文本分类之特征简约算法说明
2010-07-20 22:16
176 查看
见 http://blog.csdn.net/aalbertini/archive/2010/07/20/5749883.aspx
用数值衡量某个特征的重要性。
1 df: 用df衡量重要性。 df就是包含该词的文档的个数 除以 文档总数
2 ig: infomation gain
信息论中有关信息量(就是“熵”)的定义。说有这么一个变量X,它可能的取值有n多种,分别是x1,x2,……,xn,每一种取到的概率分别是P1,P2,……,Pn,那么X的熵就定义为:

意思就是一个变量可能的变化越多(反而跟变量具体的取值没有任何关系,只和值的种类多少以及发生概率有关),它携带的信息量就越大(因此我一直觉得我们的政策法规信息量非常大,因为它变化很多,基本朝令夕改,笑)。
对分类系统来说,类别C是变量,它可能的取值是C1,C2,……,Cn,而每一个类别出现的概率是P(C1),P(C2),……,P(Cn),因此n就是类别的总数。此时分类系统的熵就可以表示为:

我们用T代表特征,而用t代表T出现,那么:

与刚才的式子对照一下,含义很清楚对吧,P(t)就是T出现的概率,

就是T不出现的概率。这个式子可以进一步展开,其中的

另一半就可以展开为:

因此特征T给系统带来的信息增益就可以写成系统原本的熵与固定特征T后的条件熵之差:

公式中的东西看上去很多,其实也都很好计算。比如P(Ci),表示类别Ci出现的概率,其实只要用1除以类别总数就得到了(这是说你平等的看待每个类别而忽略它们的大小时这样算,如果考虑了大小就要把大小的影响加进去)。再比如P(t),就是特征T出现的概率,只要用出现过T的文档数除以总文档数就可以了,再比如P(Ci|t)表示出现T的时候,类别Ci出现的概率,只要用出现了T并且属于类别Ci的文档数除以出现了T的文档数就可以了。
代码中的 double p = 1 + pt / total * pct + (1 - pt / total) * pnotct;
其中
1表示H(C)。因为每个类别都是一样大,所以H(C) = 2。。。???
pt/total 表示P(t);特征t出线的概率;
(1 - pt/total)表示P(t');特征t不出现的概率
http://www.360doc.com/content/10/0520/14/1472642_28554810.shtml
3 mi, mutual infomation
互信息衡量的是某个词和类别之间的统计独立关系,某个词t和某个类别Ci传统的互信息定义如下:
互信息是计算语言学模型分析的常用方法,它度量两个对象之间的相互性。在过滤问题中用于度量特征对于主题的区分度。互信息的定义与交叉嫡近似。互信息本来是信息论中的一个概念,用于表示信息之间的关系, 是两个随机变量统计相关性的测度,使用互信息理论进行特征抽取是基于如下假设:在某个特定类别出现频率高,但在其他类别出现频率比较低的词条与该类的互信息比较大。通常用互信息作为特征词和类别之问的测度,如果特征词属于该类的话,它们的互信息量最大。由于该方法不需要对特征词和类别之问关系的性质作任何假设,因此非常适合于文本分类的特征和类别的配准工作。
double itc = Math.log(tf / one / (pt / total * one / total));
// double itc = Math.log(tf * total / one * pt);
avgItc += itc * (one / total);
其中,
pt表示P(t),包含该特征的文档个数
tf/one表示类中包含该特征的文档个数, pt/total表示特征出线的概率, one/total表示类的大小
4 chi,
5 sd, standard deviation. st = Math.sqrt(st / (tfs.length - 1) ); 其中为什么要减去1? 似乎和标准差的定义不符合。。
6 是df * idf? 应该是tf * idf吧?
7 df * idf * sd? 同上, 应该是tf * idf * sd? 而且sd的求法有问题?
用数值衡量某个特征的重要性。
1 df: 用df衡量重要性。 df就是包含该词的文档的个数 除以 文档总数
2 ig: infomation gain
信息论中有关信息量(就是“熵”)的定义。说有这么一个变量X,它可能的取值有n多种,分别是x1,x2,……,xn,每一种取到的概率分别是P1,P2,……,Pn,那么X的熵就定义为:
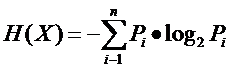
意思就是一个变量可能的变化越多(反而跟变量具体的取值没有任何关系,只和值的种类多少以及发生概率有关),它携带的信息量就越大(因此我一直觉得我们的政策法规信息量非常大,因为它变化很多,基本朝令夕改,笑)。
对分类系统来说,类别C是变量,它可能的取值是C1,C2,……,Cn,而每一个类别出现的概率是P(C1),P(C2),……,P(Cn),因此n就是类别的总数。此时分类系统的熵就可以表示为:

我们用T代表特征,而用t代表T出现,那么:
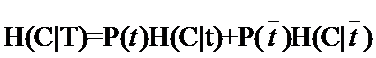
与刚才的式子对照一下,含义很清楚对吧,P(t)就是T出现的概率,

就是T不出现的概率。这个式子可以进一步展开,其中的
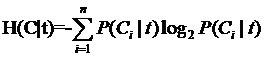
另一半就可以展开为:

因此特征T给系统带来的信息增益就可以写成系统原本的熵与固定特征T后的条件熵之差:
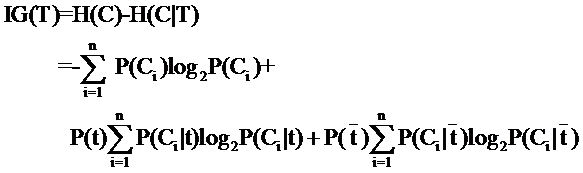
公式中的东西看上去很多,其实也都很好计算。比如P(Ci),表示类别Ci出现的概率,其实只要用1除以类别总数就得到了(这是说你平等的看待每个类别而忽略它们的大小时这样算,如果考虑了大小就要把大小的影响加进去)。再比如P(t),就是特征T出现的概率,只要用出现过T的文档数除以总文档数就可以了,再比如P(Ci|t)表示出现T的时候,类别Ci出现的概率,只要用出现了T并且属于类别Ci的文档数除以出现了T的文档数就可以了。
代码中的 double p = 1 + pt / total * pct + (1 - pt / total) * pnotct;
其中
1表示H(C)。因为每个类别都是一样大,所以H(C) = 2。。。???
pt/total 表示P(t);特征t出线的概率;
(1 - pt/total)表示P(t');特征t不出现的概率
http://www.360doc.com/content/10/0520/14/1472642_28554810.shtml
3 mi, mutual infomation
互信息衡量的是某个词和类别之间的统计独立关系,某个词t和某个类别Ci传统的互信息定义如下:
互信息是计算语言学模型分析的常用方法,它度量两个对象之间的相互性。在过滤问题中用于度量特征对于主题的区分度。互信息的定义与交叉嫡近似。互信息本来是信息论中的一个概念,用于表示信息之间的关系, 是两个随机变量统计相关性的测度,使用互信息理论进行特征抽取是基于如下假设:在某个特定类别出现频率高,但在其他类别出现频率比较低的词条与该类的互信息比较大。通常用互信息作为特征词和类别之问的测度,如果特征词属于该类的话,它们的互信息量最大。由于该方法不需要对特征词和类别之问关系的性质作任何假设,因此非常适合于文本分类的特征和类别的配准工作。
double itc = Math.log(tf / one / (pt / total * one / total));
// double itc = Math.log(tf * total / one * pt);
avgItc += itc * (one / total);
其中,
pt表示P(t),包含该特征的文档个数
tf/one表示类中包含该特征的文档个数, pt/total表示特征出线的概率, one/total表示类的大小
4 chi,
5 sd, standard deviation. st = Math.sqrt(st / (tfs.length - 1) ); 其中为什么要减去1? 似乎和标准差的定义不符合。。
6 是df * idf? 应该是tf * idf吧?
7 df * idf * sd? 同上, 应该是tf * idf * sd? 而且sd的求法有问题?

相关文章推荐
- 文本分类之特征简约
- 文本分类中的特征词选择算法系列科普(前言AND 一)
- 文本分类入门:特征选择算法之开方检验、信息增益;特征选择与特征权重计算的区别
- 从文本分类问题中的特征词选择算法追踪如何将数学知识,数学理论迁移到实际工程中去
- 文本分类入门(十)特征选择算法之开方检验
- 特征词选择算法对文本分类准确率的影响(前言)
- 短文本/Query分类算法特征选择
- 文本分类特征词选择算法科普(前言and一)
- 文本分类入门特征选择算法之开方检验
- 特征词选择算法对文本分类准确率的影响(二)
- 特征词选择算法对文本分类准确率的影响(三)
- 技术积累--常用的文本分类的特征选择算法
- 特征词选择算法对文本分类准确率的影响(四)
- 文本分类入门(十)特征选择算法之开方检验
- 特征词选择算法对文本分类准确率的影响(五)
- 短文本/Query分类算法特征选择
- 文本分类入门-特征选择算法之开方检验
- 文本分类之特征简约
- 图像基础8 图像分类——PCA 图像特征提取算法
- 【C++】基于特征向量的KNN分类算法