如何使用Superset可无缝对接MRS进行自助分析
摘要:本文主要介绍如何在MRS之上使用Superset进行数据分析。
本文分享自华为云社区《使用商业智能软件Superset分析MRS数据之最佳实践》,作者: 啊喔YeYe 。
1. 概要
Superset
Apache Superset是一个现代的数据探索和可视化平台。具有功能强大、支持数据种类多、使用简单、易扩展、可视化能力丰富等诸多优势,在github上也有4.6w+的star.

MRS
MRS是华为云提供的一站式大数据平台,基本覆盖了Hadoop生态中常用的基本组件,免去我们运维、搭建的烦恼。
本文主要介绍如何在MRS之上使用Superset进行数据分析。
2.环境准备
- 在华为云购买创建弹性云服务器ECS(公共镜像建议选择CentOS 8.2 64bit),用于安装运行Superset,并绑定弹性公网IP,用于访问公网安装依赖包和Superset服务。
- MRS服务开通,选择MRS 3.1.0版本的普通集群模式。注意网络与superset打通
3. superset安装
3.1 登录已购买的Linux弹性云服务器,执行以下命令安装Superset运行依赖包
yum install gcc gcc-c++ libffi-devel openssl-devel cyrus-sasl-devel openldap-devel python36-devel cyrus-sasl-plain
3.2 执行以下命令升级pip版本
pip3 install --upgrade pip
3.3 执行以下命令安装python虚拟环境
pip install virtualenv
3.4 执行以下命令创建,并进入python虚拟环境
python3 -m venv venv . venv/bin/activate
3.5 执行以下命令安装python依赖包
pip install dataclasses pip install pyhive[hive] pip install pyhive[presto]
3.6 执行以下命令安装Superset
pip install apache-superset
3.7 执行以下命令初始化database
superset db upgrade
3.8 执行以下命令创建admin用户。需要输入用户名、FirstName、LastName和电子邮箱地址和密码
export FLASK_APP=superset superset fab create-admin
3.9 执行以下命令初始化角色和用户信息
superset init
3.10 执行以下命令启动superset服务
superset run -p 8088 -h 0.0.0.0 --with-threads --reload --debugger
3.11 选择“服务列表 > 弹性云服务器ECS > 待操作弹性云服务器名称 > 安全组”,单击“配置规则”。在配置规则界面,选择“入方向规则 > 添加规则”,将协议端口设置为8088,源地址设置为访问Supereset页面的机器的IP。
3.12 访问http://ECS弹性IP:8088,并以admin用户登录,开始使用Superset
4. MRS Hive对接
MRS HiveServer通过ZooKeeper实现高可用,Superset直接使用pyhive连接HiveServer,无法通过ZooKeeper进行服务发现,因此只配置连接一个HiveServer。
4.1 登录MRS管理控制台,在现有集群页面,单击集群名称进入MRS Manager页面。选择“组件管理 > Hive > 实例”,查看HiveServer实例所在节点IP

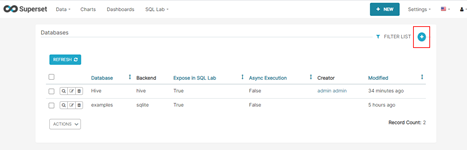
4.2 在Superset界面,选择“Data > Databases”,单击右侧的“+”按钮进入创建Database页面
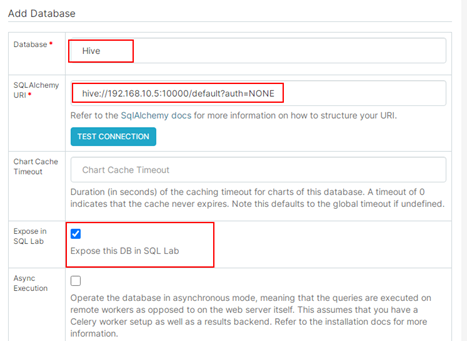
4.3 在Add Database页面填写Database和SQL Alchemy URI。SQL Alchemy URI的填写内容为“hive://{HiveServer实例ip}:端口/{hive database名字}?auth=NONE”,其中,{HiveServer实例ip}为HiveServer实例的业务IP,{hive database名字}为要连接的Hive Database,例如default。勾选“Expose in SQL Lab”,单击“Save”保存配置.
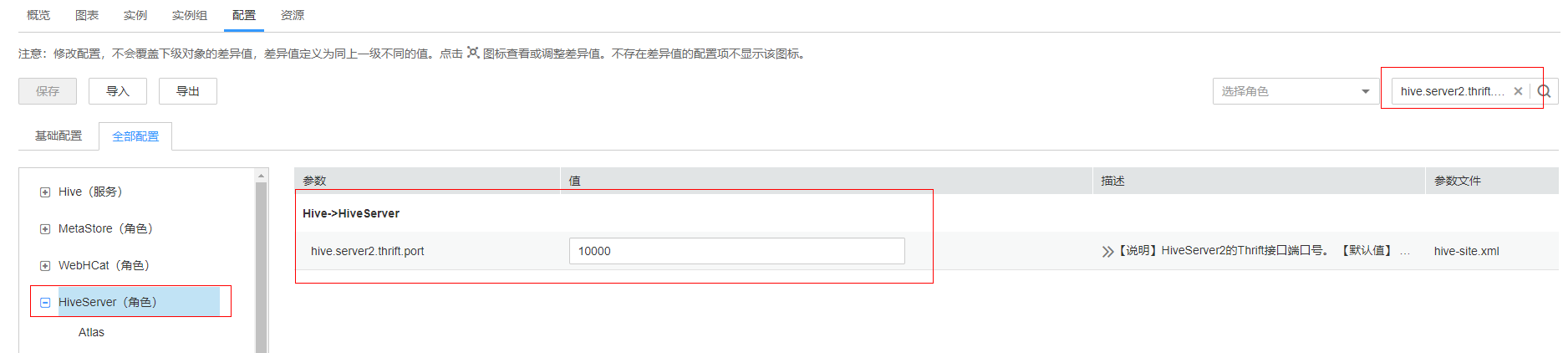
MRS 普通集群hiveserver2默认端口为10000。查看方式:登录manager,点击hive服务,点击全部配置,搜索hive.server2.thrift.port
superset配置:
4.4 选择“SQL Lab > SQL Editor”,进入Untitled Query页面。在左侧“Database”下拉菜单中选择创建好的Database,在“Select a schema”下拉菜单中选择要查询的Schema(即Hive的databse,如default),在中间SQL编辑框内输入SQL语句。然后单击“RUN”按钮执行SQL,在下方Result页签中查看执行结果。
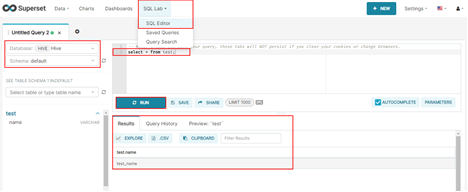
5. MRS SparkJDBC对接使用
5.1 参考hive对接方式获取SparkJDBC实例ip与端口(默认22550,配置项:hive.server2.thrift.port),然后在Superset添加database。
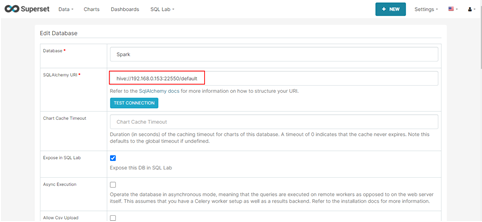
5.2 执行SQL验证
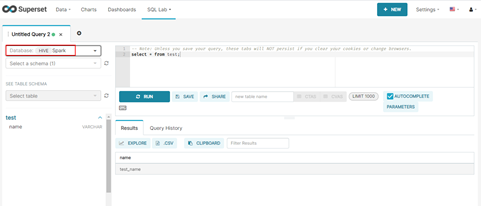
6. Superset中使用MRS PrestoSQL
6.1 在Manager界面,选择“集群 > 服务 > Presto > 配置 > 全部配置” ,搜索配置项PRESTO_COORDINATOR_FLOAT_IP ,获取Presto Coordinator浮动IP
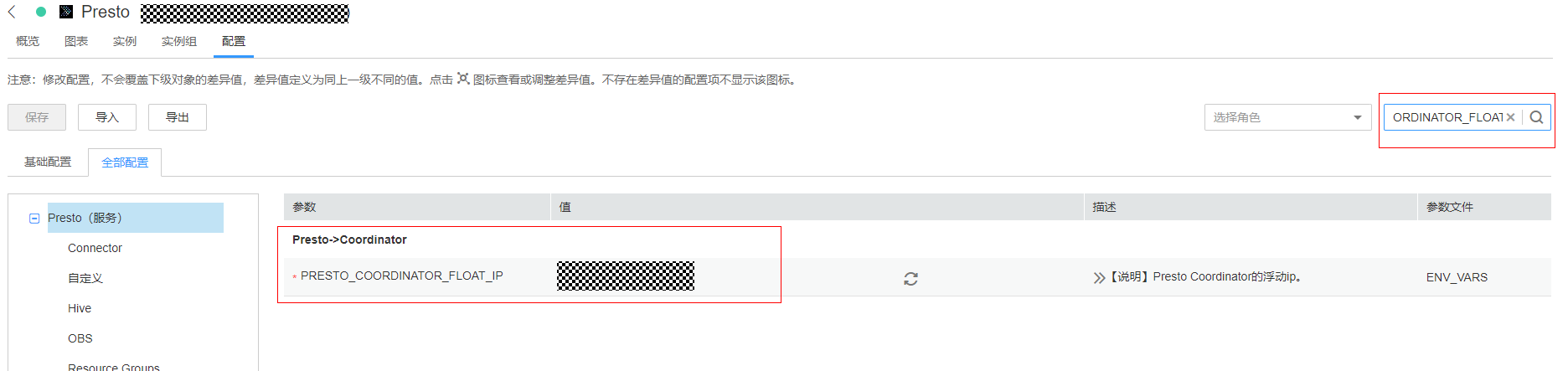
端口:默认7520
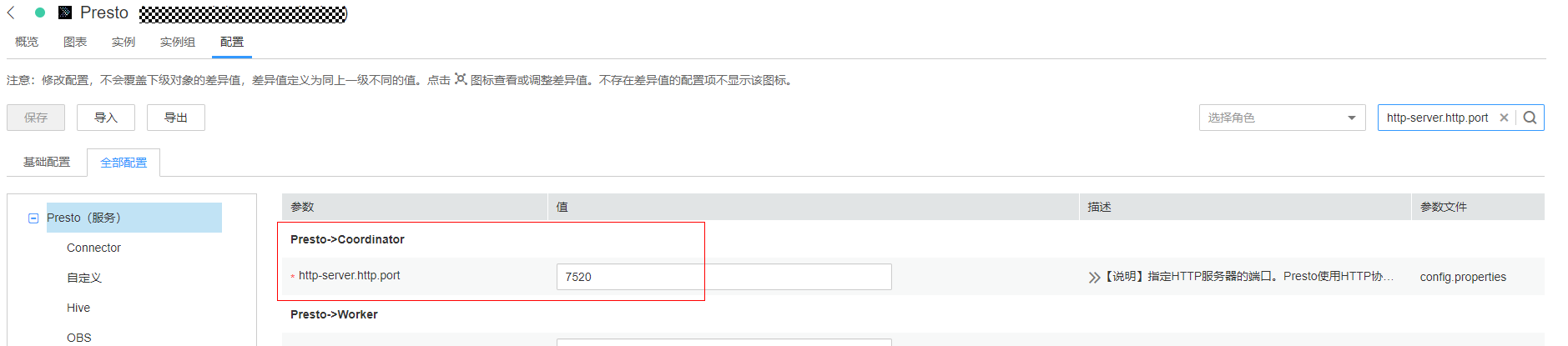
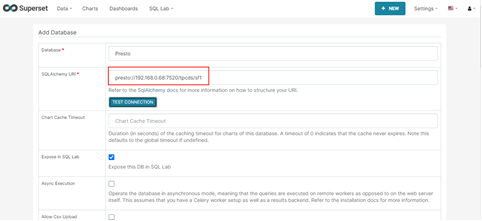
6.2 添加Presto database
SQL Alchemy URI填写内容为“presto://{Presto Coordinator浮动IP}:{port}/{catalog名称}/{schema名称}”,其中{Presto Coordinator浮动IP}为1中获取的Presto Coordinator浮动IP,{catalog名称}为要连接的Presto catalog,{schema名称}为catalog对应的schema名字,例如hive/default.
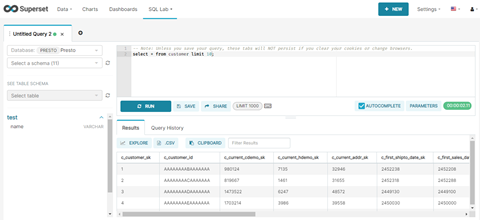
6.3 执行Presto SQL验证

华为伙伴暨开发者大会2022火热来袭,重磅内容不容错过!
【精彩活动】
勇往直前·做全能开发者→12场技术直播前瞻,8大技术宝典高能输出,还有代码密室、知识竞赛等多轮神秘任务等你来挑战。即刻闯关,开启终极大奖!点击踏上全能开发者晋级之路吧!
【技术专题】
未来已来,2022技术探秘→华为各领域的前沿技术、重磅开源项目、创新的应用实践,站在智能世界的入口,探索未来如何照进现实,干货满满点击了解

- java开发中如何使用JVisualVM进行性能分析
- 如何使用JVisualVM进行性能分析
- 如何使用ProcessMonitor进行application 依赖分析
- 如何使用Python Seaborn进行探索性数据分析
- [待解决]自定义头像时使用vue-cropper进行图片裁剪,得到的是base64格式的图片,如何对接file类型的api接口
- 如何使用工具进行线上 PHP 性能追踪及分析?
- 如何使用python进行社交网络分析
- 如何使用掘金进行量化策略绩效分析?
- IT 接口前端:足迹第十五步使用Google接口调试和DEBUG快捷键调试(如何在前端进行接口对接和打断点)
- 干货丨如何使用时序数据库DolphinDB进行淘宝用户行为分析
- 如何使用R包进行KEGG和GO分析
- 使用IDA5.0进行VB的逆向分析--如何减轻我的工作量?
- 如何使用工具进行线上 PHP 性能追踪及分析?
- 如何使用工具进行线上 PHP 性能追踪及分析?
- 如何使用Hive&R从Hadoop集群中提取数据进行分析
- phoenix 如何优化成使用索引进行查询源码分析
- mac如何使用infer进行maven项目源码静态分析
- 如何使用Erds进行洪水淹没分析
- 如何使用JVisualVM进行性能分析
- 使用回头客会员管理系统后如何进行数据分析