【python】【scrapy】使用方法概要(三)
2012-12-03 21:58
218 查看
前两篇大概讲述了scrapy的安装及工作流程。这篇文章主要以一个实例来介绍scrapy的开发流程,本想以教程自带的dirbot作为例子,但感觉大家应该最先都尝试过这个示例,应该都很熟悉,这里不赘述,所以,将用笔者自己第一个较为完整的抓取程序作为示例作为讲解。
首先,要大规模抓取一个网站的内容,必要的资源便是代理ip这一资源,如果不使用代理ip,又追求抓取的速度,很可能会被被抓网站发现行踪并封掉抓取机,所以抓取大量可用的代理ip便是我们第一个任务。
大概这个爬虫要实现以下三个功能:
1. 抓取代理ip,端口信息
2. 验证代理ip,判断其透明性
3. 将可用的代理ip持久化到文件中以供后续抓取程序使用
http://www.cnproxy.com/ 代理服务器网便是一个很好的代理ip的来源,简单看一下,共有12个页面,页面格式相同:
http://www.cnproxy.com/proxy1.html
…
http://www.cnproxy.com/proxy10.html
http://www.cnproxy.com/proxyedu1.html
http://www.cnproxy.com/proxyedu2.html
准备就绪,下面正式开始:
1. 定义item,根据需求,抓取的item最后应该包含如下信息才好用:
#前4个数据为页面可以直接获取的
ip地址
端口
协议类型
地理位置
#后三个数据为pipeline中后期得到的数据,很有用
代理类型
延迟
时间戳
所以定义代码如下:

2. 定义爬虫
爬虫中做的主要工作就是设置初始化urls,即【种子】,【可不是那种种子~是这种种子~】
然后在默认的parse函数中使用xpath可以轻松的获得所需要的字段,比如
addresses = hxs.select('//tr[position()>1]/td[position()=1]').re('\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}')
可以获得ip信息的数组
locations = hxs.select('//tr[position()>1]/td[position()=4]').re('<td>(.*)<\/td>')
可以获得地理位置信息的数组
唯一有点麻烦的就是端口信息,网站站长可能想到数据会被抓取的可能,所以端口的输出使用了js输出,这确实增加了抓取的难度,scrapy和一般的爬虫是不具备浏览器的javascript解释器的,也不会执行这些js代码,所以,爬虫拿到的html代码中的端口号好没有被输出出来~
源码是这个样子

所以,一定在html的上部,会有这些‘r’的定义,不难发现

经过几次刷新,发现这些定义并不是动态的,所以就简单些,直接拿到代码中的+r+d+r+d信息,将+号替换为空,将r替换成8,d替换成0即可,所以可以声明下边这样的一个map
port_map = {'z':'3','m':'4','k':'2','l':'9','d':'0','b':'5','i':'7','w':'6','r':'8','c':'1','+':''}
具体的爬虫代码如下

3. 执行pipeline,过滤并检查抓取到的代理ip,并将其持久化到文件中
一般性的校验过程我就不赘述了,直接介绍如果验证代理可用性及透明性的方法。
这需要另一个cgi程序的帮助。简单来说一个代理是否透明,就是在做中转的时候是否会将源ip放到请求包中并能够被被抓取方获取,如果能,就说明这个代理不是透明的,使用的时候就要多留意。
一般非透明代理ip会将源ip放到HTTP_X_FORWARDED_FOR字段中,为了更严谨些,另一个cgi脚本将服务器能获取到的所有跟ip有关的数据echo出来,php代码如下:

假设这个服务地址为http://xxx.xxx.xxx.xxx/apps/proxydetect.php
那么pipelines的代码如下

其中local_ip为抓取服务器本机的ip地址
4. 最后一个要说的就是setting.py配置文件,大家看具体代码吧

最后秀一下抓取到的代理ip数据
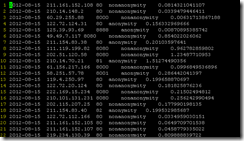
好了,这篇就这些,下一篇将介绍如果使用代理ip作为媒介,放心的去大规模抓取网站数据,晚安。
首先,要大规模抓取一个网站的内容,必要的资源便是代理ip这一资源,如果不使用代理ip,又追求抓取的速度,很可能会被被抓网站发现行踪并封掉抓取机,所以抓取大量可用的代理ip便是我们第一个任务。
大概这个爬虫要实现以下三个功能:
1. 抓取代理ip,端口信息
2. 验证代理ip,判断其透明性
3. 将可用的代理ip持久化到文件中以供后续抓取程序使用
http://www.cnproxy.com/ 代理服务器网便是一个很好的代理ip的来源,简单看一下,共有12个页面,页面格式相同:
http://www.cnproxy.com/proxy1.html
…
http://www.cnproxy.com/proxy10.html
http://www.cnproxy.com/proxyedu1.html
http://www.cnproxy.com/proxyedu2.html
准备就绪,下面正式开始:
1. 定义item,根据需求,抓取的item最后应该包含如下信息才好用:
#前4个数据为页面可以直接获取的
ip地址
端口
协议类型
地理位置
#后三个数据为pipeline中后期得到的数据,很有用
代理类型
延迟
时间戳
所以定义代码如下:

2. 定义爬虫
爬虫中做的主要工作就是设置初始化urls,即【种子】,【可不是那种种子~是这种种子~】
然后在默认的parse函数中使用xpath可以轻松的获得所需要的字段,比如
addresses = hxs.select('//tr[position()>1]/td[position()=1]').re('\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}')
可以获得ip信息的数组
locations = hxs.select('//tr[position()>1]/td[position()=4]').re('<td>(.*)<\/td>')
可以获得地理位置信息的数组
唯一有点麻烦的就是端口信息,网站站长可能想到数据会被抓取的可能,所以端口的输出使用了js输出,这确实增加了抓取的难度,scrapy和一般的爬虫是不具备浏览器的javascript解释器的,也不会执行这些js代码,所以,爬虫拿到的html代码中的端口号好没有被输出出来~
源码是这个样子

所以,一定在html的上部,会有这些‘r’的定义,不难发现
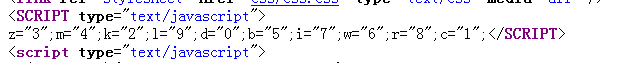
经过几次刷新,发现这些定义并不是动态的,所以就简单些,直接拿到代码中的+r+d+r+d信息,将+号替换为空,将r替换成8,d替换成0即可,所以可以声明下边这样的一个map
port_map = {'z':'3','m':'4','k':'2','l':'9','d':'0','b':'5','i':'7','w':'6','r':'8','c':'1','+':''}
具体的爬虫代码如下

3. 执行pipeline,过滤并检查抓取到的代理ip,并将其持久化到文件中
一般性的校验过程我就不赘述了,直接介绍如果验证代理可用性及透明性的方法。
这需要另一个cgi程序的帮助。简单来说一个代理是否透明,就是在做中转的时候是否会将源ip放到请求包中并能够被被抓取方获取,如果能,就说明这个代理不是透明的,使用的时候就要多留意。
一般非透明代理ip会将源ip放到HTTP_X_FORWARDED_FOR字段中,为了更严谨些,另一个cgi脚本将服务器能获取到的所有跟ip有关的数据echo出来,php代码如下:

假设这个服务地址为http://xxx.xxx.xxx.xxx/apps/proxydetect.php
那么pipelines的代码如下

其中local_ip为抓取服务器本机的ip地址
4. 最后一个要说的就是setting.py配置文件,大家看具体代码吧

最后秀一下抓取到的代理ip数据
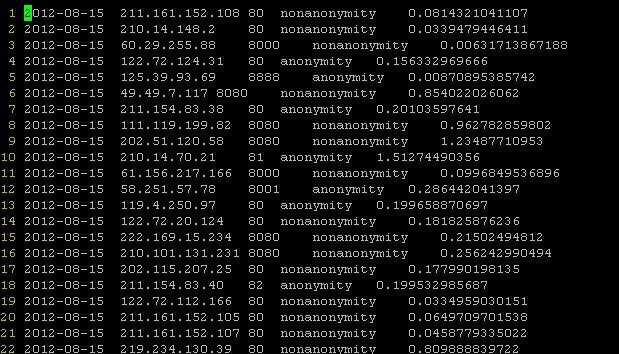
好了,这篇就这些,下一篇将介绍如果使用代理ip作为媒介,放心的去大规模抓取网站数据,晚安。

相关文章推荐
- 【python】【scrapy】使用方法概要(一)
- 【python】【scrapy】使用方法概要(二)
- 【python】【scrapy】使用方法概要(四)
- 讲解Python的Scrapy爬虫框架使用代理进行采集的方法
- 【scrapy】使用方法概要(三)(转)
- python scrapy 网络采集使用代理的方法
- Python使用scrapy采集数据过程中放回下载过大页面的方法
- 讲解Python的Scrapy爬虫框架使用代理进行采集的方法
- Python基于scrapy采集数据时使用代理服务器的方法
- 【scrapy】使用方法概要(三)(转)
- 【scrapy】使用方法概要(四)(转)
- 【scrapy】使用方法概要(四)(转)
- 【scrapy】使用方法概要(一)(转)
- 【scrapy】使用方法概要(二)(转)
- Python使用scrapy采集数据时为每个请求随机分配user-agent的方法
- scrapy一些非常实用资料整理,与其他mongdb、django、redis、solr、tor结合使用以及用Python脚本调用等等方法
- python scrapy爬虫爬取图片简易方法,使用Images模块
- scrapy使用方法概要
- Python使用scrapy抓取网站sitemap信息的方法
- Python使用scrapy采集时伪装成HTTP/1.1的方法