ASCII码详解 && PHP字符串处理函数
2013-02-06 11:45
906 查看
ASCII码表
ASCII码大致可以分作三部分組成。第一部分是:ASCII非打印控制字符;
第二部分是:ASCII打印字符;
第三部分是:扩展ASCII打印字符。
第一部分:ASCII非打印控制字符表
ASCII表上的数字0–31分配给了控制字符,用于控制像打印机等一些外围设备。例如,12代表换页/新页功能。此命令指示打印机跳到下一页的开头。(参详ASCII码表中0-31)第二部分:ASCII打印字符
数字 32–126 分配给了能在键盘上找到的字符,当您查看或打印文档时就会出现。数字127代表 DELETE 命令。(参详ASCII码表中32-127)ASCII码表 0-127
| Bin | Dec | Hex | 缩写/字符 | 解释 |
| 00000000 | 0 | 00 | NUL(null) | 空字符 |
| 00000001 | 1 | 01 | SOH(start of headling) | 标题开始 |
| 00000010 | 2 | 02 | STX (start of text) | 正文开始 |
| 00000011 | 3 | 03 | ETX (end of text) | 正文结束 |
| 00000100 | 4 | 04 | EOT (end of transmission) | 传输结束 |
| 00000101 | 5 | 05 | ENQ (enquiry) | 请求 |
| 00000110 | 6 | 06 | ACK (acknowledge) | 收到通知 |
| 00000111 | 7 | 07 | BEL (bell) | 响铃 |
| 00001000 | 8 | 08 | BS (backspace) | 退格 |
| 00001001 | 9 | 09 | HT (horizontal tab) | 水平制表符 |
| 00001010 | 10 | 0A | LF (NL line feed, new line) | 换行键 |
| 00001011 | 11 | 0B | VT (vertical tab) | 垂直制表符 |
| 00001100 | 12 | 0C | FF (NP form feed, new page) | 换页键 |
| 00001101 | 13 | 0D | CR (carriage return) | 回车键 |
| 00001110 | 14 | 0E | SO (shift out) | 不用切换 |
| 00001111 | 15 | 0F | SI (shift in) | 启用切换 |
| 00010000 | 16 | 10 | DLE (data link escape) | 数据链路转义 |
| 00010001 | 17 | 11 | DC1 (device control 1) | 设备控制1 |
| 00010010 | 18 | 12 | DC2 (device control 2) | 设备控制2 |
| 00010011 | 19 | 13 | DC3 (device control 3) | 设备控制3 |
| 00010100 | 20 | 14 | DC4 (device control 4) | 设备控制4 |
| 00010101 | 21 | 15 | NAK (negative acknowledge) | 拒绝接收 |
| 00010110 | 22 | 16 | SYN (synchronous idle) | 同步空闲 |
| 00010111 | 23 | 17 | ETB (end of trans. block) | 传输块结束 |
| 00011000 | 24 | 18 | CAN (cancel) | 取消 |
| 00011001 | 25 | 19 | EM (end of medium) | 介质中断 |
| 00011010 | 26 | 1A | SUB (substitute) | 替补 |
| 00011011 | 27 | 1B | ESC (escape) | 溢出 |
| 00011100 | 28 | 1C | FS (file separator) | 文件分割符 |
| 00011101 | 29 | 1D | GS (group separator) | 分组符 |
| 00011110 | 30 | 1E | RS (record separator) | 记录分离符 |
| 00011111 | 31 | 1F | US (unit separator) | 单元分隔符 |
| 00100000 | 32 | 20 | (space) | 空格 |
| 00100001 | 33 | 21 | ! | |
| 00100010 | 34 | 22 | " | |
| 00100011 | 35 | 23 | # | |
| 00100100 | 36 | 24 | $ | |
| 00100101 | 37 | 25 | % | |
| 00100110 | 38 | 26 | & | |
| 00100111 | 39 | 27 | ' | |
| 00101000 | 40 | 28 | ( | |
| 00101001 | 41 | 29 | ) | |
| 00101010 | 42 | 2A | * | |
| 00101011 | 43 | 2B | + | |
| 00101100 | 44 | 2C | , | |
| 00101101 | 45 | 2D | - | |
| 00101110 | 46 | 2E | . | |
| 00101111 | 47 | 2F | / | |
| 00110000 | 48 | 30 | 0 | |
| 00110001 | 49 | 31 | 1 | |
| 00110010 | 50 | 32 | 2 | |
| 00110011 | 51 | 33 | 3 | |
| 00110100 | 52 | 34 | 4 | |
| 00110101 | 53 | 35 | 5 | |
| 00110110 | 54 | 36 | 6 | |
| 00110111 | 55 | 37 | 7 | |
| 00111000 | 56 | 38 | 8 | |
| 00111001 | 57 | 39 | 9 | |
| 00111010 | 58 | 3A | : | |
| 00111011 | 59 | 3B | ; | |
| 00111100 | 60 | 3C | < | |
| 00111101 | 61 | 3D | = | |
| 00111110 | 62 | 3E | > | |
| 00111111 | 63 | 3F | ? | |
| 01000000 | 64 | 40 | @ | |
| 01000001 | 65 | 41 | A | |
| 01000010 | 66 | 42 | B | |
| 01000011 | 67 | 43 | C | |
| 01000100 | 68 | 44 | D | |
| 01000101 | 69 | 45 | E | |
| 01000110 | 70 | 46 | F | |
| 01000111 | 71 | 47 | G | |
| 01001000 | 72 | 48 | H | |
| 01001001 | 73 | 49 | I | |
| 01001010 | 74 | 4A | J | |
| 01001011 | 75 | 4B | K | |
| 01001100 | 76 | 4C | L | |
| 01001101 | 77 | 4D | M | |
| 01001110 | 78 | 4E | N | |
| 01001111 | 79 | 4F | O | |
| 01010000 | 80 | 50 | P | |
| 01010001 | 81 | 51 | Q | |
| 01010010 | 82 | 52 | R | |
| 01010011 | 83 | 53 | S | |
| 01010100 | 84 | 54 | T | |
| 01010101 | 85 | 55 | U | |
| 01010110 | 86 | 56 | V | |
| 01010111 | 87 | 57 | W | |
| 01011000 | 88 | 58 | X | |
| 01011001 | 89 | 59 | Y | |
| 01011010 | 90 | 5A | Z | |
| 01011011 | 91 | 5B | [ | |
| 01011100 | 92 | 5C | \ | |
| 01011101 | 93 | 5D | ] | |
| 01011110 | 94 | 5E | ^ | |
| 01011111 | 95 | 5F | _ | |
| 01100000 | 96 | 60 | ` | |
| 01100001 | 97 | 61 | a | |
| 01100010 | 98 | 62 | b | |
| 01100011 | 99 | 63 | c | |
| 01100100 | 100 | 64 | d | |
| 01100101 | 101 | 65 | e | |
| 01100110 | 102 | 66 | f | |
| 01100111 | 103 | 67 | g | |
| 01101000 | 104 | 68 | h | |
| 01101001 | 105 | 69 | i | |
| 01101010 | 106 | 6A | j | |
| 01101011 | 107 | 6B | k | |
| 01101100 | 108 | 6C | l | |
| 01101101 | 109 | 6D | m | |
| 01101110 | 110 | 6E | n | |
| 01101111 | 111 | 6F | o | |
| 01110000 | 112 | 70 | p | |
| 01110001 | 113 | 71 | q | |
| 01110010 | 114 | 72 | r | |
| 01110011 | 115 | 73 | s | |
| 01110100 | 116 | 74 | t | |
| 01110101 | 117 | 75 | u | |
| 01110110 | 118 | 76 | v | |
| 01110111 | 119 | 77 | w | |
| 01111000 | 120 | 78 | x | |
| 01111001 | 121 | 79 | y | |
| 01111010 | 122 | 7A | z | |
| 01111011 | 123 | 7B | { | |
| 01111100 | 124 | 7C | | | |
| 01111101 | 125 | 7D | } | |
| 01111110 | 126 | 7E | ~ | |
| 01111111 | 127 | 7F | DEL (delete) | 删除 |
第三部分:扩展ASCII打印字符
扩展的ASCII字符满足了对更多字符的需求。扩展的ASCII包含ASCII中已有的128个字符(数字0–32显示在下图中),又增加了128个字符,总共是256个。即使有了这些更多的字符,许多语言还是包含无法压缩到256个字符中的符号。因此,出现了一些ASCII的变体来囊括地区性字符和符号。例如,许多软件程序把ASCII表(又称作ISO8859-1)用于北美、西欧、澳大利亚和非洲的语言。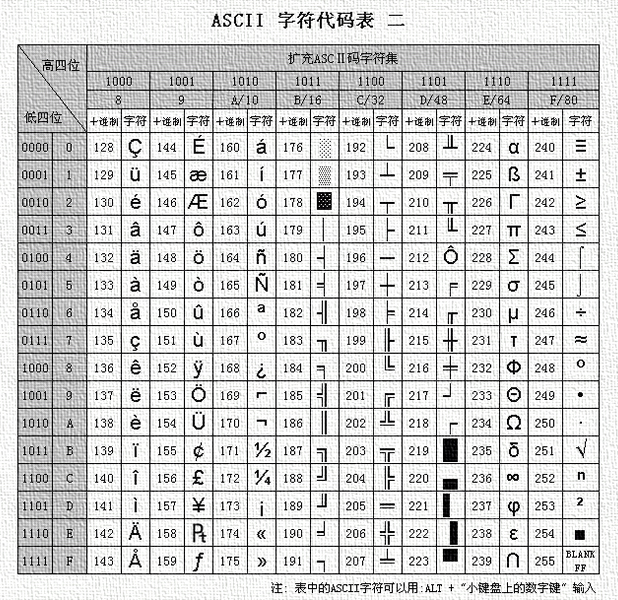
| ASCII码表 |
| 信息在计算机上是用二进制表示的,这种表示法让人理解就很困难。因此计算机上都配有输入和输出设备,这些设备的主要目的就是,以一种人类可阅读的形式将信息在这些设备上显示出来供人阅读理解。为保证人类和设备,设备和计算机之间能进行正确的信息交换,人们编制的统一的信息交换代码,这就是ASCII码表,它的全称是“美国信息交换标准代码”。 |
| 八进制 | 十六进制 | 十进制 | 字符 | 八进制 | 十六进制 | 十进制 | 字符 |
|---|---|---|---|---|---|---|---|
| 00 | 00 | 0 | nul | 100 | 40 | 64 | @ |
| 01 | 01 | 1 | soh | 101 | 41 | 65 | A |
| 02 | 02 | 2 | stx | 102 | 42 | 66 | B |
| 03 | 03 | 3 | etx | 103 | 43 | 67 | C |
| 04 | 04 | 4 | eot | 104 | 44 | 68 | D |
| 05 | 05 | 5 | enq | 105 | 45 | 69 | E |
| 06 | 06 | 6 | ack | 106 | 46 | 70 | F |
| 07 | 07 | 7 | bel | 107 | 47 | 71 | G |
| 10 | 08 | 8 | bs | 110 | 48 | 72 | H |
| 11 | 09 | 9 | ht | 111 | 49 | 73 | I |
| 12 | 0a | 10 | nl | 112 | 4a | 74 | J |
| 13 | 0b | 11 | vt | 113 | 4b | 75 | K |
| 14 | 0c | 12 | ff | 114 | 4c | 76 | L |
| 15 | 0d | 13 | er | 115 | 4d | 77 | M |
| 16 | 0e | 14 | so | 116 | 4e | 78 | N |
| 17 | 0f | 15 | si | 117 | 4f | 79 | O |
| 20 | 10 | 16 | dle | 120 | 50 | 80 | P |
| 21 | 11 | 17 | dc1 | 121 | 51 | 81 | Q |
| 22 | 12 | 18 | dc2 | 122 | 52 | 82 | R |
| 23 | 13 | 19 | dc3 | 123 | 53 | 83 | S |
| 24 | 14 | 20 | dc4 | 124 | 54 | 84 | T |
| 25 | 15 | 21 | nak | 125 | 55 | 85 | U |
| 26 | 16 | 22 | syn | 126 | 56 | 86 | V |
| 27 | 17 | 23 | etb | 127 | 57 | 87 | W |
| 30 | 18 | 24 | can | 130 | 58 | 88 | X |
| 31 | 19 | 25 | em | 131 | 59 | 89 | Y |
| 32 | 1a | 26 | sub | 132 | 5a | 90 | Z |
| 33 | 1b | 27 | esc | 133 | 5b | 91 | [ |
| 34 | 1c | 28 | fs | 134 | 5c | 92 | \ |
| 35 | 1d | 29 | gs | 135 | 5d | 93 | ] |
| 36 | 1e | 30 | re | 136 | 5e | 94 | ^ |
| 37 | 1f | 31 | us | 137 | 5f | 95 | _ |
| 40 | 20 | 32 | sp | 140 | 60 | 96 | ' |
| 41 | 21 | 33 | ! | 141 | 61 | 97 | a |
| 42 | 22 | 34 | " | 142 | 62 | 98 | b |
| 43 | 23 | 35 | # | 143 | 63 | 99 | c |
| 44 | 24 | 36 | $ | 144 | 64 | 100 | d |
| 45 | 25 | 37 | % | 145 | 65 | 101 | e |
| 46 | 26 | 38 | & | 146 | 66 | 102 | f |
| 47 | 27 | 39 | ` | 147 | 67 | 103 | g |
| 50 | 28 | 40 | ( | 150 | 68 | 104 | h |
| 51 | 29 | 41 | ) | 151 | 69 | 105 | i |
| 52 | 2a | 42 | * | 152 | 6a | 106 | j |
| 53 | 2b | 43 | + | 153 | 6b | 107 | k |
| 54 | 2c | 44 | , | 154 | 6c | 108 | l |
| 55 | 2d | 45 | - | 155 | 6d | 109 | m |
| 56 | 2e | 46 | . | 156 | 6e | 110 | n |
| 57 | 2f | 47 | / | 157 | 6f | 111 | o |
| 60 | 30 | 48 | 0 | 160 | 70 | 112 | p |
| 61 | 31 | 49 | 1 | 161 | 71 | 113 | q |
| 62 | 32 | 50 | 2 | 162 | 72 | 114 | r |
| 63 | 33 | 51 | 3 | 163 | 73 | 115 | s |
| 64 | 34 | 52 | 4 | 164 | 74 | 116 | t |
| 65 | 35 | 53 | 5 | 165 | 75 | 117 | u |
| 66 | 36 | 54 | 6 | 166 | 76 | 118 | v |
| 67 | 37 | 55 | 7 | 167 | 77 | 119 | w |
| 70 | 38 | 56 | 8 | 170 | 78 | 120 | x |
| 71 | 39 | 57 | 9 | 171 | 79 | 121 | y |
| 72 | 3a | 58 | : | 172 | 7a | 122 | z |
| 73 | 3b | 59 | ; | 173 | 7b | 123 | { |
| 74 | 3c | 60 | < | 174 | 7c | 124 | | |
| 75 | 3d | 61 | = | 175 | 7d | 125 | } |
| 76 | 3e | 62 | > | 176 | 7e | 126 | ~ |
| 77 | 3f | 63 | ? | 177 | 7f | 127 | del |
php字符串处理函数大全
addcslashes — 为字符串里面的部分字符添加反斜线转义字符addslashes — 用指定的方式对字符串里面的字符进行转义
bin2hex — 将二进制数据转换成十六进制表示
chop — rtrim() 的别名函数
chr — 返回一个字符的ASCII码
chunk_split — 按一定的字符长度将字符串分割成小块
convert_cyr_string — 将斯拉夫语字符转换为别的字符
convert_uudecode — 解密一个字符串
convert_uuencode — 加密一个字符串
count_chars — 返回一个字符串里面的字符使用信息
crc32 — 计算一个字符串的crc32多项式
crypt — 单向散列加密函数
echo — 用以显示一些内容
explode — 将一个字符串用分割符转变为一数组形式
fprintf — 按照要求对数据进行返回,并直接写入文档流
get_html_translation_table — 返回可以转换的HTML实体
hebrev — 将Hebrew编码的字符串转换为可视的文本
hebrevc — 将Hebrew编码的字符串转换为可视的文本
html_entity_decode — htmlentities ()函数的反函数,将HTML实体转换为字符
htmlentities — 将字符串中一些字符转换为HTML实体
htmlspecialchars_decode —htmlspecialchars()函数的反函数,将HTML实体转换为字符
htmlspecialchars — 将字符串中一些字符转换为HTML实体
implode — 将数组用特定的分割符转变为字符串
join — 将数组转变为字符串,implode()函数的别名
levenshtein — 计算两个词的差别大小
localeconv — 获取数字相关的格式定义
ltrim — 去除字符串左侧的空白或者指定的字符
md5_file — 将一个文件进行MD5算法加密
md5 — 将一个字符串进行MD5算法加密
metaphone — 判断一个字符串的发音规则
money_format — 按照参数对数字进行格式化的输出
nl_langinfo — 查询语言和本地信息
nl2br — 将字符串中的换行符“\n”替换成“<br/>”
number_format — 按照参数对数字进行格式化的输出
ord — 将一个ASCII码转换为一个字符
parse_str — 把一定格式的字符串转变为变量和值
print — 用以输出一个单独的值
printf — 按照要求对数据进行显示
quoted_printable_decode — 将一个字符串加密为一个8位的二进制字符串
quotemeta — 对若干个特定字符进行转义
rtrim — 去除字符串右侧的空白或者指定的字符
setlocale — 设置关于数字,日期等等的本地格式
sha1_file — 将一个文件进行SHA1算法加密
sha1 — 将一个字符串进行SHA1算法加密
similar_text — 比较两个字符串,返回系统认为的相似字符个数
soundex — 判断一个字符串的发音规则
sprintf — 按照要求对数据进行返回,但是不输出
sscanf — 可以对字符串进行格式化
str_ireplace — 像str_replace()函数一样匹配和替换字符串,但是不区分大小写
str_pad — 对字符串进行两侧的补白
str_repeat — 对字符串进行重复组合
str_replace — 匹配和替换字符串
str_rot13 — 将字符串进行ROT13加密处理
str_shuffle — 对一个字符串里面的字符进行随机排序
str_split — 将一个字符串按照字符间距分割为一个数组
str_word_count — 获取字符串里面的英文单词信息
strcasecmp — 对字符串进行大小比较,不区分大小写
strchr — 通过比较返回一个字符串的部分strstr()函数的别名
strcmp — 对字符串进行大小比较
strcoll – 根据本地设置对字符串进行大小比较
strcspn — 返回字符连续非匹配长度的值
strip_tags — 去除一个字符串里面的HTML和PHP代码
stripcslashes — 反转义addcslashes()函数转义处理过的字符串
stripos — 查找并返回首个匹配项的位置,匹配不区分大小写
stripslashes — 反转义addslashes()函数转义处理过的字符串
stristr — 通过比较返回一个字符串的部分,比较时不区分大小写
strlen — 获取一个字符串的编码长度
strnatcasecmp — 使用自然排序法对字符串进行大小比较,不区分大小写
strnatcmp — 使用自然排序法对字符串进行大小比较
strncasecmp — 对字符串的前N个字符进行大小比较,不区分大小写
strncmp — 对字符串的前N个字符进行大小比较
strpbrk — 通过比较返回一个字符串的部分
strpos — 查找并返回首个匹配项的位置
strrchr — 通过从后往前比较返回一个字符串的部分
strrev — 将字符串里面的所有字母反向排列
strripos — 从后往前查找并返回首个匹配项的位置,匹配不区分大小写
strrpos – 从后往前查找并返回首个匹配项的位置
strspn — 匹配并返回字符连续出现长度的值
strstr — 通过比较返回一个字符串的部分
strtok — 用指定的若干个字符来分割字符串
strtolower — 将字符串转变为小写
strtoupper –将字符串转变为大写
strtr — 对字符串比较替换
substr_compare — 对字符串进行截取后的比较
substr_count — 计算字符串中某字符段的出现次数
substr_replace — 对字符串中的部分字符进行替换
substr — 对字符串进行截取
trim — 去除字符串两边的空白或者指定的字符
ucfirst — 将所给字符串的第一个字母转换为大写
ucwords — 将所给字符串的每一个英文单词的第一个字母变成大写
vfprintf — 按照要求对数据进行返回,并直接写入文档流
vprintf — 按照要求对数据进行显示
vsprintf — 按照要求对数据进行返回,但是不输出
wordwrap — 按照一定的字符长度分割字符串

相关文章推荐
- PHP详解ASCII码对照表与字符转换 && 字符串处理函数库
- php字符串处理函数详解
- 详解PHP处理字符串类似indexof的方法函数
- 正则表达式函数实例详解(及PHP字符串处理函数)
- 关于PHP内置的字符串处理函数详解
- php字符串处理函数大全
- php字符串处理函数大全
- php字符串处理函数大全
- PHP字符串替换str_replace()函数4种用法详解
- php之字符串处理函数
- php-设置关键词高亮的字符串处理函数
- PHP--字符串处理函数
- Php 字符串处理函数大全
- PHP字符串替换str_replace()函数4种用法详解
- PHP常见字符串处理函数用法示例【转换,转义,截取,比较,查找,反转,切割】
- php字符串处理函数大全(学习)
- PHP 中英文混合排版中处理字符串常用的函数
- PHP 数组处理使用foreach、list、each等三个函数详解
- php 数组处理函数extract详解及实例代码
- php学习第二章:字符串处理函数(一)