大型网站架构:Flickr网站体系结构分析(转)
2009-11-14 22:58
330 查看
Flickr是我个人喜爱的网站之一,也是互联网上最主要的图片共享网站。Flickr网站后台有许多非常复杂的问题需要处理,它们需要处理海量的新增的内容,管理大批的用户,不断保持新的功能特征,与此同时,还要提供一流的性能。它们是如何做到的呢?
Flickr网站的网址是:http://www.flickr.com/
参考文献
Flickr and PHP(一个早期的文档)
LAMP容量规划
Flickr联盟:Flickr网站体系结构指南
来自Flickr网站工程师Cal Henderson所写的文章:如何构建可伸缩web站点
Cal Henderson的谈话记录,在许多幻灯片中陈述对一些web技术的看法
平台
PHP
MySQL
Shards
Memcached高速缓冲层
Squid反向代理(reverse-proxy)
Linux(红帽子)操作系统
Smarty模板
Perl脚本语言
使用PEAR进行XML和Email分析
ImageMagick图像处理
Java节点服务程序
Apache服务器
SystemImager部署
Ganglia分布式监控系统
Subcon存储系统配置文件
使用Cvsup来分布和更新文件集
下面附上Flicker站点系统构架
1
统计情况
每天超过4百万请求
Squid高速缓存中大约35M的照片
Squid RAM中大约2M照片
memcached每秒38k个请求(12M)
2 PB原始数据存储器(在星期天消耗大约1.5TB)
每天增加400,000张照片以上
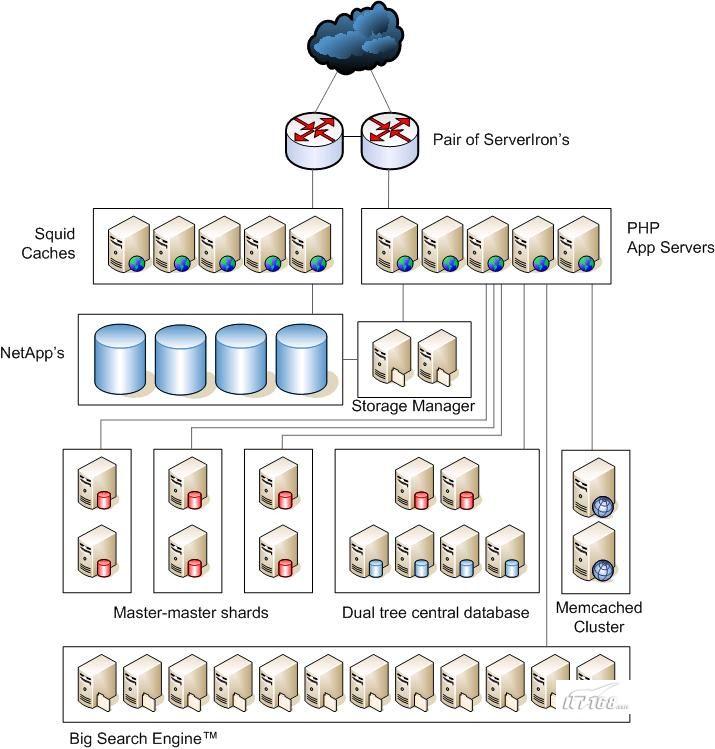
系统结构
关于Flickr站点体系结构的一组图像化的展示,如图一所示,更多关于Flickr站点体系结构的描述,你可以在这个页面查到。进行简单的描述就是:
—一对ServerIron
—Squid Caches
—Net应用程序
—PHP应用程序服务器
—存储管理器
—Master-master碎片
—双树形中心数据库
—Memcached Cluster
—大型搜索引擎
双重树形系统结构是一项对MySQL常规配置,通过增加masters,而不是环形体系结构来增加伸缩性。比起需要两倍硬件的master-master安装来说,这种方式你只需要较少的硬件,因此节约了提高网站伸缩性的费用。
系统结构中的中心数据库包括想用户表这样的数据,这个表包括主要的用户信息,主键,和指向用户相关的数据。
对于静态内容使用的专门服务器
研究如何支持Unicode
不要使用共用的结构系统
所有的东西(除了照片)都要存在数据库中
创建一个搜索农场(search farm),复制部分需要进行搜索的数据库
使用横尺度,保证更多所必需的的机器
分析每封邮件,处理用户通过邮件发送的图片。
早期曾经遭受Master-Slave延迟。太多负载会有出现单点故障
保证网站一直开通,不断修复数据等等,不要让网站关闭
进行好的容量规划。获取更多的信息查看文章前面部分的参考文献。
使用统一的方法以便为了以后进行伸缩扩展
碎片:我的一些数据存储在我拥有的磁盘碎片上,但是进行对你的一些评论,存储在你的碎片空间上。如当你对其它人的博客进行评论的时候,这种情况就会发生。
Global Ring:像DNS,你需要知道页面往哪里链接,谁来控制方向。每一个页面的浏览,都要计算当前你的数据在哪里。
PHP 逻辑来连接那些碎片空间,保持数据的一致性(带注释的10行代码)
碎片
—主要数据库的一个小部分
—活动的Master-Master Ring Replication:MySQL 4.1中的小缺点,而在Master-Master—确是光环。ID自动增加能保持有效。
对于新的用户,碎片的分配是一个随机数。
迁移是时不时要发生的,因此你可以删除一些用户。当有很多的照片的时候,你需要均衡。192,000张照片,700,000标签的迁移需要大约3-4分钟。迁移时人工完成的。
移出Cache中的照片拥有帐户,给他们分配一个碎片空间地址。从cache中移出我的信息,将它们加到我的碎片地址中去。
如果当前主机宕机,访问列表中的下一个主句,如果所有的主机宕机,显示一个错误页面。他们不会使用持久性连接。每一个页面加载,都要测试连接。
每个用户的读写都放在一个碎片中。不存在什么复制延迟的事情。
平均请求每个页面,用到 27-35 SQL语句。API访问数据库都是实时的。完成实时处理需求
每秒超过3600个请求,在容量极限范围之内。在高峰期爆发时,会达到两个36000每秒的请求数。
每个碎片能持有400K以上的数据
许多数据存储了两次。举个例子,一个评论关系到评论者和被评论者。评论存储在什么地方?是不是在两个地方都存储了?事务处理机制用来阻止同步数据:打开事务1,写入一些命令,打开事务2,写入一些命令,提交第一个事物后,如果第一个提交,再提交第二个事务。但是这还有存在失败的可能性,可能提交了两次。
硬件:
- EMT64 w/RHEL4, 16GB RAM
- 6-disk 15K RPM RAID-10.
- 2U 逻辑单元。每个碎片空间存储~120GB数据
备份过程:
每天晚上对整个数据库集群进行快照
当在进行复制备份文件时,在复制文件存储中一次写入或者删除几个大的备份文件会损害性能。对图片存储文件进行这种操作时非常坏的主意。
虽然将你所有的数据进行备份很多天使非常耗费资源的,但是这么做是值得的。保持错列的备份时很有用的,特别是当你在几天后发现出现问题的时候。你可以做1,2,10,30天的备份。
图片是存储在文件夹中。当你上传的时候,会处理图片,供给你不同的尺寸选择。元数据和指向文件夹的路径会保存在数据库中。
每个shard max_connections = 40的连接数,或者每个server & shard加起来等于800的连接数。线程高速缓冲器设置为45,因为你不会有超过45个用户同时在活动。
标签
对于传统的关系型数据库管理系统设计,标签是不太适合的。方向规格化或者重型高速缓冲器是唯一的方法来生成标签,一毫秒能产生上百万的标签。
未来的方向:
使用实时BCP,能够运行的更快,因此所有的数据中心一直都能够接受写入信息。所有的资源都是使用中的,没有一个将会在空闲。
学到的经验:
不仅仅把你的应用程序看作一个web应用程序。你将会有使用到REST APIs,、SOAP APIs、 RSS feeds、 Atom feeds等;
无界限化。无界限化能够让你的系统更加鲁棒,毫无顾虑的进行升级。
高速缓存。尽量高速缓存和RAM来响应每个请求
抽象化。在数据库,业务逻辑,页面逻辑,页面标签,和表现层之间创建很清晰的抽象层次。在迭代开发中将会很灵活好用。
分层。分层设计能够让开发者处理业务逻辑,而设计者能够进行用户体验页面设计。设计者还能在需要时请求页面逻辑。这两层之间有一个很好的协商。
释放频率。每30分钟一次。
忽略微小性能改善,不成熟的优化将灾难的根源。
应用程序测试。要能轻松的在你的应用程序体系结构机制(如设置标签,负载均衡等)中插入或者移除新的硬件。
忘记基准。对于获得容量的一般观念设置一个基准是很好的,但是,对于规划来说,设置基准并不好,人工测试会提供一个测试结果,对真实情况进行一个测试会是一个更好的方法。
确定最高限额
每个服务器能够达到的最大极限服务是多少?
每个服务器接近到最大极限有多近?这个趋势又是怎么样的?MySQL(disk IO)情况又是怎样的?SQUID (disk IO 或者 CPU )的情况又是怎样的呢?memcached(CPU 或者 network )情况又是如何的?
对用户的使用规律要敏感
与上一年的第一个工作日相比,Flickr网站在今年的第一个工作日会增加20-40%的负载每周日平均要比这一周其它天增加40-50%负载 。对用户指数级的增张要求敏感。更多的用户意味着更多的内容,更多的内容意味着更多的连接,更多的连接意味着更多的请求。
负载高峰备用。要有能够处理高峰负载的计划
原文的url : http://highscalability.com/flickr-architecture
Flickr网站的网址是:http://www.flickr.com/
参考文献
Flickr and PHP(一个早期的文档)
LAMP容量规划
Flickr联盟:Flickr网站体系结构指南
来自Flickr网站工程师Cal Henderson所写的文章:如何构建可伸缩web站点
Cal Henderson的谈话记录,在许多幻灯片中陈述对一些web技术的看法
平台
PHP
MySQL
Shards
Memcached高速缓冲层
Squid反向代理(reverse-proxy)
Linux(红帽子)操作系统
Smarty模板
Perl脚本语言
使用PEAR进行XML和Email分析
ImageMagick图像处理
Java节点服务程序
Apache服务器
SystemImager部署
Ganglia分布式监控系统
Subcon存储系统配置文件
使用Cvsup来分布和更新文件集
下面附上Flicker站点系统构架
1
统计情况
每天超过4百万请求
Squid高速缓存中大约35M的照片
Squid RAM中大约2M照片
memcached每秒38k个请求(12M)
2 PB原始数据存储器(在星期天消耗大约1.5TB)
每天增加400,000张照片以上
系统结构
关于Flickr站点体系结构的一组图像化的展示,如图一所示,更多关于Flickr站点体系结构的描述,你可以在这个页面查到。进行简单的描述就是:
—一对ServerIron
—Squid Caches
—Net应用程序
—PHP应用程序服务器
—存储管理器
—Master-master碎片
—双树形中心数据库
—Memcached Cluster
—大型搜索引擎
双重树形系统结构是一项对MySQL常规配置,通过增加masters,而不是环形体系结构来增加伸缩性。比起需要两倍硬件的master-master安装来说,这种方式你只需要较少的硬件,因此节约了提高网站伸缩性的费用。
系统结构中的中心数据库包括想用户表这样的数据,这个表包括主要的用户信息,主键,和指向用户相关的数据。
对于静态内容使用的专门服务器
研究如何支持Unicode
不要使用共用的结构系统
所有的东西(除了照片)都要存在数据库中
创建一个搜索农场(search farm),复制部分需要进行搜索的数据库
使用横尺度,保证更多所必需的的机器
分析每封邮件,处理用户通过邮件发送的图片。
早期曾经遭受Master-Slave延迟。太多负载会有出现单点故障
保证网站一直开通,不断修复数据等等,不要让网站关闭
进行好的容量规划。获取更多的信息查看文章前面部分的参考文献。
使用统一的方法以便为了以后进行伸缩扩展
碎片:我的一些数据存储在我拥有的磁盘碎片上,但是进行对你的一些评论,存储在你的碎片空间上。如当你对其它人的博客进行评论的时候,这种情况就会发生。
Global Ring:像DNS,你需要知道页面往哪里链接,谁来控制方向。每一个页面的浏览,都要计算当前你的数据在哪里。
PHP 逻辑来连接那些碎片空间,保持数据的一致性(带注释的10行代码)
碎片
—主要数据库的一个小部分
—活动的Master-Master Ring Replication:MySQL 4.1中的小缺点,而在Master-Master—确是光环。ID自动增加能保持有效。
对于新的用户,碎片的分配是一个随机数。
迁移是时不时要发生的,因此你可以删除一些用户。当有很多的照片的时候,你需要均衡。192,000张照片,700,000标签的迁移需要大约3-4分钟。迁移时人工完成的。
移出Cache中的照片拥有帐户,给他们分配一个碎片空间地址。从cache中移出我的信息,将它们加到我的碎片地址中去。
如果当前主机宕机,访问列表中的下一个主句,如果所有的主机宕机,显示一个错误页面。他们不会使用持久性连接。每一个页面加载,都要测试连接。
每个用户的读写都放在一个碎片中。不存在什么复制延迟的事情。
平均请求每个页面,用到 27-35 SQL语句。API访问数据库都是实时的。完成实时处理需求
每秒超过3600个请求,在容量极限范围之内。在高峰期爆发时,会达到两个36000每秒的请求数。
每个碎片能持有400K以上的数据
许多数据存储了两次。举个例子,一个评论关系到评论者和被评论者。评论存储在什么地方?是不是在两个地方都存储了?事务处理机制用来阻止同步数据:打开事务1,写入一些命令,打开事务2,写入一些命令,提交第一个事物后,如果第一个提交,再提交第二个事务。但是这还有存在失败的可能性,可能提交了两次。
硬件:
- EMT64 w/RHEL4, 16GB RAM
- 6-disk 15K RPM RAID-10.
- 2U 逻辑单元。每个碎片空间存储~120GB数据
备份过程:
每天晚上对整个数据库集群进行快照
当在进行复制备份文件时,在复制文件存储中一次写入或者删除几个大的备份文件会损害性能。对图片存储文件进行这种操作时非常坏的主意。
虽然将你所有的数据进行备份很多天使非常耗费资源的,但是这么做是值得的。保持错列的备份时很有用的,特别是当你在几天后发现出现问题的时候。你可以做1,2,10,30天的备份。
图片是存储在文件夹中。当你上传的时候,会处理图片,供给你不同的尺寸选择。元数据和指向文件夹的路径会保存在数据库中。
每个shard max_connections = 40的连接数,或者每个server & shard加起来等于800的连接数。线程高速缓冲器设置为45,因为你不会有超过45个用户同时在活动。
标签
对于传统的关系型数据库管理系统设计,标签是不太适合的。方向规格化或者重型高速缓冲器是唯一的方法来生成标签,一毫秒能产生上百万的标签。
未来的方向:
使用实时BCP,能够运行的更快,因此所有的数据中心一直都能够接受写入信息。所有的资源都是使用中的,没有一个将会在空闲。
学到的经验:
不仅仅把你的应用程序看作一个web应用程序。你将会有使用到REST APIs,、SOAP APIs、 RSS feeds、 Atom feeds等;
无界限化。无界限化能够让你的系统更加鲁棒,毫无顾虑的进行升级。
高速缓存。尽量高速缓存和RAM来响应每个请求
抽象化。在数据库,业务逻辑,页面逻辑,页面标签,和表现层之间创建很清晰的抽象层次。在迭代开发中将会很灵活好用。
分层。分层设计能够让开发者处理业务逻辑,而设计者能够进行用户体验页面设计。设计者还能在需要时请求页面逻辑。这两层之间有一个很好的协商。
释放频率。每30分钟一次。
忽略微小性能改善,不成熟的优化将灾难的根源。
应用程序测试。要能轻松的在你的应用程序体系结构机制(如设置标签,负载均衡等)中插入或者移除新的硬件。
忘记基准。对于获得容量的一般观念设置一个基准是很好的,但是,对于规划来说,设置基准并不好,人工测试会提供一个测试结果,对真实情况进行一个测试会是一个更好的方法。
确定最高限额
每个服务器能够达到的最大极限服务是多少?
每个服务器接近到最大极限有多近?这个趋势又是怎么样的?MySQL(disk IO)情况又是怎样的?SQUID (disk IO 或者 CPU )的情况又是怎样的呢?memcached(CPU 或者 network )情况又是如何的?
对用户的使用规律要敏感
与上一年的第一个工作日相比,Flickr网站在今年的第一个工作日会增加20-40%的负载每周日平均要比这一周其它天增加40-50%负载 。对用户指数级的增张要求敏感。更多的用户意味着更多的内容,更多的内容意味着更多的连接,更多的连接意味着更多的请求。
负载高峰备用。要有能够处理高峰负载的计划
原文的url : http://highscalability.com/flickr-architecture
