数据挖掘 自习笔记 第三章 定性归纳实践(上)
2013-05-15 22:55
183 查看
基于属性归纳的基本思想就是首先利用关系数据库查询来收集与任务相关的数据并通过对任务相关的数据并通过对任务相关数据集中各属性不同值个数的检查完成数据泛化操作。
下面是《数据挖掘导论》原文提供的算法——AOI方法(基于属性归纳方法),我本来概念挺模糊的,但后来自己还是思考了,发现这个算法可以看成为一个泛化表的程序。

(1)选择数据表。
(2)获取数据表中各属性不同值的个数,为下面操作做准备(其中应该运用了SQL中的groupby语句进行汇总)
(3)对满足条件的属性,进行泛化操作,并可进行删减、整理工作。
(4)合并数据表,整理数据表。
(5)输出,完成过程。
这里还提到一个概念是泛化阈值,泛化阈值,据我理解是这样的。泛化阈值是一个自定义的数值,是与属性中不同值的个数作对比。如果泛化阈值比属性不同值的个数要小,证明该属性要进行泛化操作了。
如:一个表的属性名为:“姓名”,它有700个不同取值,设泛化阈值是2。2<700,那么该属性要进行泛化操作。
此外,还有一个概念叫概念层次树。我的理解是这样的。原表有自己本来的属性。如果它要进行泛化操作。那么进行操作后,要根据新数据与原数据的关系进行新的命名。此时,泛化的属性名与原属性名组成的关系,我们称之为概念层次树。


下面是书中提及的例子
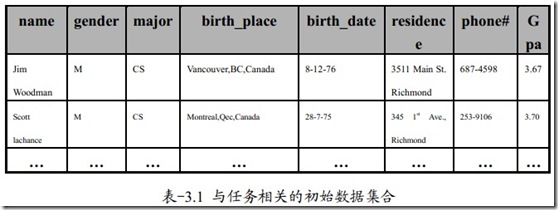
例3.1 从一个大学数据库的学生数据中挖掘出研究生的概念描述。所涉及的属性包括:姓名、性别、专业、出生地、出生日期、居住地、电话和GPA。
第一步将相关学生的数据抽取出来。
得到如下属性
第二部进行分析处理。
(1) name,由于name属性拥有许多不同的取值且对它也没定义合适的泛化操作。可被省掉。
(2) gender,由于gender属性仅包含两个不同值,该属性被保留无需进行泛化。
(3) major,该属性已经定义一个概念层次树,可以进行泛化。设泛化阈值为5,初始数据有25个不同取值。Major属性可以被泛化成指定概念(art&science、engineering、business)
(4) birth_place,该属性拥有不同的取值,我们需要对其进行泛化。着实行有一定的层次:city<provinve<country。我们要根据实际情况来泛化该属性。如果country取值超过属性泛化阈值时,此属性应该被省略。全部都是一国的学生对此项目便无意义了。如果超过属性的泛化阈值,则该属性被泛化为birth_country。
(5) birth_date, 设它有一个概念层次树的存在。birth_date属性可以泛化成age;然后再到age_range。
(6) residence, 假设residence属性是有number、street、residence_city、residence_province、residence_country属性描述。Number和street属性的不同值可能非常多。所以number和street属性或被减掉,residence_city它仅包含四个不同取值。所以将residence属性被泛化成residence_city
(7) phone#,与name属性相似,减掉
(8) gpa,假设gpa存在一个概念层次树。它将平均成绩划分为若干组。如{3.75-4.0,3.5-3.75等},也可以相应的描述为:{excellent,good, …},因此该属性应进行属性的泛化操作。
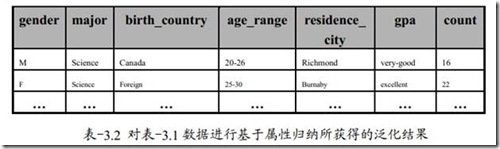
因此得如下结果。
下面是《数据挖掘导论》原文提供的算法——AOI方法(基于属性归纳方法),我本来概念挺模糊的,但后来自己还是思考了,发现这个算法可以看成为一个泛化表的程序。

(1)选择数据表。
(2)获取数据表中各属性不同值的个数,为下面操作做准备(其中应该运用了SQL中的groupby语句进行汇总)
(3)对满足条件的属性,进行泛化操作,并可进行删减、整理工作。
(4)合并数据表,整理数据表。
(5)输出,完成过程。
这里还提到一个概念是泛化阈值,泛化阈值,据我理解是这样的。泛化阈值是一个自定义的数值,是与属性中不同值的个数作对比。如果泛化阈值比属性不同值的个数要小,证明该属性要进行泛化操作了。
如:一个表的属性名为:“姓名”,它有700个不同取值,设泛化阈值是2。2<700,那么该属性要进行泛化操作。
此外,还有一个概念叫概念层次树。我的理解是这样的。原表有自己本来的属性。如果它要进行泛化操作。那么进行操作后,要根据新数据与原数据的关系进行新的命名。此时,泛化的属性名与原属性名组成的关系,我们称之为概念层次树。


下面是书中提及的例子
例3.1 从一个大学数据库的学生数据中挖掘出研究生的概念描述。所涉及的属性包括:姓名、性别、专业、出生地、出生日期、居住地、电话和GPA。
第一步将相关学生的数据抽取出来。
得到如下属性

第二部进行分析处理。
(1) name,由于name属性拥有许多不同的取值且对它也没定义合适的泛化操作。可被省掉。
(2) gender,由于gender属性仅包含两个不同值,该属性被保留无需进行泛化。
(3) major,该属性已经定义一个概念层次树,可以进行泛化。设泛化阈值为5,初始数据有25个不同取值。Major属性可以被泛化成指定概念(art&science、engineering、business)
(4) birth_place,该属性拥有不同的取值,我们需要对其进行泛化。着实行有一定的层次:city<provinve<country。我们要根据实际情况来泛化该属性。如果country取值超过属性泛化阈值时,此属性应该被省略。全部都是一国的学生对此项目便无意义了。如果超过属性的泛化阈值,则该属性被泛化为birth_country。
(5) birth_date, 设它有一个概念层次树的存在。birth_date属性可以泛化成age;然后再到age_range。
(6) residence, 假设residence属性是有number、street、residence_city、residence_province、residence_country属性描述。Number和street属性的不同值可能非常多。所以number和street属性或被减掉,residence_city它仅包含四个不同取值。所以将residence属性被泛化成residence_city
(7) phone#,与name属性相似,减掉
(8) gpa,假设gpa存在一个概念层次树。它将平均成绩划分为若干组。如{3.75-4.0,3.5-3.75等},也可以相应的描述为:{excellent,good, …},因此该属性应进行属性的泛化操作。
因此得如下结果。


相关文章推荐
- 数据挖掘 自习笔记 第三章 定性归纳实践(下)
- 数据挖掘 自习笔记 第三章 定性归纳
- 数据挖掘 自习笔记 第二章 数据处理实践(上)
- 数据挖掘 自习笔记 第二章 数据处理实践(下)
- 《python数据挖掘入门与实践》“电影推荐” 笔记3
- 数据挖掘 自习笔记 第一章 绪论
- 《python数据挖掘入门与实践》笔记1
- 《python数据挖掘入门与实践》笔记2
- 数据挖掘 自习笔记 第二章 数据预处理
- R语言与数据挖掘学习笔记
- 机器学习&数据挖掘笔记_16(常见面试之机器学习算法思想简单梳理) 常用模型汇总
- 【数据挖掘与R语言笔记】预测海藻数量(二)线性模型和回归树模型
- 如何在Web数据挖掘中保证用户访问速度的一点实践(SQLite+Quartz)
- python-MySQL学习笔记-第三章-利用Connector/Python来插入数据
- python数据分析与挖掘学习笔记(4)-垃圾邮件自动识别
- 【学堂在线数据挖掘:理论方法笔记】第八天(4.2)
- OLE DB for DM实践 —— 用数据挖掘实现交叉销售(转)
- 数据挖掘笔记
- 【慕课笔记】第三章 JAVA中必须了解的常用类 第6节 使用Math类操作数据
- 数据挖掘入门笔记