广义线性模型3
2014-06-20 21:24
344 查看
词袋模型和主题模型的相关讲解,如下所示:
(1)bag of words model
bag of words,也叫做“词袋”,在信息检索中,bag of words model假定对于一个文本,忽略其词序和语法,句法,将
其仅仅看做是一个词集合,或者说是词的一个组合,文本中每个词的出现都是独立的,不依赖于其他词是否出现,或
者说当这篇文章的作者在任意一个位置选择一个词汇都不受前面句子的影响而独立选择的。
词袋模型被用在文本分类的一些方法当中。当传统的贝叶斯分类被应用到文本当中时,贝叶斯中的条件独立性假设导
致词袋模型。另外一些文本分类方法,比如,LDA和LSA也使用了这个模型。
(2)词袋模型缺点
BOW在传统NLP领域取得了巨大的成功,在计算机视觉领域(Computer Vision)也开始崭露头角,但在实际应用过程
中,它却有一些不可避免的缺陷,比如:
稀疏性(Sparseness):对于大词典,尤其是包括了生僻字的词典,文档稀疏性不可避免;
多义词(Polysem):一词多义在文档中是常见的现象,BOW模型只统计单词出现的次数,而忽略了他们之间的区别;
同义词(Synonym):同样的,在不同的文档中,或者在相同的文档中,可以有多个单词表示同一个意思。
从同义词和多义词问题我们可以看到,单词也许不是文档的最基本组成元素,在单词与文档之间还有一层隐含的关
系,我们称之为主题(Topic)。我们在写文章时,首先想到的是文章的主题,然后才根据主题选择合适的单词来表达
自己的观点。在BOW模型中引入Topic的因素,成为了大家研究的方向,这就是我们要讲的Latent Semantic Analysis
(LSA)和Probabilitistic Latent Semantic Analysis(PLSA),至于更复杂的Latent Dirichlet Allocation(LDA)和众
多其他的Topic Models此处不再讨论。
(3)主题模型(Topic Model)
LFM(Latent Factor Model):隐语义模型
LFI(Latent Semantic Indexing):隐性语义索引;潜在语义索引
LFA(Latent Semantic Analysis):隐性语义分析;潜在语义分析
TM(Topic Model):话题模型;主题模型
EM(Expectation Maximization):期望最大值
PLSA(Probabilistic Latent Semantic Analysis):概率性潜在语义索引
LDA(Latent Dirichlet Allocation):隐含狄利克雷分配
LCM(Latent Class Model):隐含类别模型
LTM(Latent Topic Model):隐含主题模型
MF(Matrix Factorization):矩阵分解
PCA(Principal Component Analysis):主成分分析
FA(Factor Analysis):因子分析
ICA(Independent Component Analysis):独立成分分析
隐语义模型LFM和LSI,LDA,Topic Model其实都属于隐含语义分析技术,是一类概念,他们在本质上是相通的,都
是找出潜在的主题或分类。这些技术一开始都是在文本挖掘领域中提出来的,近些年它们也被不断应用到其他领域
中,并得到了不错的应用效果。比如,主题模型最初是运用于自然语言处理相关方向,但目前以及延伸至例如生物信
息学的其它领域。主题模型(Topic Model)在机器学习和自然语言处理等领域是用来在一系列文档中发现抽象主题的一
种统计模型。
Examples: Classification of text documents using sparse features
解析:
(1)__future__模块
从Python 2.1开始,当一个新的语言特性首次出现在发行版中时,如果该特性与旧版Python不兼容,则该特性将被默
认禁用。要启用这些特性,使用语句from __future__ import *。
Python 2.6实际已经支持新的print()语法,如下所示:
(2)logging模块
这是Python的日志模块。
(3)optparse模块
optparse是专门用来在命令行添加选项的一个模块。
(4)Pylab模块
简单理解,numpy,scipy和matplotlib的合体叫做pylab。
(5)sklearn模块
(6)__name__属性和__doc__属性
__name__属性用于判断当前模块是不是程序入口,如果当前程序正在使用,那么__name__的值为__main__。在编写程序时,通常需要给每个模块添加条件语句,用于单独测试该模块的功能。
模块本身是一个对象,而每个对象都会有一个__doc__属性,该属性用于描述该对象的作用。
解析:
(1)广义线性模型是指线性模型及其简单的推广,包括岭回归,Lasso,LAR,Logistic回归,感知器等等。
(2)常见的交叉验证形式,如下所示:
Holdout验证:常识来说,Holdout验证并非一种交叉验证,因为数据并没有交叉使用。随机从最初的样本中选出部分,形成交叉验证数据,而剩余的就当做训练数据。一般来说,少于原本样本三分之一的数据被选做验证数据。
K-fold cross-validation:K折交叉验证,初始采样分割成K个子样本,一个单独的子样本被保留作为验证模型的数据,其他K-1个样本用来训练。交叉验证重复K次,每个子样本验证一次,平均K次的结果或者使用其它结合方式,最终得到一个单一估测。这个方法的优势在于,同时重复运用随机产生的子样本进行训练和验证,每次的结果验证一次,10折交叉验证是最常用的。
留一验证:正如名称所建议,留一验证(LOOCV)意指只使用原本样本中的一项来当做验证资料,而剩余的则留下来当做训练资料。这个步骤一直持续到每个样本都被当做一次验证资料。事实上,这等同于K-fold交叉验证是一样的,其中K为原本样本个数。在某些情况下是存在有效率的算法,如使用kernel regression和Tikhonov regularization。
1.1.3 Lasso
Lasso基本思想是在回归系数的绝对值之和小于一个常数的约束条件下,使残差(eg: 残差就是实际观察值与回归估计
值的差)平方和最小,从而能够产生某些严格等于0的回归系数,得到解释力较强的模型。Lasso类使用坐标下降法
(coordinate descent)来拟合系数,如下所示:
说明:
(1)clf.coef_和clf.intercept_分别表示Lasso回归的系数和截距,根据这两个参数,我们就可以得到Lasso回归模型。
(2)正则化(Regularization)、归一化(也有称为正规化/标准化,Normalization)是对数据进行预处理的方式,他们的
目的都是为了让数据更便于我们的计算或获得更加泛化的结果,但并不改变问题的本质。
1.1.4 Multi-task Lasso
Multi-task Lasso就是多元Lasso。Lasso在多元回归中推广的tricky在于如何设置惩罚项。最小化目标函数,如下所
示:
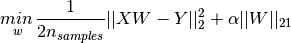
其中,
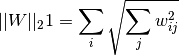
。在sklearn中的类MultiTaskLasso使用坐标轴下降法拟合系数。
1.1.5 Elastic Net
Elastic Net是Ridge和Lasso的折中,通过参数l1_ratio
(
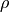
)将L1和L2范数进行结合。最小化目标函数,如下所示:
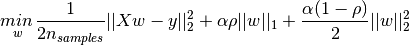
1.1.6 Least Angle Regression
LARS即最小角回归。一个针对高纬度数据的回归算法 。优点包括:(1)当维度远远大于数据点的个数时,非常有
效。(2)拥有向前选择法(forward selection)的速度,同时具有普通最小二乘法的复杂度。(3)更符合人的直
觉,比如两个相似的数据会有两个相似的结果。缺点主要是因为它是基于迭代的,所以对噪声特别敏感。
1.1.7 LARS Lasso
LassoLars是一个使用LARS算法实现的Lasso模型。相关代码,如下所示:
参考文献:
[1] bag of words model:http://zhidao.baidu.com/link?url=Zmq-EkUIF782nYYWmQ8jeCJaP7FLQljK0gqb0L-IHX8baGpxtd4liWFsTkdcY3YzAhbMtMSRuKfapEGtGnA3j_
[2] 词袋模型: http://blog.csdn.net/wanwenweifly4/article/details/6575905
[3] 主题模型:http://blog.csdn.net/huagong_adu/article/details/7937616
[4] LSA and PLSA: http://www.douban.com/note/63275934/
[5] 主题模型:http://zh.wikipedia.org/zh-cn/%E4%B8%BB%E9%A2%98%E6%A8%A1%E5%9E%8B
[6] Python: http://zh.wikipedia.org/zh-cn/Python
[7] python的日志logging模块学习: http://blog.csdn.net/yatere/article/details/6655445
[8] optparse之OptionParser: http://blog.csdn.net/yyt8yyt8/article/details/6999565
[9] python __doc__: http://blog.csdn.net/pi9nc/article/details/9397059
[10] 交叉验证:http://zh.wikipedia.org/zh-cn/%E4%BA%A4%E5%8F%89%E9%A9%97%E8%AD%89
[11] 基于Lasso特征选择的方法比较:http://www.doc88.com/p-3691023631589.html
[12] 分组最小角回归算法(group LARS):http://cos.name/2011/04/group-least-angle-regression-algorithm/
(1)bag of words model
bag of words,也叫做“词袋”,在信息检索中,bag of words model假定对于一个文本,忽略其词序和语法,句法,将
其仅仅看做是一个词集合,或者说是词的一个组合,文本中每个词的出现都是独立的,不依赖于其他词是否出现,或
者说当这篇文章的作者在任意一个位置选择一个词汇都不受前面句子的影响而独立选择的。
词袋模型被用在文本分类的一些方法当中。当传统的贝叶斯分类被应用到文本当中时,贝叶斯中的条件独立性假设导
致词袋模型。另外一些文本分类方法,比如,LDA和LSA也使用了这个模型。
(2)词袋模型缺点
BOW在传统NLP领域取得了巨大的成功,在计算机视觉领域(Computer Vision)也开始崭露头角,但在实际应用过程
中,它却有一些不可避免的缺陷,比如:
稀疏性(Sparseness):对于大词典,尤其是包括了生僻字的词典,文档稀疏性不可避免;
多义词(Polysem):一词多义在文档中是常见的现象,BOW模型只统计单词出现的次数,而忽略了他们之间的区别;
同义词(Synonym):同样的,在不同的文档中,或者在相同的文档中,可以有多个单词表示同一个意思。
从同义词和多义词问题我们可以看到,单词也许不是文档的最基本组成元素,在单词与文档之间还有一层隐含的关
系,我们称之为主题(Topic)。我们在写文章时,首先想到的是文章的主题,然后才根据主题选择合适的单词来表达
自己的观点。在BOW模型中引入Topic的因素,成为了大家研究的方向,这就是我们要讲的Latent Semantic Analysis
(LSA)和Probabilitistic Latent Semantic Analysis(PLSA),至于更复杂的Latent Dirichlet Allocation(LDA)和众
多其他的Topic Models此处不再讨论。
(3)主题模型(Topic Model)
LFM(Latent Factor Model):隐语义模型
LFI(Latent Semantic Indexing):隐性语义索引;潜在语义索引
LFA(Latent Semantic Analysis):隐性语义分析;潜在语义分析
TM(Topic Model):话题模型;主题模型
EM(Expectation Maximization):期望最大值
PLSA(Probabilistic Latent Semantic Analysis):概率性潜在语义索引
LDA(Latent Dirichlet Allocation):隐含狄利克雷分配
LCM(Latent Class Model):隐含类别模型
LTM(Latent Topic Model):隐含主题模型
MF(Matrix Factorization):矩阵分解
PCA(Principal Component Analysis):主成分分析
FA(Factor Analysis):因子分析
ICA(Independent Component Analysis):独立成分分析
隐语义模型LFM和LSI,LDA,Topic Model其实都属于隐含语义分析技术,是一类概念,他们在本质上是相通的,都
是找出潜在的主题或分类。这些技术一开始都是在文本挖掘领域中提出来的,近些年它们也被不断应用到其他领域
中,并得到了不错的应用效果。比如,主题模型最初是运用于自然语言处理相关方向,但目前以及延伸至例如生物信
息学的其它领域。主题模型(Topic Model)在机器学习和自然语言处理等领域是用来在一系列文档中发现抽象主题的一
种统计模型。
Examples: Classification of text documents using sparse features
from __future__ import print_function
import logging
import numpy as np
from optparse import OptionParser
import sys
from time import time
import pylab as pl
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import HashingVectorizer
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.linear_model import RidgeClassifier
from sklearn.svm import LinearSVC
from sklearn.linear_model import SGDClassifier
from sklearn.linear_model import Perceptron
from sklearn.linear_model import PassiveAggressiveClassifier
from sklearn.naive_bayes import BernoulliNB, MultinomialNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.neighbors import NearestCentroid
from sklearn.utils.extmath import density
from sklearn import metrics
# Display progress logs on stdout
logging.basicConfig(level=logging.INFO,
format='%(asctime)s %(levelname)s %(message)s')
......
# make some plots
indices = np.arange(len(results))
results = [[x[i] for x in results] for i in range(4)]
clf_names, score, training_time, test_time = results
training_time = np.array(training_time) / np.max(training_time)
test_time = np.array(test_time) / np.max(test_time)
pl.figure(figsize=(12,8))
pl.title("Score")
pl.barh(indices, score, .2, label="score", color='r')
pl.barh(indices + .3, training_time, .2, label="training time", color='g')
pl.barh(indices + .6, test_time, .2, label="test time", color='b')
pl.yticks(())
pl.legend(loc='best')
pl.subplots_adjust(left=.25)
pl.subplots_adjust(top=.95)
pl.subplots_adjust(bottom=.05)
for i, c in zip(indices, clf_names):
pl.text(-.3, i, c)
pl.show()解析:
(1)__future__模块
从Python 2.1开始,当一个新的语言特性首次出现在发行版中时,如果该特性与旧版Python不兼容,则该特性将被默
认禁用。要启用这些特性,使用语句from __future__ import *。
Python 2.6实际已经支持新的print()语法,如下所示:
from __future__ import print_function
print("fish", "panda", sep=', ')(2)logging模块
这是Python的日志模块。
(3)optparse模块
optparse是专门用来在命令行添加选项的一个模块。
(4)Pylab模块
简单理解,numpy,scipy和matplotlib的合体叫做pylab。
(5)sklearn模块
In [5]: import sklearn In [6]: sklearn. sklearn.base sklearn.linear_model sklearn.clone sklearn.manifold sklearn.cluster sklearn.metrics sklearn.covariance sklearn.mixture sklearn.cross_decomposition sklearn.naive_bayes sklearn.cross_validation sklearn.neighbors sklearn.datasets sklearn.pipeline sklearn.decomposition sklearn.pls sklearn.externals sklearn.preprocessing sklearn.feature_extraction sklearn.qda sklearn.feature_selection sklearn.semi_supervised sklearn.gaussian_process sklearn.setup_module sklearn.grid_search sklearn.svm sklearn.hmm sklearn.sys sklearn.isotonic sklearn.test sklearn.lda sklearn.utils以上是sklearn模块所有的子模块。
(6)__name__属性和__doc__属性
__name__属性用于判断当前模块是不是程序入口,如果当前程序正在使用,那么__name__的值为__main__。在编写程序时,通常需要给每个模块添加条件语句,用于单独测试该模块的功能。
模块本身是一个对象,而每个对象都会有一个__doc__属性,该属性用于描述该对象的作用。
解析:
(1)广义线性模型是指线性模型及其简单的推广,包括岭回归,Lasso,LAR,Logistic回归,感知器等等。
(2)常见的交叉验证形式,如下所示:
Holdout验证:常识来说,Holdout验证并非一种交叉验证,因为数据并没有交叉使用。随机从最初的样本中选出部分,形成交叉验证数据,而剩余的就当做训练数据。一般来说,少于原本样本三分之一的数据被选做验证数据。
K-fold cross-validation:K折交叉验证,初始采样分割成K个子样本,一个单独的子样本被保留作为验证模型的数据,其他K-1个样本用来训练。交叉验证重复K次,每个子样本验证一次,平均K次的结果或者使用其它结合方式,最终得到一个单一估测。这个方法的优势在于,同时重复运用随机产生的子样本进行训练和验证,每次的结果验证一次,10折交叉验证是最常用的。
留一验证:正如名称所建议,留一验证(LOOCV)意指只使用原本样本中的一项来当做验证资料,而剩余的则留下来当做训练资料。这个步骤一直持续到每个样本都被当做一次验证资料。事实上,这等同于K-fold交叉验证是一样的,其中K为原本样本个数。在某些情况下是存在有效率的算法,如使用kernel regression和Tikhonov regularization。
1.1.3 Lasso
Lasso基本思想是在回归系数的绝对值之和小于一个常数的约束条件下,使残差(eg: 残差就是实际观察值与回归估计
值的差)平方和最小,从而能够产生某些严格等于0的回归系数,得到解释力较强的模型。Lasso类使用坐标下降法
(coordinate descent)来拟合系数,如下所示:
>>> clf = linear_model.Lasso(alpha = 0.1) >>> clf.fit([[0, 0], [1, 1]], [0, 1]) Lasso(alpha=0.1, copy_X=True, fit_intercept=True, max_iter=1000, normalize=False, positive=False, precompute='auto', tol=0.0001, warm_start=False) >>> clf.predict([[1, 1]]) array([ 0.8])
说明:
(1)clf.coef_和clf.intercept_分别表示Lasso回归的系数和截距,根据这两个参数,我们就可以得到Lasso回归模型。
(2)正则化(Regularization)、归一化(也有称为正规化/标准化,Normalization)是对数据进行预处理的方式,他们的
目的都是为了让数据更便于我们的计算或获得更加泛化的结果,但并不改变问题的本质。
1.1.4 Multi-task Lasso
Multi-task Lasso就是多元Lasso。Lasso在多元回归中推广的tricky在于如何设置惩罚项。最小化目标函数,如下所
示:
其中,
。在sklearn中的类MultiTaskLasso使用坐标轴下降法拟合系数。
1.1.5 Elastic Net
Elastic Net是Ridge和Lasso的折中,通过参数l1_ratio
(
)将L1和L2范数进行结合。最小化目标函数,如下所示:
1.1.6 Least Angle Regression
LARS即最小角回归。一个针对高纬度数据的回归算法 。优点包括:(1)当维度远远大于数据点的个数时,非常有
效。(2)拥有向前选择法(forward selection)的速度,同时具有普通最小二乘法的复杂度。(3)更符合人的直
觉,比如两个相似的数据会有两个相似的结果。缺点主要是因为它是基于迭代的,所以对噪声特别敏感。
1.1.7 LARS Lasso
LassoLars是一个使用LARS算法实现的Lasso模型。相关代码,如下所示:
from sklearn import linear_model clf = linear_model.LassoLars(alpha=.1) clf.fit([[0, 0], [1, 1]], [0, 1]) LassoLars(alpha=0.1, copy_X=True, eps=..., fit_intercept=True, fit_path=True, max_iter=500, normalize=True, precompute='auto',verbose=False) clf.coef_ array([ 0.717157..., 0. ])
参考文献:
[1] bag of words model:http://zhidao.baidu.com/link?url=Zmq-EkUIF782nYYWmQ8jeCJaP7FLQljK0gqb0L-IHX8baGpxtd4liWFsTkdcY3YzAhbMtMSRuKfapEGtGnA3j_
[2] 词袋模型: http://blog.csdn.net/wanwenweifly4/article/details/6575905
[3] 主题模型:http://blog.csdn.net/huagong_adu/article/details/7937616
[4] LSA and PLSA: http://www.douban.com/note/63275934/
[5] 主题模型:http://zh.wikipedia.org/zh-cn/%E4%B8%BB%E9%A2%98%E6%A8%A1%E5%9E%8B
[6] Python: http://zh.wikipedia.org/zh-cn/Python
[7] python的日志logging模块学习: http://blog.csdn.net/yatere/article/details/6655445
[8] optparse之OptionParser: http://blog.csdn.net/yyt8yyt8/article/details/6999565
[9] python __doc__: http://blog.csdn.net/pi9nc/article/details/9397059
[10] 交叉验证:http://zh.wikipedia.org/zh-cn/%E4%BA%A4%E5%8F%89%E9%A9%97%E8%AD%89
[11] 基于Lasso特征选择的方法比较:http://www.doc88.com/p-3691023631589.html
[12] 分组最小角回归算法(group LARS):http://cos.name/2011/04/group-least-angle-regression-algorithm/

相关文章推荐
- 广义线性模型2
- 广义线性模型
- 广义线性模型分类
- 机器学习笔记—再谈广义线性模型
- [机器学习笔记]三:Generalized Linear Models(广义线性模型)
- 机器学习小组知识点39:广义线性模型(Generalized Linear Model)
- 广义线性模型(Generalized Linear Models, GLM)
- scikit-learn广义线性模型之最小二乘法
- CS229学习笔记之广义线性模型
- 牛顿方法、指数分布族、广义线性模型—斯坦福ML公开课笔记4
- scikit-learn中文文档-学习笔记二-广义线性模型
- 数据挖掘,筛选,补充的广义线性模型的---- LASSO 回归
- 机器学习笔记1_3:广义线性模型(GLM, Generalized Linear Models)
- 广义的线性模型
- 指数族分布、广义线性模型、逻辑回归前传
- 广义线性模型 GLM
- 对数线性模型之一(逻辑回归), 广义线性模型学习总结
- 关于机器学习中的广义线性模型(GLM)
- 【Scikit-Learn 中文文档】广义线性模型 - 监督学习 - 用户指南 | ApacheCN
- 【Scikit-Learn 中文文档】广义线性模型 - 监督学习 - 用户指南 | ApacheCN