关于利用机器学习进行手写数字的的识别
2014-04-04 16:15
417 查看
学习机器学习也有段时间了,借《机器学习 实战》的第一篇中的例子来记录下自己的学习过程吧,《实战》中的第一讲即是利用k近邻分类器进行手写体的识别,原理很简单,由于手写体的数字已经被处理成用01表示的文本

,如图所示
在进行识别的时候,把要识别的文本转化成一个32*32的矩阵,为了方便计算,又将该矩阵转化为一个1024维的向量,然后将该向量与训练的样本相减求模,选择模最小的几个样本,又根据这个样本所代表数字最多的作为识别的结果,思路很简单,但计算量比较大,每识别一次就得利用每个样本进行大量的运算,这是书中所采用的方法,作为训练自己,我当然不会按步就班,于是,我就想,能否利用其他的监督学习方法呢?首先这是一个多分类的问题,一共有十个结果,既然是多分类,那么第一个我能想到的便是朴素贝叶斯的分类方法,朴素贝叶斯原理也很简单,它有一个很强的假设,对于这个手写识别的特定问题而言,就是每个位置上出现的1和0是独立事件,尽管不大合适,作为练习实验,也无不可,好,说干就干!

Q(太长了就部分截图吧):
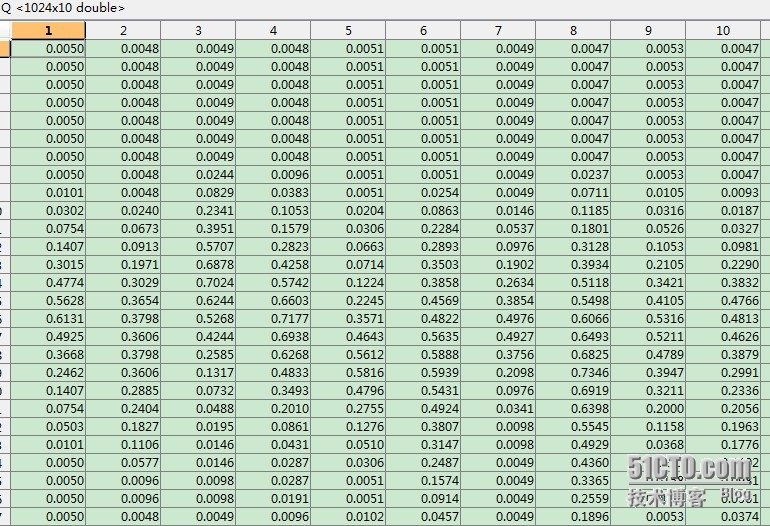
稍微解释一下数据的含义,比如Qy中的0.0977就表示样本中数字0所占得比例,即0出现的概率,可以发现Qy中每种样本的概率接近1,这是因为各种样本数量相当,而Q是一个1024*10的矩阵,就那1行1列的数来说吧,表示数字0的手写体中的1行1列为1的概率为0.0050,噢,对了,由于进行了拉格朗日平滑,所以没有为0的概率,其实这个0.0050算是最小的了, 这些相信只要懂得朴素贝叶斯的原理,应该很好理解吧...呵呵.... 最后,测试下识别率!
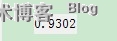
正确率为0.9302,还算行吧,呵呵,噢,对了,代码不但输出了正确率,也输出了识别错误的那些样本,帮助自己分析错误原因,如果大家要实验的话,建议大家先把《实战》的样本包下载下来,再实验,至于网址吧,百度一下就行了,哈哈!本文出自 “Rainlee的随笔记” 博客,请务必保留此出处http://rainlee.blog.51cto.com/7389753/1390648
,如图所示
在进行识别的时候,把要识别的文本转化成一个32*32的矩阵,为了方便计算,又将该矩阵转化为一个1024维的向量,然后将该向量与训练的样本相减求模,选择模最小的几个样本,又根据这个样本所代表数字最多的作为识别的结果,思路很简单,但计算量比较大,每识别一次就得利用每个样本进行大量的运算,这是书中所采用的方法,作为训练自己,我当然不会按步就班,于是,我就想,能否利用其他的监督学习方法呢?首先这是一个多分类的问题,一共有十个结果,既然是多分类,那么第一个我能想到的便是朴素贝叶斯的分类方法,朴素贝叶斯原理也很简单,它有一个很强的假设,对于这个手写识别的特定问题而言,就是每个位置上出现的1和0是独立事件,尽管不大合适,作为练习实验,也无不可,好,说干就干!
clear;
rate=1;
sour=dir('*.txt');%Get all *.txt
sourc=size(sour);
sourconut=sourc(1);
samto=cell(1,sourconut);
for k=1:sourconut
title=int8(sour(k).name(1))-int8('0');%获取txt文件的第一个字符,作为值
sample.title=title;
f = fopen(sour(k).name,'rt');
x = fread(f,'char');
fclose(f);
t=size(x);
buff=[];
for i=1:t(1)
if( int8(x(i))~=10 && int8(x(i))~= 32)
t1=size(buff);
t2=t1(1)+1;
buff(t2,1)=int8(int8(x(i))-int8('0'));
end
end
sample.content=buff;
samto{k}=sample;%此处samto为所有样本的元胞,格式为{title content}
end
%samto={{title content},..},content=图片按行取列
Qy=zeros(1,10); %Qy为样本中出现每个类型的概率,即样本为0的概率,1的概率...
Q=zeros(1024,10);
ty=zeros(1,10);
for i=0:9
t=0;
for k=1:sourconut
t1=samto(k);
if(t1{1}.title==i)
t=t+1;
end
end
ty(i+1)=t;
Qy(i+1)=t/sourconut*rate;
end %Qy计算完
disp('begin to calculate Q');
for y=0:9
disp(strcat('y=',int2str(y)));
for k=1:1024
t2=0;
for i=1:sourconut
t1=samto{i}.title;
if(samto{i}.content(k)==1 &&t1==y)
t2=t2+1;
end
end
Q(k,y+1)=(t2+1)/(ty(y+1)+10)*rate;
%disp(strcat('Q=',int2str(t2)));
end
end
disp('done!'); 靠,代码居然没有Matlab,那就将就用Python的吧,应该也行吧,呵呵,Matlab刚学不久,表示代码写得有点不伦不类.....代码中的*.txt是用的《实战》中的训练样本,每个训练样本被都为一个txt文件,如数字1的7号书写体文件名为1_7.txt,数字2的28号书写体文件名2_28.txt,样本中一共有近2000个样本,上面的代码,即可获得Q及Qy两个值,Qy表示样本中出现数字n的概率,Q为数字n中每个位置为1的概率,还是截个图吧。。。Qy:Q(太长了就部分截图吧):
稍微解释一下数据的含义,比如Qy中的0.0977就表示样本中数字0所占得比例,即0出现的概率,可以发现Qy中每种样本的概率接近1,这是因为各种样本数量相当,而Q是一个1024*10的矩阵,就那1行1列的数来说吧,表示数字0的手写体中的1行1列为1的概率为0.0050,噢,对了,由于进行了拉格朗日平滑,所以没有为0的概率,其实这个0.0050算是最小的了, 这些相信只要懂得朴素贝叶斯的原理,应该很好理解吧...呵呵.... 最后,测试下识别率!
clear;
Qroot=load('Q');
Qroot=Qroot.Q;
Qyroot=load('Qy');
Qyroot=Qyroot.Qy;
sour=dir('*.txt');
sourc=size(sour);
sourcount=sourc(1);
samto=cell(1,sourcount);
for k=1:sourcount
title=int8(sour(k).name(1))-int8('0');
sample.title=title;
sample.name=sour(k).name;
f = fopen(sour(k).name,'rt');
x = fread(f,'char');
fclose(f);
t=size(x);
buff=[];
for i=1:t(1)
if( int8(x(i))~=10 && int8(x(i))~= 32)
t1=size(buff);
t2=t1(1)+1;
buff(t2,1)=int8(int8(x(i))-int8('0'));
end
end
sample.content=buff;
samto{k}=sample;
end
r=0;
for j=1:sourcount
test=samto{j}.content;
testTitle=samto{j}.title;
name=samto{j}.name;
p=ones(1,10);
for i=0:9
for k=1:1024
if(test(k)==1)
p(i+1)=p(i+1)*Qroot(k,i+1);
else
p(i+1)=p(i+1)*(1-Qroot(k,i+1));
end
end
p(i+1)=p(i+1)*Qyroot(i+1);
end
guess=find(p==max(p))-1;
if guess==testTitle
r=r+1;
else
disp(strcat('guess:',int2str(guess)));
disp(strcat('title:',int2str(testTitle)));
disp(strcat('name:',name));
disp(p);
end
end
disp(r/sourcount);正确率为0.9302,还算行吧,呵呵,噢,对了,代码不但输出了正确率,也输出了识别错误的那些样本,帮助自己分析错误原因,如果大家要实验的话,建议大家先把《实战》的样本包下载下来,再实验,至于网址吧,百度一下就行了,哈哈!本文出自 “Rainlee的随笔记” 博客,请务必保留此出处http://rainlee.blog.51cto.com/7389753/1390648

相关文章推荐
- 关于利用机器学习进行手写数字的的识别
- mnsit 手写数据集 python3.x的读入 以及利用softmax回归进行数字识别
- 利用opencv提取Hu不变量特征 形状匹配 机器学习识别手写数字 傅里叶变换
- 【转】机器学习教程 十四-利用tensorflow做手写数字识别
- Tensorflow - Tutorial (2) : 利用softmax回归进行手写数字识别
- caffe学习(二):利用mnist数据集训练并进行手写数字识别(windows)
- 利用tensorflow一步一步实现基于MNIST 数据集进行手写数字识别的神经网络,逻辑回归
- Tensorflow - Tutorial (7) : 利用 RNN/LSTM 进行手写数字识别
- keras入门 利用卷积神经网络进行手写数字识别
- Tensorflow - Tutorial (7) : 利用 RNN/LSTM 进行手写数字识别
- 机器学习(4)——KNN算法及手写数字的识别(二)
- 利用SVM(支持向量机)和MNIST库在OpenCV环境下实现手写数字0~9的识别
- 机器学习-tensorflow入门教程二——识别手写数字
- tensorflow进行MNIST手写数字识别-优化版
- tensorflow进行MNIST手写数字识别-CNN
- 从一到二:利用mnist训练集生成的caffemodel对mnist测试集与自己手写的数字进行测试
- [DL]2.使用Softmax回归进行手写数字识别
- 【机器学习】BP神经网络实现手写数字识别
- 如何利用离散Hopfield神经网络进行数字识别(2)
- 深度学习-灰度平均值算法和支持向量机算法(SVM)进行手写数字识别