Lucene学习总结之七:Lucene搜索过程解析(6)
2010-04-04 18:12
393 查看
2.4、搜索查询对象
2.4.4、收集文档结果集合及计算打分
在函数IndexSearcher.search(Weight, Filter, int) 中,有如下代码:TopScoreDocCollector collector = TopScoreDocCollector.create(nDocs, !weight.scoresDocsOutOfOrder());
search(weight, filter, collector);
return collector.topDocs();
[b]2.4.4.1、创建结果文档收集器[/b] TopScoreDocCollector collector = TopScoreDocCollector.create(nDocs, !weight.scoresDocsOutOfOrder());
| public static TopScoreDocCollector create(int numHits, boolean docsScoredInOrder) { if (docsScoredInOrder) { return new InOrderTopScoreDocCollector(numHits); } else { return new OutOfOrderTopScoreDocCollector(numHits); } } |
[b]2.4.4.2、收集文档号[/b] 当创建完毕Scorer对象树和SumScorer对象树后,IndexSearcher.search(Weight, Filter, Collector) 有以下调用:
scorer.score(collector) ,如下代码所示,其不断的得到合并的倒排表后的文档号,并收集它们。
| public void score(Collector collector) throws IOException { collector.setScorer(this); while ((doc = countingSumScorer.nextDoc()) != NO_MORE_DOCS) { collector.collect(doc); } } |
| public void collect(int doc) throws IOException { float score = scorer.score(); totalHits++; if (score <= pqTop.score) { return; } pqTop.doc = doc + docBase; pqTop.score = score; pqTop = pq.updateTop(); } |
| public void collect(int doc) throws IOException { float score = scorer.score(); totalHits++; doc += docBase; if (score < pqTop.score || (score == pqTop.score && doc > pqTop.doc)) { return; } pqTop.doc = doc; pqTop.score = score; pqTop = pq.updateTop(); } |
然而存在一个问题,如果要取10篇文档,而第8,9,10,11,12篇文档的打分都相同,则抛弃那些呢?Lucene的策略是,在文档打分相同的情况下,文档号小的优先。
也即8,9,10被保留,11,12被抛弃。
由上面的叙述可知,创建collector的时候,根据文档是否将按照文档号从小到大的顺序返回而创建InOrderTopScoreDocCollector或者OutOfOrderTopScoreDocCollector。
对于InOrderTopScoreDocCollector,由于文档是按照顺序返回的,后来的文档号肯定大于前面的文档号,因而当score <= pqTop.score的时候,直接抛弃。
对于OutOfOrderTopScoreDocCollector,由于文档不是按顺序返回的,因而当score<pqTop.score,自然直接抛弃,当score==pqTop.score的时候,则要比较后来的文档和前面的文档的大小,如果大于,则抛弃,如果小于则入队列。
[b]2.4.4.3、打分计算[/b] BooleanScorer2的打分函数如下:
将子语句的打分乘以coord
| public float score() throws IOException { coordinator.nrMatchers = 0; float sum = countingSumScorer.score(); return sum * coordinator.coordFactors[coordinator.nrMatchers]; } |
将取交集的子语句的打分相加,然后乘以coord
| public float score() throws IOException { float sum = 0.0f; for (int i = 0; i < scorers.length; i++) { sum += scorers[i].score(); } return sum * coord; } |
| public float score() throws IOException { return currentScore; } currentScore计算如下: currentScore += scorerDocQueue.topScore(); 以上计算是在DisjunctionSumScorer的倒排表合并算法中进行的,其是取堆顶的打分函数。 public final float topScore() throws IOException { return topHSD.scorer.score(); } |
仅仅取required语句的打分
| public float score() throws IOException { return reqScorer.score(); } |
上面曾经指出,ReqOptSumScorer的nextDoc()函数仅仅返回required语句的文档号。
而optional的部分仅仅在打分的时候有所体现,从下面的实现可以看出optional的语句的分数加到required语句的分数上,也即文档还是required语句包含的文档,只不过是当此文档能够满足optional的语句的时候,打分得到增加。
| public float score() throws IOException { int curDoc = reqScorer.docID(); float reqScore = reqScorer.score(); if (optScorer == null) { return reqScore; } int optScorerDoc = optScorer.docID(); if (optScorerDoc < curDoc && (optScorerDoc = optScorer.advance(curDoc)) == NO_MORE_DOCS) { optScorer = null; return reqScore; } return optScorerDoc == curDoc ? reqScore + optScorer.score() : reqScore; } |
整个Scorer及SumScorer对象树的打分计算,最终都会源自叶子节点TermScorer上。
从TermScorer的计算可以看出,它计算出tf * norm * weightValue = tf * norm * queryNorm * idf^2 * t.getBoost()
| public float score() { int f = freqs[pointer]; float raw = f < SCORE_CACHE_SIZE ? scoreCache[f] : getSimilarity().tf(f)*weightValue; return norms == null ? raw : raw * SIM_NORM_DECODER[norms[doc] & 0xFF]; } |
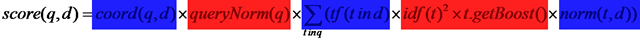
打分计算到此结束。
[b]2.4.4.4、返回打分最高的N篇文档[/b] IndexSearcher.search(Weight, Filter, int)中,在收集完文档后,调用collector.topDocs()返回打分最高的N篇文档:
| public final TopDocs topDocs() { return topDocs(0, totalHits < pq.size() ? totalHits : pq.size()); } |
| public final TopDocs topDocs(int start, int howMany) { int size = totalHits < pq.size() ? totalHits : pq.size(); howMany = Math.min(size - start, howMany); ScoreDoc[] results = new ScoreDoc[howMany]; //由于pq是最小堆,因而要首先弹出最小的文档。比如qp中总共有50篇文档,想取第5到10篇文档,则应该先弹出打分最小的40篇文档。 for (int i = pq.size() - start - howMany; i > 0; i--) { pq.pop(); } populateResults(results, howMany); return newTopDocs(results, start); } |
| protected void populateResults(ScoreDoc[] results, int howMany) { //然后再从pq弹出第5到10篇文档,并按照打分从大到小的顺序放入results中。 for (int i = howMany - 1; i >= 0; i--) { results[i] = pq.pop(); } } |
| protected TopDocs newTopDocs(ScoreDoc[] results, int start) { return results == null ? EMPTY_TOPDOCS : new TopDocs(totalHits, results); } |
2.4.5、Lucene如何在搜索阶段读取索引信息
以上叙述的是搜索过程中如何进行倒排表合并以及计算打分。然而索引信息是从索引文件中读出来的,下面分析如何读取这些信息。其实读取的信息无非是两种信息,一个是词典信息,一个是倒排表信息。
词典信息的读取是在Scorer对象树生成的时候进行的,真正读取这些信息的是叶子节点TermScorer。
倒排表信息的读取时在合并倒排表的时候进行的,真正读取这些信息的也是叶子节点TermScorer.nextDoc()。
[b]2.4.5.1、读取词典信息[/b] 此步是在TermWeight.scorer(IndexReader, boolean, boolean) 中进行的,其代码如下:
| public Scorer scorer(IndexReader reader, boolean scoreDocsInOrder, boolean topScorer) { TermDocs termDocs = reader.termDocs(term); if (termDocs == null) return null; return new TermScorer(this, termDocs, similarity, reader.norms(term.field())); } |
| public TermDocs termDocs(Term term) throws IOException { ensureOpen(); TermDocs termDocs = termDocs(); termDocs.seek(term); return termDocs; } |
| protected SegmentTermDocs(SegmentReader parent) { this.parent = parent; this.freqStream = (IndexInput) parent.core.freqStream.clone();//用于读取freq synchronized (parent) { this.deletedDocs = parent.deletedDocs; } this.skipInterval = parent.core.getTermsReader().getSkipInterval(); this.maxSkipLevels = parent.core.getTermsReader().getMaxSkipLevels(); } |
| public void seek(Term term) throws IOException { TermInfo ti = parent.core.getTermsReader().get(term); seek(ti, term); } |
| TermInfosReader.get(Term, boolean)主要是读取词典中的Term得到TermInfo,代码如下: private TermInfo get(Term term, boolean useCache) { if (size == 0) return null; ensureIndexIsRead(); TermInfo ti; ThreadResources resources = getThreadResources(); SegmentTermEnum enumerator = resources.termEnum; seekEnum(enumerator, getIndexOffset(term)); enumerator.scanTo(term); if (enumerator.term() != null && term.compareTo(enumerator.term()) == 0) { ti = enumerator.termInfo(); } else { ti = null; } return ti; } |
| private final void seekEnum(SegmentTermEnum enumerator, int indexOffset) throws IOException { enumerator.seek(indexPointers[indexOffset], (indexOffset * totalIndexInterval) - 1, indexTerms[indexOffset], indexInfos[indexOffset]); } |
| final void SegmentTermEnum.seek(long pointer, int p, Term t, TermInfo ti) { input.seek(pointer); position = p; termBuffer.set(t); prevBuffer.reset(); termInfo.set(ti); } |
| final int scanTo(Term term) throws IOException { scanBuffer.set(term); int count = 0; //不断取得下一个term到termBuffer中,目标term放入scanBuffer中,当两者相等的时候,目标Term找到。 while (scanBuffer.compareTo(termBuffer) > 0 && next()) { count++; } return count; } |
| public final boolean next() throws IOException { if (position++ >= size - 1) { prevBuffer.set(termBuffer); termBuffer.reset(); return false; } prevBuffer.set(termBuffer); //读取Term的字符串 termBuffer.read(input, fieldInfos); //读取docFreq,也即多少文档包含此Term termInfo.docFreq = input.readVInt(); //读取偏移量 termInfo.freqPointer += input.readVLong(); termInfo.proxPointer += input.readVLong(); if (termInfo.docFreq >= skipInterval) termInfo.skipOffset = input.readVInt(); indexPointer += input.readVLong(); return true; } |
| TermBuffer.read(IndexInput, FieldInfos) 代码如下: public final void read(IndexInput input, FieldInfos fieldInfos) { this.term = null; int start = input.readVInt(); int length = input.readVInt(); int totalLength = start + length; text.setLength(totalLength); input.readChars(text.result, start, length); this.field = fieldInfos.fieldName(input.readVInt()); } |
| void seek(TermInfo ti, Term term) { count = 0; FieldInfo fi = parent.core.fieldInfos.fieldInfo(term.field); df = ti.docFreq; doc = 0; freqBasePointer = ti.freqPointer; proxBasePointer = ti.proxPointer; skipPointer = freqBasePointer + ti.skipOffset; freqStream.seek(freqBasePointer); haveSkipped = false; } |
| public int nextDoc() throws IOException { pointer++; if (pointer >= pointerMax) { pointerMax = termDocs.read(docs, freqs); if (pointerMax != 0) { pointer = 0; } else { termDocs.close(); return doc = NO_MORE_DOCS; } } doc = docs[pointer]; return doc; } |
| public int read(final int[] docs, final int[] freqs) { final int length = docs.length; int i = 0; while (i < length && count < df) { //读取docid final int docCode = freqStream.readVInt(); doc += docCode >>> 1; if ((docCode & 1) != 0) freq = 1; else freq = freqStream.readVInt(); //读取freq count++; if (deletedDocs == null || !deletedDocs.get(doc)) { docs[i] = doc; freqs[i] = freq; ++i; } return i; } } |

相关文章推荐
- Lucene学习总结之七:Lucene搜索过程解析(1)
- Lucene学习总结之七:Lucene搜索过程解析(1)
- Lucene学习总结之七:Lucene搜索过程解析(3)
- Lucene学习总结之七:Lucene搜索过程解析(2)
- Lucene学习总结之七:Lucene搜索过程解析(2)
- Lucene学习总结之七:Lucene搜索过程解析(5)
- Lucene学习总结之七:Lucene搜索过程解析(3)
- Lucene学习总结之七:Lucene搜索过程解析(3)
- Lucene学习总结之七:Lucene搜索过程解析(3)
- Lucene学习总结之七:Lucene搜索过程解析(4)
- Lucene学习总结之七:Lucene搜索过程解析(4)
- Lucene学习总结之七:Lucene搜索过程解析(4)
- Lucene学习总结之七:Lucene搜索过程解析(6)
- Lucene学习总结之七:Lucene搜索过程解析(5)
- Lucene学习总结之七:Lucene搜索过程解析(2)
- Lucene学习总结之七:Lucene搜索过程解析(6)
- Lucene学习总结之七:Lucene搜索过程解析(2)
- Lucene学习总结之七:Lucene搜索过程解析(3)
- Lucene学习总结之七:Lucene搜索过程解析
- Lucene学习总结之七:Lucene搜索过程解析(1)