www.javaei.com网站建设手记——(4)实现细节
2009-06-25 16:27
771 查看
Javaei的发布系统的主要功能是录入、预览和发布,在实现上,其实是个很小很小的增删改查,本微不足道,但我觉得技术不是最重要的事,因为我的网站目前不需要太高深的技术。但还是要说说这个发布系统的一些实现细节,不为别的,只为给自己做个记录,给网站做个记录。
在上一篇已经说到过,发布系统的关键在于生成html并替换动态连接为静态的html连接,我想到的实现方式有两种,在客户端用程序发起请求,第一种方式是解析响应的html,对要处理的超级链接(也就是<a href=””>)做处理,第二种方式是在开发的时候定制一个标签,把要处理的超级链接写在定制标签里,服务器在解析标签的时候对超级链接进行处理。对超级链接进行处理有两件事,一件事就是生成该链接的html文件,一件事是替换原来的连接为指向生成的html文件的静态链接。我采用的是第二种方式。第一种方式更适合对已有的网站进行静态化。不管是哪种方式,都面临着一个相同的问题,那就是在处理超级链接的时候,超级链接指向的页面同样包含着要处理的超级链接,而且还会有与正在处理超级链接相同的超级链接,这是个递归。其实这也是个简单的爬虫,已经爬过的就不能再爬。解决这个问题其实很简单,对已经处理过的超级链接做个hash缓存就可以了。
要处理的超级链接生成的html方式可能不一样,简单来说就是生成的html文件的路径和生成的html连接的uri可能不相同,所以需要把这种不同从标签处理器里分出来,标签不能太复杂,标签的主要作用应该是接受标签的属性值作为参数和输出<a>标签和href属性的值及其他属性的值。而生成html文件和html路径(也作为uri)应该由一个独立出来的处理器来完成。下面是相关的类结构图。
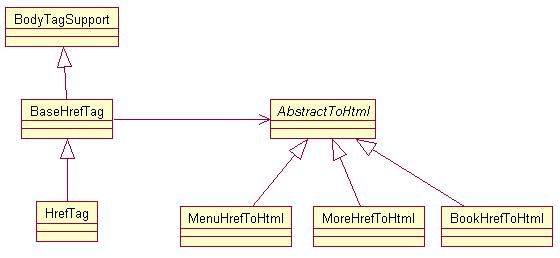
BaseHrefTag的部分代码如下
Java代码
public abstract class BaseHrefTag extends BodyTagSupport {
private String href;//
private String tohtml;//是否需要处理,预览时为false
private String classname;//css class name
private String target;//target
private String root;//生成html链接时是否加上host
public int doStartTag() throws JspException {
// TODO Auto-generated method stub
String hrefvalue = null;
// System.out.println("getHref() "+getHref());
if(getHrefCache().containsKey(getHref())){
hrefvalue = getHrefCache().get(getHref());
}else{
hrefvalue = getHref();
if(isTohtml()){
hrefvalue=getToHtml().getHtmlHref(hrefvalue);
hrefvalue = addRoot(hrefvalue);
getHrefCache().put(getHref(), hrefvalue);
try {
hrefvalue = getToHtml().exportToHtmlFile(getHref());
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
hrefvalue = addRoot(hrefvalue);
getHrefCache().put(getHref(), hrefvalue);
}
}
String href ="<a href="""+hrefvalue+""" ";
if(getTarget() != null){
href = href + "target = """+getTarget()+""" ";
}
if(getClassname() != null){
href = href + "class="""+getClassname()+"""";
}
href = href + ">";
printToPage(href);
return (BodyTagSupport.EVAL_BODY_TAG);
}
}
AbstractToHtml的部分代码如下
Java代码
public abstract class AbstractToHtml { //有子类实现,构造生成的html文件的名称和路径 protected abstract String[] createDirAndFile(String href); public String exportToHtmlFile(String href)throws Exception{ //发起get方式请求 URL mu = new URL(ClientParam.root+appendToHref(href)); URLConnection conn = mu.openConnection(); conn.connect(); String[] dirfile = createDirAndFile(href); writeToFile(ClientParam.basicdir+dirfile[0],dirfile[1],conn); return dirfile[0]+dirfile[1]; } //读取服务器响应的内容输出到html文件 private void writeToFile(String dirname,String filename,URLConnection conn)throws Exception{ deleteOldFile(dirname,filename); PrintStream ps=new PrintStream(dirname+filename,ClientParam.charset); BufferedReader br = new BufferedReader(new InputStreamReader(conn.getInputStream(),ClientParam.charset)); String s; while((s=br.readLine())!=null){ ps.println(s); } br.close(); ps.close(); } }
页面的<iframe src="">src属性又是也需要处理,采用同样的方法,定义SrcTag。
在开发的时候,非常喜欢用jstl和自己定义的标签,其实人家的模板技术也大致如此。
文章转载自http://summeryhrb.javaeye.com/admin/blogs/415054
在上一篇已经说到过,发布系统的关键在于生成html并替换动态连接为静态的html连接,我想到的实现方式有两种,在客户端用程序发起请求,第一种方式是解析响应的html,对要处理的超级链接(也就是<a href=””>)做处理,第二种方式是在开发的时候定制一个标签,把要处理的超级链接写在定制标签里,服务器在解析标签的时候对超级链接进行处理。对超级链接进行处理有两件事,一件事就是生成该链接的html文件,一件事是替换原来的连接为指向生成的html文件的静态链接。我采用的是第二种方式。第一种方式更适合对已有的网站进行静态化。不管是哪种方式,都面临着一个相同的问题,那就是在处理超级链接的时候,超级链接指向的页面同样包含着要处理的超级链接,而且还会有与正在处理超级链接相同的超级链接,这是个递归。其实这也是个简单的爬虫,已经爬过的就不能再爬。解决这个问题其实很简单,对已经处理过的超级链接做个hash缓存就可以了。
要处理的超级链接生成的html方式可能不一样,简单来说就是生成的html文件的路径和生成的html连接的uri可能不相同,所以需要把这种不同从标签处理器里分出来,标签不能太复杂,标签的主要作用应该是接受标签的属性值作为参数和输出<a>标签和href属性的值及其他属性的值。而生成html文件和html路径(也作为uri)应该由一个独立出来的处理器来完成。下面是相关的类结构图。
BaseHrefTag的部分代码如下
Java代码
public abstract class BaseHrefTag extends BodyTagSupport {
private String href;//
private String tohtml;//是否需要处理,预览时为false
private String classname;//css class name
private String target;//target
private String root;//生成html链接时是否加上host
public int doStartTag() throws JspException {
// TODO Auto-generated method stub
String hrefvalue = null;
// System.out.println("getHref() "+getHref());
if(getHrefCache().containsKey(getHref())){
hrefvalue = getHrefCache().get(getHref());
}else{
hrefvalue = getHref();
if(isTohtml()){
hrefvalue=getToHtml().getHtmlHref(hrefvalue);
hrefvalue = addRoot(hrefvalue);
getHrefCache().put(getHref(), hrefvalue);
try {
hrefvalue = getToHtml().exportToHtmlFile(getHref());
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
hrefvalue = addRoot(hrefvalue);
getHrefCache().put(getHref(), hrefvalue);
}
}
String href ="<a href="""+hrefvalue+""" ";
if(getTarget() != null){
href = href + "target = """+getTarget()+""" ";
}
if(getClassname() != null){
href = href + "class="""+getClassname()+"""";
}
href = href + ">";
printToPage(href);
return (BodyTagSupport.EVAL_BODY_TAG);
}
}
public abstract class BaseHrefTag extends BodyTagSupport {
private String href;//
private String tohtml;//是否需要处理,预览时为false
private String classname;//css class name
private String target;//target
private String root;//生成html链接时是否加上host
public int doStartTag() throws JspException {
// TODO Auto-generated method stub
String hrefvalue = null;
// System.out.println("getHref() "+getHref());
if(getHrefCache().containsKey(getHref())){
hrefvalue = getHrefCache().get(getHref());
}else{
hrefvalue = getHref();
if(isTohtml()){
hrefvalue=getToHtml().getHtmlHref(hrefvalue);
hrefvalue = addRoot(hrefvalue);
getHrefCache().put(getHref(), hrefvalue);
try {
hrefvalue = getToHtml().exportToHtmlFile(getHref());
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
hrefvalue = addRoot(hrefvalue);
getHrefCache().put(getHref(), hrefvalue);
}
}
String href ="<a href="""+hrefvalue+""" ";
if(getTarget() != null){
href = href + "target = """+getTarget()+""" ";
}
if(getClassname() != null){
href = href + "class="""+getClassname()+"""";
}
href = href + ">";
printToPage(href);
return (BodyTagSupport.EVAL_BODY_TAG);
}
}AbstractToHtml的部分代码如下
Java代码
public abstract class AbstractToHtml { //有子类实现,构造生成的html文件的名称和路径 protected abstract String[] createDirAndFile(String href); public String exportToHtmlFile(String href)throws Exception{ //发起get方式请求 URL mu = new URL(ClientParam.root+appendToHref(href)); URLConnection conn = mu.openConnection(); conn.connect(); String[] dirfile = createDirAndFile(href); writeToFile(ClientParam.basicdir+dirfile[0],dirfile[1],conn); return dirfile[0]+dirfile[1]; } //读取服务器响应的内容输出到html文件 private void writeToFile(String dirname,String filename,URLConnection conn)throws Exception{ deleteOldFile(dirname,filename); PrintStream ps=new PrintStream(dirname+filename,ClientParam.charset); BufferedReader br = new BufferedReader(new InputStreamReader(conn.getInputStream(),ClientParam.charset)); String s; while((s=br.readLine())!=null){ ps.println(s); } br.close(); ps.close(); } }
public abstract class AbstractToHtml {
//有子类实现,构造生成的html文件的名称和路径
protected abstract String[] createDirAndFile(String href);
public String exportToHtmlFile(String href)throws Exception{
//发起get方式请求
URL mu = new URL(ClientParam.root+appendToHref(href));
URLConnection conn = mu.openConnection();
conn.connect();
String[] dirfile = createDirAndFile(href);
writeToFile(ClientParam.basicdir+dirfile[0],dirfile[1],conn);
return dirfile[0]+dirfile[1];
}
//读取服务器响应的内容输出到html文件
private void writeToFile(String dirname,String filename,URLConnection conn)throws Exception{
deleteOldFile(dirname,filename);
PrintStream ps=new PrintStream(dirname+filename,ClientParam.charset);
BufferedReader br = new BufferedReader(new InputStreamReader(conn.getInputStream(),ClientParam.charset));
String s;
while((s=br.readLine())!=null){
ps.println(s);
}
br.close();
ps.close();
}
}页面的<iframe src="">src属性又是也需要处理,采用同样的方法,定义SrcTag。
在开发的时候,非常喜欢用jstl和自己定义的标签,其实人家的模板技术也大致如此。
文章转载自http://summeryhrb.javaeye.com/admin/blogs/415054

相关文章推荐
- www.javaei.com网站建设手记——(3)实现方案
- www.javaei.com网站建设手记——(16)h2p被java开源大全收录为开源项目
- www.javaei.com网站建设手记——(13)推出h2p(首创)
- www.javaei.com网站建设手记——(9)增加快捷阅读
- www.javaei.com网站建设手记——(10)增加HTA下载
- www.javaei.com网站建设手记——(2)界面设计
- www.javaei.com网站建设手记——(8)简单的宣传
- www.javaei.com网站建设手记——(15)h2p被开源中国收录为开源项目
- www.javaei.com网站建设手记——(11)增加rss订阅
- www.javaei.com网站建设手记——(12)增加带树形菜单优秀在线连载
- www.javaei.com网站建设手记——(1)构想由来
- www.javaei.com网站建设手记——(5)购买虚拟主机和域名
- www.javaei.com网站建设手记——(14) 诚邀合作
- www.javaei.com网站建设手记——(6)意想不到的Bug
- www.javaei.com网站建设手记——(7)javaei的seo
- Android模拟器访问google网站获取天气信息时,出现 java.net.UnknownHostException: www.google.com 错误
- java+oracle+web(第七天) tomcat介绍 (四)实现https://www.igo.com 直接访问我的主页
- 使用Java爬虫当数据后台的资源网站搭建(已建成www.ciliyunsou.com)
- 知名网站的技术实现(http://www.kuqin.com/web/20130703/334631.html)
- 不错的Ajax的实现网站 http://www.zapatec.com/