Algorithm,LCA,Tarjan,深搜+并查集,最近公共祖先
2013-07-23 22:45
197 查看
思想:
要查找 lca(u,v)
dfs到两个结点
入栈动作:
建立自己的集合,代表元(祖先)为自己
出栈动作:
合并自己集合到父结点集合(祖先为父结点)
注意到一个结点必先入栈,接着另一个结点入栈,设u先发现,v后发现
则发现v后,u为黑结点(已经出栈)或灰结点(已经入栈,但未出栈)
发现v时,栈中所有灰结点为v的祖先路径
若此时u为灰,则lca(u,v)为u,等于u的代表元(因为u未出栈,集合没有向父结点合并)
若此时u为黑,则此时u所在集合的代表元就是lca(u,v),且是此时栈中一个灰结点
这个文章图文并茂一看就懂:
http://scturtle.is-programmer.com/posts/30055
tarjan算法的步骤是(当dfs到节点u时):
1 在并查集中建立仅有u的集合,设置该集合的祖先为u
1 对u的每个孩子v:
1.1 tarjan之
1.2 合并v到父节点u的集合,确保集合的祖先是u
2 设置u为已遍历
3 处理关于u的查询,若查询(u,v)中的v已遍历过,则LCA(u,v)=v所在的集合的祖先
举例说明(非证明):
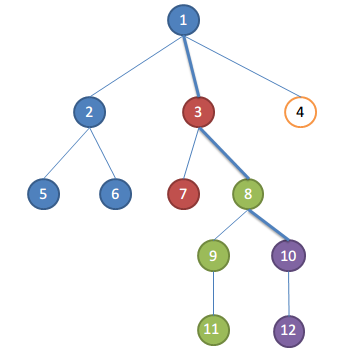
假设遍历完10的孩子,要处理关于10的请求了
取根节点到当前正在遍历的节点的路径为关键路径,即1-3-8-10
集合的祖先便是关键路径上距离集合最近的点
比如此时:
1,2,5,6为一个集合,祖先为1,集合中点和10的LCA为1
3,7为一个集合,祖先为3,集合中点和10的LCA为3
8,9,11为一个集合,祖先为8,集合中点和10的LCA为8
10,12为一个集合,祖先为10,集合中点和10的LCA为10
你看,集合的祖先便是LCA吧,所以第3步是正确的
道理很简单,LCA(u,v)便是根至u的路径上到节点v最近的点
为什么要用祖先而且每次合并集合后都要确保集合的祖先正确呢?
因为集合是用并查集实现的,为了提高速度,当然要平衡加路径压缩了,所以合并后谁是根就不确定了,所以要始终保持集合的根的祖先是正确的
关于查询和遍历孩子的顺序:
wikipedia上就是上文中的顺序,很多人的代码也是这个顺序
但是网上的很多讲解却是查询在前,遍历孩子在后,对比上文,会不会漏掉u和u的子孙之间的查询呢?
不会的
如果在刚dfs到u的时候就设置u为visited的话,本该回溯到u时解决的那些查询,在遍历孩子时就会解决掉了
这个顺序问题就是导致我头大看了很久这个算法的原因,也是絮絮叨叨写了本文的原因,希望没有理解错= =
最后,为了符合本blog风格,还是贴代码吧:
ref:
http://purety.jp/akisame/oi/TJU/
http://en.wikipedia.org/wiki/Tarjan%27s_off-line_least_common_ancestors_algorithm
http://techfield.us/blog/2008/11/lowest_common_ancester_tarjan_alogrithm/
要查找 lca(u,v)
dfs到两个结点
入栈动作:
建立自己的集合,代表元(祖先)为自己
出栈动作:
合并自己集合到父结点集合(祖先为父结点)
注意到一个结点必先入栈,接着另一个结点入栈,设u先发现,v后发现
则发现v后,u为黑结点(已经出栈)或灰结点(已经入栈,但未出栈)
发现v时,栈中所有灰结点为v的祖先路径
若此时u为灰,则lca(u,v)为u,等于u的代表元(因为u未出栈,集合没有向父结点合并)
若此时u为黑,则此时u所在集合的代表元就是lca(u,v),且是此时栈中一个灰结点
这个文章图文并茂一看就懂:
http://scturtle.is-programmer.com/posts/30055
tarjan算法的步骤是(当dfs到节点u时):
1 在并查集中建立仅有u的集合,设置该集合的祖先为u
1 对u的每个孩子v:
1.1 tarjan之
1.2 合并v到父节点u的集合,确保集合的祖先是u
2 设置u为已遍历
3 处理关于u的查询,若查询(u,v)中的v已遍历过,则LCA(u,v)=v所在的集合的祖先
举例说明(非证明):
假设遍历完10的孩子,要处理关于10的请求了
取根节点到当前正在遍历的节点的路径为关键路径,即1-3-8-10
集合的祖先便是关键路径上距离集合最近的点
比如此时:
1,2,5,6为一个集合,祖先为1,集合中点和10的LCA为1
3,7为一个集合,祖先为3,集合中点和10的LCA为3
8,9,11为一个集合,祖先为8,集合中点和10的LCA为8
10,12为一个集合,祖先为10,集合中点和10的LCA为10
你看,集合的祖先便是LCA吧,所以第3步是正确的
道理很简单,LCA(u,v)便是根至u的路径上到节点v最近的点
为什么要用祖先而且每次合并集合后都要确保集合的祖先正确呢?
因为集合是用并查集实现的,为了提高速度,当然要平衡加路径压缩了,所以合并后谁是根就不确定了,所以要始终保持集合的根的祖先是正确的
关于查询和遍历孩子的顺序:
wikipedia上就是上文中的顺序,很多人的代码也是这个顺序
但是网上的很多讲解却是查询在前,遍历孩子在后,对比上文,会不会漏掉u和u的子孙之间的查询呢?
不会的
如果在刚dfs到u的时候就设置u为visited的话,本该回溯到u时解决的那些查询,在遍历孩子时就会解决掉了
这个顺序问题就是导致我头大看了很久这个算法的原因,也是絮絮叨叨写了本文的原因,希望没有理解错= =
最后,为了符合本blog风格,还是贴代码吧:
int f[maxn],fs[maxn];//并查集父节点 父节点个数
bool vit[maxn];
int anc[maxn];//祖先
vector<int> son[maxn];//保存树
vector<int> qes[maxn];//保存查询
typedef vector<int>::iterator IT;
int Find(int x)
{
if(f[x]==x) return x;
else return f[x]=Find(f[x]);
}
void Union(int x,int y)
{
x=Find(x);y=Find(y);
if(x==y) return;
if(fs[x]<=fs[y]) f[x]=y,fs[y]+=fs[x];
else f[y]=x,fs[x]+=fs[y];
}
void lca(int u)
{
anc[u]=u;
for(IT v=son[u].begin();v!=son[u].end();++v)
{
lca(*v);
Union(u,*v);
anc[Find(u)]=u;
}
vit[u]=true;
for(IT v=qes[u].begin();v!=qes[u].end();++v)
{
if(vit[*v])
printf("LCA(%d,%d):%d\n",u,*v,anc[Find(*v)]);
}
}ref:
http://purety.jp/akisame/oi/TJU/
http://en.wikipedia.org/wiki/Tarjan%27s_off-line_least_common_ancestors_algorithm
http://techfield.us/blog/2008/11/lowest_common_ancester_tarjan_alogrithm/

相关文章推荐
- LCA(最近公共祖先)离线算法Tarjan+并查集
- POJ 1330 最近公共祖先LCA(Tarjan离线做法)
- POJ1330 Nearest Common Ancestors(在线倍增,离线Tarjan,最近公共祖先LCA)
- Tarjan应用:求割点/桥/缩点/强连通分量/双连通分量/LCA(最近公共祖先)
- hdu2586 How far away? Tarjan(离线)算法求最近公共祖先LCA 待补完
- POJ1470 LCA(tarjan离线求最近公共祖先)
- LCA最近公共祖先问题(Tarjan离线算法)
- POJ 1330 最近公共祖先LCA_Tarjan 【水】
- 连通分量模板:tarjan: 求割点 && 桥 && 缩点 && 强连通分量 && 双连通分量 && LCA(最近公共祖先)
- [算法] LCA 最近公共祖先 (Tarjan)
- 最近公共祖先(LCA)算法实现过程 【Tarjan离线+倍增在线+RMQ】
- Tarjan应用:求割点/桥/缩点/强连通分量/双连通分量/LCA(最近公共祖先)
- hihoCoder_#1067_最近公共祖先·二(LCA+tarjan模板)
- Tarjan离线算法求最近公共祖先(LCA)
- HIHO #1067 : 最近公共祖先·二(并查集+dfs LCA离线算法)
- LCA最近公共祖先(tarjan离线算法)
- hihocoder 1067 最近公共祖先·二(tarjan LCA 离线算法O(n))
- Luogu 2245 星际导航(最小生成树,最近公共祖先LCA,并查集)
- Tarjan应用:求割点/桥/缩点/强连通分量/双连通分量/LCA(最近公共祖先)【转】【修改】
- c++最近公共祖先LCA(倍增算法和tarjan)