Lucene学习总结之七:Lucene搜索过程解析(4)
2010-04-04 17:53
537 查看
2.4、搜索查询对象
[b]2.4.1.2、创建Weight对象树[/b] BooleanQuery.createWeight(Searcher) 最终返回return new BooleanWeight(searcher),BooleanWeight构造函数的具体实现如下:| public BooleanWeight(Searcher searcher) { this.similarity = getSimilarity(searcher); weights = new ArrayList<Weight>(clauses.size()); //也是一个递归的过程,沿着新的Query对象树一直到叶子节点 for (int i = 0 ; i < clauses.size(); i++) { weights.add(clauses.get(i).getQuery().createWeight(searcher)); } } |
| public TermWeight(Searcher searcher) { this.similarity = getSimilarity(searcher); //此处计算了idf idfExp = similarity.idfExplain(term, searcher); idf = idfExp.getIdf(); } |
//idf的计算完全符合文档中的公式: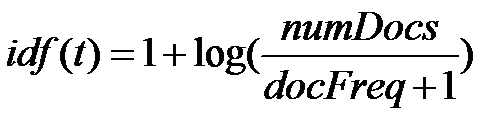 public IDFExplanation idfExplain(final Term term, final Searcher searcher) { final int df = searcher.docFreq(term); final int max = searcher.maxDoc(); final float idf = idf(df, max); return new IDFExplanation() { public float getIdf() { return idf; }}; } |
| public float idf(int docFreq, int numDocs) { return (float)(Math.log(numDocs/(double)(docFreq+1)) + 1.0); } |
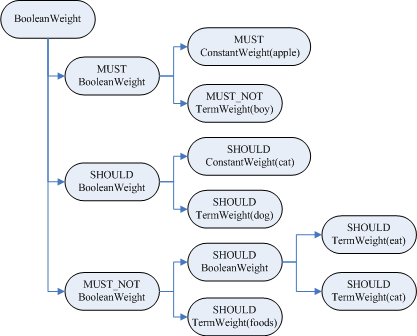
由此创建的Weight对象树如下:
| weight BooleanQuery$BooleanWeight (id=169) | similarity DefaultSimilarity (id=177) | this$0 BooleanQuery (id=89) | weights ArrayList<E> (id=188) | elementData Object[3] (id=190) |------[0] BooleanQuery$BooleanWeight (id=171) | | similarity DefaultSimilarity (id=177) | | this$0 BooleanQuery (id=105) | | weights ArrayList<E> (id=193) | | elementData Object[2] (id=199) | |------[0] ConstantScoreQuery$ConstantWeight (id=183) | | queryNorm 0.0 | | queryWeight 0.0 | | similarity DefaultSimilarity (id=177) | | //ConstantScore(contents:apple*) | | this$0 ConstantScoreQuery (id=123) | |------[1] TermQuery$TermWeight (id=175) | idf 2.0986123 | idfExp Similarity$1 (id=241) | queryNorm 0.0 | queryWeight 0.0 | similarity DefaultSimilarity (id=177) | //contents:boy | this$0 TermQuery (id=124) | value 0.0 | modCount 2 | size 2 |------[1] BooleanQuery$BooleanWeight (id=179) | | similarity DefaultSimilarity (id=177) | | this$0 BooleanQuery (id=110) | | weights ArrayList<E> (id=195) | | elementData Object[2] (id=204) | |------[0] ConstantScoreQuery$ConstantWeight (id=206) | | queryNorm 0.0 | | queryWeight 0.0 | | similarity DefaultSimilarity (id=177) | | //ConstantScore(contents:cat*) | | this$0 ConstantScoreQuery (id=135) | |------[1] TermQuery$TermWeight (id=207) | idf 1.5389965 | idfExp Similarity$1 (id=210) | queryNorm 0.0 | queryWeight 0.0 | similarity DefaultSimilarity (id=177) | //contents:dog | this$0 TermQuery (id=136) | value 0.0 | modCount 2 | size 2 |------[2] BooleanQuery$BooleanWeight (id=182) | similarity DefaultSimilarity (id=177) | this$0 BooleanQuery (id=113) | weights ArrayList<E> (id=197) | elementData Object[2] (id=216) |------[0] BooleanQuery$BooleanWeight (id=181) | | similarity BooleanQuery$1 (id=220) | | this$0 BooleanQuery (id=145) | | weights ArrayList<E> (id=221) | | elementData Object[2] (id=224) | |------[0] TermQuery$TermWeight (id=226) | | idf 2.0986123 | | idfExp Similarity$1 (id=229) | | queryNorm 0.0 | | queryWeight 0.0 | | similarity DefaultSimilarity (id=177) | | //contents:eat | | this$0 TermQuery (id=150) | | value 0.0 | |------[1] TermQuery$TermWeight (id=227) | idf 1.1823215 | idfExp Similarity$1 (id=231) | queryNorm 0.0 | queryWeight 0.0 | similarity DefaultSimilarity (id=177) | //contents:cat^0.33333325 | this$0 TermQuery (id=151) | value 0.0 | modCount 2 | size 2 |------[1] TermQuery$TermWeight (id=218) idf 2.0986123 idfExp Similarity$1 (id=233) queryNorm 0.0 queryWeight 0.0 similarity DefaultSimilarity (id=177) //contents:foods this$0 TermQuery (id=154) value 0.0 modCount 2 size 2 modCount 3 size 3 |
[b]2.4.1.3、计算Term Weight分数[/b] (1) 首先计算sumOfSquaredWeights
按照公式:
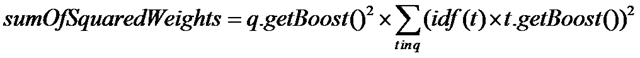
代码如下:
float sum = weight.sumOfSquaredWeights();
| //可以看出,也是一个递归的过程 public float sumOfSquaredWeights() throws IOException { float sum = 0.0f; for (int i = 0 ; i < weights.size(); i++) { float s = weights.get(i).sumOfSquaredWeights(); if (!clauses.get(i).isProhibited()) sum += s; } sum *= getBoost() * getBoost(); //乘以query boost return sum ; } |
| public float sumOfSquaredWeights() { //计算一部分打分,idf*t.getBoost(),将来还会用到。 queryWeight = idf * getBoost(); //计算(idf*t.getBoost())^2 return queryWeight * queryWeight; } |
| public float sumOfSquaredWeights() { //除了用户指定的boost以外,其他都不计算在打分内 queryWeight = getBoost(); return queryWeight * queryWeight; } |
其公式如下:
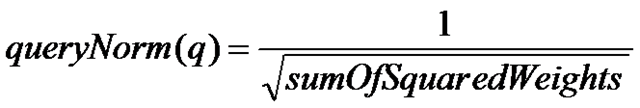
其代码如下:
| public float queryNorm(float sumOfSquaredWeights) { return (float)(1.0 / Math.sqrt(sumOfSquaredWeights)); } |
代码为:
weight.normalize(norm);
| //又是一个递归的过程 public void normalize(float norm) { norm *= getBoost(); for (Weight w : weights) { w.normalize(norm); } } |
| public void normalize(float queryNorm) { this.queryNorm = queryNorm; //原来queryWeight为idf*t.getBoost(),现在为queryNorm*idf*t.getBoost()。 queryWeight *= queryNorm; //打分到此计算了queryNorm*idf*t.getBoost()*idf = queryNorm*idf^2*t.getBoost()部分。 value = queryWeight * idf; } |
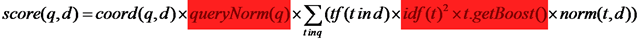
2.4.2、创建Scorer及SumScorer对象树
当创建完Weight对象树的时候,调用IndexSearcher.search(Weight, Filter, int),代码如下:| //(a)创建文档号收集器 TopScoreDocCollector collector = TopScoreDocCollector.create(nDocs, !weight.scoresDocsOutOfOrder()); search(weight, filter, collector); //(b)返回搜索结果 return collector.topDocs(); |
| public void search(Weight weight, Filter filter, Collector collector) throws IOException { if (filter == null) { for (int i = 0; i < subReaders.length; i++) { collector.setNextReader(subReaders[i], docStarts[i]); //(c)创建Scorer对象树,以及SumScorer树用来合并倒排表 Scorer scorer = weight.scorer(subReaders[i], !collector.acceptsDocsOutOfOrder(), true); if (scorer != null) { //(d)合并倒排表,(e)收集文档号 scorer.score(collector); } } } else { for (int i = 0; i < subReaders.length; i++) { collector.setNextReader(subReaders[i], docStarts[i]); searchWithFilter(subReaders[i], weight, filter, collector); } } } |
BooleanQuery$BooleanWeight.scorer(IndexReader, boolean, boolean) 代码如下:
| public Scorer scorer(IndexReader reader, boolean scoreDocsInOrder, boolean topScorer){ //存放对应于MUST语句的Scorer List<Scorer> required = new ArrayList<Scorer>(); //存放对应于MUST_NOT语句的Scorer List<Scorer> prohibited = new ArrayList<Scorer>(); //存放对应于SHOULD语句的Scorer List<Scorer> optional = new ArrayList<Scorer>(); //遍历每一个子语句,生成子Scorer对象,并加入相应的集合,这是一个递归的过程。 Iterator<BooleanClause> cIter = clauses.iterator(); for (Weight w : weights) { BooleanClause c = cIter.next(); Scorer subScorer = w.scorer(reader, true, false); if (subScorer == null) { if (c.isRequired()) { return null; } } else if (c.isRequired()) { required.add(subScorer); } else if (c.isProhibited()) { prohibited.add(subScorer); } else { optional.add(subScorer); } } //此处在有关BooleanScorer及scoreDocsInOrder一节会详细描述 if (!scoreDocsInOrder && topScorer && required.size() == 0 && prohibited.size() < 32) { return new BooleanScorer(similarity, minNrShouldMatch, optional, prohibited); } //生成Scorer对象树,同时生成SumScorer对象树 return new BooleanScorer2(similarity, minNrShouldMatch, required, prohibited, optional); } |
| public Scorer scorer(IndexReader reader, boolean scoreDocsInOrder, boolean topScorer) throws IOException { //此Term的倒排表 TermDocs termDocs = reader.termDocs(term); if (termDocs == null) return null; return new TermScorer(this, termDocs, similarity, reader.norms(term.field())); } |
| TermScorer(Weight weight, TermDocs td, Similarity similarity, byte[] norms) { super(similarity); this.weight = weight; this.termDocs = td; //得到标准化因子 this.norms = norms; //得到原来计算得的打分:queryNorm*idf^2*t.getBoost() this.weightValue = weight.getValue(); for (int i = 0; i < SCORE_CACHE_SIZE; i++) scoreCache[i] = getSimilarity().tf(i) * weightValue; } |
| public ConstantScorer(Similarity similarity, IndexReader reader, Weight w) { super(similarity); theScore = w.getValue(); //得到所有的文档号,形成统一的倒排表,参与倒排表合并。 DocIdSet docIdSet = filter.getDocIdSet(reader); DocIdSetIterator docIdSetIterator = docIdSet.iterator(); } |
| public BooleanScorer2(Similarity similarity, int minNrShouldMatch, List<Scorer> required, List<Scorer> prohibited, List<Scorer> optional) { super(similarity); //为了计算打分公式中的coord项做统计 coordinator = new Coordinator(); this.minNrShouldMatch = minNrShouldMatch; //SHOULD的部分 optionalScorers = optional; coordinator.maxCoord += optional.size(); //MUST的部分 requiredScorers = required; coordinator.maxCoord += required.size(); //MUST_NOT的部分 prohibitedScorers = prohibited; //事先计算好各种情况的coord值 coordinator.init(); //创建SumScorer为倒排表合并做准备 countingSumScorer = makeCountingSumScorer(); } |
| Coordinator.init() { coordFactors = new float[maxCoord + 1]; Similarity sim = getSimilarity(); for (int i = 0; i <= maxCoord; i++) { //计算总的子语句的个数和一个文档满足的子语句的个数之间的关系,自然是一篇文档满足的子语句个个数越多,打分越高。 coordFactors[i] = sim.coord(i, maxCoord); } } |
在解析BooleanScorer2.makeCountingSumScorer() 之前,我们先来看不同的语句之间都存在什么样的关系,又将如何影响倒排表合并呢?
语句主要分三类:MUST,SHOULD,MUST_NOT
语句之间的组合主要有以下几种情况:
多个MUST,如"(+apple +boy +dog)",则会生成ConjunctionScorer(Conjunction 交集),也即倒排表取交集
MUST和SHOULD,如"(+apple boy)",则会生成ReqOptSumScorer(required optional),也即MUST的倒排表返回,如果文档包括SHOULD的部分,则增加打分。
MUST和MUST_NOT,如"(+apple –boy)",则会生成ReqExclScorer(required exclusive),也即返回MUST的倒排表,但扣除MUST_NOT的倒排表中的文档。
多个SHOULD,如"(apple boy dog)",则会生成DisjunctionSumScorer(Disjunction 并集),也即倒排表去并集
SHOULD和MUST_NOT,如"(apple –boy)",则SHOULD被认为成MUST,会生成ReqExclScorer
MUST,SHOULD,MUST_NOT同时出现,则MUST首先和MUST_NOT组合成ReqExclScorer,SHOULD单独成为SingleMatchScorer,然后两者组合成ReqOptSumScorer。
下面分析生成SumScorer的过程:
BooleanScorer2.makeCountingSumScorer() 分两种情况:
当有MUST的语句的时候,则调用makeCountingSumScorerSomeReq()
当没有MUST的语句的时候,则调用makeCountingSumScorerNoReq()
首先来看makeCountingSumScorerSomeReq代码如下:
| private Scorer makeCountingSumScorerSomeReq() { if (optionalScorers.size() == minNrShouldMatch) { //如果optional的语句个数恰好等于最少需满足的optional的个数,则所有的optional都变成required。于是首先所有的optional生成ConjunctionScorer(交集),然后再通过addProhibitedScorers将prohibited加入,生成ReqExclScorer(required exclusive) ArrayList<Scorer> allReq = new ArrayList<Scorer>(requiredScorers); allReq.addAll(optionalScorers); return addProhibitedScorers(countingConjunctionSumScorer(allReq)); } else { //首先所有的required的语句生成ConjunctionScorer(交集) Scorer requiredCountingSumScorer = requiredScorers.size() == 1 ? new SingleMatchScorer(requiredScorers.get(0)) : countingConjunctionSumScorer(requiredScorers); if (minNrShouldMatch > 0) { //如果最少需满足的optional的个数有一定的限制,则意味着optional中有一部分要相当于required,会影响倒排表的合并。因而required生成的ConjunctionScorer(交集)和optional生成的DisjunctionSumScorer(并集)共同组合成一个ConjunctionScorer(交集),然后再加入prohibited,生成ReqExclScorer return addProhibitedScorers( dualConjunctionSumScorer( requiredCountingSumScorer, countingDisjunctionSumScorer( optionalScorers, minNrShouldMatch))); } else { // minNrShouldMatch == 0 //如果最少需满足的optional的个数没有一定的限制,则optional并不影响倒排表的合并,仅仅在文档包含optional部分的时候增加打分。所以required和prohibited首先生成ReqExclScorer,然后再加入optional,生成ReqOptSumScorer(required optional) return new ReqOptSumScorer( addProhibitedScorers(requiredCountingSumScorer), optionalScorers.size() == 1 ? new SingleMatchScorer(optionalScorers.get(0)) : countingDisjunctionSumScorer(optionalScorers, 1)); } } } |
| private Scorer makeCountingSumScorerNoReq() { // minNrShouldMatch optional scorers are required, but at least 1 int nrOptRequired = (minNrShouldMatch < 1) ? 1 : minNrShouldMatch; Scorer requiredCountingSumScorer; if (optionalScorers.size() > nrOptRequired) //如果optional的语句个数多于最少需满足的optional的个数,则optional中一部分相当required,影响倒排表的合并,所以生成DisjunctionSumScorer requiredCountingSumScorer = countingDisjunctionSumScorer(optionalScorers, nrOptRequired); else if (optionalScorers.size() == 1) //如果optional的语句只有一个,则返回SingleMatchScorer,不存在倒排表合并的问题。 requiredCountingSumScorer = new SingleMatchScorer(optionalScorers.get(0)); else //如果optional的语句个数少于等于最少需满足的optional的个数,则所有的optional都算required,所以生成ConjunctionScorer requiredCountingSumScorer = countingConjunctionSumScorer(optionalScorers); //将prohibited加入,生成ReqExclScorer return addProhibitedScorers(requiredCountingSumScorer); } |
| scorer BooleanScorer2 (id=50) | coordinator BooleanScorer2$Coordinator (id=53) | countingSumScorer ReqOptSumScorer (id=54) | minNrShouldMatch 0 |---optionalScorers ArrayList<E> (id=55) | | elementData Object[10] (id=69) | |---[0] BooleanScorer2 (id=73) | | coordinator BooleanScorer2$Coordinator (id=74) | | countingSumScorer BooleanScorer2$1 (id=75) | | minNrShouldMatch 0 | |---optionalScorers ArrayList<E> (id=76) | | | elementData Object[10] (id=83) | | |---[0] ConstantScoreQuery$ConstantScorer (id=86) | | | docIdSetIterator OpenBitSetIterator (id=88) | | | similarity DefaultSimilarity (id=64) | | | theScore 0.47844642 | | | //ConstantScore(contents:cat*) | | | this$0 ConstantScoreQuery (id=90) | | |---[1] TermScorer (id=87) | | doc -1 | | doc 0 | | docs int[32] (id=93) | | freqs int[32] (id=95) | | norms byte[4] (id=96) | | pointer 0 | | pointerMax 2 | | scoreCache float[32] (id=98) | | similarity DefaultSimilarity (id=64) | | termDocs SegmentTermDocs (id=103) | | //weight(contents:dog) | | weight TermQuery$TermWeight (id=106) | | weightValue 1.1332052 | | modCount 2 | | size 2 | |---prohibitedScorers ArrayList<E> (id=77) | | elementData Object[10] (id=84) | | size 0 | |---requiredScorers ArrayList<E> (id=78) | elementData Object[10] (id=85) | size 0 | similarity DefaultSimilarity (id=64) | size 1 |---prohibitedScorers ArrayList<E> (id=60) | | elementData Object[10] (id=71) | |---[0] BooleanScorer2 (id=81) | | coordinator BooleanScorer2$Coordinator (id=114) | | countingSumScorer BooleanScorer2$1 (id=115) | | minNrShouldMatch 0 | |---optionalScorers ArrayList<E> (id=116) | | | elementData Object[10] (id=119) | | |---[0] BooleanScorer2 (id=122) | | | | coordinator BooleanScorer2$Coordinator (id=124) | | | | countingSumScorer BooleanScorer2$1 (id=125) | | | | minNrShouldMatch 0 | | | |---optionalScorers ArrayList<E> (id=126) | | | | | elementData Object[10] (id=138) | | | | |---[0] TermScorer (id=156) | | | | | docs int[32] (id=162) | | | | | freqs int[32] (id=163) | | | | | norms byte[4] (id=96) | | | | | pointer 0 | | | | | pointerMax 1 | | | | | scoreCache float[32] (id=164) | | | | | similarity DefaultSimilarity (id=64) | | | | | termDocs SegmentTermDocs (id=165) | | | | | //weight(contents:eat) | | | | | weight TermQuery$TermWeight (id=166) | | | | | weightValue 2.107161 | | | | |---[1] TermScorer (id=157) | | | | doc -1 | | | | doc 1 | | | | docs int[32] (id=171) | | | | freqs int[32] (id=172) | | | | norms byte[4] (id=96) | | | | pointer 1 | | | | pointerMax 3 | | | | scoreCache float[32] (id=173) | | | | similarity DefaultSimilarity (id=64) | | | | termDocs SegmentTermDocs (id=180) | | | | //weight(contents:cat^0.33333325) | | | | weight TermQuery$TermWeight (id=181) | | | | weightValue 0.22293752 | | | | size 2 | | | |---prohibitedScorers ArrayList<E> (id=127) | | | | elementData Object[10] (id=140) | | | | modCount 0 | | | | size 0 | | | |---requiredScorers ArrayList<E> (id=128) | | | elementData Object[10] (id=142) | | | modCount 0 | | | size 0 | | | similarity BooleanQuery$1 (id=129) | | |---[1] TermScorer (id=123) | | doc -1 | | doc 3 | | docs int[32] (id=131) | | freqs int[32] (id=132) | | norms byte[4] (id=96) | | pointer 0 | | pointerMax 1 | | scoreCache float[32] (id=133) | | similarity DefaultSimilarity (id=64) | | termDocs SegmentTermDocs (id=134) | | //weight(contents:foods) | | weight TermQuery$TermWeight (id=135) | | weightValue 2.107161 | | size 2 | |---prohibitedScorers ArrayList<E> (id=117) | | elementData Object[10] (id=120) | | size 0 | |---requiredScorers ArrayList<E> (id=118) | elementData Object[10] (id=121) | size 0 | similarity DefaultSimilarity (id=64) | size 1 |---requiredScorers ArrayList<E> (id=63) | elementData Object[10] (id=72) |---[0] BooleanScorer2 (id=82) | coordinator BooleanScorer2$Coordinator (id=183) | countingSumScorer ReqExclScorer (id=184) | minNrShouldMatch 0 |---optionalScorers ArrayList<E> (id=185) | elementData Object[10] (id=189) | size 0 |---prohibitedScorers ArrayList<E> (id=186) | | elementData Object[10] (id=191) | |---[0] TermScorer (id=195) | docs int[32] (id=197) | freqs int[32] (id=198) | norms byte[4] (id=96) | pointer 0 | pointerMax 0 | scoreCache float[32] (id=199) | similarity DefaultSimilarity (id=64) | termDocs SegmentTermDocs (id=200) | //weight(contents:boy) | weight TermQuery$TermWeight (id=201) | weightValue 2.107161 | size 1 |---requiredScorers ArrayList<E> (id=187) | elementData Object[10] (id=193) |---[0] ConstantScoreQuery$ConstantScorer (id=203) docIdSetIterator OpenBitSetIterator (id=206) similarity DefaultSimilarity (id=64) theScore 0.47844642 //ConstantScore(contents:apple*) this$0 ConstantScoreQuery (id=207) size 1 similarity DefaultSimilarity (id=64) size 1 similarity DefaultSimilarity (id=64) |
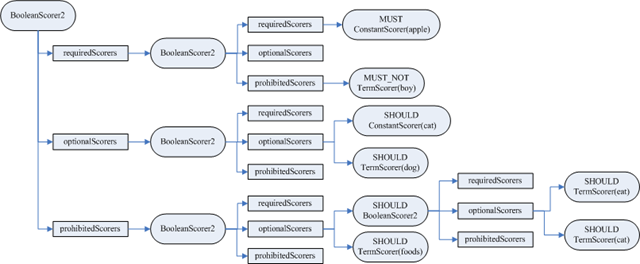
生成的SumScorer对象树如下:
| scorer BooleanScorer2 (id=50) | coordinator BooleanScorer2$Coordinator (id=53) |---countingSumScorer ReqOptSumScorer (id=54) |---optScorer BooleanScorer2$SingleMatchScorer (id=79) | | lastDocScore NaN | | lastScoredDoc -1 | |---scorer BooleanScorer2 (id=73) | | coordinator BooleanScorer2$Coordinator (id=74) | |---countingSumScorer BooleanScorer2$1(DisjunctionSumScorer) (id=75) | | currentDoc -1 | | currentScore NaN | | doc -1 | | lastDocScore NaN | | lastScoredDoc -1 | | minimumNrMatchers 1 | | nrMatchers -1 | | nrScorers 2 | | scorerDocQueue ScorerDocQueue (id=243) | | similarity null | |---subScorers ArrayList<E> (id=76) | | elementData Object[10] (id=83) | |---[0] ConstantScoreQuery$ConstantScorer (id=86) | | doc -1 | | doc -1 | | docIdSetIterator OpenBitSetIterator (id=88) | | similarity DefaultSimilarity (id=64) | | theScore 0.47844642 | | //ConstantScore(contents:cat*) | | this$0 ConstantScoreQuery (id=90) | |---[1] TermScorer (id=87) | doc -1 | doc 0 | docs int[32] (id=93) | freqs int[32] (id=95) | norms byte[4] (id=96) | pointer 0 | pointerMax 2 | scoreCache float[32] (id=98) | similarity DefaultSimilarity (id=64) | termDocs SegmentTermDocs (id=103) | //weight(contents:dog) | weight TermQuery$TermWeight (id=106) | weightValue 1.1332052 | size 2 | this$0 BooleanScorer2 (id=73) | minNrShouldMatch 0 | optionalScorers ArrayList<E> (id=76) | prohibitedScorers ArrayList<E> (id=77) | requiredScorers ArrayList<E> (id=78) | similarity DefaultSimilarity (id=64) | similarity DefaultSimilarity (id=64) | this$0 BooleanScorer2 (id=50) |---reqScorer ReqExclScorer (id=80) |---exclDisi BooleanScorer2 (id=81) | | coordinator BooleanScorer2$Coordinator (id=114) | |---countingSumScorer BooleanScorer2$1(DisjunctionSumScorer) (id=115) | | currentDoc -1 | | currentScore NaN | | doc -1 | | lastDocScore NaN | | lastScoredDoc -1 | | minimumNrMatchers 1 | | nrMatchers -1 | | nrScorers 2 | | scorerDocQueue ScorerDocQueue (id=260) | | similarity null | |---subScorers ArrayList<E> (id=116) | | elementData Object[10] (id=119) | |---[0] BooleanScorer2 (id=122) | | | coordinator BooleanScorer2$Coordinator (id=124) | | |---countingSumScorer BooleanScorer2$1(DisjunctionSumScorer) (id=125) | | | currentDoc 0 | | | currentScore 0.11146876 | | | doc -1 | | | lastDocScore NaN | | | lastScoredDoc -1 | | | minimumNrMatchers 1 | | | nrMatchers 1 | | | nrScorers 2 | | | scorerDocQueue ScorerDocQueue (id=270) | | | similarity null | | |---subScorers ArrayList<E> (id=126) | | | elementData Object[10] (id=138) | | |---[0] TermScorer (id=156) | | | doc -1 | | | doc 2 | | | docs int[32] (id=162) | | | freqs int[32] (id=163) | | | norms byte[4] (id=96) | | | pointer 0 | | | pointerMax 1 | | | scoreCache float[32] (id=164) | | | similarity DefaultSimilarity (id=64) | | | termDocs SegmentTermDocs (id=165) | | | //weight(contents:eat) | | | weight TermQuery$TermWeight (id=166) | | | weightValue 2.107161 | | |---[1] TermScorer (id=157) | | doc -1 | | doc 1 | | docs int[32] (id=171) | | freqs int[32] (id=172) | | norms byte[4] (id=96) | | pointer 1 | | pointerMax 3 | | scoreCache float[32] (id=173) | | similarity DefaultSimilarity (id=64) | | termDocs SegmentTermDocs (id=180) | | //weight(contents:cat^0.33333325) | | weight TermQuery$TermWeight (id=181) | | weightValue 0.22293752 | | size 2 | | this$0 BooleanScorer2 (id=122) | | doc -1 | | doc 0 | | minNrShouldMatch 0 | | optionalScorers ArrayList<E> (id=126) | | prohibitedScorers ArrayList<E> (id=127) | | requiredScorers ArrayList<E> (id=128) | | similarity BooleanQuery$1 (id=129) | |---[1] TermScorer (id=123) | doc -1 | doc 3 | docs int[32] (id=131) | freqs int[32] (id=132) | norms byte[4] (id=96) | pointer 0 | pointerMax 1 | scoreCache float[32] (id=133) | similarity DefaultSimilarity (id=64) | termDocs SegmentTermDocs (id=134) | //weight(contents:foods) | weight TermQuery$TermWeight (id=135) | weightValue 2.107161 | size 2 | this$0 BooleanScorer2 (id=81) | doc -1 | doc -1 | minNrShouldMatch 0 | optionalScorers ArrayList<E> (id=116) | prohibitedScorers ArrayList<E> (id=117) | requiredScorers ArrayList<E> (id=118) | similarity DefaultSimilarity (id=64) |---reqScorer BooleanScorer2$SingleMatchScorer (id=237) | doc -1 | lastDocScore NaN | lastScoredDoc -1 |---scorer BooleanScorer2 (id=82) | coordinator BooleanScorer2$Coordinator (id=183) |---countingSumScorer ReqExclScorer (id=184) |---exclDisi TermScorer (id=195) | doc -1 | doc -1 | docs int[32] (id=197) | freqs int[32] (id=198) | norms byte[4] (id=96) | pointer 0 | pointerMax 0 | scoreCache float[32] (id=199) | similarity DefaultSimilarity (id=64) | termDocs SegmentTermDocs (id=200) | //weight(contents:boy) | weight TermQuery$TermWeight (id=201) | weightValue 2.107161 |---reqScorer BooleanScorer2$2(ConjunctionScorer) (id=281) | coord 1.0 | doc -1 | lastDoc -1 | lastDocScore NaN | lastScoredDoc -1 |---scorers Scorer[1] (id=283) |---[0] ConstantScoreQuery$ConstantScorer (id=203) doc -1 doc -1 docIdSetIterator OpenBitSetIterator (id=206) similarity DefaultSimilarity (id=64) theScore 0.47844642 //ConstantScore(contents:apple*) this$0 ConstantScoreQuery (id=207) similarity DefaultSimilarity (id=64) this$0 BooleanScorer2 (id=82) val$requiredNrMatchers 1 similarity null minNrShouldMatch 0 optionalScorers ArrayList<E> (id=185) prohibitedScorers ArrayList<E> (id=186) requiredScorers ArrayList<E> (id=187) similarity DefaultSimilarity (id=64) similarity DefaultSimilarity (id=64) this$0 BooleanScorer2 (id=50) similarity null similarity null minNrShouldMatch 0 optionalScorers ArrayList<E> (id=55) prohibitedScorers ArrayList<E> (id=60) requiredScorers ArrayList<E> (id=63) similarity DefaultSimilarity (id=64) |

相关文章推荐
- Lucene学习总结之七:Lucene搜索过程解析(1)
- Lucene学习总结之七:Lucene搜索过程解析(1)
- Lucene学习总结之七:Lucene搜索过程解析(3)
- Lucene学习总结之七:Lucene搜索过程解析(2)
- Lucene学习总结之七:Lucene搜索过程解析(2)
- Lucene学习总结之七:Lucene搜索过程解析(5)
- Lucene学习总结之七:Lucene搜索过程解析(3)
- Lucene学习总结之七:Lucene搜索过程解析(3)
- Lucene学习总结之七:Lucene搜索过程解析(3)
- Lucene学习总结之七:Lucene搜索过程解析(6)
- Lucene学习总结之七:Lucene搜索过程解析(4)
- Lucene学习总结之七:Lucene搜索过程解析(4)
- Lucene学习总结之七:Lucene搜索过程解析(6)
- Lucene学习总结之七:Lucene搜索过程解析(5)
- Lucene学习总结之七:Lucene搜索过程解析(2)
- Lucene学习总结之七:Lucene搜索过程解析(6)
- Lucene学习总结之七:Lucene搜索过程解析(2)
- Lucene学习总结之七:Lucene搜索过程解析(3)
- Lucene学习总结之七:Lucene搜索过程解析
- Lucene学习总结之七:Lucene搜索过程解析(1)