为什么列式存储会被广泛用在 OLAP 中?
大家好,我是大D。
不知是否有小伙伴们疑问,为什么列式存储会广泛地应用在 OLAP 领域,和行式存储相比,它的优势在哪里?今天我们一起来对比下这两种存储方式的差别。
其实,列式存储并不是一项新技术,最早可以追溯到 1983 年的论文 Cantor。然而,受限于早期的硬件条件和应用场景,传统的事务型数据库(OLTP)如 Oracle、MySQL 等关系型数据库都是以行的方式来存储数据的。
直到近几年分析型数据库(OLAP)的兴起,列式存储这一概念又变得流行,如 HBase、Cassandra 等大数据相关的数据库都是以列的方式来存储数据的。
行式存储的原理与特点
对于 OLAP 场景,大多都是对一整行记录进行增删改查操作的,那么行式存储采用以行的行式在磁盘上存储数据就是一个不错的选择。
当查询基于需求字段查询和返回结果时,由于这些字段都埋藏在各行数据中,就必须读取每一条完整的行记录,大量磁盘转动寻址的操作使得读取效率大大降低。
举个例子,下图为员工信息emp表。
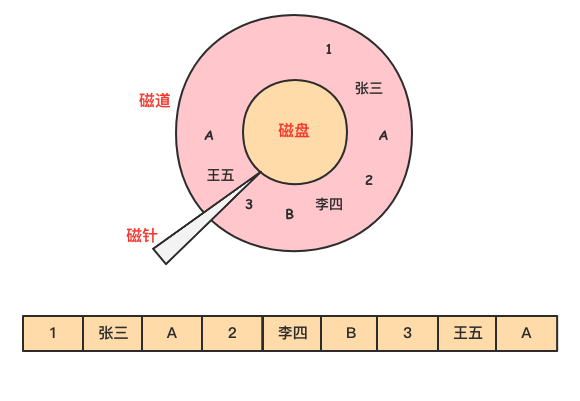
数据在磁盘上是以行的形式存储在磁盘上,同一行的数据紧挨着存放在一起。
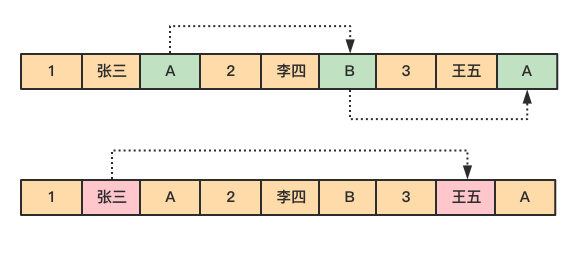
对于 emp 表,要查询部门 dept 为 A 的所有员工的名字。
select name from emp where dept = A
由于 dept 的值是离散地存储在磁盘中,在查询过程中,需要磁盘转动多次,才能完成数据的定位和返回结果。
列式存储的原理与特点
对于 OLAP 场景,一个典型的查询需要遍历整个表,进行分组、排序、聚合等操作,这样一来行式存储中把一整行记录存放在一起的优势就不复存在了。而且,分析型 SQL 常常不会用到所有的列,而仅仅对其中某些需要的的列做运算,那一行中无关的列也不得不参与扫描。
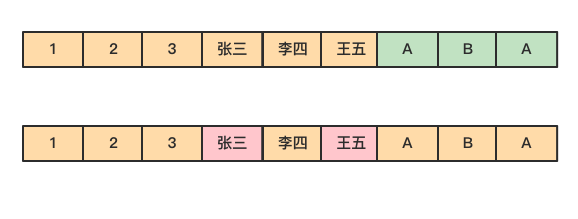
然而在列式存储中,由于同一列的数据被紧挨着存放在了一起,如下图所示。
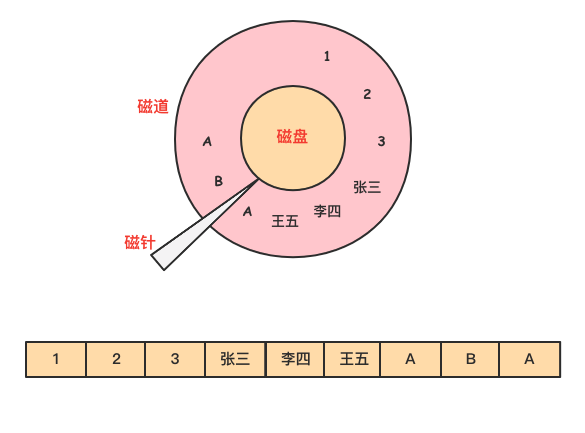
那么基于需求字段查询和返回结果时,就不许对每一行数据进行扫描,按照列找到需要的数据,磁盘的转动次数少,性能也会提高。
还是上面例子中的查询,由于在列式存储中 dept 的值是按照顺序存储在磁盘上的,因此磁盘只需要顺序查询和返回结果即可。
列式存储不仅具有按需查询来提高效率的优势,由于同一列的数据属于同一种类型,如数值类型,字符串类型等,相似度很高,还可以选择使用合适的编码压缩可减少数据的存储空间,进而减少IO提高读取性能。
总的来说,行式存储和列式存储没有说谁比谁更优越,只能说谁更适合哪种应用场景。
非常欢迎大家加我微信:Abox_0226,备注「进群」,有关大数据技术的问题在群里一起探讨。

- 为什么MaxCompute采用列式存储?列式存储和行式存储的主要区别在哪
- 为什么MaxCompute采用列式存储?列式存储和行式存储的主要区别在哪
- 为什么MaxCompute采用列式存储?列式存储和行式存储的主要区别在哪
- 常量字符串为什么位于静态存储区?
- Hadoop-No.4之列式存储格式
- List和Hashtable都是可以存储数据的,可为什么有时选择List,有时需要Hashtable,这两个有什么区别
- 列式存储 HBase 系统架构学习
- Lua 为什么在游戏编程领域被广泛运用?
- 常量字符串为什么位于静态存储区?
- 为什么要用存储过程,什么时候要用存储过程,存储过程的优点
- 计算机为什么要用补码存储整型
- mondrian 如何使用xml存储olap服务器的元数据
- 内存列式存储 vs Buffer Cache
- SQL Server中的TempDB管理——TempDB基本知识(为什么需要版本存储区)
- 常量字符串为什么位于静态存储区?
- 为什么不能用memcached存储Session?
- 为什么Docker没有在生产环境取得广泛成功
- 为什么不能用memcached存储Session?
- 【安卓开发】为什么不能往Android的Application对象里存储数据
- 问:当前计算机系统一般会采用层次结构存储数据,请介绍下典型计算机存储系统一般分为哪几个层次,为什么采用分层存储数据能有效提高程序的执行效率?