深入java NIO系列之缓冲区分析与源码解读(一)
2014-03-12 22:48
309 查看
在进行NIO 缓冲区的介绍之前,我们需要理解以下概念:
缓冲区操作
进程执行IO操作,向操作系统发起请求,操作系统要么向缓冲区中写入数据,要么将缓冲区中的数据排干
数据从磁盘移动到进程的内存区域整个过程:进程发起read()系统调用,要求其缓冲区被填满,内核随即要求磁盘控制硬件发送命令,磁盘控制器直接将数据写入内核的内存缓冲区中,该过程通过DMA来完成,无需主CPU协助,当磁盘控制器将内核缓冲区填满,内核随即将数据复制到进程对应缓冲区中。
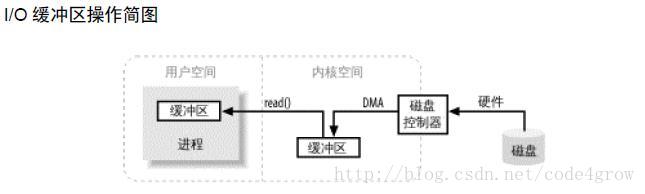
这里涉及到内核空间和用户空间的概念
内核空间:内核空间是操作系统所在的区域,可以直接与磁盘硬件设备通讯,控制用户区域的运行状态,所有的IO操作都直接或者间接的通过内核空间。当用户空间所需要的数据在内核空间中已经存在,那么内核无需再次向磁盘控制硬件发起系统调用,直接对内核缓冲区进行复制,这些数据成为高速缓存,当然内核也可以预读取用户空间需要的数据。
用户空间:用户空间通常是常规进程所在区域,即非特权区域,不能直接访问磁盘硬件设备 。由于磁盘数据都是基于块存储的数据块,其大小是固定的,而用户空间所需要的数据大小可能是任意大小或者非对齐的,那么数据在磁盘和用户空间的移动过程中操作系统也充当了数据的分解和组合的工作。
发散和汇聚
进程通过一个系统调用,就可以把一连串的缓冲区传递给操作系统,操作系统按照顺序填充或者排干多个缓冲区,读的时候把数据发散到多个缓冲区,写的时候把多个缓冲区的数据汇聚起来,这样做的优点在于可以避免多次的系统调用。
虚拟内存
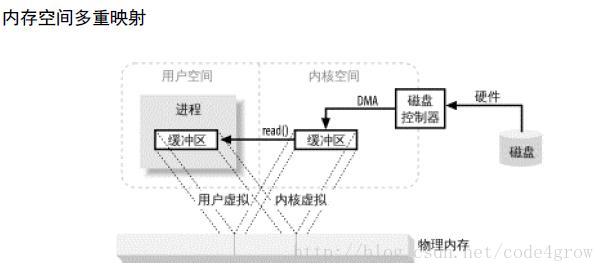
现代的操作系统都支持虚拟内存,设备控制器不能直接访问用户空间,通过把内核空间和用户空间的虚拟的地址映射到同一块物理地址,这样DMA硬件可以填充对内核空间和用户空间同时可见的缓冲区。
通过虚拟内存可以将多个虚拟地址映射到同一块物理内存地址,同时虚拟内存空间可以大于实际可用的内存空间,使用虚拟内存省去了用户空间和内存空间的数据往来拷贝,但缓冲区的大小必须是磁盘数据块的倍数,用户空间和内核空间也必须使用相同的页对其方式。
分页技术(待补充)
文件IO
文件系统与磁盘不同,磁盘把数据存取在磁盘扇区,磁盘属于硬件设备,对文件系统一无所知,它只提供了一系列数据的存取窗口。
文件系统是安排、解释磁盘数据的一种独特方式,文件系统定义了文件名、路径、文件、文件属性等一系列抽象概念。
页面调度发生在磁盘扇区和内存页的直接传输。而文件IO则可以任意大小,任意定位。
当用户进程请求文件数据时,文件系统需要确定数据在磁盘什么位置,然后将相关磁盘分区读进内存。
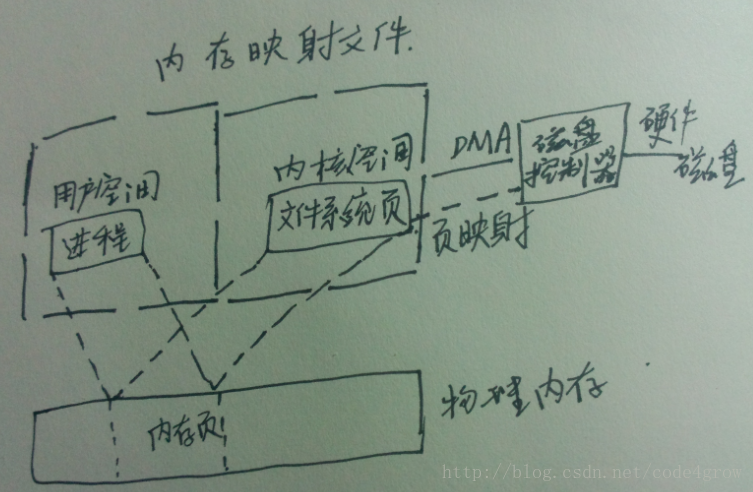
内存映射文件:
传统的IO通过用户进程发布read()和write()系统调用来传输数据,为了在内核空间的文件系统页和用户空间内存区之间移动数据,一次以上的拷贝总是避免不了,因为文件系统页和用户缓冲区之间没有一一对应关系。
但是还有一种IO操作允许用户进程最大限度的利用面向页的系统IO特性,摒弃缓冲区拷贝。
内存映射IO建立从用户空间直到可用文件系统页的虚拟内存映射:
用户进程把文件数据当做内存,无需发布read()、write()系统调用
当用户进程触碰到映射内存空间,页错误自动产生,从而将文件数据从磁盘读入内存,如果用户修改了映射内存空间,相关页会自动标记为脏,随后刷新到磁盘。
操作系统的虚拟内存会对页进行智能缓存
数据按页对齐无需缓冲区拷贝
文件锁定:
文件锁定分为两种共享锁和独占锁。多个共享锁可以对同一区域进行操作,而独占所要求相关区域不能有其他锁。
Buffer缓冲区原理及源码解读:
缓冲区实质就是一给定数据类型的数组。缓冲区包括三个基本属性:位置、限制和容量
position :下一个要写入或读取的元素在缓冲区中的索引
limit:第一个不应该读取或写入的元素的索引
capacity:缓冲区的容量,其大小不可改变
标记、位置、限制和容量值遵守以下不变式:
0 <= 标记 <= 位置 <= 限制 <= 容量
线程安全:多个当前线程使用缓冲区是不安全的。如果一个缓冲区由不止一个线程使用,则应该通过适当的同步来控制对该缓冲区的访问。
缓冲区数据传输,缓冲区的标记和重置
asIntBuffer() 创建int类型视图缓冲区
allocate()和allocateDirect() (创建直接缓冲区和非直接缓冲区)
compact() 对缓冲区进行压缩
dumplicate() 创建当前缓冲区的共享缓冲区
slice() 创建当前缓冲区的共享子序列
wrap() 将字节数组包装到缓冲区中
arrayOffset() 返回缓冲区元素在底层数组中的偏移量
asReadOnlyBuffer() 创建只读的缓冲区
进程执行IO操作,向操作系统发起请求,操作系统要么向缓冲区中写入数据,要么将缓冲区中的数据排干
数据从磁盘移动到进程的内存区域整个过程:进程发起read()系统调用,要求其缓冲区被填满,内核随即要求磁盘控制硬件发送命令,磁盘控制器直接将数据写入内核的内存缓冲区中,该过程通过DMA来完成,无需主CPU协助,当磁盘控制器将内核缓冲区填满,内核随即将数据复制到进程对应缓冲区中。
这里涉及到内核空间和用户空间的概念
内核空间:内核空间是操作系统所在的区域,可以直接与磁盘硬件设备通讯,控制用户区域的运行状态,所有的IO操作都直接或者间接的通过内核空间。当用户空间所需要的数据在内核空间中已经存在,那么内核无需再次向磁盘控制硬件发起系统调用,直接对内核缓冲区进行复制,这些数据成为高速缓存,当然内核也可以预读取用户空间需要的数据。
用户空间:用户空间通常是常规进程所在区域,即非特权区域,不能直接访问磁盘硬件设备 。由于磁盘数据都是基于块存储的数据块,其大小是固定的,而用户空间所需要的数据大小可能是任意大小或者非对齐的,那么数据在磁盘和用户空间的移动过程中操作系统也充当了数据的分解和组合的工作。
进程通过一个系统调用,就可以把一连串的缓冲区传递给操作系统,操作系统按照顺序填充或者排干多个缓冲区,读的时候把数据发散到多个缓冲区,写的时候把多个缓冲区的数据汇聚起来,这样做的优点在于可以避免多次的系统调用。
现代的操作系统都支持虚拟内存,设备控制器不能直接访问用户空间,通过把内核空间和用户空间的虚拟的地址映射到同一块物理地址,这样DMA硬件可以填充对内核空间和用户空间同时可见的缓冲区。
通过虚拟内存可以将多个虚拟地址映射到同一块物理内存地址,同时虚拟内存空间可以大于实际可用的内存空间,使用虚拟内存省去了用户空间和内存空间的数据往来拷贝,但缓冲区的大小必须是磁盘数据块的倍数,用户空间和内核空间也必须使用相同的页对其方式。
分页技术(待补充)
文件系统与磁盘不同,磁盘把数据存取在磁盘扇区,磁盘属于硬件设备,对文件系统一无所知,它只提供了一系列数据的存取窗口。
文件系统是安排、解释磁盘数据的一种独特方式,文件系统定义了文件名、路径、文件、文件属性等一系列抽象概念。
页面调度发生在磁盘扇区和内存页的直接传输。而文件IO则可以任意大小,任意定位。
当用户进程请求文件数据时,文件系统需要确定数据在磁盘什么位置,然后将相关磁盘分区读进内存。
内存映射文件:
传统的IO通过用户进程发布read()和write()系统调用来传输数据,为了在内核空间的文件系统页和用户空间内存区之间移动数据,一次以上的拷贝总是避免不了,因为文件系统页和用户缓冲区之间没有一一对应关系。
但是还有一种IO操作允许用户进程最大限度的利用面向页的系统IO特性,摒弃缓冲区拷贝。
内存映射IO建立从用户空间直到可用文件系统页的虚拟内存映射:
用户进程把文件数据当做内存,无需发布read()、write()系统调用
当用户进程触碰到映射内存空间,页错误自动产生,从而将文件数据从磁盘读入内存,如果用户修改了映射内存空间,相关页会自动标记为脏,随后刷新到磁盘。
操作系统的虚拟内存会对页进行智能缓存
数据按页对齐无需缓冲区拷贝
文件锁定:
文件锁定分为两种共享锁和独占锁。多个共享锁可以对同一区域进行操作,而独占所要求相关区域不能有其他锁。
缓冲区实质就是一给定数据类型的数组。缓冲区包括三个基本属性:位置、限制和容量
position :下一个要写入或读取的元素在缓冲区中的索引
limit:第一个不应该读取或写入的元素的索引
capacity:缓冲区的容量,其大小不可改变
标记、位置、限制和容量值遵守以下不变式:
0 <= 标记 <= 位置 <= 限制 <= 容量
线程安全:多个当前线程使用缓冲区是不安全的。如果一个缓冲区由不止一个线程使用,则应该通过适当的同步来控制对该缓冲区的访问。
缓冲区数据传输,缓冲区的标记和重置
/** * 可以向通过ByteBuffer的各种方法put字节、字节数组 * 这个过程中,可以mark来标记当前的位置,mark需要小于当前position * 可以通过limit限制put的位置 * * 如果希望通过缓冲区获取字节流,那么首先需要flip翻转因为,通过flip方法会将 * 当前位置标记为limit,position恢复为0, * 也可以通过reset()方法将当前位置恢复到标记位置 * */
asIntBuffer() 创建int类型视图缓冲区
/**
* 由于一个int类型的数据,占用4个字节,
* 向缓冲区中写入一个int值时,缓冲区会将一个包含给定int值的4个字节按照当前的字节顺序写入缓冲区的当前位置,然后将该位置加4
* getInt()用于从缓冲区的当前位置读取4个字节,根据当前的字节顺序将它们组成int值,缓冲区位置加4
*
* 视图缓冲区的容量 = 字节缓冲区中存在的元素数量除以视图中一个数据类型的数据量
* 视图缓冲区和原来的缓冲区共享数据元素,视图缓冲区和当前缓冲区保持独立的limit、position和capacity
* asIntBuffer()创建的视图缓冲区从ByteBuffer 的当前position开始
*/
public void asIntBuffer()
{
ByteBuffer bBuf = ByteBuffer.allocate(512);
bBuf.putInt(100);
bBuf.putInt(200);
bBuf.putInt(300);
System.out.println("缓冲区容量:"+bBuf.capacity());
IntBuffer intBuf = bBuf.asIntBuffer();
System.out.println("int类型视图缓冲区容量:"+intBuf.capacity());
bBuf.putInt(1000);
bBuf.putInt(2000);
bBuf.putInt(3000);
bBuf.putInt(4000);
bBuf.flip();
bBuf.limit(41);
bBuf.putInt(5000);
bBuf.putInt(6000);
System.out.println(bBuf.getInt());
System.out.println(bBuf.getInt());
System.out.println(bBuf.getInt());
System.out.println(bBuf.getInt());
System.out.println(intBuf.get());
System.out.println(intBuf.get());
System.out.println(intBuf.get());
System.out.println(intBuf.get());
intBuf.put(2);
intBuf.flip();
System.out.println(intBuf.get());
System.out.println(intBuf.get());
System.out.println(intBuf.get());
System.out.println(intBuf.get());
System.out.println(intBuf.get());
System.out.println("intBuf容量:"+intBuf.capacity());
}allocate()和allocateDirect() (创建直接缓冲区和非直接缓冲区)
/**
* 非直接内存缓冲区与直接内存缓冲区的区别:
* 直接内存缓冲区:直接缓冲区使用的内存由操作系统直接分配,不受JVM堆栈的支配
*
*非直接内存缓冲区:ByteBuffer.allocate() 在堆内存中创建,如果向一个通道中传入一个非直接ByteBuffer用于写入,
*通道可能会进行如下隐含操作:
*在通道中创建临时缓冲区,将非直接ByteBuffer中的内容复制到临时缓冲区中,执行低层次IO操作,
*当对象离开作用域时,变成无用数据,等待清理
*
*/
/**
* 创建直接内存缓冲区
* @param capacity
* @return
*/
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
/**
* 创建非直接缓冲区
* @param capacity
* @return
*/
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity);
}compact() 对缓冲区进行压缩
/**
* 将缓冲区的当前位置和界限之间的字节(如果有)复制到缓冲区的开始处。
* 即将索引 p = position() 处的字节复制到索引 0 处,将索引 p + 1 处的字节复制到索引 1 处,依此类推,
* 直到将索引 limit() - 1 处的字节复制到索引 n = limit() - 1 - p 处。
* 然后将缓冲区的位置设置为 n+1,
* 并将其界限设置为其容量。如果已定义了标记,则丢弃它。
*
*/
public void compact()
{
ByteBuffer bBuf = ByteBuffer.allocate(512);
byte[] b = "hello world".getBytes();
bBuf.put(b,0,b.length);
bBuf.put("world hello zhe shi yi shou jian dan de xiao qing ge .".getBytes());
bBuf.put("world hello zhe shi yi shou jian dan de xiao qing ge .".getBytes());
bBuf.position(70);
bBuf.compact();
System.out.println(bBuf.position()+" "+bBuf.limit()+bBuf.capacity());
}dumplicate() 创建当前缓冲区的共享缓冲区
/**
* 创建共享此缓冲区内容的新的字节缓冲区。 新缓冲区的内容将为此缓冲区的内容。
*此缓冲区内容的更改在新缓冲区中是可见的,反之亦然;这两个缓冲区的位置、界限和标记值是相互独立的。
*新缓冲区的容量、界限、位置和标记值将与此缓冲区相同。当且仅当此缓冲区为直接时,新缓冲区才是直接的,
*当且仅当此缓冲区为只读时,新缓冲区才是只读的。
*
*/
public void duplicate()
{
ByteBuffer bBuf = ByteBuffer.allocate(512);
byte[] b = "hello world".getBytes();
bBuf.put(b,0,b.length);
bBuf.put("world hello zhe shi yi shou jian dan de xiao qing ge .".getBytes());
bBuf.put("world hello zhe shi yi shou jian dan de xiao qing ge .".getBytes());
ByteBuffer sliceBuffer = bBuf.slice();
System.out.println(sliceBuffer.position());
}slice() 创建当前缓冲区的共享子序列
/**
* 创建新的字节缓冲区,该缓冲区为原缓冲区的共享子序列
* 该缓冲区的操作对原缓冲区是可见的,反之亦然。两个缓冲区的保存各自独立的limit、position、capacity,
* 新缓冲区的内容将从此缓冲区的当前位置开始,
* 新缓冲区的位置将为零,其容量和界限将为此缓冲区中所剩余的字节数量,其标记是不确定的。
*/
public void slice()
{
ByteBuffer bBuf = ByteBuffer.allocate(512);
byte[] b = "hello world".getBytes();
bBuf.put(b,0,b.length);
bBuf.put("world hello zhe shi yi shou jian dan de xiao qing ge .".getBytes());
ByteBuffer sliceBuffer = bBuf.slice();
bBuf.put("lallalallalallalalllaallalallallalalallalalalalla".getBytes());
bBuf.flip();
System.out.println(sliceBuffer.limit()-sliceBuffer.position());
byte[] sliceBytes = new byte[sliceBuffer.limit()-sliceBuffer.position()] ;
sliceBuffer.get(sliceBytes);
System.out.println(new String(sliceBytes));
}wrap() 将字节数组包装到缓冲区中
/**
* 将字节数组包装到缓冲区中
*
* 缓冲区的容量为字节数组的长度,缓冲区位置为0,缓冲区的变化对字节数组是可见的。
*
*/
public void wrap()
{
byte[] b = "hello world world hello".getBytes();
ByteBuffer bBuf = ByteBuffer.wrap(b);
b[0] = 'a';
System.out.println(bBuf.position()+" "+bBuf.capacity()+" "+bBuf.limit());
System.out.println(new String(bBuf.array()));
}arrayOffset() 返回缓冲区元素在底层数组中的偏移量
/**
* 返回此缓冲区中第一个元素在缓冲区底层实现数组中的偏移量,调用之前需要先调用hasArray()方法,判断此缓冲区是否有可访问的底层数 *组
*子缓冲从原缓冲区创建时的当前位置开始
*/
public void arrayOffset()
{
ByteBuffer bBuf = ByteBuffer.allocate(512);
byte[] b = "hello world".getBytes();
bBuf.put(b,0,b.length);
bBuf.put("world hello zhe shi yi shou jian dan de xiao qing ge .".getBytes());
bBuf.put("world hello zhe shi yi shou jian dan de xiao qing ge .".getBytes());
System.out.println("判断此缓冲区是否有底层实现的数组:"+bBuf.hasArray());
System.out.println(bBuf.arrayOffset());
bBuf.flip();
bBuf.get();
System.out.println(bBuf.arrayOffset());
}asReadOnlyBuffer() 创建只读的缓冲区
/**
* 该缓冲区和原有的字节缓冲区共享数据元素,但只读,两个缓冲区保有独立的position,limit,capacity
*/
public void asReadOnlyBuffer()
{
ByteBuffer bBuf = ByteBuffer.allocate(512);
byte[] b = "hello world".getBytes();
bBuf.put(b,0,b.length);
bBuf.put("world hello zhe shi yi shou jian dan de xiao qing ge .".getBytes());
bBuf.put("world hello zhe shi yi shou jian dan de xiao qing ge .".getBytes());
ByteBuffer asReadOnlyBuffer = bBuf.asReadOnlyBuffer();
asReadOnlyBuffer.put("hahaha".getBytes());
}

相关文章推荐
- 深入java NIO系列之通道分析与源码解读(二)
- 深入理解JAVA集合系列四:ArrayList源码解读
- 深入理解JAVA集合系列一:HashMap源码解读
- 深入理解JAVA集合系列四:ArrayList源码解读
- 面试系列之AsyncTask源码深入解读
- WorldWind源码剖析系列:BMNG类构造函数深入分析
- Android 源码系列之<五>从源码的角度深入理解LayoutInflater.Factory之主题切换(中)
- Tomcat源码解读系列——Tomcat对HTTP请求处理的整体流程
- 深入理解Tomcat系列之二:源码调试环境搭建(转)
- Kafka深入 - Eagle 源码解读
- spring深入发掘-IOC容器解读系列-BeanFactory
- 深入解析python版SVM源码系列(三)——计算样本的预测类别
- 【dubbo源码解读系列】之五 rpc 处理类 DubboProtocol
- Alamofire源码解读系列(十二)之时间轴(Timeline)
- 源码探索系列2---深入解析AsyncTask
- Android 源码系列之<十二>从源码的角度深入理解LeakCanary的内存泄露检测机制(上)
- Alamofire源码解读系列(四)之参数编码(ParameterEncoding)
- Tomcat源码解读系列——Tomcat的核心组成和启动过程
- 第127课: Spark Streaming源码经典解读系列之二:Spark Streaming生成RDD