C#网站登录学习笔记(二):访问需登录后才能访问的页面
2012-05-15 18:48
330 查看
本文摘自: http://www.cnblogs.com/jailu/archive/2008/05/10/1191755.html
在上篇笔记中,描述了在C#中如何使用HttpWebRequest、HttpWebResponse登录简单网站,但如果用同样的方法去访问一个需要登录后才能访问的页面,会出现什么结果呢?让我们先来尝试一下!
尝试一:在上篇笔记中,创建了一个用于测试的简单网站,其中LoginSuccess.aspx页面是需要登录后才能访问的(没登录的用户访问该页面,会被重定向到default.aspx页面)。这里我们调用GetHtml("http://localhost/TestLogin/LoginSuccess.aspx")来直接访问LoginSuccess.aspx页面,同时用HTTP Analyzer抓包:

(图一)
从抓包截图(图一)上可以看到,当程序访问LoginSuccess.aspx页面时,被重定向到default.aspx页面去了,证明不能直接访问。
尝试二:那么是不是用程序先在defaul.aspx中登录后在访问LoginSuccess.aspx页面就OK了呢?我们再来尝试一下:1. 调用GetHtml("http://localhost/TestLogin/Default.aspx", postData, Method.POST)登录;2.调用GetHtml("http://localhost/TestLogin/LoginSuccess.aspx")访问LoginSuccess.aspx页面。
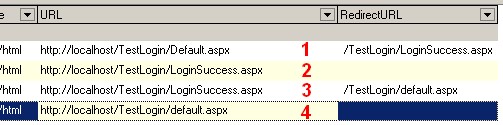
(图二)
图二是第二次尝试中庸HTTP Analyzer抓包的截图。1、2:程序在Default.aspx中登录成功后,自动跳转至LoginSuccess.aspx;3、4:程序在登录成功后,访问LoginSuccess.aspx页面,被重定向到Default.aspx。看来这次的尝试又失败了。
然道没办法在程序中访问需登录后才能访问的页面了吗?答案是否定的!那么该如何实现呢?在实现前,有一些基础知识是要先了解的:
以下文字转自深蓝的博客文章《使用C#实现网站用户登录》
HTTP协议是一个无连接的协议,也就是说这次对话的内容和状态与上次的无关,为了实现和用户的持久交互,网站与浏览器之前在刚建立会话时将在服务器内存中建立一个Session,该Session标识了该用户(浏览器),每一个Session都有一个唯一的ID,第一次建立会话时服务器将生成的这个ID传给浏览器,浏览器在接下来的浏览中每一个发向服务器的请求中都将包含该SessionID,从而标识了自己的身份。
服务器上是使用内存来保存Session中的信息,那么浏览器又使用什么来保存服务器分配的这个SessionID了?对,是Cookie。在刚建立会话时浏览器向服务器的请求中将不包含SessionID在Cookie中,服务器就认为是一个全新的会话,从而在服务器上分配一段内存给该 Session用,同时将该Session的ID在Http Header中使用Set-Cookie发送给浏览器。
哈哈,原来是Cookie的原因啊!看来我们只需在访问需登录的页面时把该网站对应的Cookie带上就OK了。这里使用CookieContainer来保存Cookie。
尝试三:给HttpWebRequest指定CookieContainer,登录并访问LoginSuccess.aspx页面。
以下是修改后的代码:
在上篇笔记中,描述了在C#中如何使用HttpWebRequest、HttpWebResponse登录简单网站,但如果用同样的方法去访问一个需要登录后才能访问的页面,会出现什么结果呢?让我们先来尝试一下!
尝试一:在上篇笔记中,创建了一个用于测试的简单网站,其中LoginSuccess.aspx页面是需要登录后才能访问的(没登录的用户访问该页面,会被重定向到default.aspx页面)。这里我们调用GetHtml("http://localhost/TestLogin/LoginSuccess.aspx")来直接访问LoginSuccess.aspx页面,同时用HTTP Analyzer抓包:
(图一)
从抓包截图(图一)上可以看到,当程序访问LoginSuccess.aspx页面时,被重定向到default.aspx页面去了,证明不能直接访问。
尝试二:那么是不是用程序先在defaul.aspx中登录后在访问LoginSuccess.aspx页面就OK了呢?我们再来尝试一下:1. 调用GetHtml("http://localhost/TestLogin/Default.aspx", postData, Method.POST)登录;2.调用GetHtml("http://localhost/TestLogin/LoginSuccess.aspx")访问LoginSuccess.aspx页面。
(图二)
图二是第二次尝试中庸HTTP Analyzer抓包的截图。1、2:程序在Default.aspx中登录成功后,自动跳转至LoginSuccess.aspx;3、4:程序在登录成功后,访问LoginSuccess.aspx页面,被重定向到Default.aspx。看来这次的尝试又失败了。
然道没办法在程序中访问需登录后才能访问的页面了吗?答案是否定的!那么该如何实现呢?在实现前,有一些基础知识是要先了解的:
以下文字转自深蓝的博客文章《使用C#实现网站用户登录》
HTTP协议是一个无连接的协议,也就是说这次对话的内容和状态与上次的无关,为了实现和用户的持久交互,网站与浏览器之前在刚建立会话时将在服务器内存中建立一个Session,该Session标识了该用户(浏览器),每一个Session都有一个唯一的ID,第一次建立会话时服务器将生成的这个ID传给浏览器,浏览器在接下来的浏览中每一个发向服务器的请求中都将包含该SessionID,从而标识了自己的身份。
服务器上是使用内存来保存Session中的信息,那么浏览器又使用什么来保存服务器分配的这个SessionID了?对,是Cookie。在刚建立会话时浏览器向服务器的请求中将不包含SessionID在Cookie中,服务器就认为是一个全新的会话,从而在服务器上分配一段内存给该 Session用,同时将该Session的ID在Http Header中使用Set-Cookie发送给浏览器。
哈哈,原来是Cookie的原因啊!看来我们只需在访问需登录的页面时把该网站对应的Cookie带上就OK了。这里使用CookieContainer来保存Cookie。
尝试三:给HttpWebRequest指定CookieContainer,登录并访问LoginSuccess.aspx页面。
以下是修改后的代码:

相关文章推荐
- C#网站登录学习笔记(二):访问需登录后才能访问的页面
- C#网站登录学习笔记(一):登录简单网站
- c#学习笔记三 如何访问另一个页面的控件数据
- C#网站登录学习笔记(一):登录简单网站
- C#网站登录学习笔记(一):登录简单网站
- C#学习笔记(六)抽象类 访问限制关键字 委托 事件
- 学习博客园开源代码笔记(登录页面)
- laravel学习笔记------laravel在nginx环境访问页面404
- magento-只有登录的用户才能看到网站的页面,未登录的页面都跳转到登录页面!
- [C#学习笔记之多线程2]多线程同步与并发访问共享资源工具—Lock、Monitor、Mutex、Semaphore .
- servlet学习笔记3——用户登录网站(通过session验证登陆用户)
- 黑马程序员之c#学习笔记:用户登录验证码的设计
- PHP学习笔记 登录页面
- servlet学习笔记5——分页实现(登录网站的完善)
- JSP基础实例_登录页面的制作_学习笔记
- servlet学习笔记4——用户登录网站(数据库验证)
- 20160410servlet学习笔记网站访问次数计数器
- php学习笔记-1.登录页面的学习
- 【swift学习笔记】六.访facebook登录页面
- React-Native学习笔记之:实现简单地登录页面