scrapy使用方法概要
2013-11-26 14:59
555 查看
一般所说的爬虫工作分为两个部分,downoader 和 parser:
downloader输入是url列表,输出抓取到的rawdata,可能时候是html源代码,也可能是json,xml格式的数据。
parser输入是第一部分输出的rawdata,根据已知的规则提取所需的info

图1. 简单爬虫
图1所示的是最简单的爬虫,不考虑解析url,并把rawdata中的url提取做进一步提取,并假设预先知道抓取的所有的url,而且抓到的网页的parser(提取规则)是相同的。
---------------------------------------------------------------------------------------------------------------------------
重新回到主角scrapy
下面是摘取的scrapy文档中的抓取流程图
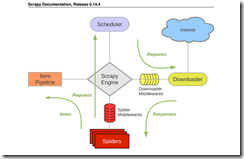
官方文档中对图中的每个components如下:
scrapy engine 【scrapy引擎】
引擎控制系统中的数据流,当某些情况发生时,触发事件。
scheduler 【调度器】
调度器接受引擎发送过来的request对象【可简单理解成抓取任务】并把他们入队列,等待的引擎在适当时刻提取出这些request并把它们通过下载中间件交给downloader去做下载。
Downloader【下载器】
Downloader根据request对象中的地址获取网页内容告知引擎下载结果,并把网页内容传送给spider组件
Spiders【解析器】
Spiders是开发人员主要接触的组件,开发人员通过在这里coding,从raw网页中提取出所需的数据并存入item【数据原单元,一个item代表一项数据对象,使用者自己定义item包含的数据项】或者提取出新的抓取request对象【新的抓取任务】 一个爬虫负责一个指定domain列表下的网页
ItemPipeline【item管道】
item管道负责处理爬虫吐出的item,包括数据清理,验证,保存
DownloaderMiddleware【下载中间件】
【工作原理很像一般mvc框架中的拦截器或者behavior,开发者可以在某些步骤之间插入自己的处理逻辑】有了中间件,开发这可以在engine向downloader传request任务之间,或者,在downloader下载完毕,向engine吐回response对象的时候对request,或者resonse插入custom code
Spider milldleware【解析器中间件】
spider middleware是引擎和spider之间的hook程序【拦截器】,用来处理spider的输入【response】和输出【item and requests】
【这两类中间件为开发者提供了非常便利的扩展scrapy的方式】

scrapy的数据流有engine【类似于mvc框架中的controller】指挥,如下:
1. engine打开一个domain,定位spider代码的位置,获取最初的urls【start_urls,暂叫‘种子’】,拿到Request对象
2. 拿到这些最初的Request对象,并把他们交给scheduler,enqueue到scheduler负责的任务队列中
3. engine向scheduler索取下一个要下载的request【url】
4. scheduler收到请求后,从任务队列中pop出一个request,并feed给engine,engine收到后,将抓取任务发送给downloader,这些request将通过downloader middlewares【scrapy默认会开启很多内置的downloader】
5. 当downloader下载完毕后,downloader生成一个Response对象并通过downloader middlerware传递给engine
6. engine拿到reponse后,通过spidermiddleware将response交给spider做解析工作
7. spider解析response,将解析出来的item和新的Request【新的抓取任务】交给engine
8. engine将拿到的item交给pipeline处理,将新的Request按照第2步骤发送给scheduler
9. 程序会在2-8之间循环直至scheduler中的任务队列为空
抓取的目标网站是现在炙手可热的旅游网站 www.qunar.com, 目标信息是qunar的所有seo页面,及页面的seo相关信息。
qunar并没有一般网站具有的 robots.txt文件,所以无法利用列表进行抓取,但是,可以发现,qunar的seo页面主要部署在
http://www.qunar.com/routes/
下,这个页面为入口文件,由此页面及此页面上所有带有routes的链接开始递归的抓取所有带有routes/字段的链接即可。
目标信息为目标站点的seo信息,所以为head中的meta和description字段。

因为要使用代理ip,所以需要实现自己的downloadermiddlerware,主要功能是从代理ip文件中随即选取一个ip端口作为代理服务,代码如下
最重要的还是爬虫,主要功能是提取页面所有的链接,把满足条件的url实例成Request对象并yield, 同时提取页面的keywords,description信息,以item的形式yield,代码如下:
pipe文件比较简单,只是把抓取到的数据存储起来,代码如下
最后附上的是setting.py文件
downloader输入是url列表,输出抓取到的rawdata,可能时候是html源代码,也可能是json,xml格式的数据。
parser输入是第一部分输出的rawdata,根据已知的规则提取所需的info
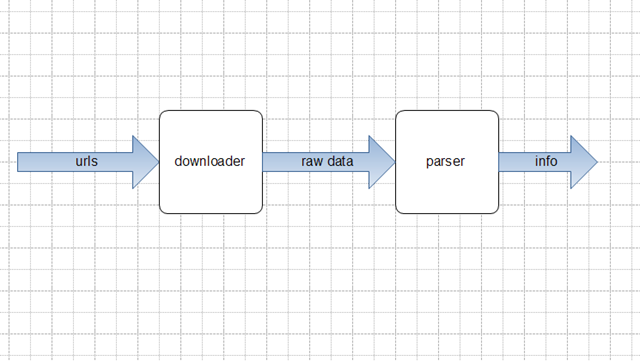
图1. 简单爬虫
图1所示的是最简单的爬虫,不考虑解析url,并把rawdata中的url提取做进一步提取,并假设预先知道抓取的所有的url,而且抓到的网页的parser(提取规则)是相同的。
---------------------------------------------------------------------------------------------------------------------------
重新回到主角scrapy
下面是摘取的scrapy文档中的抓取流程图
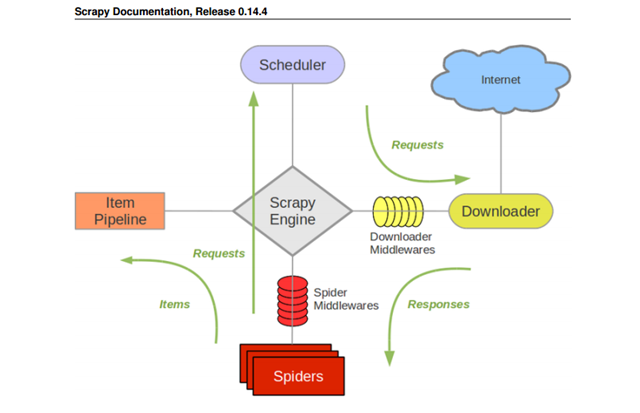
官方文档中对图中的每个components如下:
scrapy engine 【scrapy引擎】
引擎控制系统中的数据流,当某些情况发生时,触发事件。
scheduler 【调度器】
调度器接受引擎发送过来的request对象【可简单理解成抓取任务】并把他们入队列,等待的引擎在适当时刻提取出这些request并把它们通过下载中间件交给downloader去做下载。
Downloader【下载器】
Downloader根据request对象中的地址获取网页内容告知引擎下载结果,并把网页内容传送给spider组件
Spiders【解析器】
Spiders是开发人员主要接触的组件,开发人员通过在这里coding,从raw网页中提取出所需的数据并存入item【数据原单元,一个item代表一项数据对象,使用者自己定义item包含的数据项】或者提取出新的抓取request对象【新的抓取任务】 一个爬虫负责一个指定domain列表下的网页
ItemPipeline【item管道】
item管道负责处理爬虫吐出的item,包括数据清理,验证,保存
DownloaderMiddleware【下载中间件】
【工作原理很像一般mvc框架中的拦截器或者behavior,开发者可以在某些步骤之间插入自己的处理逻辑】有了中间件,开发这可以在engine向downloader传request任务之间,或者,在downloader下载完毕,向engine吐回response对象的时候对request,或者resonse插入custom code
Spider milldleware【解析器中间件】
spider middleware是引擎和spider之间的hook程序【拦截器】,用来处理spider的输入【response】和输出【item and requests】
【这两类中间件为开发者提供了非常便利的扩展scrapy的方式】

scrapy的数据流有engine【类似于mvc框架中的controller】指挥,如下:
1. engine打开一个domain,定位spider代码的位置,获取最初的urls【start_urls,暂叫‘种子’】,拿到Request对象
2. 拿到这些最初的Request对象,并把他们交给scheduler,enqueue到scheduler负责的任务队列中
3. engine向scheduler索取下一个要下载的request【url】
4. scheduler收到请求后,从任务队列中pop出一个request,并feed给engine,engine收到后,将抓取任务发送给downloader,这些request将通过downloader middlewares【scrapy默认会开启很多内置的downloader】
5. 当downloader下载完毕后,downloader生成一个Response对象并通过downloader middlerware传递给engine
6. engine拿到reponse后,通过spidermiddleware将response交给spider做解析工作
7. spider解析response,将解析出来的item和新的Request【新的抓取任务】交给engine
8. engine将拿到的item交给pipeline处理,将新的Request按照第2步骤发送给scheduler
9. 程序会在2-8之间循环直至scheduler中的任务队列为空
抓取的目标网站是现在炙手可热的旅游网站 www.qunar.com, 目标信息是qunar的所有seo页面,及页面的seo相关信息。
qunar并没有一般网站具有的 robots.txt文件,所以无法利用列表进行抓取,但是,可以发现,qunar的seo页面主要部署在
http://www.qunar.com/routes/
下,这个页面为入口文件,由此页面及此页面上所有带有routes的链接开始递归的抓取所有带有routes/字段的链接即可。
目标信息为目标站点的seo信息,所以为head中的meta和description字段。
1 # Define here the models for your scraped items 2 # 3 # See documentation in: 4 # http://doc.scrapy.org/topics/items.html 5 6 from scrapy.item import Item, Field 7 8 class SitemapItem(Item): 9 # define the fields for your item here like: 10 # name = Field() 11 url = Field() 12 keywords = Field() 13 description = Field()
因为要使用代理ip,所以需要实现自己的downloadermiddlerware,主要功能是从代理ip文件中随即选取一个ip端口作为代理服务,代码如下
1 import random
2
3 class ProxyMiddleware(object):
4 def process_request(self, request, spider):
5 fd = open('/home/xxx/services_runenv/crawlers/sitemap/sitemap/data/proxy_list.txt','r')
6 data = fd.readlines()
7 fd.close()
8 length = len(data)
9 index = random.randint(0, length -1)
10 item = data[index]
11 arr = item.split(',')
12 request.meta['proxy'] = 'http://%s:%s' % (arr[0],arr[1])最重要的还是爬虫,主要功能是提取页面所有的链接,把满足条件的url实例成Request对象并yield, 同时提取页面的keywords,description信息,以item的形式yield,代码如下:
1 from scrapy.selector import HtmlXPathSelector
2 from sitemap.items import SitemapItem
3
4 import urllib
5 import simplejson
6 import exceptions
7 import pickle
8
9 class SitemapSpider(CrawlSpider):
10 name = 'sitemap_spider'
11 allowed_domains = ['qunar.com']
12 start_urls = ['http://www.qunar.com/routes/']
13
14 rules = (
15 #Rule(SgmlLinkExtractor(allow=(r'http://www.qunar.com/routes/.*')), callback='parse'),
16 #Rule(SgmlLinkExtractor(allow=('http:.*/routes/.*')), callback='parse'),
17 )
18
19 def parse(self, response):
20 item = SitemapItem()
21 x = HtmlXPathSelector(response)
22 raw_urls = x.select("//a/@href").extract()
23 urls = []
24 for url in raw_urls:
25 if 'routes' in url:
26 if 'http' not in url:
27 url = 'http://www.qunar.com' + url
28 urls.append(url)
29
30 for url in urls:
31 yield Request(url)
32
33 item['url'] = response.url.encode('UTF-8')
34 arr_keywords = x.select("//meta[@name='keywords']/@content").extract()
35 item['keywords'] = arr_keywords[0].encode('UTF-8')
36 arr_description = x.select("//meta[@name='description']/@content").extract()
37 item['description'] = arr_description[0].encode('UTF-8')
38
39 yield itempipe文件比较简单,只是把抓取到的数据存储起来,代码如下
1 # Define your item pipelines here 2 # 3 # Don't forget to add your pipeline to the ITEM_PIPELINES setting 4 # See: http://doc.scrapy.org/topics/item-pipeline.html 5 6 class SitemapPipeline(object): 7 def process_item(self, item, spider): 8 data_path = '/home/xxx/services_runenv/crawlers/sitemap/sitemap/data/output/sitemap_data.txt' 9 fd = open(data_path, 'a') 10 line = str(item['url']) + '#$#' + str(item['keywords']) + '#$#' + str(item['description']) + '\n' 11 fd.write(line) 12 fd.close 13 return item
最后附上的是setting.py文件
# Scrapy settings for sitemap project # # For simplicity, this file contains only the most important settings by # default. All the other settings are documented here: # # http://doc.scrapy.org/topics/settings.html # BOT_NAME = 'sitemap hello,world~!' BOT_VERSION = '1.0' SPIDER_MODULES = ['sitemap.spiders'] NEWSPIDER_MODULE = 'sitemap.spiders' USER_AGENT = '%s/%s' % (BOT_NAME, BOT_VERSION) DOWNLOAD_DELAY = 0 ITEM_PIPELINES = [ 'sitemap.pipelines.SitemapPipeline' ] DOWNLOADER_MIDDLEWARES = { 'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware': 110, 'sitemap.middlewares.ProxyMiddleware': 100, } CONCURRENT_ITEMS = 128 CONCURRENT_REQUEST = 64 CONCURRENT_REQUEST_PER_DOMAIN = 64 LOG_ENABLED = True LOG_ENCODING = 'utf-8' LOG_FILE = '/home/xxx/services_runenv/crawlers/sitemap/sitemap/log/sitemap.log' LOG_LEVEL = 'DEBUG' LOG_STDOUT = False

相关文章推荐
- 【scrapy】使用方法概要(三)(转)
- 【scrapy】使用方法概要(三)(转)
- 【scrapy】使用方法概要(四)(转)
- 【scrapy】使用方法概要(一)(转)
- 【scrapy】使用方法概要(二)(转)
- 【scrapy】使用方法概要(四)(转)
- 【python】【scrapy】使用方法概要(一)
- 【python】【scrapy】使用方法概要(三)
- 【python】【scrapy】使用方法概要(二)
- 【python】【scrapy】使用方法概要(四)
- python scrapy 网络采集使用代理的方法
- Python使用scrapy抓取网站sitemap信息的方法
- Python使用scrapy采集数据过程中放回下载过大页面的方法
- scrapy一些非常实用资料整理,与其他mongdb、django、redis、solr、tor结合使用以及用Python脚本调用等等方法
- scrapy的scrapyd使用方法
- Scrapy下xpath基本的使用方法
- scrapy框架的使用方法
- Scrapy下xpath基本的使用方法
- scrapy:使用response.follow()方法时出现AttributeError: 'HtmlResponse' object has no attribute 'follow'
- mac下使用scrapy时出现的raise DistributionNotFound(req)异常的处理方法