论文阅读笔记之ICML2012::The Landmark Selection Method for Multiple Output Prediction 基于代表性特征选取的多维度回归方法
2013-04-26 18:46
806 查看
论文目标:
做high dimensional regression的问题,即

一般做回归的时候y的维度会比x低,甚至是一维的,比如一般用回归来做分类、预测。
但是y的维度如果比较高,而x可以是高维也可以是低维,回归问题可能需要有不一样的角度去思考。
主要idea:
假设y中的feature是有冗余的,可以用一部分feature来拟合出整个y,我们需要找到那一些“好”的少量的feature(文章称之为landmark)来拟合y。于是可以分两步来做regrssion,

;

基本实现方法:
首先解释一下landmark,其实很多其他文章中的landmark往往指的一些被选出来的样本点(sample),在这个文章中却是一些被选出来的数据特征(feature)。不过总是可以理解的。
实现方法分为三步
S1: 也是去完成文章假设的一步,去挑一些landmark feature,怎么挑?求解下面这个目标函数:

总的来看,(3)的意思是说用Y里面的一部分feature来进行线性组合,组合出来的y的表达要和原来的y尽可能的相似(F-norm)。其中

项是group
sparse约束,他的意思是先对A的每一行做norm约束,然后对norm vector做L1的sparse约束,得到的结果就是A的某一些行全为0。 第三项

是对A整体做sparse
约束,得到的结果就是A的很多元素为0。Sparse的约束就是为了去找到那些最有用的landmark。这个思想在machine learning,computer vision很多研究里面都有体现。
S2:计算

,通过A我们可以看到哪些feature被挑出来了,组成了yL
然后用一般regression的方法根据training data来做回归,算出yL
S3:用yL 来还原出y
这一部分文章中写的很隐晦,可能作者觉得很好理解就没有具体讲。就我个人理解是得到了yL以后得到y可以直接用下面的方法:
y用y *A 拟合,但是test集合y是需要我们计算的,不知道的。回顾第一步的假设,组合出来的y的表达要和原来的y尽可能的相似。而A是sparse的,于是实际上真正用来拟合的只是yL,所用用第二步预测出来的yL*A即可预测出整个test集合的y。
总结:
这篇文章解决问题的思路值得借鉴,把一个复杂问题简化成两个有关联又相对简单的问题来解。
文章中解第一步的优化问题的方法具体就不展开了,如果真的需要去解类似的group sparse问题的朋友可以去读读论文。
做high dimensional regression的问题,即

一般做回归的时候y的维度会比x低,甚至是一维的,比如一般用回归来做分类、预测。
但是y的维度如果比较高,而x可以是高维也可以是低维,回归问题可能需要有不一样的角度去思考。
主要idea:
假设y中的feature是有冗余的,可以用一部分feature来拟合出整个y,我们需要找到那一些“好”的少量的feature(文章称之为landmark)来拟合y。于是可以分两步来做regrssion,

;
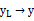
基本实现方法:
首先解释一下landmark,其实很多其他文章中的landmark往往指的一些被选出来的样本点(sample),在这个文章中却是一些被选出来的数据特征(feature)。不过总是可以理解的。
实现方法分为三步
S1: 也是去完成文章假设的一步,去挑一些landmark feature,怎么挑?求解下面这个目标函数:

总的来看,(3)的意思是说用Y里面的一部分feature来进行线性组合,组合出来的y的表达要和原来的y尽可能的相似(F-norm)。其中
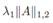
项是group
sparse约束,他的意思是先对A的每一行做norm约束,然后对norm vector做L1的sparse约束,得到的结果就是A的某一些行全为0。 第三项
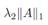
是对A整体做sparse
约束,得到的结果就是A的很多元素为0。Sparse的约束就是为了去找到那些最有用的landmark。这个思想在machine learning,computer vision很多研究里面都有体现。
S2:计算
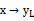
,通过A我们可以看到哪些feature被挑出来了,组成了yL
然后用一般regression的方法根据training data来做回归,算出yL
S3:用yL 来还原出y
这一部分文章中写的很隐晦,可能作者觉得很好理解就没有具体讲。就我个人理解是得到了yL以后得到y可以直接用下面的方法:
y用y *A 拟合,但是test集合y是需要我们计算的,不知道的。回顾第一步的假设,组合出来的y的表达要和原来的y尽可能的相似。而A是sparse的,于是实际上真正用来拟合的只是yL,所用用第二步预测出来的yL*A即可预测出整个test集合的y。
总结:
这篇文章解决问题的思路值得借鉴,把一个复杂问题简化成两个有关联又相对简单的问题来解。
文章中解第一步的优化问题的方法具体就不展开了,如果真的需要去解类似的group sparse问题的朋友可以去读读论文。

相关文章推荐
- 论文阅读笔记之ICML2012::The Landmark Selection Method for Multiple Output Prediction 基于代表性特征选取的多维度回归方法
- 论文阅读笔记之ICML2012::The Landmark Selection Method for Multiple Output Prediction 基于代表性特征选取的多维度回归方法
- [论文笔记] A minimal role mining method for the web service composition (2009)
- [论文笔记] Direct Answers for Search Queries in the Long Tail (CHI, 2012)
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
- [论文笔记] Leveraging the crowd as a source of innovation Does crowdsourcing represent a new model for product and service innovation? (SIGMIS-CPR, 2012)
- TAO: Facebook's Distributed Data Store for the Social Graph论文阅读笔记
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
- 1703.In Defense of the Triplet Loss for Person Re-Identification 论文阅读笔记
- [论文笔记](东北大学)基于组合服务执行信息的服务选取方法研究(计算机学报, 2008)
- 1705.IAN- The Individual Aggregation Network for Person Search 论文阅读笔记
- 计算机视觉-论文阅读笔记-基于高性能检测器与表观特征的多目标跟踪
- 论文阅读笔记 - Chubby: The Chubby lock service for loosely-coupled distributed systems
- 图割论文阅读笔记:Interactive Graph Cuts for Optimal Boundary & Region Segmentation of Objects in N-D Images
- [论文笔记] Energy-aware resource allocation heuristics for efficient management of data centers for Cloud computing (FGCS, 2012)
- 论文阅读笔记:Fully Convolutional Networks for Semantic Segmentation
- 阅读笔记:Building a Distributed Full-Text Index for the Web
- jsp The method getServletContext() is undefined for the type in eclipse解决方法
- CVPR2016之A Key Volume Mining Deep Framework for Action Recognition论文阅读(视频关键帧选取)
- The method getJspApplicationContext(ServletContext) is undefined for the type JspFactory的解决方法