聚类基本数学模型
2009-04-11 16:23
169 查看
聚类方法是一类用途非常广泛的算法,聚类包含很多各式各样的算法。所有这些算法都有它的基本数学模型。本文就简单介绍一下聚类的基本数学模型。了解了基本数学模型就了解了聚类最本质的原理。无论是学习算法还是自己开发新的算法,学习基本数学模型都是很有帮助的。本文的目的一方面是介绍数学模型,另一方面也算是自己学习内容的一个记录吧。
假设X={x1,x2,…,xn}是待分析的对象全体,也可称为论域或样本集合。X中的每个对象(也可称为样本)

常用有限个参数值来刻画(这里的参数值也可称为样本的属性值),每个参数值用于刻画xi的某个特征(属性)。于是对象xi就伴随着一个向量P(xi)=(xi1,xi2,…,xim), 其中xij()是xi在j个特征上的值,P(xi)称为xi的特征向量或模式向量(也可理解为用于定义聚类中心的向量,不过这样的理解并不严谨,因为并非每种聚类方法都是以类似于KMEANS那样的中心点来定义簇的,所以在数据模型中以P(xi)来表示在意义上更加抽象)。聚类分析就是分析论域或样本集合X中的n个样本所对应的模式矢量间的空间距离及分散情况,按照各样本间的距离远近或相似程度把x1, x2,…, xn划分成k个不相交的模式子集X1, X2, …, Xk,并要求满足下列条件:

样本
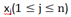
对子集
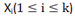
的隶属度关系可用隶属度函数表示为:
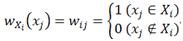
其中,隶属度函数必须满足条件
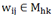
。也就是说:
要求每一个样本能且只能隶属于某一类。
要求每个子类都是非空的。
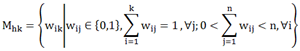
在这个表达式中
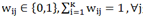
是用于约束"每一个样本能且只能属于某一类";
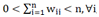
用于约束"每个子类都是非空的"。将以上定义的隶属度函数wij扩展到[0,1]这个区间即为模糊聚类的定义。模糊聚类又称为软聚类,相应的非模糊聚类也可称为硬聚类。
假设X={x1,x2,…,xn}是待分析的对象全体,也可称为论域或样本集合。X中的每个对象(也可称为样本)
常用有限个参数值来刻画(这里的参数值也可称为样本的属性值),每个参数值用于刻画xi的某个特征(属性)。于是对象xi就伴随着一个向量P(xi)=(xi1,xi2,…,xim), 其中xij()是xi在j个特征上的值,P(xi)称为xi的特征向量或模式向量(也可理解为用于定义聚类中心的向量,不过这样的理解并不严谨,因为并非每种聚类方法都是以类似于KMEANS那样的中心点来定义簇的,所以在数据模型中以P(xi)来表示在意义上更加抽象)。聚类分析就是分析论域或样本集合X中的n个样本所对应的模式矢量间的空间距离及分散情况,按照各样本间的距离远近或相似程度把x1, x2,…, xn划分成k个不相交的模式子集X1, X2, …, Xk,并要求满足下列条件:
样本
对子集
的隶属度关系可用隶属度函数表示为:
其中,隶属度函数必须满足条件
。也就是说:
要求每一个样本能且只能隶属于某一类。
要求每个子类都是非空的。
在这个表达式中
是用于约束"每一个样本能且只能属于某一类";
用于约束"每个子类都是非空的"。将以上定义的隶属度函数wij扩展到[0,1]这个区间即为模糊聚类的定义。模糊聚类又称为软聚类,相应的非模糊聚类也可称为硬聚类。

相关文章推荐
- 聚类基本数学模型
- [数学建模]马氏链模型(一)基本介绍
- 6-加速度计和陀螺仪的数学模型和基本算法
- 数学模型 机器学习 系统聚类(system clustering) Python实现
- 使用Octave音频处理(二):基本数学信号处理
- 数学建模——统计回归模型
- 动态规划基本模型(二)
- 中医五行学说的数学模型与仿射型广义Cartan矩阵
- mahout 源码解析之聚类--聚类分类模型
- Unix下5种基本的I/O模型
- 数学之美 系列一 -- 统计语言模型
- 数学之美 十四 谈谈数学模型的重要性
- 干货 | 机器学习数学、概念及模型思维导图
- 目录服务中LDAP的基本模型
- buck-boost基本模型
- Oracle 基本数学函数
- 转型AI产品经理,原来不需要学那么深的算法和数学模型
- 使用Octave音频处理(二):基本数学信号处理
- 数学之美系列十六 -- 谈谈最大熵模型
- 《Unix网络编程》 多进程并发服务器基本模型