Deep Learning 在中文分词和词性标注任务中的应用
2013-10-30 01:20
260 查看
开源软件包 SENNA 和 word2vec 中都用到了词向量(distributed word representation),当时我就在想,对于我们的中文,是不是也类似地有字向量(distributed character representation)的概念呢?
最近恰好读到复旦大学郑骁庆博士等人的文章 [1]《Deep Learning for Chinese Word Segmentation and POS tagging》。这篇文章利用文 [3] 作者提出的神经网络框架,针对中文分词和词性标注任务,给出了一种基于字向量的 perceptron-style 算法,该算法的亮点是受文 [4] 启发在训练部分用了一种新的思路,而不是采用传统的 maximum log-likelihood 方法,极大地降低了算法复杂度,且非常容易实现。数值实验表明,该算法的 performance 也还不错。
本博客是读完文 [1] 后的一则笔记,内容以翻译为主,同时也穿插了一些注记,供感兴趣的读者参考。



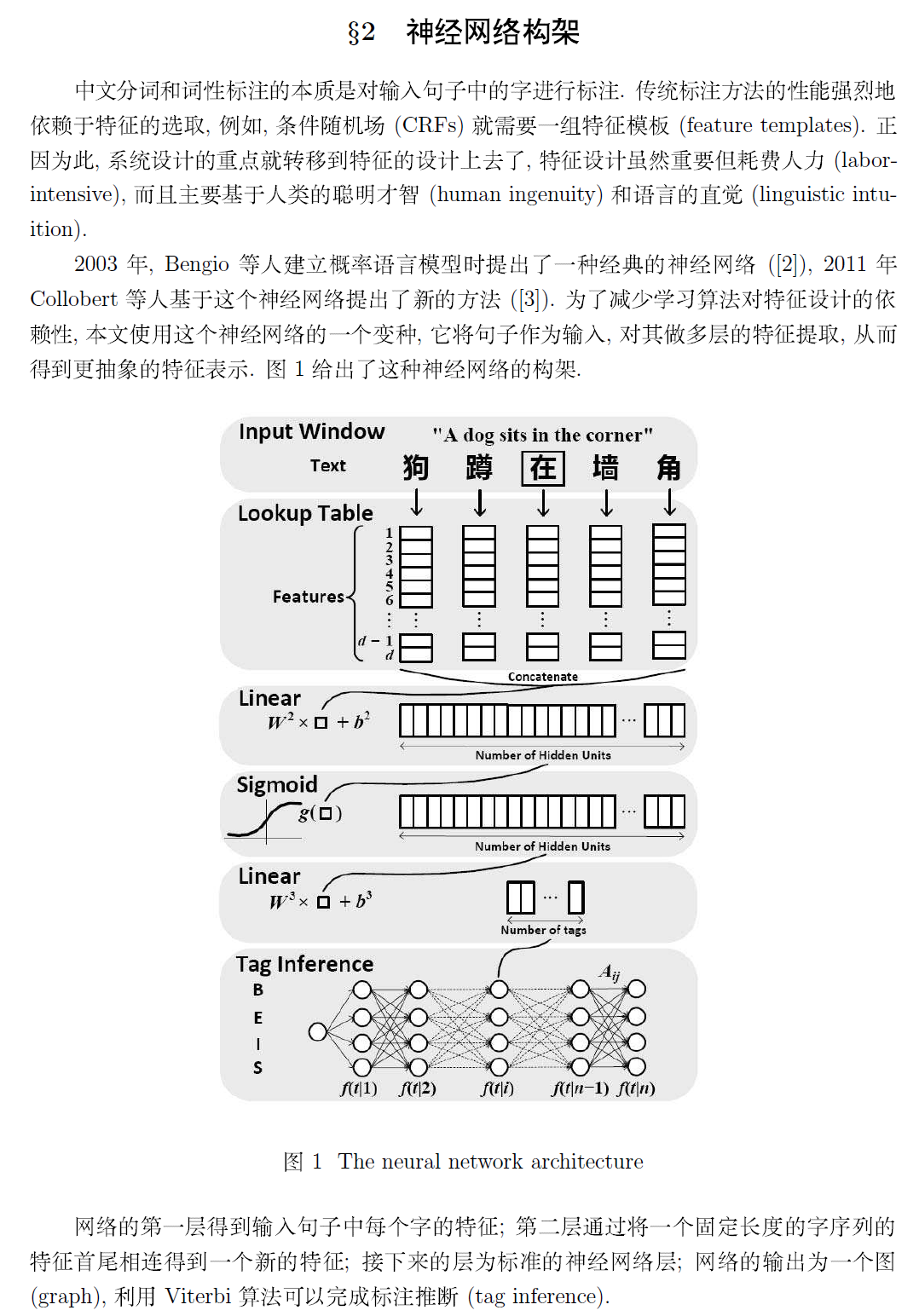









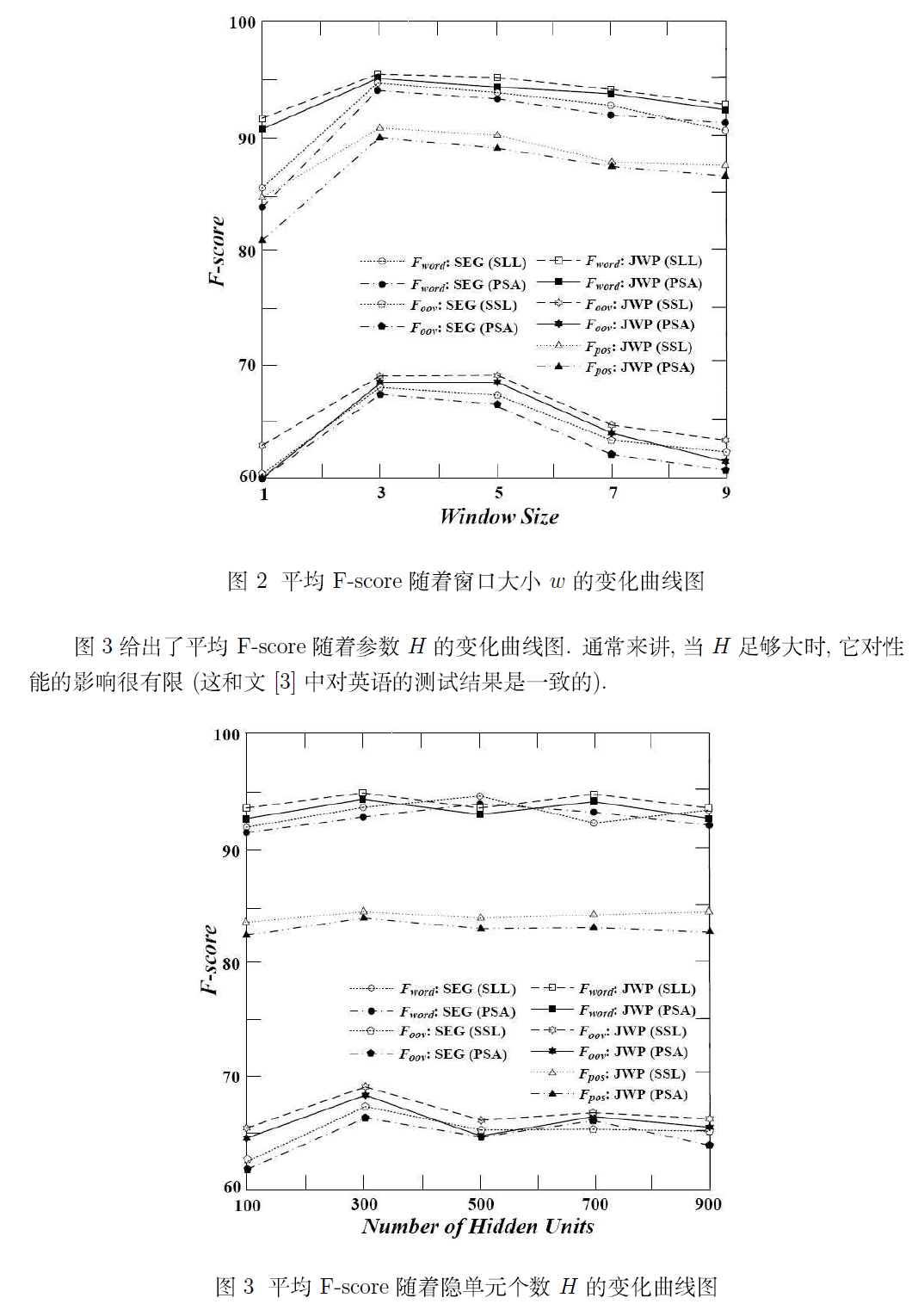

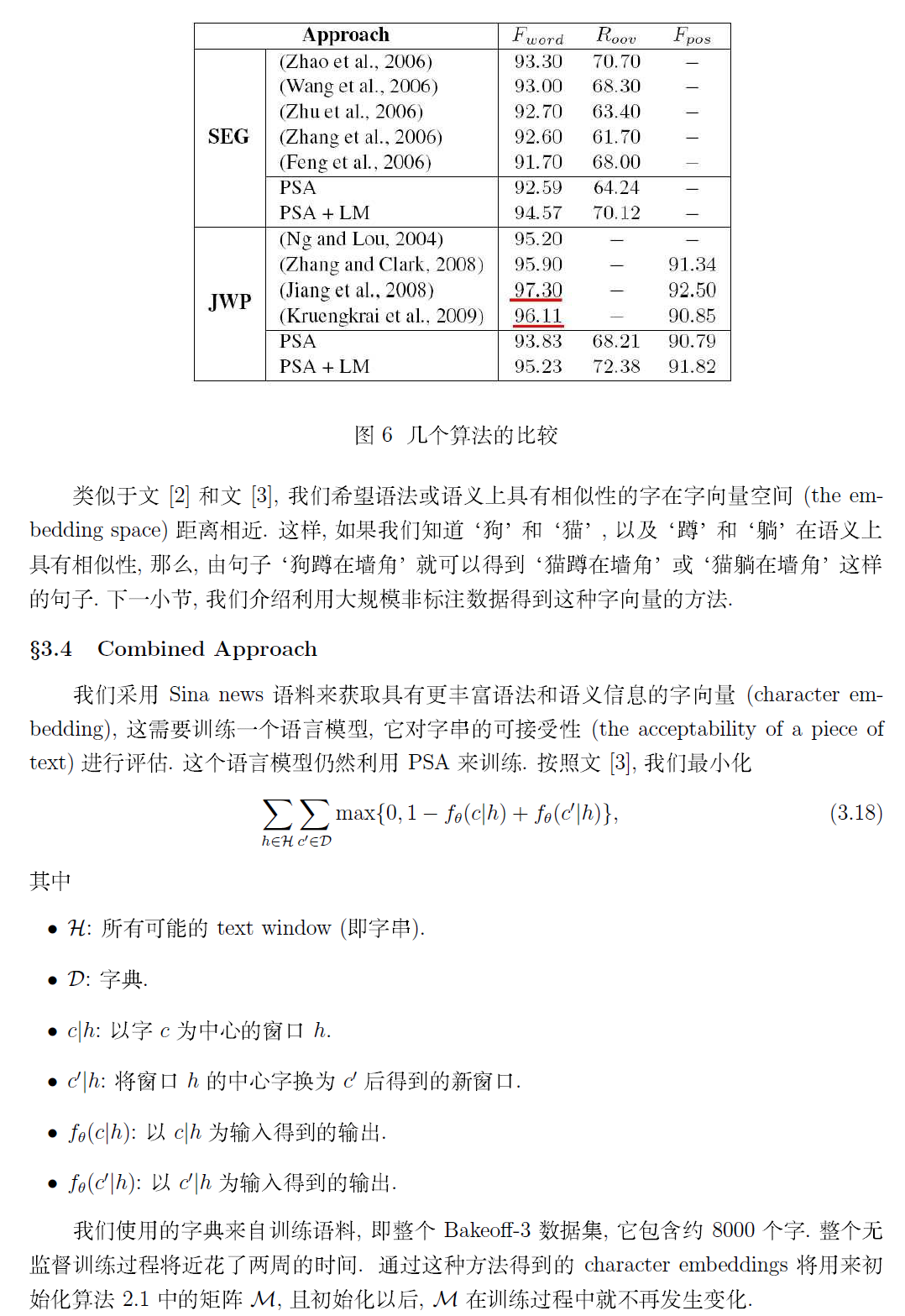
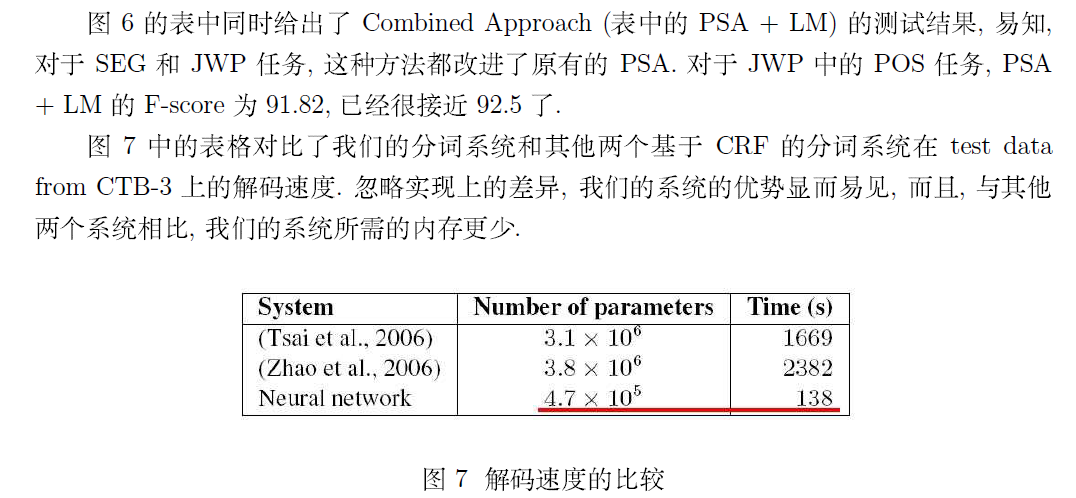

 若需要本文完整的 PDF 文档,请点击《Deep Learning 在中文分词和词性标注任务中的应用》进行下载!作者: peghoty 出处: http://blog.csdn.net/itplus/article/details/13616045欢迎转载/分享, 但请务必声明文章出处.
若需要本文完整的 PDF 文档,请点击《Deep Learning 在中文分词和词性标注任务中的应用》进行下载!作者: peghoty 出处: http://blog.csdn.net/itplus/article/details/13616045欢迎转载/分享, 但请务必声明文章出处.

相关文章推荐
- Deep Learning 在中文分词和词性标注任务中的应用
- 使用Stanford CoreNLP的Python封装包处理中文(分词、词性标注、命名实体识别、句法树、依存句法分析)
- NLP自然语言处理 jieba中文分词,关键词提取,词性标注,并行分词,起止位置,文本挖掘,NLP WordEmbedding的概念和实现
- fudannlp - 开源中文自然语言处理工具包|中文分词|词性标注|依存句法分析|指代消解 - Google Project Hosting
- ICTCLAS 中科院分词系统 代码 注释 中文分词 词性标注(2009-06-18 更新 可下载)
- ictclas,ansj,结巴分词,StanfordNLP中文分词以及所用词性标注集
- python进行中文分词、词性标注、词频统计
- Python 文本挖掘:jieba中文分词和词性标注
- ICTCLAS 中科院分词系统 代码 注释 中文分词 词性标注
- ICTCLAS 中科院分词系统 代码 注释 中文分词 词性标注
- 聊天机器人 ,中文翻译,繁简 ,关键词提取,主题提取,摘要提取 ,命名体识别,分词 ,情感分析,正负类分析 ,近义词,同义词,句子相似性,聚类,监督,无监督,词性标注,词向量句子向量
- 中文分词与词性标注
- Python 文本挖掘:jieba中文分词和词性标注
- ictclas,ansj,结巴分词,StanfordNLP中文分词以及所用词性标注集
- SCWS中文分词,词典词性标注详解
- 基于MaxEnt的中文词性标注模型实现
- HMM算法-viterbi算法的实现及与分词、词性标注、命名实体识别的引用
- HMM在自然语言处理中的应用一:词性标注
- 汉语分词在中文软件中的广泛应用
- 中文分词词性对照表