NUMA2
2014-05-27 18:41
211 查看
NUMA微架构
written by qingran September 8th, 2011 1comment
现在开始补日志,逐步的扫清以前写了一半的和“欠账未还的”。半年之前开的头,今天先把NUMA说完。
PC硬件结构近5年的最大变化是多核CPU在PC上的普及,多核最常用的SMP微架构:
多个CPU之间是平等的,无主从关系(对比IBM Cell);
多个CPU平等的访问系统内存,也就是说内存是统一结构、统一寻址的(UMA,Uniform Memory Architecture);
CPU到CPU的访问必须通过系统总线。
结构如图所示:
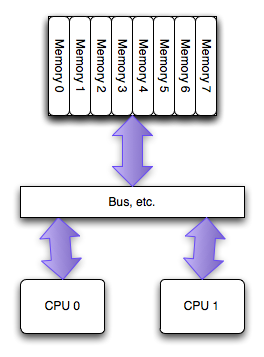
SMP的问题主要在CPU和内存之间的通信延迟较大、通信带宽受限于系统总线带宽,同时总线带宽会成为整个系统的瓶颈。
由此应运而生了NUMA架构:
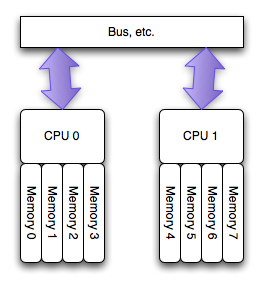
NUMA(Non-Uniform
Memory Access)是起源于AMD Opteron的微架构,同时被Intel
Nehalem采用(英特尔志强E5500以上的CPU和桌面的i3、i5、i7均基于此架构)。这也应该是继AMD64后AMD对CPU架构的又一项重要改进。
在这个架构中,每个处理器有其可以直接访问其自身的“本地”内存池,使CPU和这块儿内存之间拥有更小的延迟和更大的带宽。而且整个内存仍然可做为一个整体,可以接受来自任何CPU的访问。简言之就是CPU访问自己领地内的内存延迟最小独占带宽,访问其他的内存区域稍慢并且共享带宽。
GNU/Linux如何管理NUMA:
probe硬件,了解物理CPU数量,内存大小等;
根据物理CPU的数量(不是core)分配node,一个物理CPU对应一个node;
把属于一个node的内存模块和其node相联系;
测试各个CPU到各个内存区域的通信延迟;
在一台16GB内存,双Xeon E5620 CPU Dell R710用numactl得到以下信息:
# numactl --hardware
available: 2 nodes (0-1)
node 0 size: 8080 MB
node 0 free: 5643 MB
node 1 size: 8051 MB
node 1 free: 2294 MB
node distances:
node 0 1
0: 10 20
1: 20 10
第一列node0和node1就是对应物理CPU0和CPU1;
size就是指在此节点NUMA分配的内存总数;
free是指此节点NUMA的内存空闲数量;
node distances就是指node到各个内存节点之间的距离,默认情况10是指本地内存,21是指跨区域访问。
因为就近内存访问的快速性,所以默认情况下一个CPU只访问其所属区域的内存空间。此时造成的问题是在大内存占用的一些应用时会有CPU近线内存不够的情况,可以使用如下方式把CPU对内存区域的访问变为round robin方式。此时需要通过以下方式修改:
# echo 0 > /proc/sys/vm/zone_reclaim_mode
# numactl --interleave=all
memcached、redis、monodb等应该做以上的优化修改。
另外,如果有时间,下一篇会总结一下自己对于此问题的思考:如果自己实现一个内存池,并发挥NUMA架构的最大效能,如何设计?

相关文章推荐
- SMP MPP NUMA
- NUMA
- Linux内核学习笔记:SMP、UMA、NUMA
- NUMA的取舍
- NUMA
- SMP,UMA,NUMA
- mongodb的NUMA问题
- CPU性能监控之三-----非Numa架构的进程绑定
- Mongo部署到Win2008 上 CPU持续100%,改为 Non- NUMA 即可
- NUMA架构的CPU -- 你真的用好了么?
- Linux Shell脚本查看NUMA信息
- 为什么linux物理内存还有很多,却开始使用swap? NUMA - 罪魁祸首
- mongodb的NUMA问题
- NUMA的取舍
- NUMA体系结构详解
- NUMA和PCI相关命令
- NUMA特性禁用
- NUMA体系结构简述
- should be described in NUMA config 和 CPU feature cmt not found
- numa.h:No such file or directory 解决方法