Hadoop分布式搭建配置(详细)
2012-01-05 20:24
357 查看
【http://youzitool.com 新博客,欢迎访问】
Hadoop分布式搭建配置(详细)
一、前期准备
1、hadoop-0.20.203.0rc1.tar.gz(官网下载)
2、VMware7 (官网下载)
3、jdk-6u25-linux-i586.bin (官网下载)
4、 Ubuntu 10.04 (ISO)
用户:matraxa(192.168.110.100) 对应 namenode、secondnamenode、JobTracker
wfl(192.168.110.101) 对应 datanode、TaskTrack
二、安装Ubuntu
磁盘分区方案见:/article/8295433.html
三、安装jdk
1、在usr下面新建一个文件夹java,然后将jdk移过去
sudo mkdir /usr/java
sudo mv /home/jdk-6u25-linux-i586.bin /usr/java //将jdk移动到/usr/java
2、进入到java目录下,改变文件权限为可执行
cd /usr/java
sudo chmod 777 jdk-6u25-linux-i586.bin //添加权限
3、执行安装
sudo ./jdk-6u25-linux-i586.bin //安装JDK
4、设置环境变量
sudo gedit /etc/profile 在“umask 022”前添加如下代码:
export JAVA_HOME="/usr/java/jdk1.6.0_25"
export PATH="$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin"
export CLASSPATH="$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib"
5、souce /etc/profile //使环境变量生效
6、which java //测试JDK安装是否成功 成功则显示: /usr/java/jdk1.6.0_25/jre/bin/java
说明:另一种安装jdk的方法见:/article/8295436.html
四、安装SSH ,实现SSH的无密码连接
说明:每台电脑上都要安装ssh
在namenode(这里为matraxa)上:
1、$ sudo apt-get install ssh //安装ssh (这步在每台电脑上都要执行!)
2、ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa //生成密钥(这里密码为空) 文件如:id_dsa id_dsa.pub
3、 cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys //加入受信列表
4、 ssh localhost 或者 ssh matraxa //第一次需输入"yes",成功就能无密码访问 这个是进行的本地测试
说明:1、若要实现datanode无密码访问namenode,只需按照上面的步骤将datanode的*.pub文件复制到namenode上,并追加到authorized_keys中
2、其它文件都不用修改,网上有文章说要修改/etc/ssh/sshd_config,我配置的时候也是没有修改的
五、安装hadoop
注意:由于Hadoop要求所有机器上hadoop的部署目录结构要相同,并且都有一个相同的用户名的帐户。
我的为:/home/matraxa/hadoop-0.20.203
在namenode(这里为matraxa)上:
1、sudo gedit /etc/hosts
127.0.0.1 localhost
192.168.110.100 matraxa-desktop
192.168.110.100 matraxa
192.168.110.101 wfl-desktop
192.168.110.101 wfl
2、cd /home/matraxa
3、tar -xzvf hadoop-0.20.203.0rc1.tar.gz //将压缩包解压到/home/matraxa
4、配置hadoop-0.20.203/conf 下的 hadoop-env.sh文件
将# export JAVA_HOME=/usr/lib/j2sdk1.5-sun 改为:
export JAVA_HOME=/usr/java/jdk1.6.0_25
5、配置hadoop-0.20.203/conf下的slaves文件,一行一个DataNode,格式为:用户名@hostip
wfl@wfl //必须这样写,我开始只写的wfl(或192.168.110.101),花了很长时间都没配置正确,奔泪啊~
//修改masters文件内容为:
matraxa //也可以是namenode的ip,由于在/etc/hosts中设置了matraxa与ip的对应,可以写为matraxa
6、配置hadoop-0.20.203/conf下的三个xml文件
修 改 core-site.xml
<property>
<name>fs.default.name</name>
<value>hdfs://matraxa:9000</value>
</property>
修改 mapred-site.xml
<property>
<name>mapred.job.tracker</name>
<value>matraxa:9001</value>
</property>
修改 hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/matraxa/hadoop_tmp_dir/</value>
</property>
7、进入hadoop-0.20.203/
bin/hadoop namenode -format //必需初始化 只需要初始化namenode
8、bin/start-all.sh //启动namdnode
六、在datanode(这里为wfl)上:
注意:由于Hadoop要求所有机器上hadoop的部署目录结构要相同,并且都有一个相同的用户名的帐户。
我的为:/home/matraxa/hadoop-0.20.203
1、在wfl机器上建立了一个录:/home/matraxa。注意:将matraxa的宿主和属主都改为wfl
命令如下:sudo mkdir /home/matraxa //建立matraxa目录
sudo chown -R wfl:wfl /home/matraxa //更改宿主(-R表示递归)
2、将matraxa机器上/home/matraxa/hadoop-0.20.203文件夹拷贝到wfl机器上的/home/matraxa/
命令为:scp -r /home/matraxa/hadoop-0.20.203 wfl@192.168.110.101:/home/matraxa/
3、/etc/hosts和namenode的一样 //参照namenode的1
七、启动Hadoop
1、格式化namenode:启动之前要先格式化namenode,进入/home/matraxa/hadoop-0.20.203目录,执行下面的命令:
bin/hadoop namenode -format
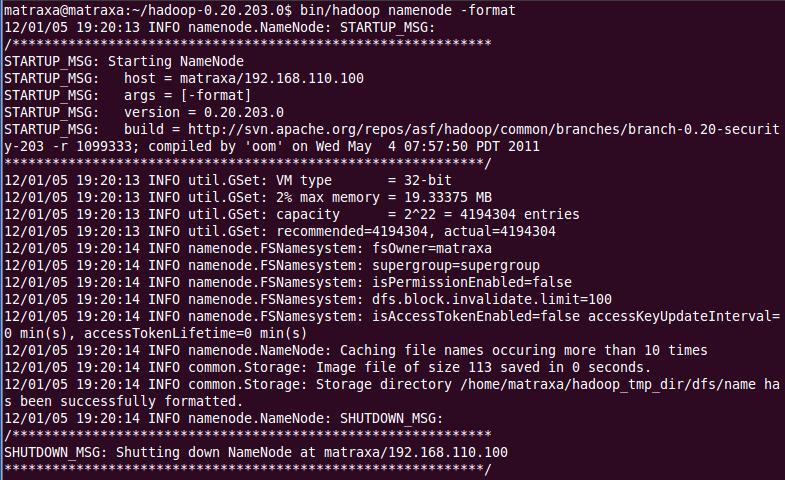
2、启动namenode:执行命令
bin/start-all.sh
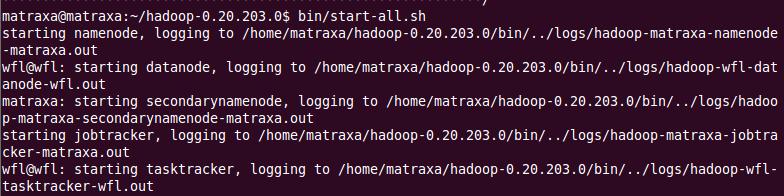
要停止Hadoop则执行如下命令:bin/stop-all.sh
完美搭建完成!~
可以通过 http://matraxa:50070 查看namenode 状态
http://matraxa:50030 查看 JobTracke状态
说明:我Hadoop运行遇到了以下的错误:
org.apache.hadoop.security.AccessControlException: Permission denied: user=wfl, access=EXECUTE, inode="job_201010161322_0003":heipark:supergroup:rwx------
解决方法:在hdfs-site.xml中添加如下:
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
其它错误请见:/article/8295444.html
配置Hadoop虽然简单,但由于粗心花了我很久时间,还多亏了好友的帮忙,在此表示感谢。将此配置步骤记下以备今后忘记后查看,也希望能给正在配置Hadoop的朋友一点帮助。
若您有意见或建议,欢迎留言互相讨论~
Hadoop分布式搭建配置(详细)
一、前期准备
1、hadoop-0.20.203.0rc1.tar.gz(官网下载)
2、VMware7 (官网下载)
3、jdk-6u25-linux-i586.bin (官网下载)
4、 Ubuntu 10.04 (ISO)
用户:matraxa(192.168.110.100) 对应 namenode、secondnamenode、JobTracker
wfl(192.168.110.101) 对应 datanode、TaskTrack
二、安装Ubuntu
磁盘分区方案见:/article/8295433.html
三、安装jdk
1、在usr下面新建一个文件夹java,然后将jdk移过去
sudo mkdir /usr/java
sudo mv /home/jdk-6u25-linux-i586.bin /usr/java //将jdk移动到/usr/java
2、进入到java目录下,改变文件权限为可执行
cd /usr/java
sudo chmod 777 jdk-6u25-linux-i586.bin //添加权限
3、执行安装
sudo ./jdk-6u25-linux-i586.bin //安装JDK
4、设置环境变量
sudo gedit /etc/profile 在“umask 022”前添加如下代码:
export JAVA_HOME="/usr/java/jdk1.6.0_25"
export PATH="$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin"
export CLASSPATH="$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib"
5、souce /etc/profile //使环境变量生效
6、which java //测试JDK安装是否成功 成功则显示: /usr/java/jdk1.6.0_25/jre/bin/java
说明:另一种安装jdk的方法见:/article/8295436.html
四、安装SSH ,实现SSH的无密码连接
说明:每台电脑上都要安装ssh
在namenode(这里为matraxa)上:
1、$ sudo apt-get install ssh //安装ssh (这步在每台电脑上都要执行!)
2、ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa //生成密钥(这里密码为空) 文件如:id_dsa id_dsa.pub
3、 cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys //加入受信列表
4、 ssh localhost 或者 ssh matraxa //第一次需输入"yes",成功就能无密码访问 这个是进行的本地测试
5、把matraxa上的id_dsa.pub 文件追加到wfl的authorized_keys 内:a. 拷贝matraxa的id_dsa.pub文件:$ scp id_dsa.pub wfl@192.168.110.101:/home/wfl //如果拷贝到其它目录下,可能会出现permission denied错误,如拷贝到home下,这是因为其它用户没有写权限,我就因此悲剧了半天~
在datanode(这里为wfl)上:
登录wfl(192.168.110.101),进入/home/wfl目录执行:$ cat id_dsa.pub >> .ssh/authorized_keys //可以在matraxa上不输入密码直接访问wfl
说明:1、若要实现datanode无密码访问namenode,只需按照上面的步骤将datanode的*.pub文件复制到namenode上,并追加到authorized_keys中
2、其它文件都不用修改,网上有文章说要修改/etc/ssh/sshd_config,我配置的时候也是没有修改的
五、安装hadoop
注意:由于Hadoop要求所有机器上hadoop的部署目录结构要相同,并且都有一个相同的用户名的帐户。
我的为:/home/matraxa/hadoop-0.20.203
在namenode(这里为matraxa)上:
1、sudo gedit /etc/hosts
127.0.0.1 localhost
192.168.110.100 matraxa-desktop
192.168.110.100 matraxa
192.168.110.101 wfl-desktop
192.168.110.101 wfl
2、cd /home/matraxa
3、tar -xzvf hadoop-0.20.203.0rc1.tar.gz //将压缩包解压到/home/matraxa
4、配置hadoop-0.20.203/conf 下的 hadoop-env.sh文件
将# export JAVA_HOME=/usr/lib/j2sdk1.5-sun 改为:
export JAVA_HOME=/usr/java/jdk1.6.0_25
5、配置hadoop-0.20.203/conf下的slaves文件,一行一个DataNode,格式为:用户名@hostip
wfl@wfl //必须这样写,我开始只写的wfl(或192.168.110.101),花了很长时间都没配置正确,奔泪啊~
//修改masters文件内容为:
matraxa //也可以是namenode的ip,由于在/etc/hosts中设置了matraxa与ip的对应,可以写为matraxa
6、配置hadoop-0.20.203/conf下的三个xml文件
修 改 core-site.xml
<property>
<name>fs.default.name</name>
<value>hdfs://matraxa:9000</value>
</property>
修改 mapred-site.xml
<property>
<name>mapred.job.tracker</name>
<value>matraxa:9001</value>
</property>
修改 hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/matraxa/hadoop_tmp_dir/</value>
</property>
7、进入hadoop-0.20.203/
bin/hadoop namenode -format //必需初始化 只需要初始化namenode
8、bin/start-all.sh //启动namdnode
六、在datanode(这里为wfl)上:
注意:由于Hadoop要求所有机器上hadoop的部署目录结构要相同,并且都有一个相同的用户名的帐户。
我的为:/home/matraxa/hadoop-0.20.203
1、在wfl机器上建立了一个录:/home/matraxa。注意:将matraxa的宿主和属主都改为wfl
命令如下:sudo mkdir /home/matraxa //建立matraxa目录
sudo chown -R wfl:wfl /home/matraxa //更改宿主(-R表示递归)
2、将matraxa机器上/home/matraxa/hadoop-0.20.203文件夹拷贝到wfl机器上的/home/matraxa/
命令为:scp -r /home/matraxa/hadoop-0.20.203 wfl@192.168.110.101:/home/matraxa/
3、/etc/hosts和namenode的一样 //参照namenode的1
七、启动Hadoop
1、格式化namenode:启动之前要先格式化namenode,进入/home/matraxa/hadoop-0.20.203目录,执行下面的命令:
bin/hadoop namenode -format
2、启动namenode:执行命令
bin/start-all.sh
要停止Hadoop则执行如下命令:bin/stop-all.sh
完美搭建完成!~
可以通过 http://matraxa:50070 查看namenode 状态
http://matraxa:50030 查看 JobTracke状态
说明:我Hadoop运行遇到了以下的错误:
org.apache.hadoop.security.AccessControlException: Permission denied: user=wfl, access=EXECUTE, inode="job_201010161322_0003":heipark:supergroup:rwx------
解决方法:在hdfs-site.xml中添加如下:
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
其它错误请见:/article/8295444.html
配置Hadoop虽然简单,但由于粗心花了我很久时间,还多亏了好友的帮忙,在此表示感谢。将此配置步骤记下以备今后忘记后查看,也希望能给正在配置Hadoop的朋友一点帮助。
若您有意见或建议,欢迎留言互相讨论~

相关文章推荐
- hadoop学习第一天-hadoop初步环境搭建&伪分布式计算配置(详细)
- Hadoop分布式搭建配置(详细)
- Hadoop 2.4.0完全分布式平台搭建、配置、安装
- Hadoop环境搭建-入门伪分布式配置(Mac OS,0.21.0,Eclipse 3.6)
- 5节点Hadoop分布式集群搭建-超详细文档
- 入门级Hadoop集群搭建详细教程(六):yum本地仓库与远程仓库配置
- 使用docker搭建hadoop环境,并配置伪分布式模式
- hadoop - hadoop2.6 分布式 - 集群环境搭建 - JDK安装配置和SSH安装配置与免密码登陆(集群中)
- 王家林 云计算分布式大数据Hadoop实战高手之路---从零开始 第二讲:全球最详细的从零起步搭建Hadoop单机和伪分布式开发环境图文教程
- 搭建Hadoop分布式集群------修改三台机器的配置文件
- Hadoop伪分布式环境搭建详细步骤
- Hadoop2.6.4 HA 高可用分布式集群安装配置详细步骤
- 5节点Hadoop分布式集群搭建-超详细文档
- Apache Hadoop 2.8 完全分布式集群搭建超详细过程,实现NameNode HA、ResourceManager HA高可靠性
- 超详细解说Hadoop伪分布式搭建
- Hadoop2.2.0安装配置手册!完全分布式Hadoop集群搭建过程
- Hadoop伪分布式、完全分布式搭建和测试(详细版)
- hadoop2.x 完全分布式详细集群搭建
- hadoop2.x单机搭建分布式集群超详细教程
- 5节点Hadoop分布式集群搭建-超详细文档