堆排序
2010-01-02 12:42
148 查看
五. 堆排序
1、堆排序定义
n个关键字序列Kl,K2,…,Kn称为堆,当且仅当该序列满足如下性质(简称为堆性质):
(1)ki≤K2i且ki≤K2i+1或(2)Ki≥K2i且ki≥K2i+1(1≤i≤

)
若将此序列所存储的向量R[1..n]看做是一棵完全二叉树的存储结构,则堆实质上是满足如下性质的完全二叉树:树中任一非叶结点的关键字均不大于(或不小于)其左右孩子(若存在)结点的关键字。
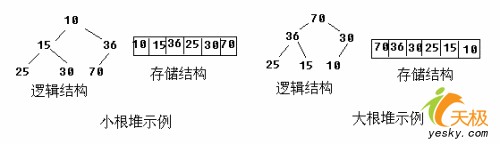
【例】关键字序列(10,15,56,25,30,70)和(70,56,30,25,15,10)分别满足堆性质(1)和(2),故它们均是堆,其对应的完全二叉树分别如小根堆示例和大根堆示例所示。

2、大根堆和小根堆
根结点(亦称为堆顶)的关键字是堆里所有结点关键字中最小者的堆称为小根堆。
根结点(亦称为堆顶)的关键字是堆里所有结点关键字中最大者,称为大根堆。
注意:
①堆中任一子树亦是堆。
②以上讨论的堆实际上是二叉堆(BinaryHeap),类似地可定义k叉堆。
3、堆排序特点
堆排序(HeapSort)是一树形选择排序。
堆排序的特点是:在排序过程中,将R[l..n]看成是一棵完全二叉树的顺序存储结构,利用完全二叉树中双亲结点和孩子结点之间的内在关系【参见二叉树的顺序存储结构】,在当前无序区中选择关键字最大(或最小)的记录。
4、堆排序与直接插入排序的区别
直接选择排序中,为了从R[1..n]中选出关键字最小的记录,必须进行n-1次比较,然后在R[2..n]中选出关键字最小的记录,又需要做n-2次比较。事实上,后面的n-2次比较中,有许多比较可能在前面的n-1次比较中已经做过,但由于前一趟排序时未保留这些比较结果,所以后一趟排序时又重复执行了这些比较操作。
堆排序可通过树形结构保存部分比较结果,可减少比较次数。
5、堆排序
堆排序利用了大根堆(或小根堆)堆顶记录的关键字最大(或最小)这一特征,使得在当前无序区中选取最大(或最小)关键字的记录变得简单。
(1)用大根堆排序的基本思想
①先将初始文件R[1..n]建成一个大根堆,此堆为初始的无序区
②再将关键字最大的记录R[1](即堆顶)和无序区的最后一个记录R
交换,由此得到新的无序区R[1..n-1]和有序区R
,且满足R[1..n-1].keys≤R
.key
③由于交换后新的根R[1]可能违反堆性质,故应将当前无序区R[1..n-1]调整为堆。然后再次将R[1..n-1]中关键字最大的记录R[1]和该区间的最后一个记录R[n-1]交换,由此得到新的无序区R[1..n-2]和有序区R[n-1..n],且仍满足关系R[1..n-2].keys≤R[n-1..n].keys,同样要将R[1..n-2]调整为堆。
……
直到无序区只有一个元素为止。
(2)大根堆排序算法的基本操作:
① 初始化操作:将R[1..n]构造为初始堆;
②每一趟排序的基本操作:将当前无序区的堆顶记录R[1]和该区间的最后一个记录交换,然后将新的无序区调整为堆(亦称重建堆)。
注意:
①只需做n-1趟排序,选出较大的n-1个关键字即可以使得文件递增有序。
②用小根堆排序与利用大根堆类似,只不过其排序结果是递减有序的。堆排序和直接选择排序相反:在任何时刻,堆排序中无序区总是在有序区之前,且有序区是在原向量的尾部由后往前逐步扩大至整个向量为止。
(3)堆排序的算法:
void HeapSort(SeqIAst R)
{//对R[1..n]进行堆排序,不妨用R[0]做暂存单元
inti;
BuildHeap(R); //将R[1-n]建成初始堆
for(i=n;i>1;i--){//对当前无序区R[1..i]进行堆排序,共做n-1趟。
R[0]=R[1];R[1]=R[i];R[i]=R[0];//将堆顶和堆中最后一个记录交换
Heapify(R,1,i-1);//将R[1..i-1]重新调整为堆,仅有R[1]可能违反堆性质
} //endfor
} //HeapSort
(4)BuildHeap和Heapify函数的实现
因为构造初始堆必须使用到调整堆的操作,先讨论Heapify的实现。
① Heapify函数思想方法
每趟排序开始前R[l..i]是以R[1]为根的堆,在R[1]与R[i]交换后,新的无序区R[1..i-1]中只有R[1]的值发生了变化,故除R[1]可能违反堆性质外,其余任何结点为根的子树均是堆。因此,当被调整区间是R[low..high]时,只须调整以R[low]为根的树即可。
"筛选法"调整堆
R[low]的左、右子树(若存在)均已是堆,这两棵子树的根R[2low]和R[2low+1]分别是各自子树中关键字最大的结点。若R[low].key不小于这两个孩子结点的关键字,则R[low]未违反堆性质,以R[low]为根的树已是堆,无须调整;否则必须将R[low]和它的两个孩子结点中关键字较大者进行交换,即R[low]与R[large](R[large].key=max(R[2low].key,R[2low+1].key))交换。交换后又可能使结点R[large]违反堆性质,同样由于该结点的两棵子树(若存在)仍然是堆,故可重复上述的调整过程,对以R[large]为根的树进行调整。此过程直至当前被调整的结点已满足堆性质,或者该结点已是叶子为止。上述过程就象过筛子一样,把较小的关键字逐层筛下去,而将较大的关键字逐层选上来。因此,有人将此方法称为"筛选法"。
②BuildHeap的实现
要将初始文件R[l..n]调整为一个大根堆,就必须将它所对应的完全二叉树中以每一结点为根的子树都调整为堆。
显然只有一个结点的树是堆,而在完全二叉树中,所有序号

的结点都是叶子,因此以这些结点为根的子树均已是堆。这样,我们只需依次将以序号为

,
-1,…,1的结点作为根的子树都调整为堆即可。
=================================================================================
5.1. 基本思想:
堆排序是一树形选择排序,在排序过程中,将R[1..N]看成是一颗完全二叉树的顺序存储结构,利用完全二叉树中双亲结点和孩子结点之间的内在关系来选择最小的元素。
5.2. 堆的定义:
N个元素的序列K1,K2,K3,...,Kn.称为堆,当且仅当该序列满足特性:Ki≤K2iKi ≤K2i+1(1≤ I≤ [N/2])。
堆实质上是满足如下性质的完全二叉树:树中任一非叶子结点的关键字均大于等于其孩子结点的关键字。例如序列10,15,56,25,30,70就是一个堆,它对应的完全二叉树如上图所示。这种堆中根结点(称为堆顶)的关键字最小,我们把它称为小根堆。反之,若完全二叉树中任一非叶子结点的关键字均大于等于其孩子的关键字,则称之为大根堆。
5.3. 排序过程:
堆排序正是利用小根堆(或大根堆)来选取当前无序区中关键字小(或最大)的记录实现排序的。我们不妨利用大根堆来排序。每一趟排序的基本操作是:将当前无序区调整为一个大根堆,选取关键字最大的堆顶记录,将它和无序区中的最后一个记录交换。这样,正好和直接选择排序相反,有序区是在原记录区的尾部形成并逐步向前扩大到整个记录区。
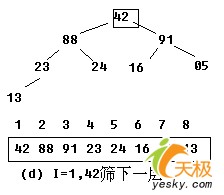
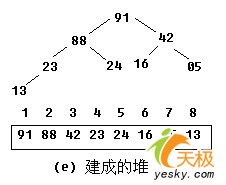
【示例】:对关键字序列42,13,91,23,24,16,05,88建堆。
1、堆排序定义
n个关键字序列Kl,K2,…,Kn称为堆,当且仅当该序列满足如下性质(简称为堆性质):
(1)ki≤K2i且ki≤K2i+1或(2)Ki≥K2i且ki≥K2i+1(1≤i≤
)
若将此序列所存储的向量R[1..n]看做是一棵完全二叉树的存储结构,则堆实质上是满足如下性质的完全二叉树:树中任一非叶结点的关键字均不大于(或不小于)其左右孩子(若存在)结点的关键字。
【例】关键字序列(10,15,56,25,30,70)和(70,56,30,25,15,10)分别满足堆性质(1)和(2),故它们均是堆,其对应的完全二叉树分别如小根堆示例和大根堆示例所示。
2、大根堆和小根堆
根结点(亦称为堆顶)的关键字是堆里所有结点关键字中最小者的堆称为小根堆。
根结点(亦称为堆顶)的关键字是堆里所有结点关键字中最大者,称为大根堆。
注意:
①堆中任一子树亦是堆。
②以上讨论的堆实际上是二叉堆(BinaryHeap),类似地可定义k叉堆。
3、堆排序特点
堆排序(HeapSort)是一树形选择排序。
堆排序的特点是:在排序过程中,将R[l..n]看成是一棵完全二叉树的顺序存储结构,利用完全二叉树中双亲结点和孩子结点之间的内在关系【参见二叉树的顺序存储结构】,在当前无序区中选择关键字最大(或最小)的记录。
4、堆排序与直接插入排序的区别
直接选择排序中,为了从R[1..n]中选出关键字最小的记录,必须进行n-1次比较,然后在R[2..n]中选出关键字最小的记录,又需要做n-2次比较。事实上,后面的n-2次比较中,有许多比较可能在前面的n-1次比较中已经做过,但由于前一趟排序时未保留这些比较结果,所以后一趟排序时又重复执行了这些比较操作。
堆排序可通过树形结构保存部分比较结果,可减少比较次数。
5、堆排序
堆排序利用了大根堆(或小根堆)堆顶记录的关键字最大(或最小)这一特征,使得在当前无序区中选取最大(或最小)关键字的记录变得简单。
(1)用大根堆排序的基本思想
①先将初始文件R[1..n]建成一个大根堆,此堆为初始的无序区
②再将关键字最大的记录R[1](即堆顶)和无序区的最后一个记录R
交换,由此得到新的无序区R[1..n-1]和有序区R
,且满足R[1..n-1].keys≤R
.key
③由于交换后新的根R[1]可能违反堆性质,故应将当前无序区R[1..n-1]调整为堆。然后再次将R[1..n-1]中关键字最大的记录R[1]和该区间的最后一个记录R[n-1]交换,由此得到新的无序区R[1..n-2]和有序区R[n-1..n],且仍满足关系R[1..n-2].keys≤R[n-1..n].keys,同样要将R[1..n-2]调整为堆。
……
直到无序区只有一个元素为止。
(2)大根堆排序算法的基本操作:
① 初始化操作:将R[1..n]构造为初始堆;
②每一趟排序的基本操作:将当前无序区的堆顶记录R[1]和该区间的最后一个记录交换,然后将新的无序区调整为堆(亦称重建堆)。
注意:
①只需做n-1趟排序,选出较大的n-1个关键字即可以使得文件递增有序。
②用小根堆排序与利用大根堆类似,只不过其排序结果是递减有序的。堆排序和直接选择排序相反:在任何时刻,堆排序中无序区总是在有序区之前,且有序区是在原向量的尾部由后往前逐步扩大至整个向量为止。
(3)堆排序的算法:
void HeapSort(SeqIAst R)
{//对R[1..n]进行堆排序,不妨用R[0]做暂存单元
inti;
BuildHeap(R); //将R[1-n]建成初始堆
for(i=n;i>1;i--){//对当前无序区R[1..i]进行堆排序,共做n-1趟。
R[0]=R[1];R[1]=R[i];R[i]=R[0];//将堆顶和堆中最后一个记录交换
Heapify(R,1,i-1);//将R[1..i-1]重新调整为堆,仅有R[1]可能违反堆性质
} //endfor
} //HeapSort
(4)BuildHeap和Heapify函数的实现
因为构造初始堆必须使用到调整堆的操作,先讨论Heapify的实现。
① Heapify函数思想方法
每趟排序开始前R[l..i]是以R[1]为根的堆,在R[1]与R[i]交换后,新的无序区R[1..i-1]中只有R[1]的值发生了变化,故除R[1]可能违反堆性质外,其余任何结点为根的子树均是堆。因此,当被调整区间是R[low..high]时,只须调整以R[low]为根的树即可。
"筛选法"调整堆
R[low]的左、右子树(若存在)均已是堆,这两棵子树的根R[2low]和R[2low+1]分别是各自子树中关键字最大的结点。若R[low].key不小于这两个孩子结点的关键字,则R[low]未违反堆性质,以R[low]为根的树已是堆,无须调整;否则必须将R[low]和它的两个孩子结点中关键字较大者进行交换,即R[low]与R[large](R[large].key=max(R[2low].key,R[2low+1].key))交换。交换后又可能使结点R[large]违反堆性质,同样由于该结点的两棵子树(若存在)仍然是堆,故可重复上述的调整过程,对以R[large]为根的树进行调整。此过程直至当前被调整的结点已满足堆性质,或者该结点已是叶子为止。上述过程就象过筛子一样,把较小的关键字逐层筛下去,而将较大的关键字逐层选上来。因此,有人将此方法称为"筛选法"。
②BuildHeap的实现
要将初始文件R[l..n]调整为一个大根堆,就必须将它所对应的完全二叉树中以每一结点为根的子树都调整为堆。
显然只有一个结点的树是堆,而在完全二叉树中,所有序号
的结点都是叶子,因此以这些结点为根的子树均已是堆。这样,我们只需依次将以序号为
,
-1,…,1的结点作为根的子树都调整为堆即可。
=================================================================================
5.1. 基本思想:
堆排序是一树形选择排序,在排序过程中,将R[1..N]看成是一颗完全二叉树的顺序存储结构,利用完全二叉树中双亲结点和孩子结点之间的内在关系来选择最小的元素。
5.2. 堆的定义:
N个元素的序列K1,K2,K3,...,Kn.称为堆,当且仅当该序列满足特性:Ki≤K2iKi ≤K2i+1(1≤ I≤ [N/2])。
 |
5.3. 排序过程:
堆排序正是利用小根堆(或大根堆)来选取当前无序区中关键字小(或最大)的记录实现排序的。我们不妨利用大根堆来排序。每一趟排序的基本操作是:将当前无序区调整为一个大根堆,选取关键字最大的堆顶记录,将它和无序区中的最后一个记录交换。这样,正好和直接选择排序相反,有序区是在原记录区的尾部形成并逐步向前扩大到整个记录区。
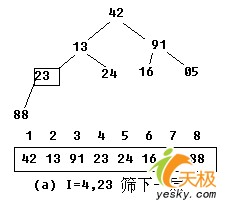
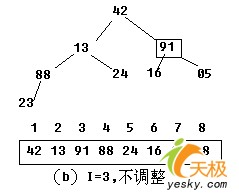
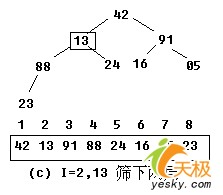
【示例】:对关键字序列42,13,91,23,24,16,05,88建堆。
     |
