目标变量的类别数。
设t为一个节点,§为该节点的一个属性分枝条件,该分支条件将该节点t中样本分别到左分支Sl和右分支Sr中,则称
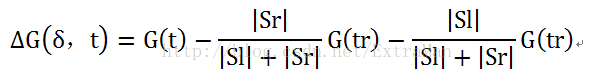
为在分支条件下节点t的差异性损失,其中,G(t)为划分前测试输出的GIni系数,|Sr|和|Sl|分辨表示划分后的左右分支的样本个数。为了使节点t尽可能的纯,我们需要选择某个属性分支条件,使该节点的差异性宣誓尽可能大。
(2)对于分类型属性,由于cart只能建立二叉树,对于多个量值得属性变量,需要将多类别合并成两个类别,形成“超类”,然后计算两“超类”,然后计算两“超类”下样本测试输出取值的差异性。
对于数值型属性,方法就是将数据按升序排序,然后从小到大一次以相邻数值的中间值作为分隔,将样本分为两组,并计算所得组中样本测试输出取值的差异性。
Cart算法的基本描述
函数名:CART(S,F)
输入:样本集数据S,属性集合F
输出:cart树
(1) if 样本S全部属于同一类别C,then
(2) 创建一个叶节点,并标记类标号C;
(3) Return;
(4) Else
(5) 计算属性集合F中每一个属性划分的差异性损失,假定差异性损失罪的大属性为A创建节点,取属性A为该节点的决策属性;
(6) 以属性A划分S得到S1和S2两个子集
(7) 递归调用Cart(S1,F);
(8) 递归调用Cart(S2,F);
例子
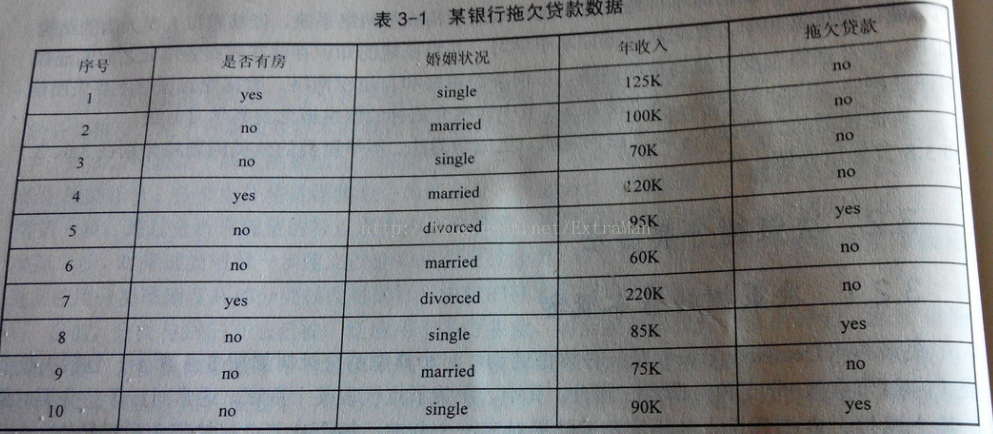
首先对数据集非类标号属性{是否有房,婚姻状况,年收入}分别计算他们的差异性损失,取差异性损失最大的属性作为决策树的根节点属性。
根节点的Gini系数
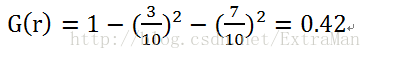
对于是否有房属性

对于婚姻状况属性
属性婚姻状况有三个可能的取值{married,single,divorced},分别计算划分后的超{married}/{single,divorce},{single}/{married,divoeced},{divorced}/{single,married}的差异性损失
(1)当分组为{married}/{single,divorce}时,Sl表示婚姻状况取值为married的分组,Sr表示婚姻状况取值为single或者divorce的分组

(2)对于分组{single}/{single,married}
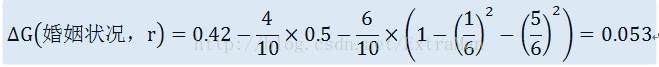
(3)对于{divorced}/{single,married}分组
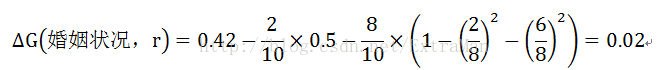
根据计算结果,属性婚姻状况划分根节点时取差异性最大的分组作为划分结果
对于年收入属性
对于年收入属性为数值型属性,首先需要对数据按升序排序,然后从小到大一次以相邻值的中间值作为分隔将样本划分为两组
下面仅仅介绍中间值65作为分割点。Sl作为年收入小于65的样本,Sr表示年收入大于等于65的样本
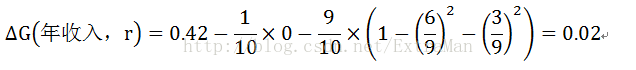

根据计算知道,三个属性划分根节点差异性损失最大的有2个:年收入属性和婚姻状况,他们的差异性损失都为0.12.此时,选取首先出现的属性作为第一次划分
第二遍
采用同样的方法,分别计算剩下属性
根节点的Gini系数为
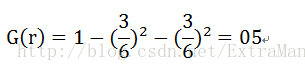
6指的是single或者divorced的数目,3就是是否贷款的数目no和yes
对于是否有房属性
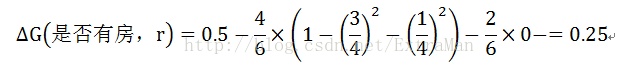
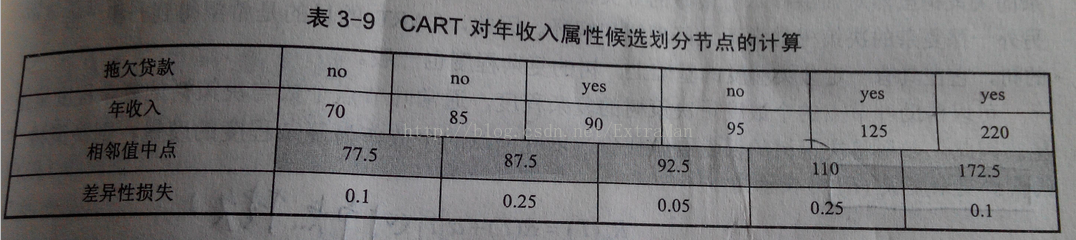
对于年收入属性
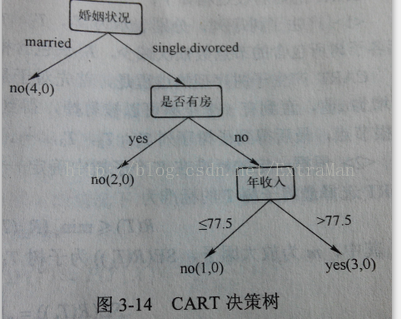
最后得出的cart树
代码实现
设t为分类回归树中的某个节点,称函数
为Gini系数,k为当前属性下测试输出的类别数,p(j|t)为节点t中样本测试输出取类别j的概率。对节点t而言,G(t)越小,意味着该节点中所包含的样本越集中在某一类上,即该节点越纯,否则说明越不纯,差异性就越大。当节点样本的测试输出均取同一类别值时,输出变量取值的差异性最小,Gini系数为0,而当各类别取概率值相等时,测试输出取值的差异性最大,GIni系数也最大,为1-(1/k),其中k为目标变量的类别数。
设t为一个节点,§为该节点的一个属性分枝条件,该分支条件将该节点t中样本分别到左分支Sl和右分支Sr中,则称
为在分支条件下节点t的差异性损失,其中,G(t)为划分前测试输出的GIni系数,|Sr|和|Sl|分辨表示划分后的左右分支的样本个数。为了使节点t尽可能的纯,我们需要选择某个属性分支条件,使该节点的差异性宣誓尽可能大。
(2)对于分类型属性,由于cart只能建立二叉树,对于多个量值得属性变量,需要将多类别合并成两个类别,形成“超类”,然后计算两“超类”,然后计算两“超类”下样本测试输出取值的差异性。
对于数值型属性,方法就是将数据按升序排序,然后从小到大一次以相邻数值的中间值作为分隔,将样本分为两组,并计算所得组中样本测试输出取值的差异性。
Cart算法的基本描述
函数名:CART(S,F)
输入:样本集数据S,属性集合F
输出:cart树
(1) if 样本S全部属于同一类别C,then
(2) 创建一个叶节点,并标记类标号C;
(3) Return;
(4) Else
(5) 计算属性集合F中每一个属性划分的差异性损失,假定差异性损失罪的大属性为A创建节点,取属性A为该节点的决策属性;
(6) 以属性A划分S得到S1和S2两个子集
(7) 递归调用Cart(S1,F);
(8) 递归调用Cart(S2,F);
例子
首先对数据集非类标号属性{是否有房,婚姻状况,年收入}分别计算他们的差异性损失,取差异性损失最大的属性作为决策树的根节点属性。
根节点的Gini系数
对于是否有房属性
对于婚姻状况属性
属性婚姻状况有三个可能的取值{married,single,divorced},分别计算划分后的超{married}/{single,divorce},{single}/{married,divoeced},{divorced}/{single,married}的差异性损失
(1)当分组为{married}/{single,divorce}时,Sl表示婚姻状况取值为married的分组,Sr表示婚姻状况取值为single或者divorce的分组
(2)对于分组{single}/{single,married}
(3)对于{divorced}/{single,married}分组
根据计算结果,属性婚姻状况划分根节点时取差异性最大的分组作为划分结果
对于年收入属性
对于年收入属性为数值型属性,首先需要对数据按升序排序,然后从小到大一次以相邻值的中间值作为分隔将样本划分为两组
下面仅仅介绍中间值65作为分割点。Sl作为年收入小于65的样本,Sr表示年收入大于等于65的样本
根据计算知道,三个属性划分根节点差异性损失最大的有2个:年收入属性和婚姻状况,他们的差异性损失都为0.12.此时,选取首先出现的属性作为第一次划分
第二遍
采用同样的方法,分别计算剩下属性
根节点的Gini系数为
6指的是single或者divorced的数目,3就是是否贷款的数目no和yes
对于是否有房属性
对于年收入属性
最后得出的cart树
代码实现

相关文章推荐
- 贝叶斯文本分类例子和原理
- 【文本分类】文本分类流程及算法原理
- 朴素贝叶斯算法文本分类原理
- [Weka]在自己的算法中调用Weka实现文本分类的一个例子
- 特征词选择算法对文本分类准确率的影响(三)
- 特征词选择算法对文本分类准确率的影响(四)
- 【转】基于朴素贝叶斯分类器的文本分类算法(下)
- 求做基于质心的半监督文本分类算法的同伴
- 一种根据关键字进行分类的文本分类算法
- 特征词选择算法对文本分类准确率的影响(二)
- 从文本分类问题中的特征词选择算法追踪如何将数学知识,数学理论迁移到实际工程中去
- 基于朴素贝叶斯分类器的文本分类算法(上)
- simhash算法的原理-用于实现文本判重复算法
- 使用weka进行文本分类的例子
- 数据挖掘十大经典算法(10) CART: 分类与回归树
- 特征词选择算法对文本分类准确率的影响(五)
- 数据挖掘十大经典算法(10) CART: 分类与回归树
- 基于朴素贝叶斯分类器的文本分类算法(下)
- 文本分类之特征简约算法说明
- 于朴素贝叶斯分类器的文本分类算法(下)