快速排序、希尔排序、插入排序、选择排序、归并排序、堆排序总结
2012-10-29 11:45
288 查看
一、快速排序的基本思想
设当前待排序的无序区为R[low..high],利用分治法可将快速排序的基本思想描述为:
①分解:
在R[low..high]中任选一个记录作为基准(Pivot),以此基准将当前无序区划分为左、右两个较小的子区间R[low..pivotpos-1)和R[pivotpos+1..high],并使左边子区间中所有记录的关键字均小于等于基准记录(不妨记为pivot)的关键字pivot.key,右边的子区间中所有记录的关键字均大于等于pivot.key,而基准记录pivot则位于正确的位置(pivotpos)上,它无须参加后续的排序。
注意:
划分的关键是要求出基准记录所在的位置pivotpos。划分的结果可以简单地表示为(注意pivot=R[pivotpos]):
R[low..pivotpos-1].keys≤R[pivotpos].key≤R[pivotpos+1..high].keys
其中low≤pivotpos≤high。
②求解:
通过递归调用快速排序对左、右子区间R[low..pivotpos-1]和R[pivotpos+1..high]快速排序。
完整的代码如下:
二、希尔排序
希尔排序(Shell Sort)又称为缩小增量排序,输入插入排序算法,是对直接排序算法的一种改进。本文介绍希尔排序算法。
对于插入排序算法来说,如果原来的数据就是有序的,那么数据就不需要移动,而插入排序算法的效率主要消耗在数据的移动中。因此可知:如果数据的本身就是有序的或者本身基本有序,那么效率就会得到提高。
希尔排序的基本思想是:将需要排序的序列划分成为若干个较小的子序列,对子序列进行插入排序,通过则插入排序能够使得原来序列成为基本有序。这样通过对较小的序列进行插入排序,然后对基本有序的数列进行插入排序,能够提高插入排序算法的效率。
在希尔排序中首先解决的是子序列的选择问题。对于子序列的构成不是简单的分段,而是采取相隔某个增量的数据组成一个序列。增量一般的选择原则是:取上一个增量的一半作为此次序列的划分增量。首次选择序列长度的一半为增量。
先假如:数组的长度为10,数组元素为:25、19、6、58、34、10、7、98、160、0
整个希尔排序的算法过程如下如所示:
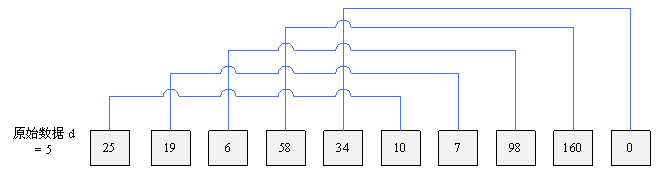
上图是原始数据和第一次选择的增量 d = 5。本次排序的结果如下图:
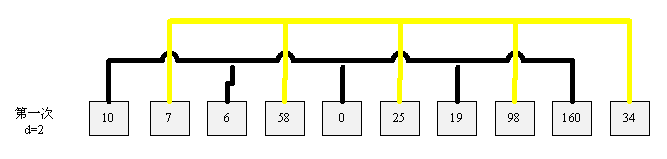
上图是第一次排序的结果,本次选择增量为 d=2。 本次排序的结果如下图:

当d=1 是进行最后一次排序,本次排序相当于冒泡排序的某一次循环。最终结果如下:

在实际使用过程中,带排序的数据肯定不是只有十个,但是上述是希尔排序的思想。其实希尔排序只是插入排序的一种优化。
C++实现希尔排序的代码如下所示:
三、插入排序
直接插入排序(direct Insert Sort)的基本思想是:顺序地将待排序的记录按其关键码的大小插入到已排序的记录子序列的适当位置。子序列的记录个数从1开始逐渐增大,当子序列的记录个数与顺序表中的记录个数相同时排序完毕。
(1)时间、空间复杂度
插入排序虽然在最坏情况下复杂性为O(n2),但是对于小规模输入来说,插入排序法是一个快速的排序法。从空间来看,它只需要一个元素的辅助空间,用于元素的位置交换O(1)。
(2)稳定性:
插入排序是稳定的;因为具有同一值的元素必然插在具有同一值得前一个元素的后面,即相对次序不变。
四、简单选择排序
简单选择排序的基本思想:第i趟简单选择排序是指通过n-i次关键字的比较,从n-i+1个记录中选出关键字最小的记录,并和第i个记录进行交换。共需进行i-1趟比较,直到所有记录排序完成为止。例如:进行第i趟选择时,从当前候选记录中选出关键字最小的k号记录,并和第i个记录进行交换。
实现代码如下:
(1)关键字比较次数
无论文件初始状态如何,在第i趟排序中选出最小关键字的记录,需做n-i次比较,因此,总的比较次数为:
n(n-1)/2=0(n2)
(2)记录的移动次数
当初始文件为正序时,移动次数为0
文件初态为反序时,每趟排序均要执行交换操作,总的移动次数取最大值3(n-1)。
直接选择排序的平均时间复杂度为O(n2)。
(3)直接选择排序是一个就地排序
(4)稳定性分析
直接选择排序是不稳定的。
【例】反例[2,2,1]
五、归并排序
六、堆排序
七、冒泡排序
// 将小元素冒泡到最前面,首先操作的是小元素
void Bubble_Sort1(int array[] , int len)
{
int i , j;
for(i = 0 ; i < len - 1 ; ++i)
{
for(j = i + 1 ; j < len ; ++j)
{
if(array[j] < array[i])
swap(array[i] , array[j] );
}
}
}
// 将最大的元素冒泡到最后面
void Bubble_Sort2(int array[] , int len)
{
int i , j;
for(i = 0 ; i < len ; ++i) //注意和上面的算法对照此循环
{
for(j = 0 ; j < len - 1 - i ; ++j)
{
if(array[j] > array[j + 1])
swap(array[j] , array[j+1] );
}
}
}
// 双向冒泡
void Bubble_Sort3(int array[] , int len)
{
int left , right , i;
left = 0 , right = len - 1;
while(left < right)
{
for(i = left ; i < right ; ++i) // 从左到右冒泡
{
if(array[i + 1] < array[i])
swap(array[i] , array[i+1]);
}
--right;
for(i = right ; i > left ; --i) // 从右到左冒泡
{
if(array[i ] < array[i - 1])
swap(array[i] , array[i-1]);
}
++left;
}
}
设当前待排序的无序区为R[low..high],利用分治法可将快速排序的基本思想描述为:
①分解:
在R[low..high]中任选一个记录作为基准(Pivot),以此基准将当前无序区划分为左、右两个较小的子区间R[low..pivotpos-1)和R[pivotpos+1..high],并使左边子区间中所有记录的关键字均小于等于基准记录(不妨记为pivot)的关键字pivot.key,右边的子区间中所有记录的关键字均大于等于pivot.key,而基准记录pivot则位于正确的位置(pivotpos)上,它无须参加后续的排序。
注意:
划分的关键是要求出基准记录所在的位置pivotpos。划分的结果可以简单地表示为(注意pivot=R[pivotpos]):
R[low..pivotpos-1].keys≤R[pivotpos].key≤R[pivotpos+1..high].keys
其中low≤pivotpos≤high。
②求解:
通过递归调用快速排序对左、右子区间R[low..pivotpos-1]和R[pivotpos+1..high]快速排序。
完整的代码如下:
#include<iostream>
#include<stack>
using namespace std;
int partition(int *arr , int low , int high)
{
int pivo = arr[low];
while(low < high)
{
while(low < high && arr[high] >= pivo)
--high;
arr[low] = arr[high];
while(low < high && arr[low] <= pivo)
++low;
arr[high] = arr[low];
}
arr[low] = pivo;
return low;
}
// 快速排序 递归
void qsort(int *arr , int low , int high)
{
if(low < high)
{
int pivo = partition(arr , low , high);
qsort(arr , low , pivo-1);
qsort(arr , pivo+1 , high);
}
}
// 快速排序 非递归
void qsort_no_recursive(int *arr , int low , int high)
{
stack<int>s;
int pivo;
if(low < high)
{
pivo = partition(arr , low , high);
if(low < pivo - 1)
{
s.push(low);
s.push(pivo-1);
}
if(pivo + 1 < high)
{
s.push(pivo+1);
s.push(high);
}
while(!s.empty())
{
high = s.top();
s.pop();
low = s.top();
s.pop();
pivo = partition(arr , low , high);
if(low < pivo - 1)
{
s.push(low);
s.push(pivo-1);
}
if(pivo + 1 < high)
{
s.push(pivo+1);
s.push(high);
}
}//while
}//if
}
//简单示例
int main(void)
{
int i , a[11] = {20,11,12,5,6,13,8,9,14,7,10};
printf("排序前的数据为:\n");
for(i = 0 ; i < 11 ; ++i)
printf("%d ",a[i]);
printf("\n");
//qsort(a , 0 , 10);
qsort_no_recursive(a , 0 , 10);
printf("排序后的数据为:\n");
for(i = 0 ; i < 11 ; ++i)
printf("%d ",a[i]);
printf("\n");
return 0;
}二、希尔排序
希尔排序(Shell Sort)又称为缩小增量排序,输入插入排序算法,是对直接排序算法的一种改进。本文介绍希尔排序算法。
对于插入排序算法来说,如果原来的数据就是有序的,那么数据就不需要移动,而插入排序算法的效率主要消耗在数据的移动中。因此可知:如果数据的本身就是有序的或者本身基本有序,那么效率就会得到提高。
希尔排序的基本思想是:将需要排序的序列划分成为若干个较小的子序列,对子序列进行插入排序,通过则插入排序能够使得原来序列成为基本有序。这样通过对较小的序列进行插入排序,然后对基本有序的数列进行插入排序,能够提高插入排序算法的效率。
在希尔排序中首先解决的是子序列的选择问题。对于子序列的构成不是简单的分段,而是采取相隔某个增量的数据组成一个序列。增量一般的选择原则是:取上一个增量的一半作为此次序列的划分增量。首次选择序列长度的一半为增量。
先假如:数组的长度为10,数组元素为:25、19、6、58、34、10、7、98、160、0
整个希尔排序的算法过程如下如所示:
上图是原始数据和第一次选择的增量 d = 5。本次排序的结果如下图:
上图是第一次排序的结果,本次选择增量为 d=2。 本次排序的结果如下图:
当d=1 是进行最后一次排序,本次排序相当于冒泡排序的某一次循环。最终结果如下:
在实际使用过程中,带排序的数据肯定不是只有十个,但是上述是希尔排序的思想。其实希尔排序只是插入排序的一种优化。
C++实现希尔排序的代码如下所示:
#include<iostream>
using namespace std;
void shell_sort(int array[] , int length)
{
int i , j , temp;
int d = length/2; // 设置希尔排序的初始增量
while(d >= 1)
{
for(i = d ; i < length ; ++i)
{
temp = array[i];
j = i - d; // 步长为d的前面一个位置
while(j >= 0 && array[j] > temp) // 从后往前进行插入排序
{
array[j + d] = array[j];
j -= d;
}
array[j + d] = temp; // 找到了插入位置
}
d /= 2;
}
}
int main(void)
{
int i , a[]={25,19,6,58,34,10,7,98,160,0};
shell_sort(a , 10);
for(i = 0 ; i < 10 ; ++i)
cout<<a[i]<<" ";
cout<<endl;
system("pause");
return 0;
}
// 模板
template<class T> void ShellSort(T *a,int len) //希尔排序算法
{
int gap , j;
for(gap = len / 2 ; gap > 0 ; gap /= 2)
{
for(j = gap;j < len ; ++j) //j从gap个元素开始
{
if(a[j] < a[j - gap]) //每个元素与自己组内的数据进行直接插入排序
{
T temp = a[j];
int k = j - gap;
while(k >= 0 && a[k] > temp)
{
a[k + gap] = a[k];
k -= gap;
}
a[k + gap] = temp;
}
}
}
}三、插入排序
直接插入排序(direct Insert Sort)的基本思想是:顺序地将待排序的记录按其关键码的大小插入到已排序的记录子序列的适当位置。子序列的记录个数从1开始逐渐增大,当子序列的记录个数与顺序表中的记录个数相同时排序完毕。
void InsertSort(int array[] , int length) // 无哨兵的插入排序
{
int i , j , temp;
for(i = 1 ; i < length ; ++i)
{
if(array[i] < array[i-1])
{
temp = array[i];
for(j = i - 1 ; j >= 0 && array[j] > temp ;--j)
array[j + 1] = array[j];
array[j + 1] = temp;
}
}
}
void InsertSort(int array[] , int length) // 有哨兵的插入排序
{
int i , j ;
for(i = 1 ; i <= length ; ++i)
{
if(array[i] < array[i-1])
{
array[0] = array[i];
for(j = i - 1 ; array[j] > array[0] ;--j)
array[j + 1] = array[j];
array[j + 1] = array[0];
}
}
}(1)时间、空间复杂度
插入排序虽然在最坏情况下复杂性为O(n2),但是对于小规模输入来说,插入排序法是一个快速的排序法。从空间来看,它只需要一个元素的辅助空间,用于元素的位置交换O(1)。
(2)稳定性:
插入排序是稳定的;因为具有同一值的元素必然插在具有同一值得前一个元素的后面,即相对次序不变。
四、简单选择排序
简单选择排序的基本思想:第i趟简单选择排序是指通过n-i次关键字的比较,从n-i+1个记录中选出关键字最小的记录,并和第i个记录进行交换。共需进行i-1趟比较,直到所有记录排序完成为止。例如:进行第i趟选择时,从当前候选记录中选出关键字最小的k号记录,并和第i个记录进行交换。
实现代码如下:
void SelectSort(int array[] , int length) // 简单选择排序
{
int i , j , k;
for(i = 0 ; i < length-1 ; ++i)
{
k = i;
for(j = i + 1 ; j < length ; ++j) // 从后面选择一个最小的记录
{
if(array[j] < array[k])
k = j;
}
if(k != i) // 与第i个记录交换
swap(array[i] , array[k]);
}
}(1)关键字比较次数
无论文件初始状态如何,在第i趟排序中选出最小关键字的记录,需做n-i次比较,因此,总的比较次数为:
n(n-1)/2=0(n2)
(2)记录的移动次数
当初始文件为正序时,移动次数为0
文件初态为反序时,每趟排序均要执行交换操作,总的移动次数取最大值3(n-1)。
直接选择排序的平均时间复杂度为O(n2)。
(3)直接选择排序是一个就地排序
(4)稳定性分析
直接选择排序是不稳定的。
【例】反例[2,2,1]
五、归并排序
void Merge(int array[] , int low , int mid , int high)
{
int i , j , k;
int *temp = (int *)malloc((high - low + 1)*sizeof(int));
i = low , j = mid + 1 , k = 0;
while(i <= mid && j <= high)
{
if(array[i] < array[j]) // 进行排序存入动态分配的数组中
temp[k++] = array[i++];
else
temp[k++] = array[j++];
}
while(i <= mid) // 如果前一半中还有未处理完的数据,按顺序移入动态分配的数组内
temp[k++] = array[i++];
while(j <= high) // 如果前一半中还有未处理完的数据,按顺序移入动态分配的数组内
temp[k++] = array[j++];
for(i = low , j = 0; i<= high ; ++i)
array[i] = temp[j++];
free(temp);
}
void Msort(int array[] , int low , int high)
{
int mid;
if(low < high)
{
mid = (low + high)>>1;
Msort(array , low , mid);
Msort(array , mid + 1 , high);
Merge(array , low , mid , high);
}
}六、堆排序
void HeapAdjust(int array[] , int s , int m) // 对堆进行调整,使下标从s到m的无序序列成为一个大顶堆
{
int j , temp = array[s];
for(j = 2*s; j <= m ; j *= 2)
{
if(j < m && array[j] < array[j + 1]) // 如果结点的左孩子小于右孩子增加j的值
++j; // 用于记录较大的结点的下标
if(temp >= array[j]) // 如果父结点大于等于两个孩子,则满足大顶堆的定义,跳出循环
break;
array[s] = array[j]; // 否则用较大的结点替换父结点
s = j; // 记录下替换父结点的结点下标
}
array[s] = temp; // 把原来的父结点移动到替换父结点的结点位置
}
void HeapSort(int array[] , int len)
{
int i;
for(i = len / 2; i >= 0 ; --i) // 建立大顶堆
HeapAdjust(array , i , len-1);
for(i = len - 1 ; i > 0 ; --i)
{
swap(array[0] , array[i] ); // 第个元素和最后一个元素进行交换
HeapAdjust(array , 0 , i-1); // 建立大顶堆
}
}七、冒泡排序
// 将小元素冒泡到最前面,首先操作的是小元素
void Bubble_Sort1(int array[] , int len)
{
int i , j;
for(i = 0 ; i < len - 1 ; ++i)
{
for(j = i + 1 ; j < len ; ++j)
{
if(array[j] < array[i])
swap(array[i] , array[j] );
}
}
}
// 将最大的元素冒泡到最后面
void Bubble_Sort2(int array[] , int len)
{
int i , j;
for(i = 0 ; i < len ; ++i) //注意和上面的算法对照此循环
{
for(j = 0 ; j < len - 1 - i ; ++j)
{
if(array[j] > array[j + 1])
swap(array[j] , array[j+1] );
}
}
}
// 双向冒泡
void Bubble_Sort3(int array[] , int len)
{
int left , right , i;
left = 0 , right = len - 1;
while(left < right)
{
for(i = left ; i < right ; ++i) // 从左到右冒泡
{
if(array[i + 1] < array[i])
swap(array[i] , array[i+1]);
}
--right;
for(i = right ; i > left ; --i) // 从右到左冒泡
{
if(array[i ] < array[i - 1])
swap(array[i] , array[i-1]);
}
++left;
}
}

相关文章推荐
- 面试珠玑 快速排序、希尔排序、插入排序、选择排序、归并排序、堆排序总结
- 数据结构与算法从零开始系列:冒泡排序、选择排序、插入排序、希尔排序、堆排序、快速排序、归并排序、基数排序
- 几种常用的排序算法的分析及java实现(希尔排序,堆排序,归并排序,快速排序,选择排序,插入排序,冒泡排序)
- 基本的排序算法:冒泡排序、插入排序、希尔排序、选择排序、归并排序、快速排序、堆排序
- 【程序员笔试面试必会——排序①】Python实现 冒泡排序、选择排序、插入排序、归并排序、快速排序、堆排序、希尔排序
- 牛客网Java刷题知识点之插入排序(直接插入排序和希尔排序)、选择排序(直接选择排序和堆排序)、冒泡排序、快速排序、归并排序和基数排序(博主推荐)
- 各种排序算法总结----基数排序、归并排序、插入排序、冒泡排序、选择排序、快速排序、堆排序、希尔排序
- 常见排序集合(冒泡排序,选择排序,直接插入排序,二分插入排序,快速排序,希尔排序,归并排序)
- 元素排序几种常用的排序算法的分析及java实现(希尔排序,堆排序,归并排序,快速排序,选择排序,插入排序,冒泡排序)
- 插入排序、二分插入排序、希尔排序、选择排序、冒泡排序、鸡尾酒排序、快速排序、堆排序、归并排序
- 算法分析中最常用的几种排序算法(插入排序、希尔排序、冒泡排序、选择排序、快速排序,归并排序)C 语言版
- 几种常见排序算法之Java实现(插入排序、希尔排序、冒泡排序、快速排序、选择排序、归并排序)
- 插入排序、冒泡排序、选择排序、希尔排序、快速排序、归并排序、堆排序和LST基数排序——C++实现
- 直通BAT-排序1(冒泡排序、选择排序、插入排序、归并排序、快速排序、堆排序、希尔排序)
- 面试珠玑 快速排序、希尔排序、插入排序、选择排序、归并排序、堆排序总结
- 基本排序算法(冒泡排序 选择排序 插入排序 快速排序 归并排序 基数排序 希尔排序)
- 冒泡排序、选择排序、插入排序、希尔排序、快速排序、归并排序六大排序大总结
- 各种排序算法实现——基数排序、归并排序、插入排序、冒泡排序、选择排序、快速排序、堆排序、希尔排序
- 常见排序算法的实现(归并排序、快速排序、堆排序、选择排序、插入排序、希尔排序)
- 归并排序,堆排序,基数排序,希尔排序,快速排序,交换排序,选择排序和插入排序的总结和比较