[OceanBase] 架构设计
2013-05-15 11:12
246 查看
最近花了点时间研究了下OceanBase,非常有意思,写点东西记录一下学到的东西。
参考文档:https://github.com/alibaba/oceanbase/wiki/OceanBase%E6%9E%B6%E6%9E%84%E4%BB%8B%E7%BB%8D
1)添加节点比较复杂,往往需要人工介入;
2)有些范围查询需要访问几乎所有的分区数据库,性能变的更差;
接着Hadoop如火如荼,于是这些技术人员又在考虑是否可以使用HBase,但HBase有个致命缺陷:只能支持单行事务(HBase的体系架构可参考我的另一篇博文:http://blog.csdn.net/u010415792/article/details/8902746,因为写在HBase里是针对某个HRegion,而HRegion是分布在各个结点中,所以至多只能保证单行事务的原子性),而淘宝的业务必须支持跨行跨表事务。
因此,需要开发出一个新的数据库,即有良好的可扩展性,又能支持跨行跨表事务,于是OceanBase应运而生!
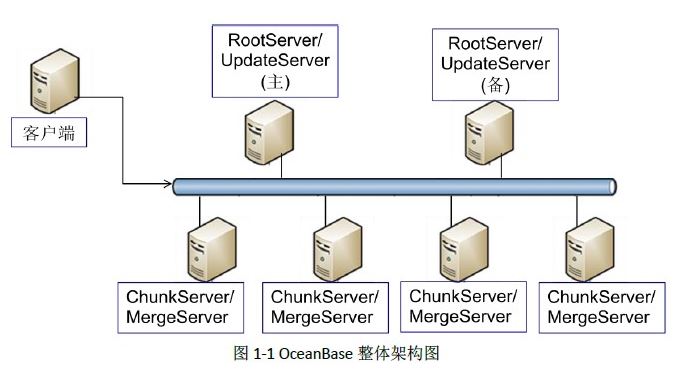
通过分析发现,虽然淘宝在线业务的数据量十分庞大,但最近一段时间(例如一天)的修改量往往不多,因此,OceanBase决定采用单台更新服务器来记录最近一段时间的修改增量,而以前的数据保持不变,称为基准数据。基准数据以类似分布式文件系统的方式存储于多台基准数据服务器中,每次查询都需要把基准数据和增量数据融合后返回给客户端。这样,写事务都集中在单台更新服务器上,避免了复杂的分布式事务,高效地实现了跨行跨表事务;另外,更新服务器上的修改增量能够定期分发到多台基准数据服务器中,避免成为瓶颈,实现了良好的扩展性。
RootServer:(存放元数据)管理集群中的服务器,tablat数据分布及副本管理。
UpdateServer:存储增量更新数据,往往和RootServer公用一台物理服务器。
ChunkServer:存储基准数据,基准数据有多个副本(类似Hadoop)
MergeServer:接受客户端请求,合并UpdataServer和ChunkServer的数据返回给客户端,并定期把UpdateServer上的数据合并到ChunkServer上。
OceanBase最大的亮点在于把写集中到一个单点UpdateServer,这样的好处是可以让一致性和可用性兼得,实现跨行跨表事务,坏处是UpdateServer单点性能有可能成为瓶颈,因此它的配置要非常非高(大内存+SSD+存储Cache)。
参考文档:https://github.com/alibaba/oceanbase/wiki/OceanBase%E6%9E%B6%E6%9E%84%E4%BB%8B%E7%BB%8D
OceanBase的产生背景
OceanBase最初是为了解决淘宝网的大规模数据而产生的(数百亿条的记录、数十TB的数据、数万TPS、数十万QPS),传统的如Oracle单机数据库肯定无法支撑(加再多硬件也不行,RAC的可扩展性太差),于是乎,有段时间,淘宝就开始用MySQL取代Oracle,然后就是疯狂分库(通常的做法是根据某个业务字段,通常取用户编号,哈希后取模,根据取模的结果将数据分布到不同的数据库服务器上,客户端请求通过数据库中间层路由到不同的数据库服务器上),这种方式有如下弊端:1)添加节点比较复杂,往往需要人工介入;
2)有些范围查询需要访问几乎所有的分区数据库,性能变的更差;
接着Hadoop如火如荼,于是这些技术人员又在考虑是否可以使用HBase,但HBase有个致命缺陷:只能支持单行事务(HBase的体系架构可参考我的另一篇博文:http://blog.csdn.net/u010415792/article/details/8902746,因为写在HBase里是针对某个HRegion,而HRegion是分布在各个结点中,所以至多只能保证单行事务的原子性),而淘宝的业务必须支持跨行跨表事务。
因此,需要开发出一个新的数据库,即有良好的可扩展性,又能支持跨行跨表事务,于是OceanBase应运而生!
OceanBase的架构设计
通过分析发现,虽然淘宝在线业务的数据量十分庞大,但最近一段时间(例如一天)的修改量往往不多,因此,OceanBase决定采用单台更新服务器来记录最近一段时间的修改增量,而以前的数据保持不变,称为基准数据。基准数据以类似分布式文件系统的方式存储于多台基准数据服务器中,每次查询都需要把基准数据和增量数据融合后返回给客户端。这样,写事务都集中在单台更新服务器上,避免了复杂的分布式事务,高效地实现了跨行跨表事务;另外,更新服务器上的修改增量能够定期分发到多台基准数据服务器中,避免成为瓶颈,实现了良好的扩展性。
RootServer:(存放元数据)管理集群中的服务器,tablat数据分布及副本管理。
UpdateServer:存储增量更新数据,往往和RootServer公用一台物理服务器。
ChunkServer:存储基准数据,基准数据有多个副本(类似Hadoop)
MergeServer:接受客户端请求,合并UpdataServer和ChunkServer的数据返回给客户端,并定期把UpdateServer上的数据合并到ChunkServer上。
架构分析
从上面可以看出,OceanBase融合了分布式存储系统和关系数据库这两种技术。通过分布式存储技术将基准数据分布到多台ChunkServer,实现数据复制、负载均衡、服务器故障检测与自动容错,等等;UpdateServer相当于一个高性能的内存数据库,底层采用关系数据库技术实现。OceanBase相当于GFS + MemSQL,ChunkServer的实现类似GFS,UpdateServer的实现类似MemSQL,目标是成为可扩展的、支持每秒百万级跨行跨表事务操作的分布式数据库。OceanBase最大的亮点在于把写集中到一个单点UpdateServer,这样的好处是可以让一致性和可用性兼得,实现跨行跨表事务,坏处是UpdateServer单点性能有可能成为瓶颈,因此它的配置要非常非高(大内存+SSD+存储Cache)。

相关文章推荐
- 架构设计之性能设计经验
- 架构设计:生产者/消费者模式[4]:双缓冲区
- Atitit 文件上传 架构设计 实现机制 解决方案 实践java php c#.net js javascript c++ python
- 基于REST风格的Web应用关键特性和架构设计
- 架构设计:生产者/消费者模式[0]:概述
- 数据中心SAN存储架构设计的八大原则
- Spring技术内幕——深入解析Spring架构与设计原理(一)IOC实现原理
- 微服务架构设计 第八步: 设计微服务对外 REST API
- 软件架构设计 ADMEMS方法体系
- 【架构】原型设计工具一览
- 网站架构之主页设计-用户体验良好的网站其主页需要具备的十二个使命
- 敏捷思维: 架构设计中的方法学(7)--组合使用模式
- 1、系统架构设计《架构之路的反思开篇》
- 架构设计三部曲之如何写架构设计说明书(转)
- 从Open Web SSO 学习软件架构设计
- 【转】架构系列-Microsoft Azure存储架构设计
- 微服务架构的设计模式
- 模式和架构读书笔记《.NET模式-架构、设计与过程》一
- web架构设计经验分享
- 如何做好软件系统的架构设计?