【原】程序员必须知道的字符集编码概念
2011-09-28 16:31
351 查看
2010年07月01日 星期四 18:44
由于某度众所周知的铜臭举动,让我搬离写了5年的渣度空间,准备把技术性的文章定在CSDN了。这些都是文章备份。勿怪。。
鉴于最近有些抓取机器和抄袭者,把标题的【原】字都复制,我不得不声明:本文为 yukon12345原创,转载请注明出处http://blog.csdn.net/yukon12345
ASCII 应该是最熟悉和最古老的编码标准了。标准C就是使用ASCII。特点是使用7比特表示128个字符。很多人都会背了。这个不用说太多。
GB2312,GBK 通常称为国标码。这是中国等汉字地区使用的国家标准编码。是中国为了在计算机上实现汉字的显示,统一制定的汉字字符集编码映射库。GB2312是1980制定的编码,GBK是1995年制定的国标扩展,支持了更多冷僻汉字和一些符号。国标码使用2字节表示字符,英文同样使用2字节。不过是全角的英文。而为了和ascii兼容,半角的英文仍然是占用1字节大小。
ANSI 为了适应各国的编码标准而指定的一种措施标准。比如中国的国标是GB2312,台湾香港地区BIG5。日本的JIS,韩国的KSC。这是各国针对本国语言制定的国家标准编码。在本国使用比较多。多国为自己国家指定的编码标准,编码库可能会互相冲突。而为了兼容这些现有的编码互相冲突的编码,ANSI使用一种码页(code pages)的方式来实现。
比如中国大陆的windows xp操作系统中,码页默认为gb2312。而日文操作系统使用JIS。打个比方 ,假如编码8EEE显示“汉”,但如果在控制面板的语言设定语言为日文,改变了码页,那么这个8EEE就会可能显示为"日"。记事本默认是用的就是ANSI编码。所以你用记事本保存汉语文件发给日本朋友,他打开就是乱码。
iso8859系列 相对来说比较常见的一种编码,可能很多人为java和javascript编程中的莫名中文奇妙乱码而头痛。因为很多IDE(比如eclipse,英文版的其他一些IDE)默认页面编码是ISO8859,这是ISO组织开发的一个支持西欧各国文字的字符编码集。但不支持中文等亚洲文字,当你稀里糊涂的敲了一段中文进IDE准备保存时,当你打开别人的源码,修改输入中文后保存时,都可能会造成中文的乱码。另外当你把一个unicode编码,gbk编码的文件保存成iso8859时也可能会弹出警告说有些字符找不到映射。好的解决方法就是编程时大家统一使用unicode编码。并且在IDE里设置页面编码为utf-8
UNICODE字符集 unicode使用四个字节32比特一一对应世界上所有的语言文字符号。为了对全世界的文字进行编码,出现了2个组织分别从事这样的编码工作。即国际标准化组织(ISO)和一个软件制造商的协会。竞争了相当长一段时间。最后握手言和,统一思想,共同开发。ISO 10646标准实际上等同于unicode。unicode字符集简写为ucs (unicode character set)。前期曾经有试图使用2字节来编码,但由于2字节只能编码2^16 =65535个字符,远不够全世界的语言字符量。因此现在Unicode用数字0-0x10FFFF来映射这些字符,最多可以容纳1114112个字符。
utf系列 分为utf-8,utf-16,utf-32。很多人以为utf系列是字符集编码,准确的说,utf是一种存储转换方式。utf全称ucs transformation format 是用来转换unicode编码的表达格式。目前的主流是utf-8。它的特点是兼容ascii码的unicode编码的可变长度转换。即:使用可变长度来表示unicode字符编码。见下图(来源于:http://www.joelonsoftware.com/articles/Unicode.html)
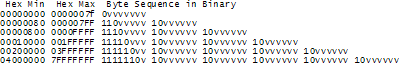
可以看出,如果使用的字符集编码在0到0x7f之间只要使用一个字节。而在0x7f到0x80,0x7fff之间使用2个字节。而且第一个字节用高位设1来表示这个字符是用几个字节表示,2个字节的为110,3个字节的为1110。。一直到六个字节。不过目前只使用到了前4种。1字节的utf8为ascii码,2字节的为西欧文字,3字节的为亚洲文字4字节多为一些平面码
这种方式最大的好处就是,它的前128个编码和Ascii一模一样了。大多数编程根本不必担心字符转换问题。同时只使用1个字节就可以表示世界上占很大比例的英文。 节省了存储空间。你用utf8格式存一100字的英语文章只需要100字节,而不是unicode编码所需的400字节。但使用utf-8有时有可能照成需要使用6字节来表示一个字符。对于utf-16和utf-32,跟utf-8原理类似,顾名思义,最小的比特数为16和32。具体解释查看百度百科http://baike.baidu.com/view/40801.htm?fr=ala0_1#2
web应用。有些人访问日韩等特殊字符网站经常会碰到乱码的问题。而有时候又不会。在ie6,ie7等老版本中出现概率比较大。这是因为,有些网站设置本站编码为自己国家的国标码,比如gb2312,JIS等等,浏览器首先会根据服务器返回的http头里的content-type charset:xxxx来确定这个网站的字符集编码。比如php中有header("Content-type:text/html; charset=utf-8")如果服务器没有设定,那么会在网页中的<meta>标签里查找content-type
charset:xxxx。如果还是没有发现,就会再查找http头中的地区语言。比如:Accept-Language: zh-cn。这是就会根据语言地区来自动选择到可能的编码集,之后浏览器就会根据编码出现的概率来自动判断这个网页是什么格式的编码。比如中文中"的","了",等字符编码出现的概率最高,根据出现概率最高的编码格式来判断这是gb2312的,还是big5的,日文中は、の等字符编码出现的概率高,就判断这是日文的JIS,但浏览器有时候会判断错误,就导致了乱码的出现。这时候就需要在浏览器的编码选项里手选择你确定的编码格式。不过目前国际网站的开发者一般都是使用UTF-8,除非是老站,已经很少有人使用各国标准编码了。
php的字符编码转换。通常存到mysql中的字符,一般是gb2312或者utf8,只要一旦存入mysql等数据库,再改变mysql的字符编码格式并不会影响库里信息的编码。因此当你utf8写入,取出来后仍只可能是utf8编码,想要转成gbk等就用iconv()转换。而对于mysql还有个mysql_query("set names 'utf8'")来正确取出编码
字符长度
strlen基本都知道,不过你有没有注意,它并不是按字符数来显示长度的,而是按所占字节数来计算
在utf-8页面编码的文件中 由于是可变字符,会造成一个字符strlen后会出现1-6的值。
echo strlen("我");//显示为3
echo strlen("υ");//显示为2.希腊字母,中学物理里的小写v。
echo strlen("a");//显示为1.英文字母。
而在这时,用
$str="中中中是";
echo strlen($str).'<br>';//12
echo mb_strlen($str,'utf8').'<br>';//4
//对于下面2个,我表示不理解。应该是php的bug
echo mb_strlen($str,'gbk').'<br>';//6
echo mb_strlen($str,'gb2312').'<br>';//7
最后,链个织梦的官方贴,对于utf-8和gbk的比较写得挺详细,不过里面有一句话好像错了。
http://bbs.dedecms.com/199818.html
“GBK包含全部中文字符,是国家编码,通用性比UTF8差,不过UTF8占用的数据库比GBK大。 ”
实际上gbk对是兼容ascii码的,半角的英文是占位1字节,如果是全英文站用什么码都是一样的。占用数据库也是一样。
由于某度众所周知的铜臭举动,让我搬离写了5年的渣度空间,准备把技术性的文章定在CSDN了。这些都是文章备份。勿怪。。
鉴于最近有些抓取机器和抄袭者,把标题的【原】字都复制,我不得不声明:本文为 yukon12345原创,转载请注明出处http://blog.csdn.net/yukon12345
ASCII 应该是最熟悉和最古老的编码标准了。标准C就是使用ASCII。特点是使用7比特表示128个字符。很多人都会背了。这个不用说太多。
GB2312,GBK 通常称为国标码。这是中国等汉字地区使用的国家标准编码。是中国为了在计算机上实现汉字的显示,统一制定的汉字字符集编码映射库。GB2312是1980制定的编码,GBK是1995年制定的国标扩展,支持了更多冷僻汉字和一些符号。国标码使用2字节表示字符,英文同样使用2字节。不过是全角的英文。而为了和ascii兼容,半角的英文仍然是占用1字节大小。
ANSI 为了适应各国的编码标准而指定的一种措施标准。比如中国的国标是GB2312,台湾香港地区BIG5。日本的JIS,韩国的KSC。这是各国针对本国语言制定的国家标准编码。在本国使用比较多。多国为自己国家指定的编码标准,编码库可能会互相冲突。而为了兼容这些现有的编码互相冲突的编码,ANSI使用一种码页(code pages)的方式来实现。
比如中国大陆的windows xp操作系统中,码页默认为gb2312。而日文操作系统使用JIS。打个比方 ,假如编码8EEE显示“汉”,但如果在控制面板的语言设定语言为日文,改变了码页,那么这个8EEE就会可能显示为"日"。记事本默认是用的就是ANSI编码。所以你用记事本保存汉语文件发给日本朋友,他打开就是乱码。
iso8859系列 相对来说比较常见的一种编码,可能很多人为java和javascript编程中的莫名中文奇妙乱码而头痛。因为很多IDE(比如eclipse,英文版的其他一些IDE)默认页面编码是ISO8859,这是ISO组织开发的一个支持西欧各国文字的字符编码集。但不支持中文等亚洲文字,当你稀里糊涂的敲了一段中文进IDE准备保存时,当你打开别人的源码,修改输入中文后保存时,都可能会造成中文的乱码。另外当你把一个unicode编码,gbk编码的文件保存成iso8859时也可能会弹出警告说有些字符找不到映射。好的解决方法就是编程时大家统一使用unicode编码。并且在IDE里设置页面编码为utf-8
UNICODE字符集 unicode使用四个字节32比特一一对应世界上所有的语言文字符号。为了对全世界的文字进行编码,出现了2个组织分别从事这样的编码工作。即国际标准化组织(ISO)和一个软件制造商的协会。竞争了相当长一段时间。最后握手言和,统一思想,共同开发。ISO 10646标准实际上等同于unicode。unicode字符集简写为ucs (unicode character set)。前期曾经有试图使用2字节来编码,但由于2字节只能编码2^16 =65535个字符,远不够全世界的语言字符量。因此现在Unicode用数字0-0x10FFFF来映射这些字符,最多可以容纳1114112个字符。
utf系列 分为utf-8,utf-16,utf-32。很多人以为utf系列是字符集编码,准确的说,utf是一种存储转换方式。utf全称ucs transformation format 是用来转换unicode编码的表达格式。目前的主流是utf-8。它的特点是兼容ascii码的unicode编码的可变长度转换。即:使用可变长度来表示unicode字符编码。见下图(来源于:http://www.joelonsoftware.com/articles/Unicode.html)
可以看出,如果使用的字符集编码在0到0x7f之间只要使用一个字节。而在0x7f到0x80,0x7fff之间使用2个字节。而且第一个字节用高位设1来表示这个字符是用几个字节表示,2个字节的为110,3个字节的为1110。。一直到六个字节。不过目前只使用到了前4种。1字节的utf8为ascii码,2字节的为西欧文字,3字节的为亚洲文字4字节多为一些平面码
这种方式最大的好处就是,它的前128个编码和Ascii一模一样了。大多数编程根本不必担心字符转换问题。同时只使用1个字节就可以表示世界上占很大比例的英文。 节省了存储空间。你用utf8格式存一100字的英语文章只需要100字节,而不是unicode编码所需的400字节。但使用utf-8有时有可能照成需要使用6字节来表示一个字符。对于utf-16和utf-32,跟utf-8原理类似,顾名思义,最小的比特数为16和32。具体解释查看百度百科http://baike.baidu.com/view/40801.htm?fr=ala0_1#2
web应用。有些人访问日韩等特殊字符网站经常会碰到乱码的问题。而有时候又不会。在ie6,ie7等老版本中出现概率比较大。这是因为,有些网站设置本站编码为自己国家的国标码,比如gb2312,JIS等等,浏览器首先会根据服务器返回的http头里的content-type charset:xxxx来确定这个网站的字符集编码。比如php中有header("Content-type:text/html; charset=utf-8")如果服务器没有设定,那么会在网页中的<meta>标签里查找content-type
charset:xxxx。如果还是没有发现,就会再查找http头中的地区语言。比如:Accept-Language: zh-cn。这是就会根据语言地区来自动选择到可能的编码集,之后浏览器就会根据编码出现的概率来自动判断这个网页是什么格式的编码。比如中文中"的","了",等字符编码出现的概率最高,根据出现概率最高的编码格式来判断这是gb2312的,还是big5的,日文中は、の等字符编码出现的概率高,就判断这是日文的JIS,但浏览器有时候会判断错误,就导致了乱码的出现。这时候就需要在浏览器的编码选项里手选择你确定的编码格式。不过目前国际网站的开发者一般都是使用UTF-8,除非是老站,已经很少有人使用各国标准编码了。
php的字符编码转换。通常存到mysql中的字符,一般是gb2312或者utf8,只要一旦存入mysql等数据库,再改变mysql的字符编码格式并不会影响库里信息的编码。因此当你utf8写入,取出来后仍只可能是utf8编码,想要转成gbk等就用iconv()转换。而对于mysql还有个mysql_query("set names 'utf8'")来正确取出编码
字符长度
strlen基本都知道,不过你有没有注意,它并不是按字符数来显示长度的,而是按所占字节数来计算
在utf-8页面编码的文件中 由于是可变字符,会造成一个字符strlen后会出现1-6的值。
echo strlen("我");//显示为3
echo strlen("υ");//显示为2.希腊字母,中学物理里的小写v。
echo strlen("a");//显示为1.英文字母。
而在这时,用
$str="中中中是";
echo strlen($str).'<br>';//12
echo mb_strlen($str,'utf8').'<br>';//4
//对于下面2个,我表示不理解。应该是php的bug
echo mb_strlen($str,'gbk').'<br>';//6
echo mb_strlen($str,'gb2312').'<br>';//7
最后,链个织梦的官方贴,对于utf-8和gbk的比较写得挺详细,不过里面有一句话好像错了。
http://bbs.dedecms.com/199818.html
“GBK包含全部中文字符,是国家编码,通用性比UTF8差,不过UTF8占用的数据库比GBK大。 ”
实际上gbk对是兼容ascii码的,半角的英文是占位1字节,如果是全英文站用什么码都是一样的。占用数据库也是一样。

相关文章推荐
- 每个程序员都绝对必须知道的关于字符集和Unicode的那点儿事(别找借口!)
- 每个程序员都绝对必须知道的关于字符集和Unicode的那点儿事
- 每一个程序员必须掌握的知识,字符集与字符编码.
- 每个程序员都绝对必须知道的关于字符集和Unicode的那点儿事(别找借口!)【ZT】
- Windows程序员必须知道的字符编码和字符集
- 每个程序员都绝对必须知道的关于字符集和Unicode的那点儿事(别找借口!)
- 程序员必须知道的10大基础实用算法及其讲解
- 分布式编程必须知道的几个基本概念
- 20个你必须知道的SEO概念
- 转:有关PowerShell脚本你必须知道的十个基本概念
- 你必须知道的C#的25个基础概念
- 程序员必须知道的Oracle索引知识
- 程序员必须知道的10大基础实用算法及其讲解
- 你必须知道的C#的25个基础概念
- 你必须知道的25个C#基础概念
- 程序员必须知道的十大基础实用算法及其讲解
- 程序员必须知道的10大基础实用算法及其讲解
- 程序员必须知道的10大基础实用算法及其讲解
- C语言测试:嵌入式程序员必须知道的16个问题(转)
- 程序员必须知道的八大排序