计数排序,基数排序和桶排序
2012-08-04 20:11
288 查看
计数排序,基数排序,桶排序等非比较排序算法,平均时间复杂度都是O(n)。这些排序因为其待排序元素本身就含有了定位特征,因而不需要比较就可以确定其前后位置,从而可以突破比较排序算法时间复杂度O(nlgn)的理论下限。
假定输入是个数组A【1...n】, length【A】=n。 另外还需要一个存放排序结果的数组B【1...n】,以及提供临时存储区的C【0...k】(k是所有元素中最大的一个)。算法伪代码:

算法的步骤如下:
找出待排序的数组中最大和最小的元素
统计数组中每个值为t的元素出现的次数,存入数组C的第t项
对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加)
反向填充目标数组:将每个元素t放在新数组的第C(t)项,每放一个元素就将C(t)减去1
算法实现:
假设我们有一些二元组(a,b),要对它们进行以a为首要关键字,b的次要关键字的排序。我们可以先把它们先按照首要关键字排序,分成首要关键字相同的若干堆。然后,在按照次要关键值分别对每一堆进行单独排序。最后再把这些堆串连到一起,使首要关键字较小的一堆排在上面。按这种方式的基数排序称为MSD(Most Significant Dight)排序。第二种方式是从最低有效关键字开始排序,称为LSD(Least Significant Dight)排序。首先对所有的数据按照次要关键字排序,然后对所有的数据按照首要关键字排序。要注意的是,使用的排序算法必须是稳定的,否则就会取消前一次排序的结果。由于不需要分堆对每堆单独排序,LSD方法往往比MSD简单而开销小。下文介绍的方法全部是基于LSD的。
基数排序的简单描述就是将数字拆分为个位十位百位,每个位依次排序。因为这对算法稳定要求高,所以我们对数位排序用到上一个排序方法计数排序。因为基数排序要经过d (数据长度)次排序, 每次使用计数排序, 计数排序的复杂度为 On),d 相当于常量和N无关,所以基数排序也是 O(n)。基数排序虽然是线性复杂度, 即对n个数字处理了n次,但是每一次代价都比较高, 而且使用计数排序的基数排序不能进行原地排序,需要更多的内存, 并且快速排序可能更好地利用硬件的缓存, 所以比较起来,像快速排序这些原地排序算法更可取。对于一个位数有限的十进制数,我们可以把它看作一个多元组,从高位到低位关键字重要程度依次递减。[b]可以使用基数排序对一些位数有限的十进制数排序。[/b]
例如我们将一个三位数分成,个位,十位,百位三部分。我们要对七个三位数来进行排序,依次对其个位,十位,百位进行排序,如下图:

很显然,每一位的数的大小都在[0,9]中,对于每一位的排序用计数排序再适合不过。
算法实现:
扫描序列A,根据每个元素的值所属的区间,放入指定的桶中(顺序放置)。
对每个桶中的元素进行排序,什么排序算法都可以,例如插入排序。
依次收集每个桶中的元素,顺序放置到输出序列中。
具体过程可以参考动画演示。
算法伪代码为:

具体代码:
三种线性排序的比较
从整体上来说,计数排序,桶排序都是非基于比较的排序算法,而其时间复杂度依赖于数据的范围,桶排序还依赖于空间的开销和数据的分布。而基数排序是一种对多元组排序的有效方法,具体实现要用到计数排序或桶排序。
相对于快速排序、堆排序等基于比较的排序算法,计数排序、桶排序和基数排序限制较多,不如快速排序、堆排序等算法灵活性好。但反过来讲,这三种线性排序算法之所以能够达到线性时间,是因为充分利用了待排序数据的特性,如果生硬得使用快速排序、堆排序等算法,就相当于浪费了这些特性,因而达不到更高的效率。
参考资料
/article/6348221.html
http://www.byvoid.com/blog/sort-radix/
计数排序(Counting sort)
计数排序(Counting sort)是一种稳定的排序算法。计数排序是最简单的特例,由于用来计数的数组C的长度取决于待排序数组中数据的范围(等于待排序数组的最大值与最小值的差加上1),这使得计数排序对于数据范围很大的数组,需要大量时间和内存,适用性不高。例如:计数排序是用来排序0到100之间的数字的最好的算法,但是它不适合按字母顺序排序人名。但是,计数排序可以用在基数排序中的算法来排序数据范围很大的数组。当输入的元素是 n 个 0 到 k 之间的整数时,它的运行时间是 Θ(n + k)。假定输入是个数组A【1...n】, length【A】=n。 另外还需要一个存放排序结果的数组B【1...n】,以及提供临时存储区的C【0...k】(k是所有元素中最大的一个)。算法伪代码:
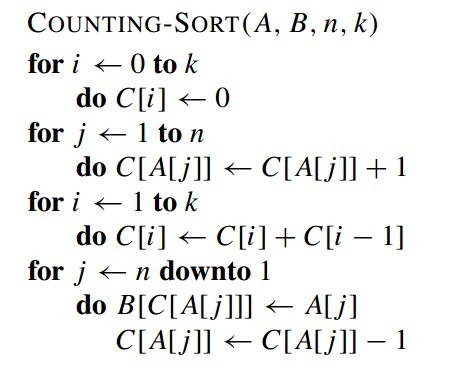
算法的步骤如下:
找出待排序的数组中最大和最小的元素
统计数组中每个值为t的元素出现的次数,存入数组C的第t项
对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加)
反向填充目标数组:将每个元素t放在新数组的第C(t)项,每放一个元素就将C(t)减去1
算法实现:
/*
*算法的步骤如下:
1、找出待排序的数组中最大和最小的元素
2、统计数组中每个值为t的元素出现的次数,存入数组C的第t项
3、对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加)
4、反向填充目标数组:将每个元素t放在新数组的第C(t)项,每放一个元素就将C(t)减去1
* */
public class CountingSort {// 类似bitmap排序
public static void countSort(int[] a, int[] b, final int k) {// k>=n
int[] c = new int[k + 1];
for (int i = 0; i < k; i++) {c[i] = 0;
}
for (int i = 0; i < a.length; i++) {c[a[i]]++;
}
System.out.println("\n****************");System.out.println("计数排序第2步后,临时数组C变为:");for (int m:c) {System.out.print(m + " ");
}
for (int i = 1; i <= k; i++) {c[i] += c[i - 1];
}
System.out.println("\n计数排序第3步后,临时数组C变为:");for (int m:c) {System.out.print(m + " ");
}
for (int i = a.length - 1; i >= 0; i--) {b[c[a[i]] - 1] = a[i];//C[A[i]]-1 就代表小于等于元素A[i]的元素个数,就是A[i]在B的位置
c[a[i]]--;
}
System.out.println("\n计数排序第4步后,临时数组C变为:");for (int n:c) {System.out.print(n + " ");
}
System.out.println("\n计数排序第4步后,数组B变为:");for (int t:b) {System.out.print(t + " ");
}
System.out.println();
System.out.println("****************\n");}
public static int getMaxNumber(int[] a) {int max = 0;
for (int i = 0; i < a.length; i++) {if (max < a[i]) {max = a[i];
}
}
return max;
}
public static void main(String[] args) {int[] a = new int[] { 2, 5, 3, 0, 2, 3, 0, 3};int[] b = new int[a.length];
System.out.println("计数排序前为:");for (int i = 0; i < a.length; i++) {System.out.print(a[i] + " ");
}
System.out.println();
countSort(a, b, getMaxNumber(a));
System.out.println("计数排序后为:");for (int i = 0; i < a.length; i++) {System.out.print(b[i] + " ");
}
System.out.println();
}
}
基数排序(radix sorting)
基数排序(radix sorting)将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。 然后 从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。具体过程可以参考动画演示。假设我们有一些二元组(a,b),要对它们进行以a为首要关键字,b的次要关键字的排序。我们可以先把它们先按照首要关键字排序,分成首要关键字相同的若干堆。然后,在按照次要关键值分别对每一堆进行单独排序。最后再把这些堆串连到一起,使首要关键字较小的一堆排在上面。按这种方式的基数排序称为MSD(Most Significant Dight)排序。第二种方式是从最低有效关键字开始排序,称为LSD(Least Significant Dight)排序。首先对所有的数据按照次要关键字排序,然后对所有的数据按照首要关键字排序。要注意的是,使用的排序算法必须是稳定的,否则就会取消前一次排序的结果。由于不需要分堆对每堆单独排序,LSD方法往往比MSD简单而开销小。下文介绍的方法全部是基于LSD的。
基数排序的简单描述就是将数字拆分为个位十位百位,每个位依次排序。因为这对算法稳定要求高,所以我们对数位排序用到上一个排序方法计数排序。因为基数排序要经过d (数据长度)次排序, 每次使用计数排序, 计数排序的复杂度为 On),d 相当于常量和N无关,所以基数排序也是 O(n)。基数排序虽然是线性复杂度, 即对n个数字处理了n次,但是每一次代价都比较高, 而且使用计数排序的基数排序不能进行原地排序,需要更多的内存, 并且快速排序可能更好地利用硬件的缓存, 所以比较起来,像快速排序这些原地排序算法更可取。对于一个位数有限的十进制数,我们可以把它看作一个多元组,从高位到低位关键字重要程度依次递减。[b]可以使用基数排序对一些位数有限的十进制数排序。[/b]
例如我们将一个三位数分成,个位,十位,百位三部分。我们要对七个三位数来进行排序,依次对其个位,十位,百位进行排序,如下图:
很显然,每一位的数的大小都在[0,9]中,对于每一位的排序用计数排序再适合不过。
算法实现:
// 基数排序:稳定排序
public class RadixSorting {// d为数据长度
private static void radixSorting(int[] arr, int d) {//arr = countingSort(arr, 0);
for (int i = 0; i < d; i++) {arr = countingSort(arr, i); // 依次对各位数字排序(直接用计数排序的变体)
print(arr,i+1,d);
}
}
// 把每次按位排序的结果打印出来
static void print(int[] arr,int k,int d)
{if(k==d)
System.out.println("最终排序结果为:");else
System.out.println("按第"+k+"位排序后,结果为:");for (int t : arr) {System.out.print(t + " ");
}
System.out.println();
}
// 利用计数排序对元素的每一位进行排序
private static int[] countingSort(int[] arr, int index) {int k = 9;
int[] b = new int[arr.length];
int[] c = new int[k + 1]; //这里比较特殊:数的每一位最大数为9
for (int i = 0; i < k; i++) {c[i] = 0;
}
for (int i = 0; i < arr.length; i++) {int d = getBitData(arr[i], index);
c[d]++;
}
for (int i = 1; i <= k; i++) {c[i] += c[i - 1];
}
for (int i = arr.length - 1; i >= 0; i--) {int d = getBitData(arr[i], index);
b[c[d] - 1] = arr[i];//C[d]-1 就代表小于等于元素d的元素个数,就是d在B的位置
c[d]--;
}
return b;
}
// 获取data指定位的数
private static int getBitData(int data, int index) {while (data != 0 && index > 0) {data /= 10;
index--;
}
return data % 10;
}
public static void main(String[] args) {// TODO Auto-generated method stub
int[] arr = new int[] {326,453,608,835,751,435,704,690,88,79,79};//{ 333, 956, 175, 345, 212, 542, 99, 87};System.out.println("基数排序前为:");for (int t : arr) {System.out.print(t + " ");
}
System.out.println();
radixSorting(arr, 4);
}
}
桶排序(Bucket Sort)
首先定义桶,桶为一个数据容器,每个桶存储一个区间内的数。依然有一个待排序的整数序列A,元素的最小值不小于0,最大值不超过K。假设我们有M个桶,第i个桶Bucket[i]存储i*K/M至(i+1)*K/M之间的数。桶排序步骤如下:扫描序列A,根据每个元素的值所属的区间,放入指定的桶中(顺序放置)。
对每个桶中的元素进行排序,什么排序算法都可以,例如插入排序。
依次收集每个桶中的元素,顺序放置到输出序列中。
具体过程可以参考动画演示。
算法伪代码为:

具体代码:
// 桶排序
public class BucketSort {// 插入排序
static void insertSort(int[] a) {int n = a.length;
for (int i = 1; i < n; i++) {int p = a[i];
insert(a, i, p);
}
}
static void insert(int[] a, int index, int x) {// 元素插入数组a[0:index-1]
int i;
for (i = index - 1; i >= 0 && x < a[i]; i--) {a[i + 1] = a[i];
}
a[i + 1] = x;
}
private static void bucketSort(int[] a) {int M = 10; // 11个桶
int n = a.length;
int[] bucketA = new int[M]; // 用于存放每个桶中的元素个数
// 构造一个二维数组b,用来存放A中的数据,这里的B相当于很多桶,B[i][]代表第i个桶
int[][] b = new int[M]
;
int i, j;
for (i = 0; i < M; i++)
for (j = 0; j < n; j++)
b[i][j] = 0;
int data, bucket;
for (i = 0; i < n; i++) {data = a[i];
bucket = data / 10;
b[bucket][bucketA[bucket]] = a[i];// B[0][]中存放A中进行A[i]/10运算后高位为0的数据,同理B[1][]存放高位为1的数据
bucketA[bucket]++;// 用来计数二维数组中列中数据的个数,也就是桶A[i]中存放数据的个数
}
System.out.println("每个桶内元素个数:");for (i = 0; i < M; i++) {System.out.print(bucketA[i] + " ");
}
System.out.println();
System.out.println("数据插入桶后,桶内未进行排序前的结果为:");for (i = 0; i < M; i++) {for (j = 0; j < n; j++)
System.out.print(b[i][j] + " ");
System.out.println();
}
System.out.println("对每个桶进行插入排序,结果为:");// 下面使用直接插入排序对这个二维数组进行排序,也就是对每个桶进行排序
for (i = 0; i < M; i++) {// 下面是对具有数据的一列进行直接插入排序,也就是对B[i][]这个桶中的数据进行排序
if (bucketA[i] != 0) {// 插入排序
for (j = 1; j < bucketA[i]; j++) {int p = b[i][j];
int k;
for (k = j - 1; k >= 0 && p < b[i][k]; k--)
{assert k==-1;
b[i][k + 1] = b[i][k];
}
b[i][k + 1] = p;
}
}
}
// 输出排序过后的顺序
for (i = 0; i < 10; i++) {if (bucketA[i] != 0) {for (j = 0; j < bucketA[i]; j++) {System.out.print(b[i][j] + " ");
}
}
}
}
/**
* @param args
*/
public static void main(String[] args) {// TODO Auto-generated method stub
int[] arr = new int[] {3,5,45,34,2,78,67,34,56,98};bucketSort(arr);
}
}
三种线性排序的比较
| 排序算法 | 时间复杂度 | 空间复杂度 | |
| 计数排序 | O(N+K) | O(N+K) | 稳定排序 |
| 基数排序 | O(N) | O(N) | 稳定排序 |
| 桶排序 | O(N+K) | O(N+K) | 稳定排序 |
相对于快速排序、堆排序等基于比较的排序算法,计数排序、桶排序和基数排序限制较多,不如快速排序、堆排序等算法灵活性好。但反过来讲,这三种线性排序算法之所以能够达到线性时间,是因为充分利用了待排序数据的特性,如果生硬得使用快速排序、堆排序等算法,就相当于浪费了这些特性,因而达不到更高的效率。
参考资料
/article/6348221.html
http://www.byvoid.com/blog/sort-radix/

相关文章推荐
- 三种线性排序算法:计数排序、桶排序与基数排序
- 计数排序,基数排序和桶排序
- 桶排序之计数排序和基数排序
- 排序算法之计数排序、基数排序和桶排序
- 计数排序,基数排序和桶排序
- 小白进阶之线性排序算法之计数排序、基数排序和桶排序
- Python线性时间排序——桶排序、基数排序与计数排序
- 三种基于“分配”“收集”的线性排序算法---计数排序、桶排序与基数排序
- 计数排序、桶排序和基数排序
- 计数排序(Counting Sort)、桶排序(Bucket Sort)和基数排序(Radix Sort)
- 【排序】基数排序(计数排序、桶排序)
- 计数排序、桶排序和基数排序
- 计数排序、桶排序和基数排序
- 排序基础之非比较的计数排序、桶排序、基数排序(Java实现)
- 【排序】基数排序(计数排序、桶排序)
- 第二十篇:内部排序之五:计数排序、基数排序和桶排序(含完整源码)
- MIT:算法导论——5.线性时间排序:计数排序、基数排序以及桶排序
- 计数排序、桶排序和基数排序
- 三种线性排序算法 计数排序、桶排序与基数排序
- 计数排序、桶排序和基数排序