机器学习——深度学习(Deep Learning)
2013-08-18 12:14
1121 查看
转自:http://blog.csdn.net/abcjennifer/article/details/7826917
algorithmclassificationfeaturesfunctionhierarchy
Deep Learning是机器学习中一个非常接近AI的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,最近研究了机器学习中一些深度学习的相关知识,本文给出一些很有用的资料和心得。
Key Words:有监督学习与无监督学习,分类、回归,密度估计、聚类,深度学习,Sparse DBN,
1. 有监督学习和无监督学习
给定一组数据(input,target)为Z=(X,Y)。
有监督学习:最常见的是regression &classification。
regression:Y是实数vector。回归问题,就是拟合(X,Y)的一条曲线,使得下式cost function L最小。

classification:Y是一个finite number,可以看做类标号。分类问题需要首先给定有label的数据训练分类器,故属于有监督学习过程。分类问题中,cost function L(X,Y)是X属于类Y的概率的负对数。

,其中fi(X)=P(Y=i
| X);

无监督学习:无监督学习的目的是学习一个function f,使它可以描述给定数据的位置分布P(Z)。 包括两种:density
estimation & clustering.
density estimation就是密度估计,估计该数据在任意位置的分布密度
clustering就是聚类,将Z聚集几类(如K-Means),或者给出一个样本属于每一类的概率。由于不需要事先根据训练数据去train聚类器,故属于无监督学习。
PCA和很多deep learning算法都属于无监督学习。
2.深度学习Deep Learning介绍
Depth 概念:depth:
the length of the longest path from an input to an output.
Deep Architecture 的三个特点:深度不足会出现问题;人脑具有一个深度结构(每深入一层进行一次abstraction,由lower-layer的features描述而成的feature构成,就是上篇中提到的feature
hierarchy问题,而且该hierarchy是一个稀疏矩阵);认知过程逐层进行,逐步抽象
3篇文章介绍Deep Belief Networks,作为DBN的breakthrough
3.Deep Learning Algorithm 的核心思想:
把learning hierarchy 看做一个network,则
①无监督学习用于每一层网络的pre-train;
②每次用无监督学习只训练一层,将其训练结果作为其higher一层的输入;
③用监督学习去调整所有层
这里不负责任地理解下,举个例子在Autoencoder中,无监督学习学的是feature,有监督学习用在fine-tuning.
比如每一个neural network 学出的hidden layer就是feature,作为下一次神经网络无监督学习的input……这样一次次就学出了一个deep的网络,每一层都是上一次学习的hidden layer。再用softmax classifier去fine-tuning这个deep network的系数。
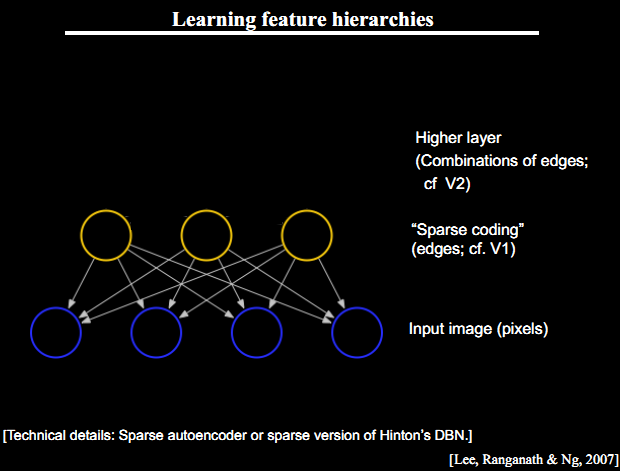
这三个点是Deep Learning Algorithm的精髓,我在上一篇文章中也有讲到,其中第三部分:Learning
Features Hierachy & Sparse DBN就讲了如何运用Sparse DBN进行feature学习。
4. Deep Learning 经典阅读材料:
The monograph or review paper
Learning Deep Architectures for AI (Foundations & Trends in Machine Learning, 2009).
The ICML 2009 Workshop on Learning Feature Hierarchies
webpage has a
list of references.
The LISA
public wiki has a
reading list and a
bibliography.
Geoff Hinton has
readings from last year’s
NIPS tutorial.
阐述Deep learning主要思想的三篇文章:
Hinton, G. E., Osindero, S. and Teh, Y.,A
fast learning algorithm for deep belief netsNeural Computation 18:1527-1554, 2006
Yoshua Bengio, Pascal Lamblin, Dan Popovici and Hugo Larochelle,Greedy
Layer-Wise Training of Deep Networks, in J. Platt et al. (Eds), Advances in Neural Information Processing Systems 19 (NIPS 2006), pp. 153-160, MIT
Press, 2007<比较了RBM和Auto-encoder>
Marc’Aurelio Ranzato, Christopher Poultney, Sumit Chopra
and Yann LeCun Efficient
Learning of Sparse Representations with an Energy-Based Model, in J. Platt et al. (Eds), Advances in Neural Information Processing Systems (NIPS
2006), MIT Press, 2007<将稀疏自编码用于回旋结构(convolutional architecture)>
06年后,大批deep learning文章涌现,感兴趣的可以看下大牛Yoshua Bengio的综述Learning
deep architectures for {AI},不过本文很长,很长……
5. Deep Learning工具——Theano
Theano是deep
learning的Python库,要求首先熟悉Python语言和numpy,建议读者先看Theano
basic tutorial,然后按照Getting
Started下载相关数据并用gradient descent的方法进行学习。
学习了Theano的基本方法后,可以练习写以下几个算法:
有监督学习:
Logistic Regression - using Theano for something
simple
Multilayer perceptron - introduction to layers
Deep Convolutional Network - a simplified version
of LeNet5
无监督学习:
Auto Encoders, Denoising Autoencoders - description of autoencoders
Stacked Denoising Auto-Encoders - easy steps into unsupervised pre-training for deep nets
Restricted Boltzmann Machines - single layer generative RBM model
Deep Belief Networks -unsupervised generative pre-training of stacked
RBMs followed by supervised fine-tuning
最后呢,推荐给大家基本ML的书籍:
Chris Bishop, “Pattern Recognition and Machine Learning”, 2007
Simon Haykin, “Neural Networks: a Comprehensive Foundation”,
2009 (3rd edition)
Richard O. Duda, Peter E. Hart and David G. Stork, “Pattern Classification”, 2001 (2nd edition)
关于Machine Learning更多的学习资料将继续更新,敬请关注本博客和新浪微博Sophia_qing。
References:
1.Brief Introduction to ML for AI
2.Deep Learning Tutorial
3.A tutorial on deep learning - Video
转自:http://www.cnblogs.com/ysjxw/archive/2011/10/08/2201819.html
Comments from Xinwei: 本文是从deeplearning网站上翻译的另一篇综述,主要简述了一些论文、算法已经工具箱。
深度学习是ML研究中的一个新的领域,它被引入到ML中使ML更接近于其原始的目标:AI。查看a brief introduction to Machine Learning for AI 和
an introduction to Deep Learning algorithms.
深度学习是关于学习多个表示和抽象层次,这些层次帮助解释数据,例如图像,声音和文本。对于更多的关于深度学习算法的知识,查看:
The monograph or review paper
Learning Deep Architectures for AI (Foundations & Trends in Machine Learning, 2009).
The ICML 2009 Workshop on Learning Feature Hierarchies
webpage has a
list of references.
The LISA
public wiki has a
reading list and a
bibliography.
Geoff Hinton has
readings from last year’s
NIPS tutorial.
这篇综述主要是介绍一些最重要的深度学习算法,并将演示如何用Theano来运行它们。Theano是一个python库,使得写深度学习模型更加容易,同时也给出了一些关于在GPU上训练它们的选项。
这个算法的综述有一些先决条件。你应该首先知道一个关于python的知识,并熟悉numpy。由于这个综述是关于如何使用Theano,你应该首先阅读Theano basic tutorial。一旦你完成这些,阅读我们的Getting
Started章节---它将介绍概念定义,数据集,和利用随机梯度下降来优化模型的方法。
纯有监督学习算法可以按照以下顺序阅读:
Logistic Regression - using Theano for something simple
Multilayer perceptron - introduction to layers
Deep Convolutional Network - a simplified version of LeNet5
无监督和半监督学习算法可以用任意顺序阅读(auto-encoders可以被独立于RBM/DBM地阅读):
Auto Encoders, Denoising Autoencoders - description of autoencoders
Stacked Denoising Auto-Encoders - easy steps into unsupervised pre-training for deep nets
Restricted Boltzmann Machines - single layer generative RBM model
Deep Belief Networks - unsupervised generative pre-training of stacked RBMs followed by supervised fine-tuning
关于mcRBM模型,我们有一篇新的关于从能量模型中抽样的综述:
HMC Sampling - hybrid (aka Hamiltonian) Monte-Carlo sampling with scan()
转自:http://www.cnblogs.com/ysjxw/archive/2011/10/08/2201782.html
深度学习(Deep Learning)算法简介
Comments from Xinwei: 最近的一个课题发展到与深度学习有联系,因此在高老师的建议下,我仔细看了下深度学习的基本概念,这篇综述翻译自http://deeplearning.net,与大家分享,有翻译不妥之处,烦请各位指正。
查看最新论文
Yoshua Bengio, Learning Deep Architectures for AI, Foundations and Trends in Machine Learning, 2(1), 2009
深度(Depth)
从一个输入中产生一个输出所涉及的计算可以通过一个流向图(flow graph)来表示:流向图是一种能够表示计算的图,在这种图中每一个节点表示一个基本的计算并且一个计算的值(计算的结果被应用到这个节点的孩子节点的值)。考虑这样一个计算集合,它可以被允许在每一个节点和可能的图结构中,并定义了一个函数族。输入节点没有孩子,输出节点没有父亲。对于表达

的流向图,可以通过一个有两个输入节点

和
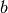
的图表示,其中一个节点通过使用

和
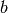
作为输入(例如作为孩子)来表示

;一个节点仅使用

作为输入来表示平方;一个节点使用
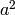
和
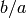
作为输入来表示加法项(其值为
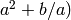
);最后一个输出节点利用一个单独的来自于加法节点的输入计算SIN。
这种流向图的一个特别属性是深度(depth):从一个输入到一个输出的最长路径的长度。
传统的前馈神经网络能够被看做拥有等于层数的深度(比如对于输出层为隐层数加1)。SVMs有深度2(一个对应于核输出或者特征空间,另一个对应于所产生输出的线性混合)。
深度架构的动机
学习基于深度架构的学习算法的主要动机是:不充分的深度是有害的;
大脑有一个深度架构;
认知过程是深度的;
不充分的深度是有害的
在许多情形中深度2就足够(比如logical gates, formal [threshold] neurons, sigmoid-neurons, Radial Basis Function [RBF] units like in SVMs)表示任何一个带有给定目标精度的函数。但是其代价是:图中所需要的节点数(比如计算和参数数量)可能变的非常大。理论结果证实那些事实上所需要的节点数随着输入的大小指数增长的函数族是存在的。这一点已经在logical gates, formal [threshold] neurons
和rbf单元中得到证实。在后者中Hastad说明了但深度是d时,函数族可以被有效地(紧地)使用O(n)个节点(对于n个输入)来表示,但是如果深度被限制为d-1,则需要指数数量的节点数O(2^n)。
我们可以将深度架构看做一种因子分解。大部分随机选择的函数不能被有效地表示,无论是用深地或者浅的架构。但是许多能够有效地被深度架构表示的却不能被用浅的架构高效表示(see the polynomials example in the
Bengio survey paper)。一个紧的和深度的表示的存在意味着在潜在的可被表示的函数中存在某种结构。如果不存在任何结构,那将不可能很好地泛化。
大脑有一个深度架构
例如,视觉皮质得到了很好的研究,并显示出一系列的区域,在每一个这种区域中包含一个输入的表示和从一个到另一个的信号流(这里忽略了在一些层次并行路径上的关联,因此更复杂)。这个特征层次的每一层表示在一个不同的抽象层上的输入,并在层次的更上层有着更多的抽象特征,他们根据低层特征定义。
需要注意的是大脑中的表示是在中间紧密分布并且纯局部:他们是稀疏的:1%的神经元是同时活动的。给定大量的神经元,任然有一个非常高效地(指数级高效)表示。
认知过程看起来是深度的
人类层次化地组织思想和概念;
人类首先学习简单的概念,然后用他们去表示更抽象的;
工程师将任务分解成多个抽象层次去处理;
学习/发现这些概念(知识工程由于没有反省而失败?)是很美好的。对语言可表达的概念的反省也建议我们一个稀疏的表示:仅所有可能单词/概念中的一个小的部分是可被应用到一个特别的输入(一个视觉场景)。
学习深度架构的突破
2006年前,尝试训练深度架构都失败了:训练一个深度有监督前馈神经网络趋向于产生坏的结果(同时在训练和测试误差中),然后将其变浅为1(1或者2个隐层)。2006年的3篇论文改变了这种状况,由Hinton的革命性的在深度信念网(Deep Belief Networks, DBNs)上的工作所引领:
Hinton, G. E., Osindero, S. and Teh, Y.,
A fast learning algorithm for deep belief nets .Neural Computation 18:1527-1554, 2006
Yoshua Bengio, Pascal Lamblin, Dan Popovici and Hugo Larochelle,
Greedy Layer-Wise Training of Deep Networks, in J. Platt et al. (Eds), Advances in Neural Information Processing Systems 19 (NIPS 2006), pp. 153-160, MIT Press, 2007
Marc’Aurelio Ranzato, Christopher Poultney, Sumit Chopra and Yann LeCun
Efficient Learning of Sparse Representations with an Energy-Based Model, in J. Platt et al. (Eds), Advances in Neural Information Processing Systems (NIPS 2006), MIT Press, 2007
在这三篇论文中以下主要原理被发现:
表示的无监督学习被用于(预)训练每一层;
在一个时间里的一个层次的无监督训练,接着之前训练的层次。在每一层学习到的表示作为下一层的输入;
用无监督训练来调整所有层(加上一个或者更多的用于产生预测的附加层);
DBNs在每一层中利用用于表示的无监督学习RBMs。Bengio et al paper 探讨和对比了RBMs和auto-encoders(通过一个表示的瓶颈内在层预测输入的神经网络)。Ranzato et al paper在一个convolutional架构的上下文中使用稀疏auto-encoders(类似于稀疏编码)。Auto-encoders和convolutional架构将在以后的课程中讲解。
从2006年以来,大量的关于深度学习的论文被发表,一些探讨了其他原理来引导中间表示的训练,查看Learning Deep Architectures for AI
本文英文版出处http://www.iro.umontreal.ca/~pift6266/H10/notes/deepintro.html
分类:
Machine Learning
本文翻译自http://deeplearning.net/tutorial/

相关文章推荐
- 机器学习——深度学习(Deep Learning)
- 机器学习——深度学习(Deep Learning)
- 机器学习——深度学习(Deep Learning)
- 机器学习——深度学习(Deep Learning)经典资料
- 机器学习——深度学习(Deep Learning)
- 机器学习——深度学习(Deep Learning)
- 机器学习——深度学习(Deep Learning)
- 机器学习——深度学习(Deep Learning)
- 机器学习——深度学习(Deep Learning)
- (转)机器学习——深度学习(Deep Learning)
- 机器学习——深度学习(Deep Learning)
- 机器学习——深度学习(Deep Learning)
- 机器学习——深度学习(Deep Learning)
- 机器学习——深度学习(Deep Learning)
- 机器学习——深度学习(Deep Learning)
- 机器学习——深度学习(Deep Learning)
- 机器学习——深度学习(Deep Learning)
- 机器学习——深度学习(Deep Learning)
- 机器学习——深度学习(Deep Learning)
- 机器学习——深度学习(Deep Learning)