HubbleDotNet 开源全文搜索数据库项目--为数据库现有表或视图建立全文索引(一) Append Only 模式
2010-05-13 10:48
495 查看
HubbleDotNet 可以非常方便的对数据库现有表或视图创建全文索引,整个过程人工干预的时间不超过5分钟。我将用几个篇幅来阐述如何对现有数据表创建全文索引。本篇将重点介绍如何创建 Append Only 模式的全文索引。
在对现有表或视图创建全文索引前,我们还是需要先在 HubbleDotNet 中创建一个数据库,如何创建数据库见:HubbleDotNet 开源全文搜索数据库项目--创建、删除数据库
创建好HubbleDotNet的数据库后就可以开始对关系数据库中现有表或视图建全文索引了。
下面我以News 库为例,创建全文索引
打开查询分析器,在News 库这个节点点右键选 Create Table,如下图所示


如上图所示我先演示一下如果创建一个中文新闻的全文索引。按照界面提示,输入HubbleDotNet 的表名,这里输入 CNews, 再输入全文索引所在目录,选择数据库适配器,这里由于我对应的关系数据库是SQLSERVER 2005,索引选SQLSERVER 2005, 这个适配器适用于SQL SERVER 2005 及以后的所有版本。
然后再配置一下关系数据库的连接字符串,点下面的按钮测试连接字符串没有问题,点Next 进入下一步。

如上图所示,这一步我们需要选择索引模式
由于是从现有数据表中创建全文索引,这里选择
Build Index from exist table
在下面那个文本框中,我们要输入关系数据库中实际的数据表或视图的名称。这里输入 News。
在 Incremental Mode 这里有两个选项
Append Only 模式适用于数据只增长,不修改的模式,实际上在这种模式下只要全文索引字段不被修改就可以适用。这种模式的优点是相对 Append, Delete,Update 模式消耗的内存要少,速度稍快一些。如果要用这种模式,关系数据库中对应的数据表或视图必须要有一个 DocId 字段,这个字段上必须要有唯一性索引(最好是聚集索引),而且要是自增长的,或者至少要保证后面插入的比前面的大。
Append,Delete,Update 模式,这种模式可以实现添加,删除和修改,内存占用比前一种方式要大一些(每条记录多4个字节)。这种模式下关系数据库中对应的数据表或视图中不能有名为 DocId 的字段,但必须有要有一个int 类型的 id 字段,id 字段的名字可以是除“DocId”外的任意名字。如果表有非int 类型的主键字段,如果建索引,我将在后续篇幅中阐述。
下面先介绍Append Only 模式,如下图所示,这是关系数据库中对应的数据表的结构:

在配置完这一步后点 Next 进入字段设置步骤
这里要特别注意的是,8.3.0 及以前版本,如果数据表中有一些特殊的数据类型,会出现一个 Tcp closed 的错误,这是一个Bug,请升级到8.3.0.1 以上版本,如何升级,见 HubbleDotNet 开源全文搜索数据库项目--如何升级 , 升级后将会出现正确提示,对特殊类型的处理,我将在后续篇幅中阐述。

如上图所示,HubbleDotNet 会自动列出所有可以索引的字段,这里我们选择
Title 和 Content 字段为全文索引字段,及 Tokenized 类型的字段,分词方法上由于是中文新闻,我们选择盘古分词,及 PanGuSegment。
Time 字段我们选择单值索引,及 UnTokenized 类型索引
Url 字段不索引,选择 None.
HublleDotNet 的数据类型见 HubbleDotNet 开源全文搜索数据库项目--数据表的数据类型和索引类型
图中每个字段左边那个 CheckBox 是删除字段用的,选中后,点 delete 将删除选中字段,如果不删除,这个 CheckBox 没有用。
完成这一步后点Next 进入最后一步

这一步列出创建语句,你可以做最后的检查,如果确认没有问题,点Finish
这时将提示

如果你打算马上就开始索引,选 Yes
这时将进入 Rebuild Table 界面

点Rebuild 就可以开始创建全文索引了
全文索引建立完以后,我们可以优化一下,如下图所示

优化完以后,就可以搜索了。(不优化也可以搜索,性能会慢一些)
下面看看怎么搜索

单词分量后面跟的参数含义如下
第一个参数表示这个单词分量的权值,这里为5000。
第二个参数表示这个单词分量在输入的被搜索的句子中的其实位置,如这里“北京”的位置为0,大学的起始位置为 2.
top 10 表示输出前10条匹配的记录

这里 title 字段后跟了一个参数2,这个参数表示 title 字段的权值为2,也就是说通过这种方法对字段设置权值。
between 0 to 9 表示输出 0 到 9 范围内的记录,这种方法可以用于分页。

采用 Contains 搜索,可以进行精确匹配,这里我们发现采用 Contains 搜索出来的数据要比 Match 少很多。因为只有同时包含“北京” 和 “大学”两个单词,才会被输出出来。

即先按时间排序,时间相同的记录,得分高的排前面。

返回 Hubble.net 技术详解
在对现有表或视图创建全文索引前,我们还是需要先在 HubbleDotNet 中创建一个数据库,如何创建数据库见:HubbleDotNet 开源全文搜索数据库项目--创建、删除数据库
创建好HubbleDotNet的数据库后就可以开始对关系数据库中现有表或视图建全文索引了。
下面我以News 库为例,创建全文索引
打开查询分析器,在News 库这个节点点右键选 Create Table,如下图所示
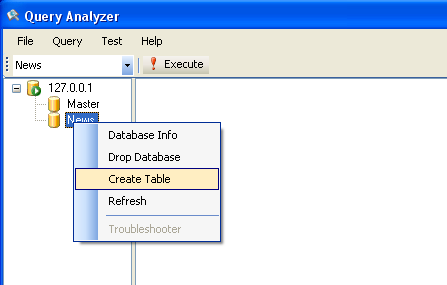
创建一个中文新闻的全文搜索
配置HubbleDotNet 数据表的基本信息
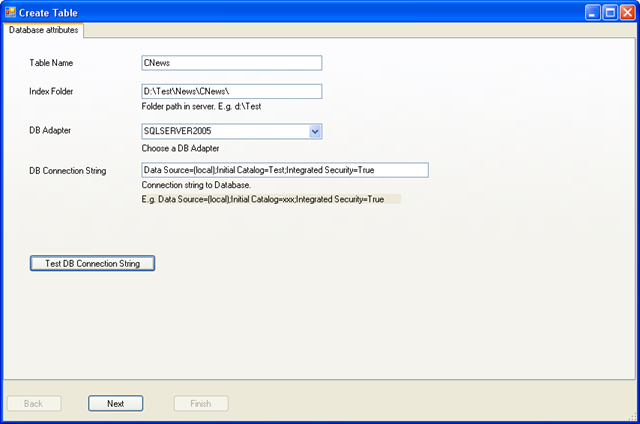
如上图所示我先演示一下如果创建一个中文新闻的全文索引。按照界面提示,输入HubbleDotNet 的表名,这里输入 CNews, 再输入全文索引所在目录,选择数据库适配器,这里由于我对应的关系数据库是SQLSERVER 2005,索引选SQLSERVER 2005, 这个适配器适用于SQL SERVER 2005 及以后的所有版本。
然后再配置一下关系数据库的连接字符串,点下面的按钮测试连接字符串没有问题,点Next 进入下一步。
选择索引模式
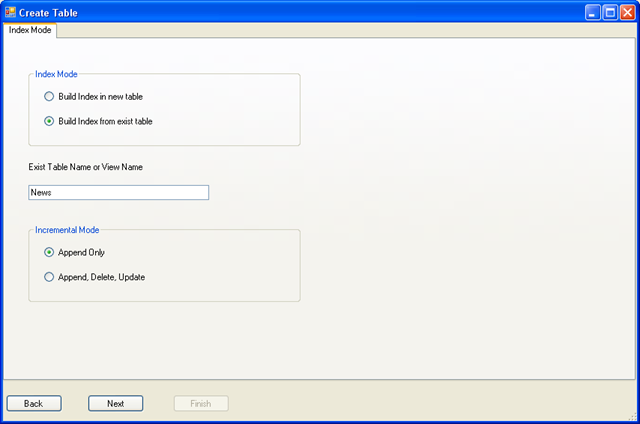
如上图所示,这一步我们需要选择索引模式
由于是从现有数据表中创建全文索引,这里选择
Build Index from exist table
在下面那个文本框中,我们要输入关系数据库中实际的数据表或视图的名称。这里输入 News。
在 Incremental Mode 这里有两个选项
Append Only 模式适用于数据只增长,不修改的模式,实际上在这种模式下只要全文索引字段不被修改就可以适用。这种模式的优点是相对 Append, Delete,Update 模式消耗的内存要少,速度稍快一些。如果要用这种模式,关系数据库中对应的数据表或视图必须要有一个 DocId 字段,这个字段上必须要有唯一性索引(最好是聚集索引),而且要是自增长的,或者至少要保证后面插入的比前面的大。
Append,Delete,Update 模式,这种模式可以实现添加,删除和修改,内存占用比前一种方式要大一些(每条记录多4个字节)。这种模式下关系数据库中对应的数据表或视图中不能有名为 DocId 的字段,但必须有要有一个int 类型的 id 字段,id 字段的名字可以是除“DocId”外的任意名字。如果表有非int 类型的主键字段,如果建索引,我将在后续篇幅中阐述。
下面先介绍Append Only 模式,如下图所示,这是关系数据库中对应的数据表的结构:

在配置完这一步后点 Next 进入字段设置步骤
这里要特别注意的是,8.3.0 及以前版本,如果数据表中有一些特殊的数据类型,会出现一个 Tcp closed 的错误,这是一个Bug,请升级到8.3.0.1 以上版本,如何升级,见 HubbleDotNet 开源全文搜索数据库项目--如何升级 , 升级后将会出现正确提示,对特殊类型的处理,我将在后续篇幅中阐述。
配置索引字段

如上图所示,HubbleDotNet 会自动列出所有可以索引的字段,这里我们选择
Title 和 Content 字段为全文索引字段,及 Tokenized 类型的字段,分词方法上由于是中文新闻,我们选择盘古分词,及 PanGuSegment。
Time 字段我们选择单值索引,及 UnTokenized 类型索引
Url 字段不索引,选择 None.
HublleDotNet 的数据类型见 HubbleDotNet 开源全文搜索数据库项目--数据表的数据类型和索引类型
图中每个字段左边那个 CheckBox 是删除字段用的,选中后,点 delete 将删除选中字段,如果不删除,这个 CheckBox 没有用。
完成这一步后点Next 进入最后一步
完成索引
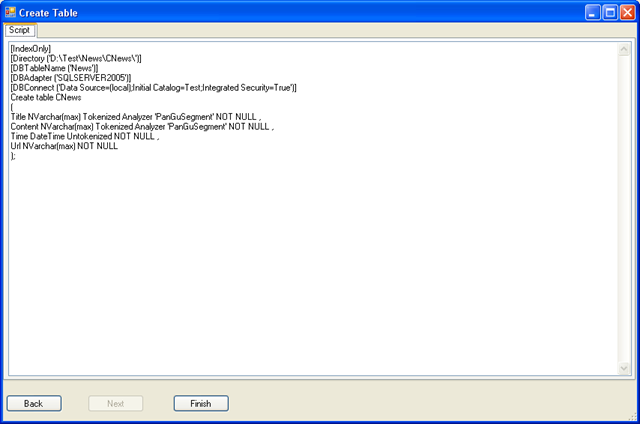
这一步列出创建语句,你可以做最后的检查,如果确认没有问题,点Finish
这时将提示
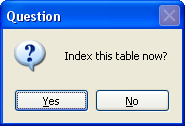
如果你打算马上就开始索引,选 Yes
这时将进入 Rebuild Table 界面
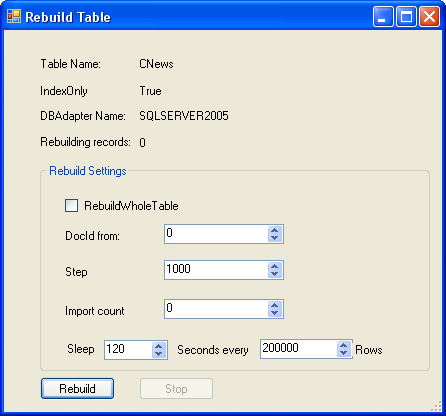
点Rebuild 就可以开始创建全文索引了
全文索引建立完以后,我们可以优化一下,如下图所示
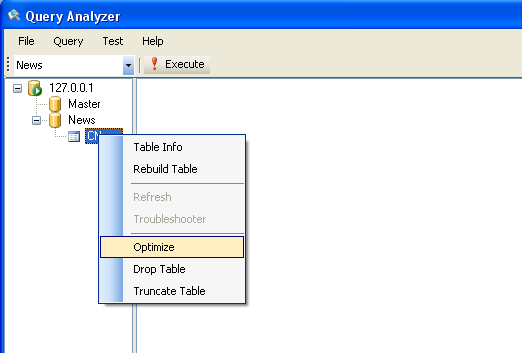
优化完以后,就可以搜索了。(不优化也可以搜索,性能会慢一些)
下面看看怎么搜索
搜索中文新闻
示例1
搜索标题中 包含 “北京” “大学” 两个关键字的所有记录,并按照得分的大小排倒序
单词分量后面跟的参数含义如下
第一个参数表示这个单词分量的权值,这里为5000。
第二个参数表示这个单词分量在输入的被搜索的句子中的其实位置,如这里“北京”的位置为0,大学的起始位置为 2.
top 10 表示输出前10条匹配的记录
示例2
搜索标题或内容中 包含 “北京” “大学” 两个关键字的所有记录,并按照得分的大小排倒序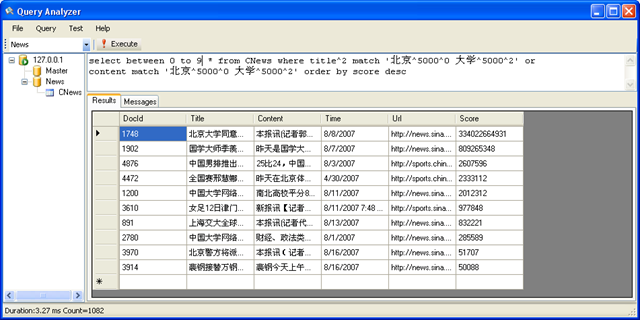
这里 title 字段后跟了一个参数2,这个参数表示 title 字段的权值为2,也就是说通过这种方法对字段设置权值。
between 0 to 9 表示输出 0 到 9 范围内的记录,这种方法可以用于分页。
示例3
搜索标题中 同时包含 “北京” “大学” 两个关键字的所有记录,并按照得分的大小排倒序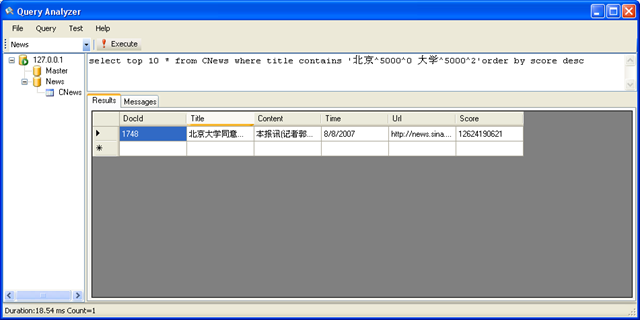
采用 Contains 搜索,可以进行精确匹配,这里我们发现采用 Contains 搜索出来的数据要比 Match 少很多。因为只有同时包含“北京” 和 “大学”两个单词,才会被输出出来。
示例4
搜索标题中 包含 “北京” “大学” 两个关键字的,并且时间大于 2007 年 1月 1日 小于 2007 年8 月16 日的所有记录,并按照时间排倒序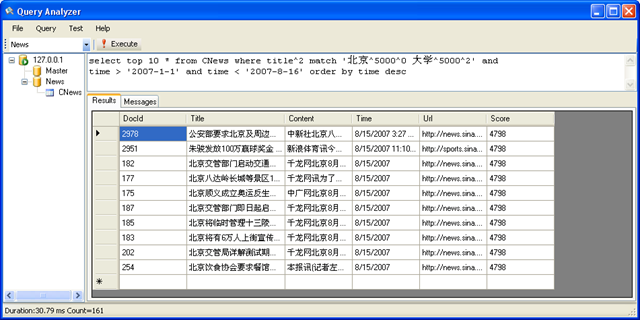
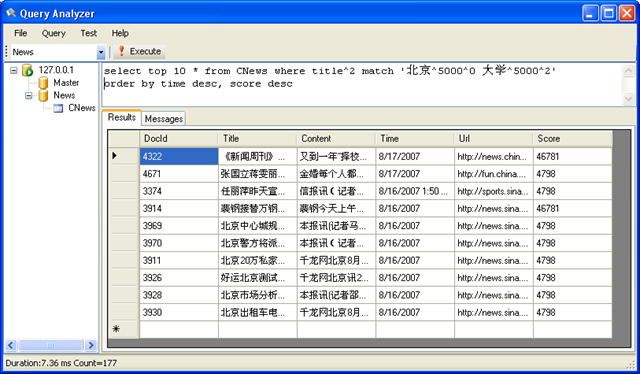
示例5
搜索标题中 包含 “北京” “大学” 两个关键字的,并且时间大于 2007 年 1月 1日 小于 2007 年8 月16 日的所有记录,并按照时间和得分同时排倒序即先按时间排序,时间相同的记录,得分高的排前面。
返回 Hubble.net 技术详解

相关文章推荐
- HubbleDotNet 开源全文搜索数据库项目--为数据库现有表或视图建立全文索引(三) 多表关联全文索引模式
- HubbleDotNet 开源全文搜索数据库项目--为数据库现有表或视图建立全文索引(三) 多表关联全文索引模式
- HubbleDotNet 开源全文搜索数据库项目--为数据库现有表建立全文索引(二) Updatable 模式
- HubbleDotNet 开源全文搜索数据库项目--通过程序和现有表或视图同步
- HubbleDotNet 开源全文搜索数据库项目--自动和现有表同步
- 【转载】HubbleDotNet 开源全文搜索数据库项目--建立数据表
- HubbleDotNet开源全文搜索数据库项目--技术详解
- HubbleDotNet开源全文搜索数据库项目--技术详解[转]
- HubbleDotNet 开源全文搜索数据库项目--数据库和数据表
- HubbleDotNet开源全文搜索数据库项目--查询方法汇总
- HubbleDotNet开源全文搜索数据库项目--如何升级
- HubbleDotNet开源全文搜索数据库项目--技术详解
- HubbleDotNet开源全文搜索数据库项目--如何升级
- HubbleDotNet 开源全文搜索数据库项目--指定文档权重
- HubbleDotNet 开源全文搜索数据库项目--建立数据表
- HubbleDotNet 开源全文搜索数据库项目--自动和现有表同步
- HubbleDotNet 开源全文搜索数据库项目--Contains 方式
- HubbleDotNet 开源全文搜索数据库项目--大量并发访问的解决方案
- HubbleDotNet开源全文搜索数据库项目
- HubbleDotNet 开源全文搜索数据库项目--创建、删除数据库