数据挖掘 自习笔记 第二章 数据处理实践(上)
2013-04-14 12:20
155 查看
数据清洗中噪声数据处理
(1)Bin 方法 :通过利用相应被平滑数据点的周围点,对一组排序数据进行平滑。如:有价格数据。
首先对价格数据进行排序,然后将其划分成若干高度的bin(即每个bin包含三个数值)
这时既可以利用每个bin的均值进行平滑。

1. 根据bin均值进行平滑,第一个bin中4、8、15的均值是9,所以可以用9来替换。
2. 根据bin边界进行平滑,利用每个bin的边界值(最大或最小值)来替换该bin中的所有值。
(2)聚类方法。相似或向邻近的数据聚合成一起形成各个聚类集合,而那些位于这些聚类集合外的数据对象,自然被认为是异常数据。
(3) 人机结合检查方法。通过人鱼计算机检查结合方法,可以帮助发现异常数据。
(4)回归方法。可以利用拟合函数对数据进行平滑。例如借助线性回归方法。
数据集成与转换
数据集成考虑的问题:1. 模式集成
2. 冗余问题。
利用相关分析方法可以帮助发现一些数据冗余情况。例如:给出两个属性,择根据这两个属性的数值分析出这两个属性剑的相互关系。属性A,B之间的互相关系可以根据以下计算公式获得。

A、B是属性中的数据。
A、B减去的,分别是A、B的平均值。
σAσB 分别表示属性A,B的标准方差。
如果r A,B >0, 则属性A,B之间是正关联,A增加,B也增加,反之则是负关联
如果r A,B =0, 则A,B属性相互独立,两者没有关系。
r A,B 绝对值越大,说明A,B关联关系越密。
3.数据值冲突检测与消除。
数据转换处理
对于急于距离计算的挖掘,规格化方法可以帮助消除因属性取值范围不同而影响挖掘结果的公正性。下面是三种规格化方法:方法1:最大最小规格化方法。该方法对被初始数据进行一种线性转换。
设minA 和 maxA 为属性A的最小和最大值。最大最小规格化方法属性A的一个值v映射为v且有v∈[new_ minA ,new_ maxA],具体映射计算公式如下:

实例:假设属性income的最大最小值分别是12,000元与98,000元,若要利用最大最小规格化方法将属性income的值映射到0至1的范围内,那么属性income的73,600元将被转化为:
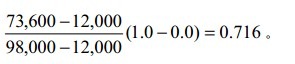
方法2:零均值规格化方法。该方法是根据属性A的均值和偏差来对A进行规格化。属性A的v值可以通过以下计算公式获得其映射数值v。

其中v减去的是属性A的均值,σA 是方差。这种规格化方法常用于属性A最大值与最小值未知;或使用最大最小规格化方法时会出现异常数据的情况。
实例2.2:假设属性income的均值与方差分别是54,000元和16,000元,是用零均值规格化方法将73,000元的属性income映射值为:

方法3:十基数变换格式化方法。该方法通过移动属性A值的小数位置来达到规格化的目的。属性A的v值可以通过以下公式计算映射值v。

其中的j为使max(|v’|)<1 成立的最小值
实例2.3:假设属性A的取值范围是-986到917。属性A绝对值得最大值为986.采用十基数变换规格化方法,就是将属性A的每个值除以1000(即j=3)即可,因此-986映射为-0.986。

相关文章推荐
- 数据挖掘 自习笔记 第二章 数据处理实践(下)
- 数据挖掘 自习笔记 第二章 数据预处理
- 数据挖掘 自习笔记 第三章 定性归纳实践(上)
- 数据挖掘 自习笔记 第三章 定性归纳实践(下)
- 数据挖掘笔记(5)——数据处理、模型评估、可视化、十大经典算法
- 数据挖掘 自习笔记 第一章 绪论
- 《python数据挖掘入门与实践》“电影推荐” 笔记3
- 『数据挖掘』scikit-learn包的进阶学习笔记——第二章:线性回归
- 数据挖掘 自习笔记 第三章 定性归纳
- 推荐系统实践阅读笔记——第二章 利用用户的行为数据
- 《python数据挖掘入门与实践》笔记1
- 《python数据挖掘入门与实践》笔记2
- Python数据挖掘入门与实践(二)——scikit-learn数据的预处理转换器以及流水线
- python数据挖掘笔记(1)—数据预处理
- 机器学习&数据挖掘笔记_15(关于凸优化的一些简单概念)
- 机器学习&数据挖掘笔记_25(PGM练习九:HMM用于分类)
- 数据挖掘笔记-01
- Learning Data Mining with Python-《Python数据挖掘入门与实践》学习后的分享
- 数据挖掘学习笔记之人工神经网络(二)
- 数据挖掘学习笔记(一)