23种设计模式分析(2):创建型模式
2014-04-04 17:50
239 查看
1.1.3 Singleton模式
保证一个类只有一个实例,并提供一个访问它的全局访问点。单例模式的要点有三个:一是某个类只能有一个实例;二是它必须自行创建这个实例;三是它必须自行向整个系统提供这个实例。UML类图如下:
图3-1 单例模式
类和对象之间的关系为:
Singleton(单例):提供了一个instance的方法,让客户可以使用它的唯一实例。内部实现只生成一个实例。
单例模式要解决的是对象的唯一性问题。由Singleton模式创建的对象在整个的应用程序的范围内,只允许有一个对象的实例存在。这样的情况在程序设计的过程中其实并不少见,比如处理JDBC请求的连接池(Connection Pool),再比如一个全局的注册表(Register),应用系统往往有且仅有一个log文件操作类实例,建立目录,或者整个系统仅有一个等待事务队列等等,这都需要使用到Singleton单例模式。
实例1: 负载均衡控制器
负载均衡器的实现就是单例模式的实例,对服务器的所以请求都通过一个了解服务器的状态对象来控制,因为个别的服务器可能会动态地开或关。这个单例的类图如下:
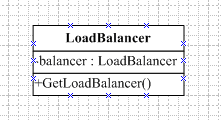
图3-2 负载均衡器
实现如下(可用于多线程环境):
import java.util.ArrayList;
import java.util.Random;
class LoadBalancer {
private static LoadBalancer balancer = null;
//服务器队列
private ArrayList<String> servers = new ArrayList<>();
private Random random = new Random();
//构造函数
protected LoadBalancer() {
servers.add("ServerI");
servers.add("ServerII");
servers.add("ServerIII");
servers.add("ServerIV");
servers.add("ServerV");
}
//返回单例,需要保证线程安全
public static synchronized LoadBalancer getInstance() {
if (balancer == null) {
balancer = new LoadBalancer();
}
return balancer;
}
public String getServer() {
int r = random.nextInt(servers.size());
return servers.get(r);
}
}
//客户应用测试
class ClientUsedForTest {
public static void main(String[] args) {
LoadBalancer b1 = LoadBalancer.getInstance();
LoadBalancer b2 = LoadBalancer.getInstance();
LoadBalancer b3 = LoadBalancer.getInstance();
LoadBalancer b4 = LoadBalancer.getInstance();
//检查是否相同,是单一实例
if ((b1 == b2) && (b2 == b3) && (b3 == b4)) {
System.out.println("Same instance");
}
//负载均衡:随机选择一个服务器来运行
System.out.println(b1.getServer());
System.out.println(b2.getServer());
System.out.println(b3.getServer());
System.out.println(b4.getServer());
}
} 在Java中,最简单的实现Singleton模式的方法是使用static修饰符,static可以用在内部类上,也可以用在方法和属性上,当一个类需要被创建成Singleton时,可以把它所有的成员都定义成static,然后再用final和private来修饰其构造函数,使其不能够被创建和重载。这在程序语法上保证了只会有一个对象实例被创建。比如java.util.Math就是这样的一个类。而好的Singleton模式所作的显然要比上面介绍的解决方法要复杂一些,也更为安全一些。它基本的思路也还是使用static变量,但是它用一个类来封装这个static变量,并拦截对象创建方法,保证只有一个对象实例被创建,这儿的关键在于使用一个private或者protected的构造函数,而且你必须提供这样的一个构造函数,否则编译器会自动的为你创建一个public的构造函数,这就达不到我们想要的目的了。
//单例模式1:非同步型
public class Singleton1 {
private static Singleton1 instance; //保存唯一实例的static变量
//为了防止对象被创建,可以为构造函数加上private修饰符,但是这同样也防止了子类的对象被
//创建,因而,可以选用protected修饰符来替代private
protected Singleton1() {
}
//static方法用来创建/访问唯一的对象实例,这儿可以对对象的创建进行控制,使得可以很容易的
//实现只允许指定个数的对象存在的泛化的Singleton模式
public static Singleton1 getInstance() {
if (instance == null) {
instance = new Singleton1(); //if模块可能会几个线程同时访问
}
return instance;
}
}这个程序在单线程下运行不会有问题,但是它不能运行在多线程的环境下,假定Thread 1 调用getInstance()方法,完成if(instance==null) 检测并且判断instance是null,然后进入if模块内的语句,在实例化instance之前,Thread 2抢占了Thread 1的CPU,Thread 2 调用getInstance() 方法,并且判断instance是null,然后进入if模块内的语句,Thread 2 实例化instance 完成,返回,Thread 1 再次实例化instance,这个单例已经不再是单例,最终一个程序可能获得n个而不是1个实例。若想让运行在多线程的环境下,最安全的方法有如下两种:
//单例模式2:静态内部类型
public class Singleton2 {
//用静态内部类
private static class Instance {
static final Singleton2 instance = new Singleton2();
}
private Singleton2() {
}
public static Singleton2 getInstance() {
return Instance.instance;
}
} 也可这样实现://单例模式3:同步方法型
public class Singleton3 {
private static Singleton3 instance = null;
private Singleton3() {
}
//用静态同步方法,保证只有一个线程能实例化instance,其他线程if模块会跳过
public static synchronized Singleton3 getInstance() {
if (instance==null)
instance = new Singleton3(); //使用时生成实例
return instance;
}
} 这种lazy initialization的形式(即推迟对象的创建、数据的计算等需要耗费较多资源的操作,只有在第一次访问的时候才执行)之所以可以,因为synchronized方法是互斥的,一个线程1进入getInstance()时,直到执行完返回后(这时返回已经实例化好的instance)另一人线程2才可以进入,这时线程2执行到if时instance不等于null了,new语句不再执行,直接返回唯一的一个instance引用。注意到这个synchronized很重要,如果没有synchronized,那么使用getInstance()是有可能得到多个Singleton实例。缺点是在一个多线程的程序中,同步的消耗是很大的,很容易造成瓶颈。考虑单例模式4,用同步块的方式,其getInstance()方法为:
//单例模式4:同步块型
public class Singleton4 {
private static Singleton4 instance = null;
private Singleton4() {
}
public static Singleton4 getInstance() {
if (instance == null) { //有多个线程判断为null时,都会进入if模块
synchronized (Singleton4.class) { //仍有可能使多个线程都执行了new语句
instance = new Singleton4();
}
}
return instance;
}
} 函数同步改成块同步,仔细分析一下,一个线程执行完synchronized块后,另一个线程若已经进入了if模块,又会执行一次实例化,这又回到了单例子模式1的情形,因此这种形式不是线程安全的,并不能解决问题。对于方式3中同步整个getInstance()方法,实际上只在第一次访问getInstance()并初始化instance对象时需要同步,其他的时候这种同步都是冗余的,造成额外的线程同步开销。我们需要减小锁定的范围并且保证线程安全。为此,有人提出双重检测同步double-checked locking (DCL)的方案:
//单例模式5:双重检测加锁(DCL)
public class Singleton5 {
private static Singleton5 instance = null;
private Singleton5() {
}
public static Singleton5 getInstance(){
if (instance == null){
synchronized(Singleton5.class) { //1
if (instance == null) //2
instance = new Singleton5(); //3
}
}
return instance;
}
}在C++/C#等语言中大量使用了这种Double-Checked Locking 模式进行优化,如ACE库。这时不会出现多次实例化的现象,既实现了单例,又没有损失性能。但是,在Java中它可能会出现无效引用的问题。因为Java语言规范和C++/C# 等不同,是一个非常灵活的规范。Java 编译器可以自由地重排变量的初始化和访问顺序,以提高运行时效率;同时Java中的变量访问是可以被自动缓存到寄存器的,这也导致潜在的依赖于具体JIT编译器的错误。每个编译器可能有不同的实现方法,同样的代码在不同编译器和执行环境下可能有不同的表现。由于JVM的优化,new操作的内部顺序可能被优化成分配内存,赋值,执行构造函数。构造函数还未完成发生线程切换就有问题了。
当new操作还没执行完,若此时某个线程进入第一个if判断,则可能判断结果为false,从而返回一个无效的引用。假设这种情况:
Thread 1:进入到//3位置,执行new Singleton5(),但是在构造函数刚刚开始的时候被Thread2抢占CPU。
Thread 2 :进入getInstance(),判断instance不等于null,返回instance(instance已经被new,已经分配了内存空间,但是没有初始化数据)。
Thread 2 :利用返回的instance做某些操作,失败或者异常抛出。
Thread 1 :取得CPU初始化完成。
这个过程中可能有多个线程取到了没有完成的实例,并用这个实例作出某些操作。出现这样的问题是因为(也可以用字节码分析工具去分析):
mem = allocate(); //分配内存 instance = mem; //标记instance非空 //未执行构造函数,thread 2从这里进入 ctorSingleton(instance); //执行构造函数 //返回instance可见instance指向了一个实际的内存地址值(不等于null),但在Java中,对象的初始化没有完成时这个地址值是无效的。既然DCL可能出现无效引用的问题,那我们就试试下面这种改进的方案:
//单例模式6:嵌套DCL
public class Singleton6 {
private static Singleton6 instance = null;
private Singleton6() {
}
public static Singleton6 getInstance(){
if (instance == null){
synchronized(Singleton6.class) { //1
Singleton6 inst = instance; //2
if (inst == null){
synchronized(Singleton6.class){ //3
inst = new Singleton6(); //4
}
instance = inst; //5
}
}
}
return instance;
}
} 这里利用嵌套DCL进行同步。Java语法允许synchronized嵌套,实际执行时它不会这么工作,因为计算机内存模型不可能出现这种嵌套同步的情况,当一个线程进入外面这个同步块时,其它线程就不能再进入了,因此对里面这个实例化语句再进行一次同步就多此一举了。Java Language Specification(JLS)规定一个同步块内的代码不能移到同步块外面来,并没有说同步块外面的代码不可以移到一个同步块里面来,这样JIT编译器在实现时可以有一个针对无作用的同步块的优化选项,这个优化把语句//5内移,即把原来的//4和//5删除,并把语句instance= new Singleton();放到//4处。如果这个优化发生,将再次发生上边提到的问题,取得没有实例化完成的数据。可见,这种改进方案本质上也是不安全的。
要解决Java中double-checked locking不安全的问题,一种可行的解决办法是使用线程局部存储来保存Singleton实例,避免JIT对其进行优化:
//单例模式7:使用线程局部变量
public class Singleton7 {
private static Singleton7 instance = null;
private static ThreadLocal<Singleton7> perThreadInstance = new ThreadLocal<>();
private Singleton7() {
}
public static Singleton7 getInstance(){
//如果perThreadInstance.get()返回非null,则本线程已经
//完成了对instance初始化的同步
if (perThreadInstance.get() == null)
createInstance();
return instance;
}
private static void createInstance(){
synchronized(Singleton7.class){
if(instance == null)
instance = new Singleton7();
}
//这里的instance对象必为非null
perThreadInstance.set(instance);
}
} 如果一个变量是成员变量,那么多个线程对同一个对象的成员变量进行操作时,它们对该成员变量是彼此影响的,也就是说一个线程对成员变量的改变会影响到另一个线程。如果一个变量是ThreadLocal维护的局部变量,那么每个线程都会有一个该局部变量的拷贝(即便是同一个对象中的方法的局部变量,也会对每一个线程有一个拷贝),一个线程对该局部变量的改变不会影响到其他线程。上面的instance成员变量每个线程都会有自己的拷贝,它们都指向同一个Singleton7实例。因为创建Singleton7实例的代码已经被同步了,保证有且只有一个线程完整地创建出Singleton7实例,其他线程不管在什么时候再去访问它的局部instance变量,都已经指向了这个唯一的实例。另一种解决办法是使用volatile关键字,用于修饰变量的可变性,强制屏蔽编译器和JIT的优化工作。
//单例模式8:双重检测加锁并使用volatile
public class Singleton8 {
private static volatile Singleton8 instance = null;
private Singleton8() {
}
public static Singleton8 getInstance(){
if (instance == null){
synchronized(Singleton8.class) { //1
if (instance == null) //2
instance = new Singleton8(); //3
}
}
return instance;
}
} 根据JLS,声明为volatile的变量具有一致性。volatile 变量可以被看作是一种“程度较轻的synchronized”;与synchronized块相比,volatile变量所需的编码较少,并且运行时开销也较少,volatile变量可用于提供线程安全,但是只能应用于非常有限的一组用例:多个变量之间或者某个变量的当前值与修改后值之间没有约束。很多以前版本JVM(如JDK1.4)并没有很好的实现volatile,所以使用它也会存在问题。但是从Java 5开始,所有符合规范的Java 5及以后的JVM都必须遵循新的Java
Memory Model(JMM),比老的JMM更严格。它特别规定了新的volatile语义,保证volatile read有acquire semantics,volatile write有release semantics,限制了乱序的程度。
实际上,Java语言class文件的编译器不会引起乱序相关问题。JVM内的JIT编译器则可能引起乱序问题。在编译器后端有一步是“指令调度”(instruction scheduling),这里有很多方面可以优化:尽量少读写内存,尽量让同一变量在寄存器里放久点,尽量少用点寄存器,尽量有效的利用指令级并行(instruction-level parallelism,ILP)之类的;为了达到这些目标,编译器会试图在保持语义的前提下改变指令的顺序。老的JMM对volatile语义规定得比较弱,没有规定要阻止volatile变量读写的乱序。新的JMM则收紧了约束,使编译器不但不能对volatile读写重新安排顺序,而且还必须保证它们在实际执行的时候不能够被CPU的乱序执行单元(out-of-order
execution unit)来改变指令顺序。为此需要根据CPU的具体情况生成memory barrier或者叫memory fence。所以说JIT编译器有可能引起乱序问题,而要阻止乱序也需要编译器的协助。有了严格的volatile修饰,new操作的内部顺序就不会被优化重排,可以保证构造函数执行完成之后再赋值。
在Java 5或以后的Java中要正确实现double-checked locking应该使用volatile变量去保存被缓存的值,以保证读写顺序的正确性。
volatile详解:
我们知道,在Java中设置变量值的操作,除了long和double类型的变量外都是原子操作,也就是说,对于变量值的简单读写操作没有必要进行同步。这在JVM 1.2之前,Java的内存模型实现总是从主存读取变量,是不需要进行特别的注意的。而随着JVM的成熟和优化,现在在多线程环境下volatile关键字的使用变得非常重要。在当前的Java内存模型下,线程可以把变量保存在本地内存(比如机器的寄存器)中,而不是直接在主存中进行读写(为了提高速度)。这就可能造成一个线程在主存中修改了一个变量的值,而另外一个线程还继续使用它在寄存器中的变量值的拷贝,造成数据的不一致。要解决这个问题,只需要像在本程序中的这样,把该变量声明为volatile(不稳定的)即可,这就指示JVM,这个变量是不稳定的,每次使用它都到主存中进行读取。一般说来,多任务环境下各任务间共享的标志都应该加volatile修饰。
volatile修饰的成员变量在每次被线程访问时,都强迫从共享内存中重读该成员变量的值。而且,当成员变量发生变化时,强迫线程将变化值回写到共享内存。这样在任何时刻,两个不同的线程总是看到某个成员变量的同一个值。
Java语言规范中指出:为了获得最佳速度,允许线程保存共享成员变量的私有拷贝,而且只当线程进入或者离开同步代码块时才与共享成员变量的原始值对比。这样当多个线程同时与某个对象交互时,就必须要注意到要让线程及时的得到共享成员变量的变化。而volatile关键字就是提示VM,对于这个成员变量不能保存它的私有拷贝,而应直接与共享成员变量交互。
使用建议:在两个或者更多的线程访问的成员变量上使用volatile。当要访问的变量已在synchronized代码块中,或者为常量时,不必使用。由于使用volatile屏蔽掉了VM中必要的代码优化,所以在效率上比较低,因此一定在必要时才使用此关键字。
总结一下,要实现多线程下的单例模式,最安全的解决方法包括:
(1)使用同步方法来创建唯一的单例;
(2)使用静态内部类来创建单例;
(3)使用线程局部变量来创建单例;
(4)若使用Java 5或以上的版本,也可以通过Double-Checked Locking并用volatile变量来保存单例。
使用注意事项:
1. Singleton继承自其他类。对象创建的方法,除了使用构造函数之外,还可以使用Object对象的clone()方法,因而在Singleton中也要注意这一点。如果Singleton类直接继承于Object,因为继承于Object的clone()方法仍保留有其protected修饰,因而不能够被其他外部类所调用,所以可以不用管它,但是如果Singleton继承于一个其他的类,而这个类又有重载clone()方法,这时就需要在Singleton中再重载clone()方法,并在其中抛出CloneNotSupportedException,这样就可以避免多个Singleton的实例被创建了。
2. Singleton与全局对象比较。一眼看去,Singleton似乎有些像全局对象。但是实际上,并不能用全局对象代替Singleton模式,这是因为:其一,有些编程语言例如Java、C#等,根本就不支持全局变量。其二,全局对象的方法并不能阻止人们将一个类实例化多次。除了类的全局实例外,开发人员仍然可以通过类的构造函数创建类的多个局部实例。而Singleton模式则通过从根本上控制类的创建,将“保证只有一个实例”这个任务交给了类本身,开发人员不可能再有其它途径得到类的多个实例。这一点是全局对象方法与Singleton模式的根本区别。Singleton模式是作为"全局变量"的替代品出现的,所以它具有全局变量的特点:全局可见;它也具有全局变量不具备的性质:同类型的对象实例只可能有一个。对于全局变量“贯穿应用程序的整个生命期”的特性,对于Singleton,视具体的实现方法,并不一定成立。
3. 反射(Reflection)和序列化(Serialization)。反射(Reflection)API会调用私有的构造器,所以为了防止创建超过一个实例,可以通过从构造器抛出异常来解决。类似的,序列化和反序列化可能会创建两个不同的实例,可以通过重写序列化API中的readResolve()方法来解决。
4. 分布式环境下。有时在某些情况下,使用Singleton并不能达到Singleton的目的,例如有多个Singleton对象同时被不同的类装入器装载;在EJB这样的分布式系统中使用也要注意这种情况,因为EJB是跨服务器,跨JVM的。我们以Java官方的宠物店源码(Pet Store 1.3.1)的ServiceLocator为例稍微分析一下。在Pet Store中ServiceLocator有两种,一个是EJB目录下;一个是WEB目录下,我们检查这两个ServiceLocator会发现内容差不多,都是提供EJB的查询定位服务,可是为什么要分开呢?仔细研究对这两种ServiceLocator才发现区别。在WEB中的ServiceLocator采用Singleton模式,ServiceLocator属于资源定位,理所当然应该使用Singleton模式。但是在EJB中,Singleton模式已经失去作用,所以ServiceLocator才分成两种,一种面向WEB服务的,一种是面向EJB服务的。
5. 系统中存在多个不同类型的Singleton时。可以考虑将Abstract Factory与Singleton模式结合,实现SingletonFactory。
Singleton模式看起来简单,使用方法也很方便,但是真正用好,是非常不容易,需要对Java的类、线程、内存等概念有相当的了解。特别是如果你的应用基于容器,那么Singleton模式少用或者不用,可以使用相关替代技术。
优势和缺陷:
Singleton单例模式为一个面向对象的应用程序提供了对象唯一的访问点,不管它实现何种功能,此种模式都为设计及开发团队提供了共享的概念。然而,Singleton对象类派生子类就有很大的困难,只有在父类没有被实例化时才可以实现。值得注意的是,有些对象不可以做成Singleton,比如.net的数据库链接对象(Connection),整个应用程序同享一个Connection对象会出现连接池溢出错误。另外,.net提供了自动废物回收的技术,因此,如果实例化的对象长时间不被利用,系统会认为它是废物,自动消灭它并回收它的资源,下次利用时又会重新实例化,这种情况下应注意其状态的丢失。
应用情景:
(1) 系统只需要一个实例的对象。
(2) 客户调用类的单个实例只允许使用一个公共访问点。
1.1.4 Builder建造者模式
将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。这里“表示”是指复杂对象有多个组成部分,建造模式是建造者在指导者的协调下,根据组成部分一步一步创建一个复杂的对象,它允许用户可以只通过指定复杂对象各组成部分的类型和内容就可以构建它们,用户不知道内部的具体构建细节。UML类图如下: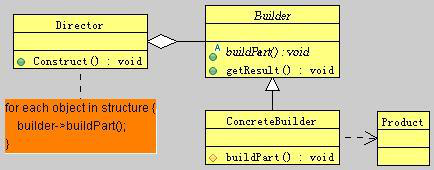
图4-1 建造者模式
Builder(抽象建造者接口)角色:为创建一个Product对象的各个部件指定抽象接口。这个角色用来规范产品对象的各个组成成分的建造。一般而言,此角色独立于应用程序的商业逻辑。
ConcreteBuilder(具体建造者)角色:担任这个角色的是于应用程序紧密相关的类,它们在指导者的调用下创建产品实例。这个角色在实现Build接口提供的方法,定义并明确它所创建的表示,提供一个返回这个产品的接口。从而达到完成产品组装,提供成品的功能。
Director(指导者)角色:调用具体建造者角色以创建产品对象。指导者并没有产品类的具体知识,真正拥有产品类的具体知识的是具体建造者对象。
Product(产品)角色:待创建的复杂对象。它要包含那些定义组件的类,包括将这些组件装配成产品的接口。
在这个模式中,Director类好像是一个多余的类,在应用中的作用好像不大。其实它的作用是明显的。第一,它隔离了客户及生产过程。第二,它负责控制产品的生成过程。比如你是客户,你要去买车子,你选好车型、颜色、内外饰等,交给Director,Director告诉你去某车间取车就可以。这样,其作用大家都能体会出来了吧?
跟Factory Pattern一样,Builder Pattern的目的也在于构建对象,并且与Abstract Factory相似,往往也包含多个Factory Method,但与Abstract Factory不同的是,Builder Pattern通过组装多个Part,最终构成一个独立的产品提供给上层应用,而Abstract Factory则往往构建多个独立的产品。
实例:产品构建
下面举一个例子来说明这个模式的使用:
import java.util.ArrayList;
//产品建造者接口:规范产品对象各组成成分的建造
interface Builder {
public void buildPartA();
public void buildPartB();
public void buildPartC();
public Product getProduct();
}
//产品角色:待创建的复杂对象
class Product {
private ArrayList<String> parts = new ArrayList<>();
public void add(String part) {
parts.add(part);
}
public void show() {
System.out.println("Product有以下几部分构成:");
for (String s : parts) {
System.out.println(s);
}
}
}
//具体建造者:在指导者的调用下创建产品的各个部分
class Worker implements Builder {
private Product product = new Product();
@Override
public void buildPartA() {
product.add("A部分");
}
@Override
public void buildPartB() {
product.add("B部分");
}
@Override
public void buildPartC() {
product.add("C部分");
}
@Override
public Product getProduct() {
return product;
}
}
//指导者:调用具体建造者建造产品,指导者相当于完成组装功能
class Designer {
public void order(Builder builder) {
builder.buildPartA();
builder.buildPartB();
builder.buildPartC();
}
}
public class Test {
public static void main(String[] args) {
Designer designer = new Designer();
Builder builder = new Worker();
designer.order(builder);
Product product = builder.getProduct();
product.show();
}
} 这里有三个角色:建造者、产品、指导者。由于产品比较复杂,有多个组成部分。把产品对象包含到建造者中去,建造者在指导者的指导下完成产品各部分的建造,可见产品表示由产品类自身完成,而产品的构建由外部的建造者来完成,产品的表示与构建分离了。Builder模式的优点是职责分离,使程序的结构更加清晰。当需要提供新的产品时,只需要从Builder基类派生新的ConcreteBuilder类,在其中实现新产品的创建工作,如果我们需要调整原有产品的创建过程,只需要对调用Builder类接口进行产品构建处的代码作简要修改即可,因为产品各部分的构建过程已经封装在ConcreteBuilder类中了。
在Abstract Factory和Factory Method模式中,抽象工厂定义创建抽象产品的方法,具体工厂创建具体的产品,而具体的产品必须符合抽象产品定义的接口,这里的产品的一个完整的产品,使用工厂模式是为了创建不同类型的完整产品,并没有深入到的产品的内部表示和构建过程中去。而在Builder模式中则是把产品的内部构建过程“外部化”为由Builder来负责,内部表示则由产品类自身完成。这样定义一个新的具体Builder角色就可以改变产品的内部构建过程,符合“开闭原则”。
Buider模式使得客户不需要知道太多产品内部的细节。它将复杂对象的创建过程封装在一个具体的Builder角色中,并由Director协调Builder角色来得到具体的产品实例。
Builder模式可以对复杂产品的创建进行更加精细的控制,产品的组成是由Director角色调用具体Builder角色来逐步完成的,所以比起其它创建型模式能更好的反映产品的构造过程。
在理解Builder模式时,有几点需要注意:
1、Builder模式与其它创建型模式一样,将产品的创建(Builder类系)与产品的使用分离(Client)开来,通过实现ConcreteBuilder来构建不同的产品;
2、除了Builder类系,Builder模式中还存在一个重要的角色:Director。Director这个角色在Builder模式中常常被忽略,但个人认为,Director对于我们理解和运用Builder模式有着重要作用,Builder及其子类负责产品各组成部分的创建,而Director负责产品的组装,二者缺一不可(有些情况下,我们可以考虑将Director类的所担负的组装的职责移植到客户代码或Builder类中实现,虽然Director的角色没有了,其功能仍然存在,但这样就失去了Director可扩展的优点);
3、由于Builder模式将对象的组装从对象创建类系中分离出来,因此,可以通过向Director类传递不同的ConcreteBuilder,达到
“同样的构建过程可以创建不同的表示”,即同样的创建过程可以创建不同的产品的效果,这正是Builder模式的意义所在。
此外,除了在Builder类系一方进行扩展,我们也可以在Director类系一方对Builder模式进行扩展,扩展成有多个ConcreteDirector的情况,每个ConcreteDirector负责完成一种组装产品的方式,如ConcreteDirector1使用builder.BuildPartA + builder.BuildPartB来组装产品,而ConcreteDirector2使用builder.BuildPartA + builder.BuildPartC来组装产品,从而实现更加复杂的“产品生产线”。
4、建造者模式的产品之间一般都有共通点,但有时候,产品之间的差异性很大,这就需要借助工厂方法模式或抽象工厂模式。另外,如果产品的内部变化复杂,Builder的每一个子类都需要对应到不同的产品去做构建的动作、方法,这就需要定义很多个具体建造类来实现这种变化。
应用情景:
1. 创建复杂对象的算法是独立于它的组成部件及装配过程。
2. 构造的过程允许构造对象有不同的表现。
1.1.5 Prototype原型模式
用原型实例指定创建对象的种类,并且通过拷贝这个原型来创建新的对象。Prototype模式用于动态抽取当前对象运行时的状态,从自身构造出一个新的对象,即自身的拷贝(往往是深拷贝),如果你愿意,你可以叫它Clone模式。大致意思是通过给出一个原型对象来指明所要创建的对象类型,然后用复制这个原型对象的办法创建出更多的同类型对象。Prototype模式的结构如下:
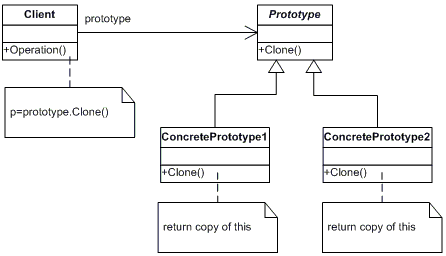
图4-2 原型模式
客户(Client)角色:客户类提出创建对象的请求。
抽象原型(Prototype)角色:这是一个抽象角色,通常由一个接口或抽象类实现。此角色给出所有的具体原型类所需的接口。在Java中,抽象原型角色通常实现了Cloneable接口。
具体原型(Concrete Prototype)角色:被复制的对象。此角色需要实现抽象原型角色所要求的接口。
原型模式的第二种形式是带原型管理器的原型模式,其UML图如下:
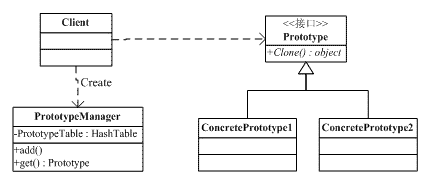
图5-2 带管理器的Prototype模式的结构
客户(Client)角色:客户端类向原型管理器提出创建对象的请求。
抽象原型(Prototype)角色:这是一个抽象角色,通常由一个接口或抽象类实现。此角色给出所有的具体原型类所需的接口。在Java中,抽象原型角色通常实现了Cloneable接口。
具体原型(Concrete Prototype)角色:被复制的对象。此角色需要实现抽象的原型角色所要求的接口。
原型管理器(Prototype Manager)角色:创建具体原型类的对象,并记录每一个被创建的对象。
在java的类库中已经实现了这一模式,只要你定义的类实现了Cloneable接口,用这个类所创建的对象可以做为原型对象进而克隆出更多的同类型的对象。下面举个例子,来介绍简单的介绍一下它的使用。
package com.demo.designpattern;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
class Prototype implements Cloneable, Serializable {
private String str;
private Temp temp;
//浅克隆
@Override
public Object clone() throws CloneNotSupportedException {
//调用超类的克隆方法实现浅克隆
Prototype prototype = (Prototype) super.clone();
return prototype;
}
//深克隆
public Object deepClone() throws IOException, ClassNotFoundException {
//把本类的对象串行化地写到字节流中,再串行化地从字节流中读入,实现深克隆
ByteArrayOutputStream bo = new ByteArrayOutputStream();
ObjectOutputStream oo = new ObjectOutputStream(bo);
oo.writeObject(this);
ByteArrayInputStream bi = new ByteArrayInputStream(bo.toByteArray());
ObjectInputStream oi = new ObjectInputStream(bi);
return oi.readObject();
}
public String getStr() {
return str;
}
public void setStr(String str) {
this.str = str;
}
public Temp getTemp() {
return temp;
}
public void setTemp(Temp temp) {
this.temp = temp;
}
}
class Temp implements Serializable {
}
public class PrototypeTest {
public static void main(String[] args) throws
CloneNotSupportedException, ClassNotFoundException, IOException {
Prototype pt = new Prototype();
Temp temp = new Temp();
pt.setTemp(temp);
pt.setStr("Hello World");
System.out.println("使用浅克隆方法进行创建对象");
Prototype pt1 = (Prototype) pt.clone();
System.out.println("=============================");
System.out.println("比较pt和pt1的str的值:");
System.out.println(pt.getStr());
System.out.println(pt1.getStr());
System.out.println("修改pt1对象中str的值后,比较pt和pt1的str的值:");
pt1.setStr("你好,世界");
System.out.println(pt.getStr());
System.out.println(pt1.getStr());
System.out.println("============================");
System.out.println("比较pt和pt1中temp对象的值");
System.out.println(pt.getTemp());
System.out.println(pt1.getTemp());
System.out.println("使用深克隆方法进行创建对象");
System.out.println("============================");
pt1 = (Prototype) pt.deepClone();
System.out.println(pt.getTemp());
System.out.println(pt1.getTemp());
}
} 输出结果:使用浅克隆方法进行创建对象 ============================= 比较pt和pt1的str的值: Hello World Hello World 修改pt1对象中str的值后,比较pt和pt1的str的值: Hello World 你好,世界 ============================ 比较pt和pt1中temp对象的值 com.demo.designpattern.Temp@7b220575 com.demo.designpattern.Temp@7b220575 使用深克隆方法进行创建对象 ============================ com.demo.designpattern.Temp@7b220575 com.demo.designpattern.Temp@27aa7aac这里Prototype类实现了原型模式,它有浅克隆clone()和深克隆deepClone()两个克隆方法,如果你要获得一个新的对象,只要在已有的对象上调用克隆方法即可。从上面的输出结果我们可以看出使用Object.clone()方法只能浅层次的克隆,即只能对那些成员变量是基本类型或String类型的对象进行克隆,对那些成员变量是类类型的对象进行克隆要使用到对象的序列化,不然克隆出来的Prototype对象都共享同一个temp实例。
应用情景:
Prototype模式在需要拷贝的产品的类型需动态指定时经常被用到。对于类似绘图软件这样的以对象管理为主要目的的应用系统中(如颜色管理器经常使用原型模式来设计),各元素往往需要支持动态拷贝动作,因此常常会运用Prototype模式。
与Builder、Factory等模式不同,Prototype的产品构建工作是由原型产品完成的,产品通过拷贝对象自身(深拷贝)来完成新产品的构建,从而无需创建一个与产品类层次平行的工厂类层次,扩展产品类型时也不会影响到产品创建代码。Builder和Factory是通过组装产品或直接创建产品来达到向上级应用提交新产品的目的,Singleton也是直接创建的方式。Builder模式由于存在一个间接层Director,在扩展产品类型时一般也不会影响到客户代码,甚至是Director类的代码。Factory模式由于需要创建与产品类层次平行的工厂类层次,当产品类型发生变化时,产品创建代码不可避免会受到影响。
Prototype模式并不是简简单单一个clone方法,Prototype模式的意义在于动态抽取当前对象运行时的状态,同时通过提供统一的clone接口方法,使得客户代码可以在不知道对象具体类型时仍然可以实现对象的拷贝,而无需运用type-switch检测对象的类型信息来分别调用创建方法来创建一个新的拷贝。
Prototype模式常常被用于与Flyweight模式(利用Prototype模式构造享元对象的拷贝)、State模式(利用Prototype模式构造状态类对象的拷贝,以供在对象间传递这些状态信息)、Strategy模式(与State模式下类似,利用Prototype模式构造Strategy类对象的拷贝,在不同的StrategyUser类间传递Strategy对象)等结合使用。
Prototype模式得到了广泛的应用,特别是在创建对象成本较大的情况下(初始化需占用较长时间,占用太多CPU资源或网络资源。比如通过Webservice或DCOM创建对象,或者创建对象要装载大文件),系统如果需要重复利用,新的对象可以通过原型模式对已有对象的属性进行复制并稍作修改来取得。另外,如果系统要保存对象的状态而对象的状态变化很小,或者对象本身占内存不大的时候,也可以用原型模式配合备忘录模式来应用。相反地,如果对象的状态变化很大,或者对象占用内存很大,那么采用状态模式会比原型模式更好。原型模式的缺点是在实现深层复制时需要编写复杂的代码。
优点:
1、通过复制自身来创建新产品,客户不需要知道对象的实际类型,只需知道它的抽象基类即可;
2、Prototype模式的应用使得扩展产品类型变得变得比较容易,不会影响到其它产品,甚至是客户代码;
3、当我们需要拷贝一个包含多种元素(同一基类)的容器时,我们需要做的工作将变得十分简单。
缺点:必须先有一个对象实例才能clone,所以clone模式并不能成为其它创建型模式的更好的替代品。
扩展:Prototype模式可以进一步扩展成带PrototypeManager的Prototype模式,在这种情况下,我们先使用PrototypeManager来创建具体原型类的对象,并记录每一个被创建的对象,以后需要拷贝原型对象时也通过PrototypeManager来完成,这从一定程度上解决了在clone前必须已经有一个对象实例的问题。
应用情景:
1. 类的实例化是动态的。
2. 你需要避免使用分层次的工厂类来创建分层次的对象。
3. 类的实例对象只有一个或很少的几个组合状态。
参考文献:
创建型设计模式——Singleton Pattern(单例模式):http://www.cnblogs.com/vrliym/archive/2010/10/26/1861978.html
The "Double-Checked Locking is Broken" Declaration: http://www.cs.umd.edu/~pugh/java/memoryModel/DoubleCheckedLocking.html
The Java Memory Model: http://www.cs.umd.edu/~pugh/java/memoryModel/
Fixing the Java Memory Model: http://www.ibm.com/developerworks/library/j-jtp03304/

相关文章推荐
- 23种设计模式分析(1):创建型模式
- 23种设计模式分析(1):创建型模式
- 23种设计模式分析(2):创建型模式
- Java 23种设计模式详尽分析与实例解析之一--创建型模式
- 23种设计模式分析(1):创建型模式
- 23种设计模式分析(2):创建型模式
- Java 23种设计模式详尽分析与实例解析之一--创建型模式
- 23种设计模式分析(2):创建型模式
- 23种设计模式分析(6):行为型模式
- 23种设计模式二:创建型工厂方法模式
- 23种设计模式之创建型模式
- GoF23种设计模式之创建型模式之建造者模式
- 23种设计模式之间的关系(提供思维导图随后分析)
- GOF设计模式-创建型模式理解与思索(二)(Factory Method分析)
- 23种设计模式分析(4):结构型模式
- 设计模式之创建型模式——简单工厂(又称为静态工厂不属于GOF23种设计模式以内)
- Java 23种设计模式使用场景(含Demo讲解分析,便于理解)
- 【23种设计模式】创建型模式 > 建造者模式
- 23种设计模式三:创建型抽象工厂模式
- 23种设计模式之四(创建型模式)Builder模式