朴素贝叶斯算法的实现与推理
什么是naive bayes
朴素贝叶斯
naive bayes,是一种概率类的机器学习算法,主要用于解决分类问题
为什么被称为朴素贝叶斯?
为什么被称为朴素,难道仅仅是因为贝叶斯很天真吗?实际上是因为,朴素贝叶斯会假设数据属性之间具有很强的的独立性。即该模型中的所有属性彼此之间都是独立的,改变一个属性的值,不会直接影响或改变算法中其他的属性的值
贝叶斯定理
了解朴素贝叶斯之前,需要掌握一些概念才可继续
- 条件概率
Conditional probability
:在另一个事件已经发生的情况下,另外一个时间发生的概率。如,在多云天气,下雨的概率是多少? 这是一个条件概率 - 联合概率
Joint Probability
:计算两个或多个事件同时发生的可能性 - 边界概率
Marginal Probability
:事件发生的概率,与另一个变量的结果无关 - 比例
Proportionality
- 贝叶斯定理
Bayes' Theorem
:概率的公式;贝叶斯定律是指根据可能与事件的先验概率描述了事件的后验概率
边界概率
边界概率是指事件发生的概率,可以认为是无条件概率。不以另一个事件为条件;用公式表示为 P(X) 如:抽到的牌是红色的概率是 P(red) = 0.5 ;
联合概率
联合概率是指两个事件在同一时间点发生的可能性,公式可以表示为 P(A \cap B)
A 和 B 是两个不同的事件相同相交,$P(A \and B), $ P(A,B) = A 和 B 的联合概率
概率用于处理事件或现象发生的可能性。它被量化为介于 0 和 1 之间的数字,其中 0 表示不可能发生的机会,1 表示事件的一定结果。
如,从一副牌中抽到一张红牌的概率是 \frac{1}{2}。这意味着抽到红色和抽到黑色的概率相同;因为一副牌中有52张牌,其中 26 张是红色的,26 张是黑色的,所以抽到一张红牌与抽到一张黑牌的概率是 50%。
而联合概率是对测量同时发生的两个事件,只能应用于可能同时发生多个情况。例如,从一副52张牌扑克中,拿起一张既是红色又是6的牌的联合概率是 P(6\cap red) = \frac{2}{52} = \frac{1}{26} ;这个是怎么得到的呢?因为抽到红色的概率为50%,而一副牌中有两个红色6(红桃6,方片6),而6和红色是两个独立的概率,那么计算公式就为:P(6 \cap red) = P(6) \times P(red) = \frac{4}{52} \times \frac{26}{52} = \frac{1}{26}
在联合概率中 $ \cap $ 称为交集,是事件 A 与 事件 B 发生的概率的相交点,通过图来表示为:两个圆的相交点,即6和红色牌共同的部分
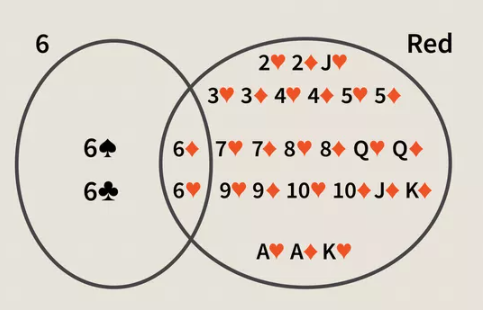
条件概率
条件概率是指事件发生的可能性,基于先有事件的结果的发生乘后续事件概率来计算的,例如,申请大学的通过率为80%,宿舍仅提供给60%学生使用,那么这个人被大学录取并提供宿舍的概率是多少?
P(accept\ and\ get\ dorm) = P(Accept|Dorm) = P(Accept) \times P(Dorm) = 0.8 \times 0.6 = 0.48
条件概率将会考虑两个事件之间的关系,例如你被大学录取的概率, 以及为你提供宿舍的概率;条件概率中的关键点:
- 另一个事件发生的情况下,这件事发生的几率
- 表示为,给定 B 的概率 A 发生的概率,用公式表示为:P(A|B),其中 A 取决于 B 发生的概率
通过例子了解条件概率
上述大致上了解到了:条件概率取决于先前的结果,那么通过几个例子来熟悉条件概率
例1:袋子里有红色,蓝色,绿色三颗玻璃球,每种被拿到的概率相等,那么摸到蓝色之后再摸到红色的条件概率是多少?
- 这里需要先得到摸到蓝色的概率:P(Blue) = \frac{1}{3} 因为只有三种可能性
- 现在还剩下两颗玻璃球 红色和蓝色,那么摸到红色的概率为:P(Red) = \frac{1}{2} 因为只有两种可能性
- 那么已经摸到蓝色在摸到红色的概率为 P(Red|Blue) = \frac{1}{3} \times \frac{1}{2} = \frac{1}{6}
例2:色子摇出5的概率为 \frac{1}{6} 那么在结果是奇数里摇出5 那么可能就是 \frac{1}{3},而这个奇数就是另外的一个条件,因为只有3个奇数,其中一个是5,那么在奇数中,抛出5的概率就是 \frac{1}{3}。
通过上述信息可知,B 作为附带条件修饰 A 发生的概率,称为给定 B ,A 发生的条件,用$P(A|B)$ 表示。那么可以的出:
- 给定A,B发生的概率为,A和B的发生概率排除掉A的概率,即
- $P(B|A) = \frac{P(A \cap B)}{P(A)} $
联合概率和条件概率的区别
条件概率是一个事件在另一个事件发生的情况下的概率:$P(X,given Y) $ 公式为: P(X∣Y);即一个事件发生的概率取决于另一事件的发生;如:从一副牌中,假设你抽到一张红牌,那么抽到6的概率是 \frac{1}{13};因为26张红牌中仅有两张为6,用公式表示:P(6|red) = \frac{2}{26}
联合概率仅考虑两个事件发生的可能性,对比与条件概率可用于计算联合概率:P(X \cap Y) = P(X|Y) \times P(Y)
通过合并上述例子得到,同时抽到6和红色的概率为:\frac{1}{26}
贝叶斯定理
贝叶斯定理是确定条件概率的数学公式。贝叶斯定理依赖于先验概率分布以计算后验概率。
后验概率和先验概率
- 先验概率
prior probability
:在收集新数据之前发送事件的概率 - 后验概率
posterior probability
:得到新的数据来修正之前事件发生的概率;换句话说是后验概率是在事件 B 已经发生的情况下,事件 A 发生的概率。
例,从一副52 张牌中抽取一张牌,那么这张牌是K的概率是 \frac{4}{52} , 因为一副牌中有4张K;假设抽中的牌是一张人物牌,那么抽到是K的概率则是 \frac{4}{12};因为一副牌中有12张人物牌。那么贝叶斯定理的公式为:
- P(A|B) = \frac{P(A \cap B)}{P(B)},P(B|A) = \frac{P(B \cap A)}{P(A)} P(A \cap B),P(B \cap A) A和B同时发生和B和A同时发生时相等的
- P(B \cap A) = P(B|A) \times P(A)
- P(A \cap B) = P(A|B) \times P(B)
-
因为 P(B \cap A) = P(A \cap B) ,那么 P(B|A) \times P(A) = P(A|B) \times P(B)
Formula for Bayes为 P(B|A) = \frac{P(A|B) \times P(B)}{P(A)}
其中:
P(A):A 的边界概率
P(B):B 的边界概率
P(A|B) :条件概率,已知 B,A 的概率
P(B|A) :条件概率,已知 A,B 的概率
P(B \cap A):联合概率 B 与 A 同时发生的概率
一个简单的概率问题可能会问:茅台股价下跌的概率是多少?条件概率通过询问这个问题更进一步:鉴于A股平均指数下跌,茅台股价下跌的概率是多少? 给定 B 已经发生的条件下 A 的概率可以表示为:
P(Mao|AS) = \frac{P(Mao \cap AS)}{P(AS)}
P(Mao \cap AS) 是 A 和 B 同时发生的概率,与 A 发生的情况下 B 也发生的概率 乘 A 发生的概率相等表示为: P(Mao) \times P(AS|Mao);这两个表达式相等,也就是贝叶斯定理,可以表示为:
- 如果, P(Mao \cap AS) = P(Mao) \times P(AS|Mao)
- 那么, P(Mao|AS) = \frac{P(Mao) \times P(AS|Mao)}{P(AS)}
P(Mao) 和 P(AS) 分别为茅台和A股的下跌概率,彼此间没有关系
一般情况下,都是以 x (输入) y (输出) 在函数中,假设 x=AS , y=MAO 那么替代到公式中就 P(Y|X) = \frac{P(X|Y) \times P(Y)}{P(X)}
朴素贝叶斯算法
朴素贝叶斯不是一个的算法,而是一组算法,所有这些算法都基于一个共同的原则,即每一对被分类的特征必须相互独立。朴素贝叶斯是一个基本的贝叶斯称呼,包含三种算法的集合:多项式
Multinomial、 伯努利
Bernoulli、高斯
Gaussian。
伯努利
伯努利朴素贝叶斯,又叫做二项式,只接受二进制值,简而言之,在伯努利中必须计算每个值的二进制出现特征,即一个单词是与否出现在文档中。
通俗地来说,伯努利有两个互斥的结果:
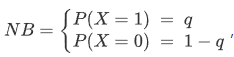
在伯努利中,可以有多个特征,但每个特征都假设为是二进制的变量,因此,需要将样本表示为二进制向量。
那么扩展出的公式为:$P(A|B) = \frac{P(B|A) \times P(A)}{P(A) \times P(B|A) + P(not A) \times P(B|not A)} $
例子:假设COVID-19测试并不准确,有**95%**几率在感染时测试出阳性(敏感性),这就意味着如果有人并未感染的概率是相同的(特异性);问:如果Jeovanna检测为阳性,那么他感染COVID-19的概率是多少?
敏感性和特异性是医学用语;敏感性,病人测出阳性的比例,特异性,非病人测试阴性的比例
一般情况下没有更多的信息来确定Jeovanna是否感染,如驻留场所,是否发烧,丧失味觉等。就需要更多的信息来计算Jeovanna感染率,比如预估Jeovanna感染率为1%,这1%就是先验概率。
此时有100000人的测试样本,预计1000人感染(先验1%),那么就是99000为感染,又因为测试具有 95% 的敏感性和 95% 的特异性,这代表了 1000的95% 和 99000的5% 是阳性。整理一个表格
| Has COVID-19 | Do not Has COVID-19 | count | |
|---|---|---|---|
| 阳性 | 950 | 4950 | 5900 |
| 阴性 | 50 | 94050 | 94100 |
那么可以看出,阳性的人并感染COVID-19的概率是,\frac{950}{5900} = 16\% ;那么也就是Jeovanna有16%几率是感染 COVID-19。
此时将先验概率设置为16%,那么爱丽丝得COVID-19的可能性为:
P(B|A) :在95%成功率情况下又获得了阳性
P(A):阳性的检测成功率
已知,P(B|A) = 0.16 ,P(A) = 0.95
P(A|B) = \frac{P(B|A) \times P(A)}{P(A) \times P(B|A) + P(not A) \times P(B|not A)} = \frac{0.16\times0.95}{0.95\times 0.16 + (1-0.95)\times(1-0.16)}= \frac{0.152}{0.194} = 0.7835 = 78.35\%
那么就可以得知,在阳性情况下感染COVID-19的情况下,再去检测会有78%几率阳性
多项式
多项式朴素贝叶斯是基于多项分布的朴素叶贝斯,用来处理文本,计算 d 在 c 中的概率计算如下:
P(c|d) \ \propto P(c) \prod_{i=1}^n\ P(t_k|c)
通俗来说就是二项式的一个变种,是计算多个不同的实例
P(t_k|c) 是 t_k 的 条件概率,发生在数据集 c 中,P(t_k|c) 解释为 t_k 有多少证据表明 c 是正确的;P(c) 是先验条件 t1..\ t2..\ t3..\ tn_d 中的标记 d,它们是我们用于分类的词汇表的一部分,n_d 是 标记 d 的数量。
例如:"Peking and Taipei join the WTO",<Peking,\ Taipei,\ join,\ WTO> ,那么 n_d = 4
那么可以简化为,
P(c=x|d=c_k) = P(c^1=x^1..,\ c^2=x^2..,\ c^n=x^n|d=c_k) = \prod_{i=1}^n(c^i|d)x^i + (1-P(c^i|d)) (1-x^i)
\prod_{i=1}^n 连乘积,即从下标起乘到上标
朴素贝叶斯实现
首先将朴素贝叶斯为 5 个部分:
- 分类
- 数据集汇总
- 按类别汇总数据
- 高斯密度函数
- 分类概率
分类
根据数据所属的类别来计算数据的概率,即所谓的基本率。
先创建一个字典对象,其中每个键都是类值,然后添加所有记录的列表作为字典中的值。
假设每行中的最后一列是类型。
# 按类拆分数据集,返回结构是一个词典 def separate_by_class(dataset): separated = dict() for i in range(len(dataset)): vector = dataset[i] class_value = vector[-1] # dataset最后一行是类别 if (class_value not in separated): separated[class_value] = list() separated[class_value].append(vector) return separated
准备一些数据集
X1 X2 Class 3.393533211 2.331273381 0 3.110073483 1.781539638 0 7.423436942 4.696522875 1 1.343808831 3.368360954 0 3.582294042 4.67917911 0 9.172168622 2.511101045 1 7.792783481 3.424088941 1 2.280362439 2.866990263 0 5.745051997 3.533989803 1 7.939820817 0.791637231 1
测试分类函数的功能
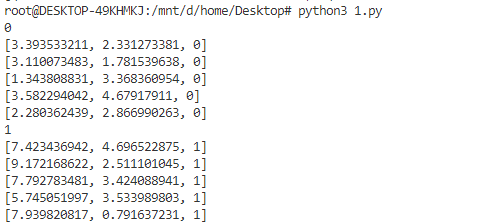
def separate_by_class(dataset): separated = dict() for i in range(len(dataset)): vector = dataset[i] class_value = vector[-1] if (class_value not in separated): separated[class_value] = list() separated[class_value].append(vector) return separated # 测试数据集 dataset = [ [3.393533211,2.331273381,0], [3.110073483,1.781539638,0], [1.343808831,3.368360954,0], [7.423436942,4.696522875,1], [3.582294042,4.67917911,0], [9.172168622,2.511101045,1], [7.792783481,3.424088941,1], [2.280362439,2.866990263,0], [5.745051997,3.533989803,1], [7.939820817,0.791637231,1] ] separated = separate_by_class(dataset) for label in separated: print(label) for row in separated[label]: print(row)
可以看到分类是成功的
数据集汇总
现在需要对给出数据集的两个数据进行统计,如何对指定数据集做概率计算?需要以下几步
计算数据集两个数据的平均值和标准差
平均值为: \frac{sum(x)}{n} \times count(x) ;其中 x 为正在查找值的列表
mean函数用于计算平均值
def mean(numbers): return sum(numbers) / float(len(numbers))
样本标准差的计算方式为平均值的平均差。公式可以为
sqrt((sum i to N (x_i – mean(x))^2) / N-1)
函数用来计算
from math import sqrt # Calculate the standard deviation of a list of numbers def stdev(numbers): avg = mean(numbers) # 平均值 variance = sum([(x-avg)**2 for x in numbers]) / float(len(numbers)-1) return sqrt(variance)
还需要对每个数据的每一列计算平均值和标准偏差统计量。通过将每列的所有值收集到一个列表中并计算该列表的平均值和标准差。计算完成后,将统计信息收集到数据汇总的列表或元组中。然后,对数据集中的每一列重复此操作并返回统计元组列表。
下面是 数据汇总的函数
summarise_dataset()用来统计每列列表的平均值和标准差
from math import sqrt # 计算平均数 def mean(numbers): return sum(numbers)/float(len(numbers)) # 计算标准差 def stdev(numbers): # 标准差 avg = mean(numbers) # 计算平均值 variance = sum([(x-avg)**2 for x in numbers]) / float(len(numbers)-1) # 计算所有的平方 return sqrt(variance) # 数据汇总 def summarize_dataset(dataset): summaries = [(mean(column), stdev(column), len(column)) for column in zip(*dataset)] del(summaries[-1]) # 因为分类不需要所以。删除掉分类哪行 return summaries # Test summarizing a dataset dataset = [ [3.393533211,2.331273381,0], [3.110073483,1.781539638,0], [1.343808831,3.368360954,0], [3.582294042,4.67917911,0], [2.280362439,2.866990263,0], [7.423436942,4.696522875,1], [5.745051997,3.533989803,1], [9.172168622,2.511101045,1], [7.792783481,3.424088941,1], [7.939820817,0.791637231,1]] summary = summarize_dataset(dataset) print(summary)
这里使用的是
zip()函数,将每列作为提供的参数。使用 * 作为位置函数,运将数据集传递给
zip(),这个运算会将每一行的分割为单独列表。然后
zip()遍历每一行的每个元素,返回一列作为数字列表。
然后计算每列中的平均数、标准差和行数。删掉不需要的列(第三列类别列的平均数,标准差和行数)
可以看到
[ (5.178333386499999, 2.7665845055177263, 10), (2.9984683241, 1.218556343617447, 10) ]
根据类别汇总数据
separate_by_class()是将数据分成行,现在要编写一个
summarise_dataset();是先计算每列的统计汇总信息,然后在按照子集分类(X1,X2)
# 按类拆分数据集 def summarize_by_class(dataset): separated = separate_by_class(dataset) summaries = dict() for class_value, rows in separated.items(): summaries[class_value] = summarize_dataset(rows) return summaries
这是完整的代码
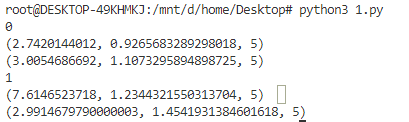
from math import sqrt # 计算平均数 def mean(numbers): return sum(numbers)/float(len(numbers)) # 计算标准差 def stdev(numbers): # 标准差 avg = mean(numbers) # 计算平均值 variance = sum([(x-avg)**2 for x in numbers]) / float(len(numbers)-1) # 计算所有的平方 return sqrt(variance) # 数据汇总 def summarize_dataset(dataset): summaries = [(mean(column), stdev(column), len(column)) for column in zip(*dataset)] del(summaries[-1]) # 因为分类不需要所以。删除掉分类哪行 return summaries # 按类进行数据汇总 def summarize_by_class(dataset): separated = separate_by_class(dataset) summaries = dict() for class_value, rows in separated.items(): summaries[class_value] = summarize_dataset(rows) return summaries # 测试数据集 dataset = [ [3.393533211,2.331273381,0], [3.110073483,1.781539638,0], [1.343808831,3.368360954,0], [3.582294042,4.67917911,0], [2.280362439,2.866990263,0], [7.423436942,4.696522875,1], [5.745051997,3.533989803,1], [9.172168622,2.511101045,1], [7.792783481,3.424088941,1], [7.939820817,0.791637231,1]] summary = summarize_by_class(dataset) for label in summary: print(label) for row in summary[label]: print(row)
按照分类,对每列计算平均值和标准差
高斯分布
高斯分布
Gaussian distribution可以用两个数字来概括,高斯分布是具有对称的钟形的分布,所以中心右侧是左侧的镜像,曲线下的面积代表概率,曲线总面积之和等于1。
高斯分布中的大多数连续数据值倾向于围绕均值聚集,值离均值越远,那么它发生的可能性就越小。接近但从未完全贴合x 轴。
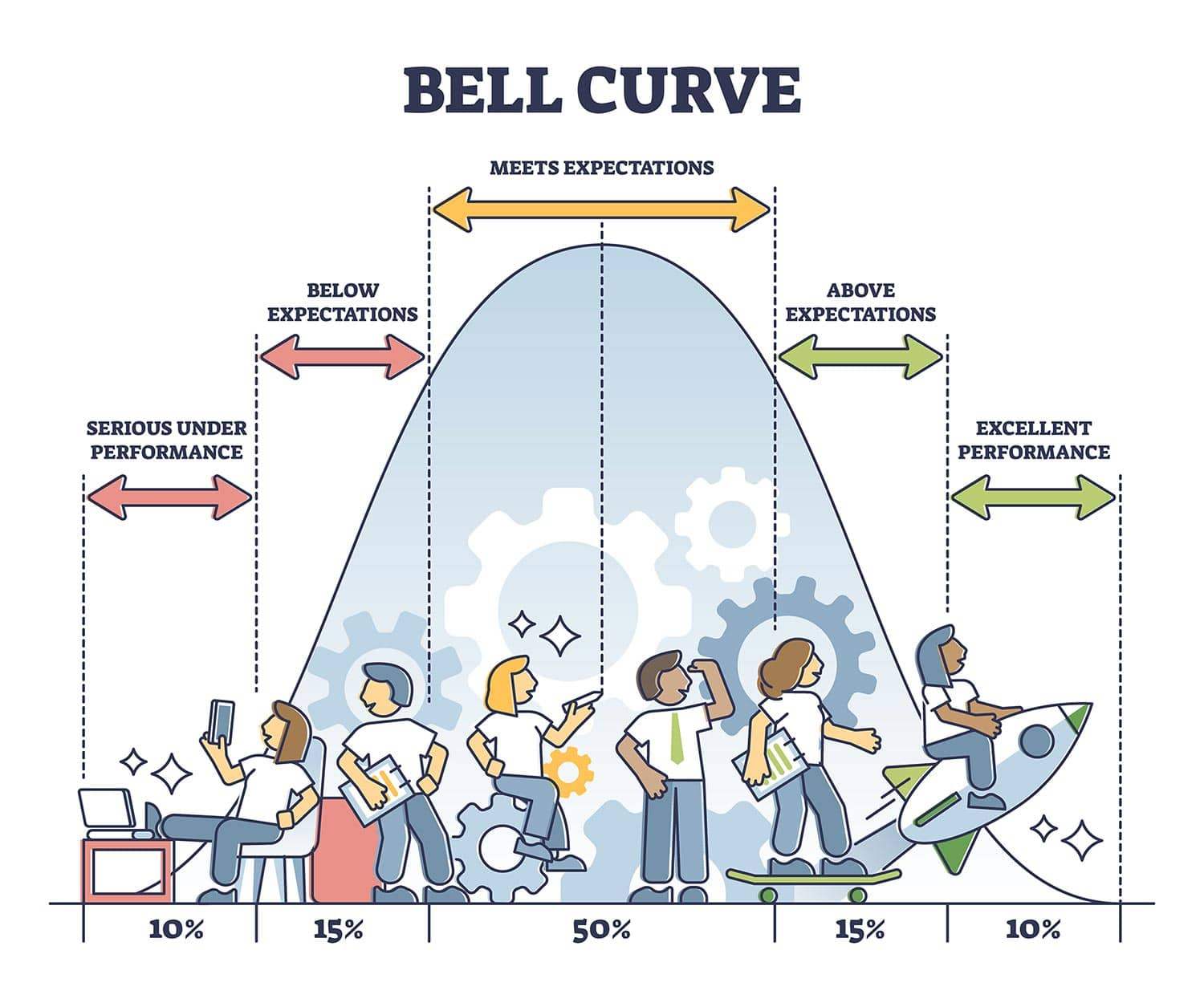
高斯分布由均值和标准差两个参数决定的,任何点 (x) 都可以通过公式 z = \frac{x-mean}{standard\ deviation} 来计算
Reference
通过这一点,就可以知道就可以计算出给定的概率,公式为:
P({x_i}|Y) = \frac{1}{\sqrt2\pi\sigma_y^2}exp(-(\frac{(x_i-\mu_y)^2}{2\sigma_y^2})
其中,\sigma 为标准差,\mu 为平均值,那么转换为可读懂的公式为:
f(x) = \frac{1}{\sqrt{(2 \times pi )}\times sigma} \times exp(-(\frac{(x-mean)^2}{(2 \times sigma)^2}))
其中,
sigma是
x的标准差,
mean是
x的平均值,PI是 就是 \pi
math.pi的值。
那么在转换成python中的代码为:
f(x) = (1 / sqrt(2 * PI) * sigma) * exp(-((x-mean)^2 / (2 * sigma^2)))
那么用python实现一个函数,来实现高斯公式
# 计算高斯分布的函数,需要三个参数,x 平均值,标准差 def calculate_probability(x, mean, stdev): exponent = exp(-((x-mean)**2 / (2 * stdev**2 ))) return (1 / (sqrt(2 * pi) * stdev)) * exponent
这里通过函数测试三个数据,
(0,1,1),
(1,1,1),
(2,1,1)
from math import sqrt from math import pi from math import exp # 计算高斯分布的函数,需要三个参数,x 平均值,标准差 def calculate_probability(x, mean, stdev): exponent = exp(-((x-mean)**2 / (2 * stdev**2 ))) return (1 / (sqrt(2 * pi) * stdev)) * exponent print(calculate_probability(1.0, 1.0, 1.0)) print(calculate_probability(2.0, 1.0, 1.0)) print(calculate_probability(0.0, 1.0, 1.0))

这里可以看到结果,
(1,1,1)的概率最可能(三个值中趋于钟形顶部)
分类概率
到这里,可以尝试通过测试数据来统计新数据的概率,这里每个类别的概率都是单独计算的,这里将简化概率计算公式 P(class|data) = P(data|class) \times P(class);这是一个常见的简化,这将意味着将结果为最大值的类的计算作为预测结果。因为通常对预测感兴趣,而不是概率
对于上述例子,有两个变量,这里以
class=0的类别来说明,公式为:
P(class=0|X1,X2) = P(X1|class=0) \times P(X2|class=0) \times P(class=0)
编写一个聚合函数,将上述四个步骤汇总处理,
# Example of calculating class probabilities from math import sqrt from math import pi from math import exp # 拆分数据集 def separate_by_class(dataset): separated = dict() for i in range(len(dataset)): vector = dataset[i] class_value = vector[-1] if (class_value not in separated): separated[class_value] = list() separated[class_value].append(vector) print(separated) return separated # 计算平均数 def mean(numbers): return sum(numbers)/float(len(numbers)) # 计算标准差 def stdev(numbers): avg = mean(numbers) # 计算平均值 variance = sum([(x-avg)**2 for x in numbers]) / float(len(numbers)-1) # 标准差 return sqrt(variance) # 数据汇总 def summarize_dataset(dataset): summaries = [(mean(column), stdev(column), len(column)) for column in zip(*dataset)] del(summaries[-1]) return summaries # 按类进行数据汇总 def summarize_by_class(dataset): separated = separate_by_class(dataset) summaries = dict() for class_value, rows in separated.items(): summaries[class_value] = summarize_dataset(rows) return summaries # 计算高斯分布的函数,需要三个参数,x 平均值,标准差 def calculate_probability(x, mean, stdev): exponent = exp(-((x-mean)**2 / (2 * stdev**2 ))) return (1 / (sqrt(2 * pi) * stdev)) * exponent # 计算每个分类的概率 def converge_probabilities(summaries, row): # 计算所有分类的个数 total_rows = sum([summaries[label][0][2] for label in summaries]) probabilities = dict() for class_value, class_summaries in summaries.items(): # 计算分类的概率,如这个分类在总分类里概率多少 probabilities[class_value] = summaries[class_value][0][2]/float(total_rows) for i in range(len(class_summaries)): mean, stdev, _ = class_summaries[i] probabilities[class_value] *= calculate_probability(row[i], mean, stdev) return probabilities # 测试数据集 dataset = [ [3.393533211,2.331273381,0], [3.110073483,1.781539638,0], [1.343808831,3.368360954,0], [3.582294042,4.67917911,0], [2.280362439,2.866990263,0], [7.423436942,4.696522875,1], [5.745051997,3.533989803,1], [9.172168622,2.511101045,1], [7.792783481,3.424088941,1], [7.939820817,0.791637231,1]] summaries = summarize_by_class(dataset) probabilities = converge_probabilities(summaries, dataset[0]) print(probabilities)
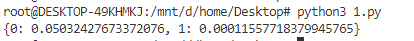
由结果可以得知,
dataset[0]X1 的概率(0.0503)要大于 X2 的概率(0.0001),所以可以正确的判断出
dataset[0]属于 X1 分类
鸢尾花(Iris)分类
鸢尾花分类,是模式识别中非常出名的一种数据库,需要先将数据下载:
实现开始
实验是根据上述实验的步骤,将朴素贝叶斯算法应用在鸢尾花数据集中,鸢尾花数据集的实验也是需要相同的步骤,只不过对于数据集中的数据还需要一些其他的步骤,大致可分为以下几种操作:
- 数据的预处理 从文件中读取数据
- 将数据类型转换为可用于上面实验的类型(
float
) - 将真实分类转换为数字
int
from csv import reader
from random import seed
from random import randrange
from math import sqrt
from math import exp
from math import pi
# 读取数据集
def load_csv(filename):
dataset = list()
with open(filename, 'r') as file:
csv_reader = reader(file)
for row in csv_reader:
if not row:
continue
dataset.append(row)
return dataset
# 将每行的数字转换为float
def str_column_to_float(dataset, column):
for row in dataset:
row[column] = float(row[column].strip())
# 将真实分类转换为数字,按照下标
def str_column_to_int(dataset, column):
'''
:param dataset: list, 数据集
:param column: string,是为类型的列要传入
:return: None
'''
# 通过循环拿到所有分类
class_values = [row[column] for row in dataset]
# 对分类型去重
unique = set(class_values)
lookup = dict()
# 拿到分类值的key 下标
for i, value in enumerate(unique):
lookup[value] = i
# 已对应的下标进行替换
for row in dataset:
row[column] = lookup[row[column]]
return lookup
# 将数据的一部分作为训练数据
def cross_validation_split(dataset, n_folds):
dataset_split = list()
dataset_copy = list(dataset)
fold_size = int(len(dataset) / n_folds)
for _ in range(n_folds):
fold = list()
while len(fold) < fold_size:
index = randrange(len(dataset_copy))
fold.append(dataset_copy.pop(index))
dataset_split.append(fold)
return dataset_split
# 计算准确度
def accuracy_metric(actual, predicted):
correct = 0
for i in range(len(actual)):
if actual[i] == predicted[i]:
correct += 1
return correct / float(len(actual)) * 100.0
# 对算法数据进行评估
def evaluate_algorithm(dataset, algorithm, n_folds, *args):
"""
:param dataset:list, 原始数据集
:param algorithm:function,算法函数
:param n_folds:int,取多少数据作为训练集
:param args:options ,参数
:return: None
"""
folds = cross_validation_split(dataset, n_folds)
scores = list()
for fold in folds:
train_set = list(folds)
train_set.remove(fold)
# 合并成一个数组
train_set = sum(train_set, [])
test_set = list()
for row in fold:
row_copy = list(row)
test_set.append(row_copy)
row_copy[-1] = None # 将最后一个类型字段设置为None
predicted = algorithm(train_set, test_set, *args)
# 真实的类型
actual = [row[-1] for row in fold]
# 精确的分数,即这一组数据正确率
accuracy = accuracy_metric(actual, predicted)
scores.append(accuracy)
print(scores)
return scores
# 按照分类拆分
def separate_by_class(dataset):
separated = dict()
for i in range(len(dataset)):
vector = dataset[i]
class_value = vector[-1]
if (class_value not in separated):
separated[class_value] = list()
separated[class_value].append(vector)
return separated
# 计算这一系列的平均值
def mean(numbers):
return sum(numbers)/float(len(numbers))
# 计算一系列数字的标准差
def stdev(numbers):
avg = mean(numbers)
variance = sum([(x-avg)**2 for x in numbers]) / float(len(numbers)-1)
return sqrt(variance)
# 计算数据集中每列的平均值 标准差 长度
def summarize_dataset(dataset):
summaries = [(mean(column), stdev(column), len(column)) for column in zip(*dataset)]
del(summaries[-1])
return summaries
# 按照分类划分数据集
def summarize_by_class(dataset):
separated = separate_by_class(dataset)
summaries = dict()
for class_value, rows in separated.items():
summaries[class_value] = summarize_dataset(rows)
return summaries
# 计算x的高斯概率
def calculate_probability(x, mean, stdev):
"""
:param x:float, 计算这个值的高斯概率
:param mean:float,x的平均值
:param stdev:float,x的标准差
:return: None
"""
exponent = exp(-((x-mean)**2 / (2 * stdev**2 )))
return (1 / (sqrt(2 * pi) * stdev)) * exponent
# 计算每行的概率
def converge_probabilities(summaries, row):
# 计算所有分类的个数
total_rows = sum([summaries[label][0][2] for label in summaries])
probabilities = dict()
for class_value, class_summaries in summaries.items():
# 计算分类的概率,如这个分类在总分类里概率多少
# 公式中的P(class)
probabilities[class_value] = summaries[class_value][0][2]/float(total_rows)
# 通过公式 P(X1|class=0) * P(X2|class=0) * P(class=0) 计算高斯概率
for i in range(len(class_summaries)):
mean, stdev, _ = class_summaries[i]
probabilities[class_value] *= calculate_probability(row[i], mean, stdev)
return probabilities
# 通过计算出来的值,预测该花属于哪个品种,取高斯概率最大的值
def predict(summaries, row):
probabilities = converge_probabilities(summaries, row)
best_label, best_prob = None, -1
for class_value, probability in probabilities.items():
if best_label is None or probability > best_prob:
best_prob = probability
best_label = class_value
return best_label
# Naive Bayes Algorithm
def naive_bayes(train, test):
# 训练数据按照类分类排序
summarize = summarize_by_class(train)
predictions = list()
for row in test:
output = predict(summarize, row)
predictions.append(output)
print(predictions)
return(predictions)
# 测试
if __name__ == '__main__':
seed(1)
filename = 'iris.csv'
dataset = load_csv(filename)
# 转换数值为float
for i in range(len(dataset[0])-1):
str_column_to_float(dataset, i)
# 将类型转换为数字
str_column_to_int(dataset, len(dataset[0])-1)
# 将数据分位测试数据和训练数据,folds为多少数据为训练数据
n_folds = 5
scores = evaluate_algorithm(dataset, naive_bayes, n_folds)
print('Scores: %s' % scores)
print('Mean Accuracy: %.3f%%' % (sum(scores)/float(len(scores))))

可以看到运行结果,对鸢尾花数据集的预测正确率,平均为95.333%
现在对
main部分进行修改,使用全部数据集作为训练,新增记录作为预测
# 按照整个数据集分类
model = summarize_by_class(dataset)
# 新加一行预测数据
row = [5.3,3.9,3.2,2.3]
# 根据训练集进行对数据预测
label = predict(model, row)
print('Data=%s, Predicted: %s' % (row, label))
完整修改过的代码如下:
from csv import reader
from random import seed
from random import randrange
from math import sqrt
from math import exp
from math import pi
# 读取数据集
def load_csv(filename):
dataset = list()
with open(filename, 'r') as file:
csv_reader = reader(file)
for row in csv_reader:
if not row:
continue
dataset.append(row)
return dataset
# 将每行的数字转换为float
def str_column_to_float(dataset, column):
for row in dataset:
row[column] = float(row[column].strip())
# 将真实分类转换为数字,按照下标
def str_column_to_int(dataset, column):
'''
:param dataset: list, 数据集
:param column: string,是为类型的列要传入
:return: None
'''
# 通过循环拿到所有分类
class_values = [row[column] for row in dataset]
# 对分类型去重
unique = set(class_values)
lookup = dict()
# 拿到分类值的key 下标
for i, value in enumerate(unique):
lookup[value] = i
# 增加一行,来显示下标和真实名称对应的数据
print(lookup)
# 已对应的下标进行替换
for row in dataset:
row[column] = lookup[row[column]]
return lookup
# 将数据的一部分作为训练数据
def cross_validation_split(dataset, n_folds):
dataset_split = list()
dataset_copy = list(dataset)
fold_size = int(len(dataset) / n_folds)
for _ in range(n_folds):
fold = list()
while len(fold) < fold_size:
index = randrange(len(dataset_copy))
fold.append(dataset_copy.pop(index))
dataset_split.append(fold)
return dataset_split
# 计算准确度
def accuracy_metric(actual, predicted):
correct = 0
for i in range(len(actual)):
if actual[i] == predicted[i]:
correct += 1
return correct / float(len(actual)) * 100.0
# 对算法数据进行评估
def evaluate_algorithm(dataset, algorithm, n_folds, *args):
"""
:param dataset:list, 原始数据集
:param algorithm:function,算法函数
:param n_folds:int,取多少数据作为训练集
:param args:options ,参数
:return: None
"""
folds = cross_validation_split(dataset, n_folds)
scores = list()
for fold in folds:
train_set = list(folds)
train_set.remove(fold)
# 合并成一个数组
train_set = sum(train_set, [])
test_set = list()
for row in fold:
row_copy = list(row)
test_set.append(row_copy)
row_copy[-1] = None # 将最后一个类型字段设置为None
predicted = algorithm(train_set, test_set, *args)
# 真实的类型
actual = [row[-1] for row in fold]
# 精确的分数,即这一组数据正确率
accuracy = accuracy_metric(actual, predicted)
scores.append(accuracy)
print(scores)
return scores
# 按照分类拆分
def separate_by_class(dataset):
"""
:param dataset:list, 按分类好的列表
:return: dict, 每个分类的每列(属性)的平均值,标准差,个数
"""
separated = dict()
for i in range(len(dataset)):
vector = dataset[i]
class_value = vector[-1]
if (class_value not in separated):
separated[class_value] = list()
separated[class_value].append(vector)
return separated
# 计算这一系列的平均值
def mean(numbers):
return sum(numbers)/float(len(numbers))
# 计算一系列数字的标准差
def stdev(numbers):
avg = mean(numbers)
variance = sum([(x-avg)**2 for x in numbers]) / float(len(numbers)-1)
return sqrt(variance)
# 计算数据集中每列的平均值 标准差 长度
def summarize_dataset(dataset):
summaries = [(mean(column), stdev(column), len(column)) for column in zip(*dataset)]
del(summaries[-1])
return summaries
# 按照分类划分数据集
def summarize_by_class(dataset):
separated = separate_by_class(dataset)
summaries = dict()
for class_value, rows in separated.items():
summaries[class_value] = summarize_dataset(rows)
return summaries
# 计算x的高斯概率
def calculate_probability(x, mean, stdev):
"""
:param x:float, 计算这个值的高斯概率
:param mean:float,x的平均值
:param stdev:float,x的标准差
:return: None
"""
exponent = exp(-((x-mean)**2 / (2 * stdev**2 )))
return (1 / (sqrt(2 * pi) * stdev)) * exponent
# 计算每行的概率
def converge_probabilities(summaries, row):
# 计算所有分类的个数
total_rows = sum([summaries[label][0][2] for label in summaries])
probabilities = dict()
for class_value, class_summaries in summaries.items():
# 计算分类的概率,如这个分类在总分类里概率多少
# 公式中的P(class)
probabilities[class_value] = summaries[class_value][0][2]/float(total_rows)
# 通过公式 P(X1|class=0) * P(X2|class=0) * P(class=0) 计算高斯概率
for i in range(len(class_summaries)):
mean, stdev, _ = class_summaries[i]
probabilities[class_value] *= calculate_probability(row[i], mean, stdev)
return probabilities
# 通过计算出来的值,预测该花属于哪个品种,取高斯概率最大的值
def predict(summaries, row):
probabilities = converge_probabilities(summaries, row)
best_label, best_prob = None, -1
for class_value, probability in probabilities.items():
if best_label is None or probability > best_prob:
best_prob = probability
best_label = class_value
return best_label
# Naive Bayes Algorithm
def naive_bayes(train, test):
# 训练数据按照类分类排序
summarize = summarize_by_class(train)
predictions = list()
for row in test:
output = predict(summarize, row)
predictions.append(output)
print(predictions)
return(predictions)
# 测试
if __name__ == '__main__':
seed(1)
filename = 'iris.csv'
dataset = load_csv(filename)
# 转换数值为float
for i in range(len(dataset[0])-1):
str_column_to_float(dataset, i)
# 将类型转换为数字
str_column_to_int(dataset, len(dataset[0])-1)
# 按照整个数据集分类
model = summarize_by_class(dataset)
# 新加一行预测数据
row = [5.3,3.9,3.2,2.3]
# 根据训练集进行对数据预测
label = predict(model, row)
print('Data=%s, Predicted: %s' % (row, label))

可以看到对数据集
[5.3,3.9,3.2,2.3]预测为
versicolor,那将属性修改为,
[2.3,0.9,0.2,1.3]预测结果为
setosa

还有一些小问题没有搞明白,为什么实现时需要省略掉除法
Reference

- 用PHP实现机器学习:朴素贝叶斯算法
- Matlab2010下使用FULLBNT工具箱实现简单的静态贝叶斯网络及推理
- 机器学习算法python实现---朴素贝叶斯算法(朴素Bayes)
- 用Python Scikit-learn 实现机器学习十大算法--朴素贝叶斯算法(文末有代码)
- python学习---朴素贝叶斯算法的简单实现
- 朴素贝叶斯算法的python实现方法
- Python实现AI推理程序:不到二十行代码
- 一道逻辑推理题的C++实现
- 基于.NET实现数据挖掘--朴素贝叶斯算法
- R 实现朴素贝叶斯算法
- 逻辑推理题-用C++实现(4)--谜语博士的难题1-思考题
- 朴素贝叶斯算法的python实现方法
- ML之RF:利用数据集(客户年龄、职业、婚姻状况、教育水平、违约记录、年账户平均余额、住房贷款、个人贷款)实现预测客户是否购买该银行的产品二分类预测和推理
- 专家系统设计与实现系列 --推理技术
- 贝叶斯网络推理之后验概率问题(基于FullBNT-1.0.4的MATLAB实现)
- 朴素贝叶斯算法Python实现
- 朴素贝叶斯算法(python 实现)
- 逻辑推理题-用C++实现(1)--谁是窃贼
- 用PHP实现机器学习:朴素贝叶斯算法
- 逻辑推理题-用C++实现(2)--黑与白