[源码解析] NVIDIA HugeCTR,GPU版本参数服务器--- (4)
[源码解析] NVIDIA HugeCTR,GPU版本参数服务器--- (4)
[toc]
0x00 摘要
在这个系列中,我们介绍了 HugeCTR,这是一个面向行业的推荐系统训练框架,针对具有模型并行嵌入和数据并行密集网络的大规模 CTR 模型进行了优化。
本文主要介绍流水线的前两级,最后一级将会独立成文。其中借鉴了HugeCTR源码阅读 这篇大作,特此感谢。
本系列其他文章如下:
[源码解析] NVIDIA HugeCTR,GPU 版本参数服务器 --(1)
[源码解析] NVIDIA HugeCTR,GPU版本参数服务器--- (2)
[源码解析] NVIDIA HugeCTR,GPU版本参数服务器---(3)
0x01 总体流程
由于高效的数据交换和三级流水线,HugeCTR的可扩展性和活跃GPU的数量都有所增加。此流水线包括三级:
- 从文件读取数据。
- 从主机到设备的数据传输(节点间和节点内)。
- 利用GPU计算。
的数据读取重叠,并训练GPU。下图显示了HugeCTR的可扩展性,批量大小为16384,在DGX1服务器上有七层。

0x02 DataReader
DataReader 被用来把数据从数据集拷贝到嵌入层。其是流水线的入口,包括了流水线的前面两步骤:读取文件和拷贝到GPU。
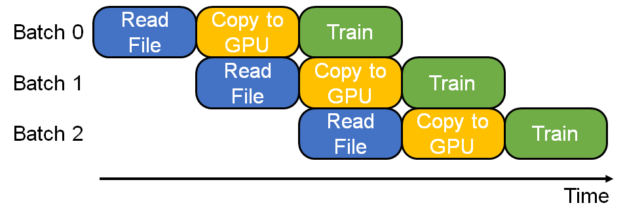
Figure 5. HugeCTR training pipeline with its data reader.
2.1 定义
为了分析需要,我们只给出成员变量,方法我们会在使用时候具体介绍。
从动态角度看,成员变量之中重要的是以下两个:
- worker_group :工作线程组,负责把数据从dataset文件读取到内存之中,这个可以认为是流水线的第一级。之前的版本之中有一个HeapEx数据结构用来做中间缓存,目前这个数据结构已经移除。
- data_collector_ :拥有一个线程,负责把数据拷贝到GPU之中。这个可以认为是流水线的第二级。
从静态角度看,主要是以下三个buffer:
std::vector<std::shared_ptr<ThreadBuffer>> thread_buffers_
:线程内部使用的buffer。std::shared_ptr<BroadcastBuffer> broadcast_buffer_
:用来后续和collector交互,collector 把它作为中间buffer。std::shared_ptr<DataReaderOutput> output_
:reader的输出,训练最后读取的是这里。
以上三个buffer的数据流动是:ThreadBuffer --> BroadcastBuffer ---> DataReaderOutput。
从资源角度看,则是:
- std::shared_ptr resource_manager_ :这是 Session 的成员变量,在DataReader构造函数之中传递进来的。
- const std::vector params_ :这是依据配置文件整理出来的sparse参数元信息。
/**
* @brief Data reading controller.
*
* Control the data reading from data set to embedding.
* An instance of DataReader will maintain independent
* threads for data reading (IDataReaderWorker)
* from dataset to heap. Meanwhile one independent
* thread consumes the data (DataCollector),
* and copy the data to GPU buffer.
*/
template <typename TypeKey>
class DataReader : public IDataReader {
private:
std::vector<std::shared_ptr<ThreadBuffer>> thread_buffers_; // gpu_id -> thread_idx
std::shared_ptr<BroadcastBuffer> broadcast_buffer_;
std::shared_ptr<DataReaderOutput> output_;
std::shared_ptr<DataReaderWorkerGroup> worker_group_;
std::shared_ptr<DataCollector<TypeKey>> data_collector_; /**< pointer of DataCollector */
/* Each gpu will have several csr output for different embedding */
const std::vector<DataReaderSparseParam> params_;
std::shared_ptr<ResourceManager> resource_manager_; /**< gpu resource used in this data reader*/
const size_t batchsize_; /**< batch size */
const size_t label_dim_; /**< dimention of label e.g. 1 for BinaryCrossEntropy */
const size_t dense_dim_; /**< dimention of dense */
long long current_batchsize_;
bool repeat_;
std::string file_name_;
SourceType_t source_type_;
}
2.2 构建
对DataReader的构建分为两部分:
- 在构造函数之中会: 对各种buffer进行配置。
- 对构建DataCollector。
我们先省略对构造函数的分析,因为其牵扯到一系列数据结构。等介绍完数据结构之后,再进行论述。
2.3 DataReaderSparseParam
2.3.1 定义
DataReaderSparseParam 是依据配置得到的Sparse参数的元信息,其主要成员变量如下:
sparse_name
是其后续层引用的稀疏输入张量的名称。没有默认值,应由用户指定。nnz_per_slot
是每个插槽的指定sparse输入的最大特征数。 'nnz_per_slot'可以是'int',即每个slot的平均nnz,因此每个实例的最大功能数应该是'nnz_per_slot*slot_num'。- 或者可以使用List[int]初始化'nnz_per_slot',则每个样本的最大特征数应为'sum(nnz_per_slot)',在这种情况下,数组'nnz_per_slot'的长度应与'slot_num'相同。
'is_fixed_length'用于标识所有样本中每个插槽的categorical inputs是否具有相同的长度。如果不同的样本对于每个插槽具有相同数量的特征,则用户可以设置“is_fixed_length=True”,Hugetr可以使用此信息来减少数据传输时间。
slot_num指定用于数据集中此稀疏输入的插槽数。
-
**注意:**如果指定了多个'DataReaderSparseParam',则任何一对'DataReaderSparseParam'之间都不应有重叠。比如,在[wdl样本](../samples/wdl/wdl.py)中,我们总共有27个插槽;我们将第一个插槽指定为"wide_data",将接下来的26个插槽指定为"deep_data"。
struct DataReaderSparseParam {
std::string top_name;
std::vector<int> nnz_per_slot;
bool is_fixed_length;
int slot_num;
DataReaderSparse_t type;
int max_feature_num;
int max_nnz;
DataReaderSparseParam() {}
DataReaderSparseParam(const std::string& top_name_, const std::vector<int>& nnz_per_slot_,
bool is_fixed_length_, int slot_num_)
: top_name(top_name_),
nnz_per_slot(nnz_per_slot_),
is_fixed_length(is_fixed_length_),
slot_num(slot_num_),
type(DataReaderSparse_t::Distributed) {
max_feature_num = std::accumulate(nnz_per_slot.begin(), nnz_per_slot.end(), 0);
max_nnz = *std::max_element(nnz_per_slot.begin(), nnz_per_slot.end());
}
DataReaderSparseParam(const std::string& top_name_, const int nnz_per_slot_,
bool is_fixed_length_, int slot_num_)
: top_name(top_name_),
nnz_per_slot(slot_num_, nnz_per_slot_),
is_fixed_length(is_fixed_length_),
slot_num(slot_num_),
type(DataReaderSparse_t::Distributed) {
max_feature_num = std::accumulate(nnz_per_slot.begin(), nnz_per_slot.end(), 0);
max_nnz = *std::max_element(nnz_per_slot.begin(), nnz_per_slot.end());
}
};
2.3.2 使用
之前提到了Parser是解析配置文件,HugeCTR 也支持代码设置,比如下面就设定了两个DataReaderSparseParam,也有对应的DistributedSlotSparseEmbeddingHash。
model = hugectr.Model(solver, reader, optimizer)
model.add(hugectr.Input(label_dim = 1, label_name = "label",
dense_dim = 13, dense_name = "dense",
data_reader_sparse_param_array =
[hugectr.DataReaderSparseParam("wide_data", 30, True, 1),
hugectr.DataReaderSparseParam("deep_data", 2, False, 26)]))
model.add(hugectr.SparseEmbedding(embedding_type = hugectr.Embedding_t.DistributedSlotSparseEmbeddingHash,
workspace_size_per_gpu_in_mb = 23,
embedding_vec_size = 1,
combiner = "sum",
sparse_embedding_name = "sparse_embedding2",
bottom_name = "wide_data",
optimizer = optimizer))
model.add(hugectr.SparseEmbedding(embedding_type = hugectr.Embedding_t.DistributedSlotSparseEmbeddingHash,
workspace_size_per_gpu_in_mb = 358,
embedding_vec_size = 16,
combiner = "sum",
sparse_embedding_name = "sparse_embedding1",
bottom_name = "deep_data",
optimizer = optimizer))
0x03 DataReader Buffer 机制
我们接下来看看 DataReader 的若干Buffer,依赖于这些buffer,HugeCTR实现了流水线的前两级。
3.1 比对
我们首先要做一个历史对比,看看这部分代码的发展脉络。我们先看看3.1版本的代码。DataReader 我们选取了部分成员变量。3.1 版本之前使用了一个heap进行操作,即下面的csr_heap_。
class DataReader : public IDataReader {
std::shared_ptr<HeapEx<CSRChunk<TypeKey>>> csr_heap_; /**< heap to cache the data set */
Tensors2<float> label_tensors_; /**< Label tensors for the usage of loss */
std::vector<TensorBag2> dense_tensors_; /**< Dense tensors for the usage of loss */
/* Each gpu will have several csr output for different embedding */
Tensors2<TypeKey> csr_buffers_; /**< csr_buffers contains row_offset_tensor and value_tensors */
Tensors2<TypeKey> row_offsets_tensors_; /**< row offset tensors*/
Tensors2<TypeKey> value_tensors_; /**< value tensors */
std::vector<std::shared_ptr<size_t>> nnz_array_;
const size_t label_dim_; /**< dimention of label e.g. 1 for BinaryCrossEntropy */
const size_t dense_dim_; /**< dimention of dense */
}
我们再看看3.2.1版本的代码,也选取了部分成员变量。
template <typename TypeKey>
class DataReader : public IDataReader {
std::vector<std::shared_ptr<ThreadBuffer>> thread_buffers_; // gpu_id -> thread_idx
std::shared_ptr<BroadcastBuffer> broadcast_buffer_;
std::shared_ptr<DataReaderOutput> output_;
const size_t label_dim_; /**< dimention of label e.g. 1 for BinaryCrossEntropy */
const size_t dense_dim_; /**< dimention of dense */
}
3.2.1 这里是:
- 把
label_tensors_
,dense_tensors_
移动到 AsyncReader。 - 把 csr_heap_ 用
thread_buffers_
,broadcast_buffer_
,output_
等进行替代。 - 把 row_offsets_tensors_,value_tensors_,nnz_array_ 等等用 ThreadBuffer,BroadcastBuffer,DataReaderOutput 之中的 SparseTensorBag 来包括,统一管理 CSR。
3.2 Buffer 相关类
我们依据上面的历史版本比对来看看。
- 在之前版本(比如3.1)之中,存在一个 HeapEX 类,其实现了 CPU 到 GPU 之间的一个数据缓存功能。
- 在最新版本之中,改为一系列 buffer 相关类,比如 ThreadBuffer 和 BroadcastBuffer,其状态都是由 BufferState 实现的。
enum class BufferState : int { FileEOF, Reading, ReadyForRead, Writing, ReadyForWrite };
以下是三个buffer的定义。
struct ThreadBuffer {
std::vector<SparseTensorBag> device_sparse_buffers; // same number as embedding number
std::vector<unsigned char> is_fixed_length; // same number as embedding number
TensorBag2 device_dense_buffers;
std::atomic<BufferState> state;
long long current_batch_size;
int batch_size;
size_t param_num;
int label_dim;
int dense_dim;
int batch_size_start_idx; // dense buffer
int batch_size_end_idx;
};
struct BroadcastBuffer {
std::vector<SparseTensorBag>
sparse_buffers; // same number as (embedding number * local device number)
std::vector<unsigned char> is_fixed_length; // same number as embedding number
std::vector<TensorBag2> dense_tensors; // same number as local device number
std::vector<cudaEvent_t> finish_broadcast_events; // same number as local device number
std::atomic<BufferState> state;
long long current_batch_size;
size_t param_num;
};
struct DataReaderOutput {
std::map<std::string, std::vector<SparseTensorBag>> sparse_tensors_map;
std::vector<std::string> sparse_name_vec;
std::vector<TensorBag2> label_tensors;
std::vector<TensorBag2> dense_tensors;
bool use_mixed_precision;
int label_dense_dim;
};
以上这些类,对应了 DataReader 的以下成员变量。
class DataReader : public IDataReader {
private:
std::vector<std::shared_ptr<ThreadBuffer>> thread_buffers_; // gpu_id -> thread_idx
std::shared_ptr<BroadcastBuffer> broadcast_buffer_;
std::shared_ptr<DataReaderOutput> output_;
}
接下来,我们就一一分析。
3.3 DataReader构造
前面跳过了 DataReader 的构造函数,接下来我们接下来对构造函数进行分析,其主要功能就是为三种buffer来预留空间,分配内存,最后构建了collector。
DataReader(int batchsize, size_t label_dim, int dense_dim,
std::vector<DataReaderSparseParam> ¶ms,
const std::shared_ptr<ResourceManager> &resource_manager, bool repeat, int num_threads,
bool use_mixed_precision)
: broadcast_buffer_(new BroadcastBuffer()),
output_(new DataReaderOutput()),
params_(params),
resource_manager_(resource_manager),
batchsize_(batchsize),
label_dim_(label_dim),
dense_dim_(dense_dim),
repeat_(repeat) {
size_t local_gpu_count = resource_manager_->get_local_gpu_count();
size_t total_gpu_count = resource_manager_->get_global_gpu_count();
// batchsize_ is a multiple of total_gpu_count
size_t batch_size_per_gpu = batchsize_ / total_gpu_count;
// 1. 生成了一个临时变量buffs,用来具体分配内存,里面是若干 CudaAllocator,每个CudaAllocator对应了i个GPU
std::vector<std::shared_ptr<GeneralBuffer2<CudaAllocator>>> buffs;
// 先预留部分内存空间
buffs.reserve(local_gpu_count);
// 为每个GPU初始化一个GeneralBuffer2
for (size_t i = 0; i < local_gpu_count; ++i) {
buffs.push_back(GeneralBuffer2<CudaAllocator>::create());
}
// 2.预留buffer
// 处理 thread_buffers_
thread_buffers_.reserve(num_threads);
for (int i = 0; i < num_threads; ++i) {
// a worker may maintain multiple buffers on device i % local_gpu_count
auto local_gpu = resource_manager_->get_local_gpu(i % local_gpu_count);
CudaCPUDeviceContext context(local_gpu->get_device_id());
auto &buff = buffs[i % local_gpu_count]; // 找到对应GPU对应的CudaAllocator,进行分配
std::shared_ptr<ThreadBuffer> current_thread_buffer = std::make_shared<ThreadBuffer>();
thread_buffers_.push_back(current_thread_buffer);
current_thread_buffer->device_sparse_buffers.reserve(params.size());
current_thread_buffer->is_fixed_length.reserve(params.size()); // vector的reserve
for (size_t param_id = 0; param_id < params.size(); ++param_id) {
auto ¶m = params_[param_id];
SparseTensor<TypeKey> temp_sparse_tensor;
// 预留内存
buff->reserve({(size_t)batchsize, (size_t)param.max_feature_num}, param.slot_num,
&temp_sparse_tensor);
current_thread_buffer->device_sparse_buffers.push_back(temp_sparse_tensor.shrink());
current_thread_buffer->is_fixed_length.push_back(param.is_fixed_length);
}
Tensor2<float> temp_dense_tensor;
// 预留内存
buff->reserve({batch_size_per_gpu * local_gpu_count, label_dim + dense_dim},
&temp_dense_tensor);
current_thread_buffer->device_dense_buffers = temp_dense_tensor.shrink();
current_thread_buffer->state.store(BufferState::ReadyForWrite);
current_thread_buffer->current_batch_size = 0;
current_thread_buffer->batch_size = batchsize;
current_thread_buffer->param_num = params.size();
current_thread_buffer->label_dim = label_dim;
current_thread_buffer->dense_dim = dense_dim;
current_thread_buffer->batch_size_start_idx =
batch_size_per_gpu * resource_manager_->get_gpu_global_id_from_local_id(0);
current_thread_buffer->batch_size_end_idx =
current_thread_buffer->batch_size_start_idx + batch_size_per_gpu * local_gpu_count;
}
// 处理 broadcast buffer,注意这里的reserve是 vector数据结构的方法,不是预留内存
broadcast_buffer_->sparse_buffers.reserve(local_gpu_count * params.size());
broadcast_buffer_->is_fixed_length.reserve(local_gpu_count * params.size());
broadcast_buffer_->dense_tensors.reserve(local_gpu_count);
broadcast_buffer_->finish_broadcast_events.resize(local_gpu_count);
broadcast_buffer_->state.store(BufferState::ReadyForWrite);
broadcast_buffer_->current_batch_size = 0;
broadcast_buffer_->param_num = params.size();
// 处理 output buffer,注意这里的reserve是 vector数据结构的方法,不是预留内存
output_->dense_tensors.reserve(local_gpu_count);
output_->label_tensors.reserve(local_gpu_count);
output_->use_mixed_precision = use_mixed_precision;
output_->label_dense_dim = label_dim + dense_dim;
// 预留sparse tensor,注意这里的reserve是 vector数据结构的方法,不是预留内存
for (size_t param_id = 0; param_id < params.size(); ++param_id) {
auto ¶m = params_[param_id];
output_->sparse_tensors_map[param.top_name].reserve(local_gpu_count);
output_->sparse_name_vec.push_back(param.top_name);
}
// 遍历本地的 GPU
for (size_t local_id = 0; local_id < local_gpu_count; ++local_id) {
// 还是需要针对每一个GPU,找到对应的CudaAllocator进行分配
auto local_gpu = resource_manager_->get_local_gpu(local_id);
CudaDeviceContext ctx(local_gpu->get_device_id());
auto &buff = buffs[local_id];
for (size_t param_id = 0; param_id < params.size(); ++param_id) {
auto ¶m = params_[param_id];
SparseTensor<TypeKey> temp_sparse_tensor;
// 给broadcast_buffer_分配内存
buff->reserve({(size_t)batchsize, (size_t)param.max_feature_num}, param.slot_num,
&temp_sparse_tensor);
broadcast_buffer_->sparse_buffers.push_back(temp_sparse_tensor.shrink());
broadcast_buffer_->is_fixed_length.push_back(param.is_fixed_length);
}
Tensor2<float> temp_dense_tensor;
buff->reserve({batch_size_per_gpu, label_dim + dense_dim}, &temp_dense_tensor);
broadcast_buffer_->dense_tensors.push_back(temp_dense_tensor.shrink());
CK_CUDA_THROW_(cudaEventCreateWithFlags(&broadcast_buffer_->finish_broadcast_events[local_id],
cudaEventDisableTiming));
for (size_t param_id = 0; param_id < params.size(); ++param_id) {
auto ¶m = params_[param_id];
SparseTensor<TypeKey> temp_sparse_tensor;
// 预留内存
buff->reserve({(size_t)batchsize, (size_t)param.max_feature_num}, param.slot_num,
&temp_sparse_tensor);
output_->sparse_tensors_map[param.top_name].push_back(temp_sparse_tensor.shrink());
}
Tensor2<float> label_tensor;
// 预留内存
buff->reserve({batch_size_per_gpu, label_dim}, &label_tensor);
output_->label_tensors.push_back(label_tensor.shrink());
if (use_mixed_precision) {
Tensor2<__half> dense_tensor;
// 预留内存
buff->reserve({(size_t)batch_size_per_gpu, (size_t)dense_dim}, &dense_tensor);
output_->dense_tensors.push_back(dense_tensor.shrink());
} else {
Tensor2<float> dense_tensor;
// 预留内存
buff->reserve({(size_t)batch_size_per_gpu, (size_t)dense_dim}, &dense_tensor);
output_->dense_tensors.push_back(dense_tensor.shrink());
}
buff->allocate(); // 3. 分配内存
}
// 4. 构建DataCollector
data_collector_ = std::make_shared<DataCollector<TypeKey>>(thread_buffers_, broadcast_buffer_,
output_, resource_manager);
return;
}
我们接下来会仔细分一下构造代码之中的各个部分。
3.3.1 辅助 GeneralBuffer2
首先我们分析上面代码之中buffs部分,这个变量作用就是统一分配内存。
// 1. 生成了一个临时变量buffs
std::vector<std::shared_ptr<GeneralBuffer2<CudaAllocator>>> buffs;
// 先预留部分容量大小
buffs.reserve(local_gpu_count);
// 为每个GPU初始化一个GeneralBuffer2
for (size_t i = 0; i < local_gpu_count; ++i) {
buffs.push_back(GeneralBuffer2<CudaAllocator>::create());
}
3.3.2 ThreadBuffer
然后我们看看处理 thread_buffers_ 部分,这里是为线程buffer进行处理。我们首先获取ThreadBuffer类定义如下,后面分析时候可以比对。
struct ThreadBuffer {
std::vector<SparseTensorBag> device_sparse_buffers; // same number as embedding number
std::vector<unsigned char> is_fixed_length; // same number as embedding number
TensorBag2 device_dense_buffers;
std::atomic<BufferState> state;
long long current_batch_size;
int batch_size;
size_t param_num;
int label_dim;
int dense_dim;
int batch_size_start_idx; // dense buffer
int batch_size_end_idx;
};
其次,具体构建函数中的逻辑如下:
- 首先,对于 thread_buffers_ 这个vector,会拓展 vector 容量到线程数大小。
- 拿到本线程(或者说是本GPU)在buffs之中对应的buffer,赋值到 buff。
- 对于每一个线程,会生成一个ThreadBuffer,命名为current_thread_buffer,放入到 thread_buffers_ 之中。
- 对于每一个 ThreadBuffer,预留 ThreadBuffer 的device_sparse_buffers 和 is_fixed_length 这两个 vector 的容量大小。
- 遍历sparse参数,对于每一个参数,会建立一个临时张量,并且通过 buff 预留内存(CPU或者GPU),然后把此临时张量放入device_sparse_buffers。
- 建立一个针对dense的张量,并且通过 buff 预留张量内存,把临时张量放入device_dense_buffers。
- 设置current_thread_buffer 状态。
- 设置 current_thread_buffer 其他信息。
// 处理 thread_buffers_,会拓展 vector 容量到线程数大小
thread_buffers_.reserve(num_threads);
for (int i = 0; i < num_threads; ++i) { // 遍历线程
// a worker may maintain multiple buffers on device i % local_gpu_count
auto local_gpu = resource_manager_->get_local_gpu(i % local_gpu_count);
CudaCPUDeviceContext context(local_gpu->get_device_id());
auto &buff = buffs[i % local_gpu_count]; // 拿到本线程(或者说是本GPU)在buffs之中对应的buffer
// 生成一个ThreadBuffer,存入到thread_buffers_
std::shared_ptr<ThreadBuffer> current_thread_buffer = std::make_shared<ThreadBuffer>();
thread_buffers_.push_back(current_thread_buffer);
// 预留 ThreadBuffer 的device_sparse_buffers 和 is_fixed_length 这两个 vector 的容量大小
current_thread_buffer->device_sparse_buffers.reserve(params.size());
current_thread_buffer->is_fixed_length.reserve(params.size());
// 遍历参数
for (size_t param_id = 0; param_id < params.size(); ++param_id) {
auto ¶m = params_[param_id];
SparseTensor<TypeKey> temp_sparse_tensor;
// 建立一个临时张量,并且预留内存(CPU或者GPU)
buff->reserve({(size_t)batchsize, (size_t)param.max_feature_num}, param.slot_num,
&temp_sparse_tensor);
// 把张量放入device_sparse_buffers
current_thread_buffer->device_sparse_buffers.push_back(temp_sparse_tensor.shrink());
current_thread_buffer->is_fixed_length.push_back(param.is_fixed_length);
}
// 建立一个针对dense的张量
Tensor2<float> temp_dense_tensor;
// 预留张量内存
buff->reserve({batch_size_per_gpu * local_gpu_count, label_dim + dense_dim},
&temp_dense_tensor);
// 把临时张量放入device_dense_buffers
current_thread_buffer->device_dense_buffers = temp_dense_tensor.shrink();
// 设置状态
current_thread_buffer->state.store(BufferState::ReadyForWrite);
// 设置其他信息
current_thread_buffer->current_batch_size = 0;
current_thread_buffer->batch_size = batchsize;
current_thread_buffer->param_num = params.size();
current_thread_buffer->label_dim = label_dim;
current_thread_buffer->dense_dim = dense_dim;
current_thread_buffer->batch_size_start_idx =
batch_size_per_gpu * resource_manager_->get_gpu_global_id_from_local_id(0);
current_thread_buffer->batch_size_end_idx =
current_thread_buffer->batch_size_start_idx + batch_size_per_gpu * local_gpu_count;
}
此时如下,注意,DataReader 包括多个 ThreadBuffer。

3.3.3 BroadcastBuffer
接下来看看如何构建BroadcastBuffer。
BroadcastBuffer定义如下:
struct BroadcastBuffer {
std::vector<SparseTensorBag>
sparse_buffers; // same number as (embedding number * local device number)
std::vector<unsigned char> is_fixed_length; // same number as embedding number
std::vector<TensorBag2> dense_tensors; // same number as local device number
std::vector<cudaEvent_t> finish_broadcast_events; // same number as local device number
std::atomic<BufferState> state;
long long current_batch_size;
size_t param_num;
};
按照构建代码来说,这里只是做了一些预留和设置,没有涉及内存,内存在后续会统一处理。
// 处理 broadcast buffer // 预留vector的容量 broadcast_buffer_->sparse_buffers.reserve(local_gpu_count * params.size()); // 预留vector的容量 broadcast_buffer_->is_fixed_length.reserve(local_gpu_count * params.size()); // 预留vector的容量 broadcast_buffer_->dense_tensors.reserve(local_gpu_count); broadcast_buffer_->finish_broadcast_events.resize(local_gpu_count); // 设置状态 broadcast_buffer_->state.store(BufferState::ReadyForWrite); broadcast_buffer_->current_batch_size = 0; broadcast_buffer_->param_num = params.size();
3.3.4 DataReaderOutput
我们接着看看如何构建DataReaderOutput。
struct DataReaderOutput {
std::map<std::string, std::vector<SparseTensorBag>> sparse_tensors_map;
std::vector<std::string> sparse_name_vec;
std::vector<TensorBag2> label_tensors;
std::vector<TensorBag2> dense_tensors;
bool use_mixed_precision;
int label_dense_dim;
};
按照构建代码来说,这里只是做了一些预留和设置,没有涉及内存,内存在后续会统一处理。
output_->dense_tensors.reserve(local_gpu_count); // 预留vector的容量
output_->label_tensors.reserve(local_gpu_count); // 预留vector的容量
output_->use_mixed_precision = use_mixed_precision;
output_->label_dense_dim = label_dim + dense_dim;
for (size_t param_id = 0; param_id < params.size(); ++param_id) {
auto ¶m = params_[param_id];
output_->sparse_tensors_map[param.top_name].reserve(local_gpu_count);
output_->sparse_name_vec.push_back(param.top_name);
}
3.3.5 预留和分配
这里会对 broadcast 和 output 进行预留,这里统一分配内存。
for (size_t local_id = 0; local_id < local_gpu_count; ++local_id) { // 遍历GPU
auto local_gpu = resource_manager_->get_local_gpu(local_id);
CudaDeviceContext ctx(local_gpu->get_device_id());
auto &buff = buffs[local_id]; // 获取临时buffs之中对应某一个本地gpu的allocator
for (size_t param_id = 0; param_id < params.size(); ++param_id) {
auto ¶m = params_[param_id];
SparseTensor<TypeKey> temp_sparse_tensor;
// 分配sparse内存
buff->reserve({(size_t)batchsize, (size_t)param.max_feature_num}, param.slot_num,
&temp_sparse_tensor);
// 赋值到broadcast 之上
broadcast_buffer_->sparse_buffers.push_back(temp_sparse_tensor.shrink());
broadcast_buffer_->is_fixed_length.push_back(param.is_fixed_length);
}
// 分配dense内存
Tensor2<float> temp_dense_tensor;
buff->reserve({batch_size_per_gpu, label_dim + dense_dim}, &temp_dense_tensor);
// 赋值到broadcast 之上
broadcast_buffer_->dense_tensors.push_back(temp_dense_tensor.shrink());
CK_CUDA_THROW_(cudaEventCreateWithFlags(&broadcast_buffer_->finish_broadcast_events[local_id],
cudaEventDisableTiming));
for (size_t param_id = 0; param_id < params.size(); ++param_id) {
auto ¶m = params_[param_id];
// 分配sparse内存
SparseTensor<TypeKey> temp_sparse_tensor;
buff->reserve({(size_t)batchsize, (size_t)param.max_feature_num}, param.slot_num,
&temp_sparse_tensor);
// 赋值到output之上
output_->sparse_tensors_map[param.top_name].push_back(temp_sparse_tensor.shrink());
}
// 分配label的内存
Tensor2<float> label_tensor;
buff->reserve({batch_size_per_gpu, label_dim}, &label_tensor);
// 赋值到output之上
output_->label_tensors.push_back(label_tensor.shrink());
if (use_mixed_precision) {
Tensor2<__half> dense_tensor;
// 分配dense内存
buff->reserve({(size_t)batch_size_per_gpu, (size_t)dense_dim}, &dense_tensor);
// 赋值到output之上
output_->dense_tensors.push_back(dense_tensor.shrink());
} else {
Tensor2<float> dense_tensor;
// 分配dense内存
buff->reserve({(size_t)batch_size_per_gpu, (size_t)dense_dim}, &dense_tensor);
// 赋值到output之上
output_->dense_tensors.push_back(dense_tensor.shrink());
}
buff->allocate(); // 统一分配
}
预留buffer的具体逻辑如下:

分配之后如下,需要注意的是,这里都是简化版本,没有体现出来多个本地GPU的状态。比如下面三个类的成员变量都会分配到多个本地GPU之上。
// embedding number 指的是本模型之中,DataReaderSparseParam 的个数,就是有几个 embedding 层
struct ThreadBuffer {
std::vector<SparseTensorBag> device_sparse_buffers; // same number as embedding number
// device_sparse_buffers 会分配在多个本地GPU之上
struct BroadcastBuffer {
std::vector<SparseTensorBag>
sparse_buffers; // same number as (embedding number * local device number)
// sparse_buffers 也会分配在多个本地GPU之上
struct DataReaderOutput {
std::map<std::string, std::vector<SparseTensorBag>> sparse_tensors_map;
// 每个 sparse_tensors_map[param.top_name] 都会分配在多个本地GPU之上
// 比如 output_->sparse_tensors_map[param.top_name].reserve(local_gpu_count);
如下简化版本之中都只体现了一个GPU,这些buffer都是位于GPU之上。

现在 DataReader 有了一系列buffer,我们接下来看看如何使用。
0x04 DataReaderWorkerGroup
DataReaderWorkerGroup 负责具体读数据操作。
4.1 构建
在 create_datareader 之中,有如下代码建立 DataReaderWorkerGroup,分别对应了三种group。
switch (format) {
case DataReaderType_t::Norm: {
train_data_reader->create_drwg_norm(source_data, check_type, start_right_now);
evaluate_data_reader->create_drwg_norm(eval_source, check_type, start_right_now);
break;
}
case DataReaderType_t::Raw: {
train_data_reader->create_drwg_raw(source_data, num_samples, float_label_dense, true,
false);
evaluate_data_reader->create_drwg_raw(eval_source, eval_num_samples, float_label_dense,
false, false);
break;
}
case DataReaderType_t::Parquet: {
train_data_reader->create_drwg_parquet(source_data, slot_offset, true);
evaluate_data_reader->create_drwg_parquet(eval_source, slot_offset, true);
break;
}
我们用create_drwg_norm来继续分析,发现其构建了DataReaderWorkerGroupNorm。即,配置了 DataReader 之中的成员变量 worker_group_ 为一个 DataReaderWorkerGroupNorm。
注意,这里传入的是
thread_buffers_,说明
DataReaderWorkerGroup操作的就是DataReader 的
thread_buffers_。
void create_drwg_norm(std::string file_name, Check_t check_type,
bool start_reading_from_beginning = true) override {
source_type_ = SourceType_t::FileList;
worker_group_.reset(new DataReaderWorkerGroupNorm<TypeKey>(
thread_buffers_, resource_manager_, file_name, repeat_, check_type, params_,
start_reading_from_beginning));
file_name_ = file_name;
}
4.2 DataReaderWorkerGroup 定义
我们只看其成员变量,主要是 IDataReaderWorker,这就是具体读数据的wroker。
class DataReaderWorkerGroup {
std::vector<std::thread> data_reader_threads_; /**< A vector of the pointers of data reader .*/
protected:
int data_reader_loop_flag_{0}; /**< p_loop_flag a flag to control the loop */
DataReaderType_t data_reader_type_;
std::vector<std::shared_ptr<IDataReaderWorker>>
data_readers_; /**< A vector of DataReaderWorker' pointer.*/
std::shared_ptr<ResourceManager> resource_manager_;
}
4.3 DataReaderWorkerGroupNorm
我们使用 DataReaderWorkerGroupNorm 来分析,其最重要的是构建 DataReaderWorker 时候,设定了每个DataReaderWorker 对应哪些GPU资源。
template <typename TypeKey>
class DataReaderWorkerGroupNorm : public DataReaderWorkerGroup {
std::string file_list_; /**< file list of data set */
std::shared_ptr<Source> create_source(size_t worker_id, size_t num_worker,
const std::string &file_name, bool repeat) override {
return std::make_shared<FileSource>(worker_id, num_worker, file_name, repeat);
}
public:
// Ctor
DataReaderWorkerGroupNorm(const std::vector<std::shared_ptr<ThreadBuffer>> &output_buffers,
const std::shared_ptr<ResourceManager> &resource_manager_,
std::string file_list, bool repeat, Check_t check_type,
const std::vector<DataReaderSparseParam> ¶ms,
bool start_reading_from_beginning = true)
: DataReaderWorkerGroup(start_reading_from_beginning, DataReaderType_t::Norm) {
int num_threads = output_buffers.size();
size_t local_gpu_count = resource_manager_->get_local_gpu_count();
// create data reader workers
int max_feature_num_per_sample = 0;
for (auto ¶m : params) {
max_feature_num_per_sample += param.max_feature_num;
}
set_resource_manager(resource_manager_);
for (int i = 0; i < num_threads; i++) {
std::shared_ptr<IDataReaderWorker> data_reader(new DataReaderWorker<TypeKey>(
// 这里设定了每个 DataReaderWorker 对应的 GPU 资源
i, num_threads, resource_manager_->get_local_gpu(i % local_gpu_count),
&data_reader_loop_flag_, output_buffers[i], file_list, max_feature_num_per_sample, repeat,
check_type, params));
data_readers_.push_back(data_reader);
}
create_data_reader_threads(); // 建立了多个工作线程
}
};
4.4 建立线程
create_data_reader_threads 建立了多个工作线程,设定了每个线程对应的 GPU 资源。
/**
* Create threads to run data reader workers
*/
void create_data_reader_threads() {
size_t local_gpu_count = resource_manager_->get_local_gpu_count();
for (size_t i = 0; i < data_readers_.size(); ++i) {
// 这里设定了每个线程对应的 GPU 资源
auto local_gpu = resource_manager_->get_local_gpu(i % local_gpu_count);
// 指定了线程主体函数
data_reader_threads_.emplace_back(data_reader_thread_func_, data_readers_[i],
&data_reader_loop_flag_, local_gpu->get_device_id());
}
}
4.5 线程主体函数
data_reader_thread_func_ 是工作线程的主体函数,里面设定了本线程的设备,然后调用了 IDataReaderWorker 完成读取数据。
/**
* A helper function to read data from dataset to heap in a new thread.
* @param data_reader a pointer of data_reader.
* @param p_loop_flag a flag to control the loop,
and break loop when IDataReaderWorker is destroyed.
*/
static void data_reader_thread_func_(const std::shared_ptr<IDataReaderWorker>& data_reader,
int* p_loop_flag, int device_id) {
try {
CudaCPUDeviceContext context(device_id); // 设定了本线程的设备
while ((*p_loop_flag) == 0) {
usleep(2);
}
while (*p_loop_flag) {
data_reader->read_a_batch(); // 然后开始读取文件数据
}
} catch (const std::runtime_error& rt_err) {
std::cerr << rt_err.what() << std::endl;
}
}
所以,这里就设定了哪个样本应该放到哪个卡上,例如,下面4个线程,分别对应了 GPU 0 和 GPU 1。

4.6 DataReaderWorker
DataReaderWorker 是解析数据的业务模块。IDataReaderWorker 是 基类,其buffer_是关键,其指向了ThreadBuffer。
class IDataReaderWorker {
std::shared_ptr<Source> source_; /**< source: can be file or network */
int worker_id_;
int worker_num_;
std::shared_ptr<GPUResource> gpu_resource_; // 这是本worker的GPU资源
bool is_eof_;
int *loop_flag_;
std::shared_ptr<ThreadBuffer> buffer_;
IDataReaderWorker(const int worker_id, const int worker_num,
const std::shared_ptr<GPUResource> &gpu_resource, bool is_eof, int *loop_flag,
const std::shared_ptr<ThreadBuffer> &buff)
: worker_id_(worker_id),
worker_num_(worker_num),
gpu_resource_(gpu_resource), // 设定GPU资源
is_eof_(is_eof),
loop_flag_(loop_flag),
buffer_(buff) {}
};
DataReaderWorker 具体定义如下:
template <class T>
class DataReaderWorker : public IDataReaderWorker {
private:
DataSetHeader
data_set_header_; /**< the header of data set, which has main informations of a data file */
size_t buffer_length_; /**< buffer size for internal use */
Check_t check_type_; /**< check type for data set */
std::vector<DataReaderSparseParam> params_; /**< configuration of data reader sparse input */
std::shared_ptr<Checker> checker_; /**< checker aim to perform error check of the input data */
bool skip_read_{false}; /**< set to true when you want to stop the data reading */
int current_record_index_{0};
size_t total_slot_num_;
std::vector<size_t> last_batch_nnz_;
Tensor2<float> temp_host_dense_buffer_; // read data to make checker move
Tensor2<float> host_dense_buffer_;
std::vector<CSR<T>> host_sparse_buffer_;
}
其构建代码如下,需要注意,
- 有一个继承于基类的变量 std::shared_ptr buffer_ 指向的是 ThreadBuffer。
- 变量 host_sparse_buffer_ 是构建在 Host 之上,而非GPU之上,这个 host_sparse_buffer_ 作用是文件中读取数据,解析成csr,放置到 host_sparse_buffer_ 之上。
- 关于变量 DataReaderSparseParam 的说明,这是一个DataReaderSparseParam 数组,如果做如下设置,则 params_ 包含三个元素,分别对应分了 user, good, cate。
model.add(hugectr.Input(label_dim = 1, label_name = "label",
dense_dim = 0, dense_name = "dense",
data_reader_sparse_param_array =
[hugectr.DataReaderSparseParam("UserID", 1, True, 1),
hugectr.DataReaderSparseParam("GoodID", 1, True, 11),
hugectr.DataReaderSparseParam("CateID", 1, True, 11)]))
DataReaderWorker 具体定义如下:
DataReaderWorker(const int worker_id, const int worker_num,
const std::shared_ptr<GPUResource>& gpu_resource, int* loop_flag,
const std::shared_ptr<ThreadBuffer>& buffer, const std::string& file_list,
size_t buffer_length, bool repeat, Check_t check_type,
const std::vector<DataReaderSparseParam>& params)
: IDataReaderWorker(worker_id, worker_num, gpu_resource, !repeat, loop_flag, buffer),
buffer_length_(buffer_length),
check_type_(check_type),
params_(params),
total_slot_num_(0),
last_batch_nnz_(params.size(), 0) {
total_slot_num_ = 0;
for (auto& p : params) {
total_slot_num_ += p.slot_num;
}
source_ = std::make_shared<FileSource>(worker_id, worker_num, file_list, repeat);
create_checker();
int batch_size = buffer->batch_size;
int batch_size_start_idx = buffer->batch_size_start_idx;
int batch_size_end_idx = buffer->batch_size_end_idx;
int label_dim = buffer->label_dim;
int dense_dim = buffer->dense_dim;
CudaCPUDeviceContext ctx(gpu_resource->get_device_id()); // 得到了本worker对应哪个GPU
std::shared_ptr<GeneralBuffer2<CudaHostAllocator>> buff =
GeneralBuffer2<CudaHostAllocator>::create();
buff->reserve({static_cast<size_t>(batch_size_end_idx - batch_size_start_idx),
static_cast<size_t>(label_dim + dense_dim)},
&host_dense_buffer_);
buff->reserve({static_cast<size_t>(label_dim + dense_dim)}, &temp_host_dense_buffer_);
for (auto& param : params) {
host_sparse_buffer_.emplace_back(batch_size * param.slot_num,
batch_size * param.max_feature_num);
}
buff->allocate();
}
具体拓展如下,其中每个thread里面含有一个worker:

或者我们进一步简化几个内存类,得到如下,DataReaderWorker 操作 DataReader 之中的一个 ThreadBuffer,

4.7 读取数据
Reader构建时候,会建立一个 checker_,用来从文件读取数据。
4.7.1 Checker
void create_checker() {
switch (check_type_) {
case Check_t::Sum:
checker_ = std::make_shared<CheckSum>(*source_);
break;
case Check_t::None:
checker_ = std::make_shared<CheckNone>(*source_);
break;
default:
assert(!"Error: no such Check_t && should never get here!!");
}
}
以 CheckNone 为例,可以看到其就是读取文件。
class CheckNone : public Checker {
private:
const int MAX_TRY{10};
public:
CheckNone(Source& src) : Checker(src) {}
/**
* Read "bytes_to_read" byte to the memory associated to ptr.
* Users don't need to manualy maintain the check bit offset, just specify
* number of bytes you really want to see in ptr.
* @param ptr pointer to user located buffer
* @param bytes_to_read bytes to read
* @return `DataCheckError` `OutOfBound` `Success` `UnspecificError`
*/
Error_t read(char* ptr, size_t bytes_to_read) noexcept {
try {
Checker::src_.read(ptr, bytes_to_read);
return Error_t::Success;
} catch (const std::runtime_error& rt_err) {
std::cerr << rt_err.what() << std::endl;
return Error_t::BrokenFile;
}
}
/**
* Start a new file to read.
* @return `FileCannotOpen` or `UnspecificError`
*/
Error_t next_source() {
for (int i = MAX_TRY; i > 0; i--) {
Error_t flag_eof = Checker::src_.next_source();
if (flag_eof == Error_t::Success || flag_eof == Error_t::EndOfFile) {
return flag_eof;
}
}
CK_THROW_(Error_t::FileCannotOpen, "Checker::src_.next_source() == Error_t::Success failed");
return Error_t::FileCannotOpen; // to elimate compile error
}
};
4.7.2 CSR 样例
我们从 samples/ncf/preprocess-1m.py 之中找出一个代码来看看 csr 文件的格式。
def write_hugeCTR_data(huge_ctr_data, filename='huge_ctr_data.dat'): with open(filename, 'wb') as f: #write header f.write(ll(0)) # 0: no error check; 1: check_num f.write(ll(huge_ctr_data.shape[0])) # the number of samples in this data file f.write(ll(1)) # dimension of label f.write(ll(1)) # dimension of dense feature f.write(ll(2)) # long long slot_num for _ in range(3): f.write(ll(0)) # reserved for future use for i in tqdm.tqdm(range(huge_ctr_data.shape[0])): f.write(c_float(huge_ctr_data[i,2])) # float label[label_dim]; f.write(c_float(0)) # dummy dense feature f.write(c_int(1)) # slot 1 nnz: user ID f.write(c_uint(huge_ctr_data[i,0])) f.write(c_int(1)) # slot 2 nnz: item ID f.write(c_uint(huge_ctr_data[i,1]))
4.7.3 读取批次数据
read_a_batch 完成具体解析数据集工作。
- 首先从文件读取数据。
- 等待 ThreadBuffer(就是DataReader的thread_buffers_成员变量)的状态变成ReadyForWrite。
- 解析成csr,放入到 host_dense_buffer_。
- 调用 wait_until_h2d_ready 等待拷贝完成。
- 其次调用cudaMemcpyAsync把数据从 host_dense_buffer_ 拷贝到 ThreadBuffer 之中。这里有两点很重要: 目前数据在 host_sparse_buffer_(CPU)之上,需要拷贝到 GPU(目标是 ThreadBuffer 的 device_sparse_buffers 成员变量)。
- 而且,host_sparse_buffer_ 是 CSR 格式,ThreadBuffer 的 device_sparse_buffers 成员变量是SparseTensor格式,需要转换。
- 这里是通过拷贝就进行了转换。
有几点如下:
- nnz 的意思是:non-zero feature number。
- 每一个slot数据对应了一个CSR row。
具体代码如下:
/**
* read a batch of data from data set to heap.
*/
void read_a_batch() {
// 得到各种配置
long long current_batch_size = buffer_->batch_size;
int label_dim = buffer_->label_dim;
int dense_dim = buffer_->dense_dim;
int label_dense_dim = label_dim + dense_dim;
int batch_size_start_idx = buffer_->batch_size_start_idx;
int batch_size_end_idx = buffer_->batch_size_end_idx;
try {
if (!checker_->is_open()) {
read_new_file(); // 读一个新文件
}
} catch (const internal_runtime_error& rt_err) {
Error_t err = rt_err.get_error();
if (err == Error_t::EndOfFile) { // 文件读完了
if (!wait_until_h2d_ready()) return; // 等待 buffer_ 状态变为 ReadyForWrite
buffer_->current_batch_size = 0;
assert(buffer_->state.load() == BufferState::Writing); // 设置
is_eof_ = true;
buffer_->state.store(BufferState::ReadyForRead); // 设置状态为可读
while (buffer_->state.load() != BufferState::ReadyForWrite) {
usleep(2);
if (*loop_flag_ == 0) return; // in case main thread exit
}
return; // need this return to run from begining
} else {
throw;
}
}
// if the EOF is faced, the current batch size can be changed later
for (auto& each_csr : host_sparse_buffer_) {
each_csr.reset();
}
// batch loop
for (int batch_idx = 0; batch_idx < buffer_->batch_size; ++batch_idx) {//读取batch中一个
if (batch_idx >= current_batch_size) { // 如果已经读取batch之中的全部数据了
for (size_t param_id = 0; param_id < params_.size(); ++param_id) { // 多个embedding
// 如果是前面那个例子,这里遍历的就是user, good, cate
auto& param = params_[param_id];
// host_sparse_buffer_类型是std::vector<CSR<T>>
auto& current_csr = host_sparse_buffer_[param_id];
for (int k = 0; k < param.slot_num; k++) { // slot数目就是行数
current_csr.new_row(); // 增加一行
}
}
if (batch_idx >= batch_size_start_idx &&
batch_idx < batch_size_end_idx) { // only read local device dense data
// 设置dense
float* ptr =
host_dense_buffer_.get_ptr() + (batch_idx - batch_size_start_idx) * label_dense_dim;
for (int j = 0; j < label_dense_dim; j++) {
ptr[j] = 0.f;
}
}
continue;
}
try {
try {
if (batch_idx >= batch_size_start_idx &&
batch_idx < batch_size_end_idx) { // only read local device dense data
// 读取dense参数
CK_THROW_(checker_->read(reinterpret_cast<char*>(host_dense_buffer_.get_ptr() +
(batch_idx - batch_size_start_idx) *
label_dense_dim),
sizeof(float) * label_dense_dim),
"failure in reading label_dense");
} else {
// 读取dense参数
CK_THROW_(checker_->read(reinterpret_cast<char*>(temp_host_dense_buffer_.get_ptr()),
sizeof(float) * label_dense_dim),
"failure in reading label_dense");
}
for (size_t param_id = 0; param_id < params_.size(); ++param_id) {
auto& current_csr = host_sparse_buffer_[param_id];
current_csr.set_check_point();
}
// 读取sparse参数
for (size_t param_id = 0; param_id < params_.size(); ++param_id) {
auto& param = params_[param_id];
auto& current_csr = host_sparse_buffer_[param_id];
for (int k = 0; k < param.slot_num; k++) {
int nnz; // 读取一个int到nnz,就是得到nnz的大小,non-zero feature number
CK_THROW_(checker_->read(reinterpret_cast<char*>(&nnz), sizeof(int)),
"failure in reading nnz");
current_csr.new_row(); // 换行
size_t num_value = current_csr.get_num_values();
// 读取nnz个数据
CK_THROW_(checker_->read(reinterpret_cast<char*>(
current_csr.get_value_tensor().get_ptr() + num_value),
sizeof(T) * nnz),
"failure in reading feature_ids_");
current_csr.update_value_size(nnz);
}
}
} catch (const internal_runtime_error& rt_err) { // 回退
batch_idx--; // restart i-th sample
for (auto& each_csr : host_sparse_buffer_) {
each_csr.roll_back();
}
Error_t err = rt_err.get_error();
if (err == Error_t::DataCheckError) {
ERROR_MESSAGE_("Error_t::DataCheckError");
} else { // Error_t::BrokenFile, Error_t::UnspecificEror, ...
read_new_file(); // can throw Error_t::EOF
}
}
current_record_index_++;
// start a new file when finish one file read
if (current_record_index_ >= data_set_header_.number_of_records) {
read_new_file(); // can throw Error_t::EOF
}
} catch (const internal_runtime_error& rt_err) {
Error_t err = rt_err.get_error();
if (err == Error_t::EndOfFile) {
current_batch_size = batch_idx + 1;
} else {
throw;
}
}
}
for (auto& each_csr : host_sparse_buffer_) {
each_csr.new_row();
}
// do h2d
// wait buffer and schedule
// 目前数据在 host_sparse_buffer_(CPU)之上,需要拷贝到 GPU(目标是 ThreadBuffer 的 device_sparse_buffers 成员变量),使用 cudaMemcpyHostToDevice
// 而且,host_sparse_buffer_ 是 CSR<T> 格式,ThreadBuffer 的 device_sparse_buffers 成员变量是SparseTensor<T>格式,需要转换
if (!wait_until_h2d_ready()) return;
buffer_->current_batch_size = current_batch_size;
{
CudaCPUDeviceContext context(gpu_resource_->get_device_id());
// 目标是 ThreadBuffer 的 device_sparse_buffers 成员变量
auto dst_dense_tensor = Tensor2<float>::stretch_from(buffer_->device_dense_buffers);
CK_CUDA_THROW_(cudaMemcpyAsync(dst_dense_tensor.get_ptr(), host_dense_buffer_.get_ptr(),
host_dense_buffer_.get_size_in_bytes(), cudaMemcpyHostToDevice,
gpu_resource_->get_memcpy_stream()));
for (size_t param_id = 0; param_id < params_.size(); ++param_id) { // 遍历嵌入层
auto dst_sparse_tensor =
SparseTensor<T>::stretch_from(buffer_->device_sparse_buffers[param_id]);
if (buffer_->is_fixed_length[param_id] &&
last_batch_nnz_[param_id] == host_sparse_buffer_[param_id].get_num_values()) {
// 拷贝到GPU,同时也进行了转换,提取了CSR的成员变量,拷贝到了SparseTensor的对应地址
CK_CUDA_THROW_(cudaMemcpyAsync(dst_sparse_tensor.get_value_ptr(),
host_sparse_buffer_[param_id].get_value_tensor().get_ptr(),
host_sparse_buffer_[param_id].get_num_values() * sizeof(T),
cudaMemcpyHostToDevice,
gpu_resource_->get_memcpy_stream()));
} else {
// 拷贝到GPU
sparse_tensor_helper::cuda::copy_async(dst_sparse_tensor, host_sparse_buffer_[param_id],
gpu_resource_->get_memcpy_stream());
last_batch_nnz_[param_id] = host_sparse_buffer_[param_id].get_num_values();
}
}
// 进行同步
CK_CUDA_THROW_(cudaStreamSynchronize(gpu_resource_->get_memcpy_stream()));
}
assert(buffer_->state.load() == BufferState::Writing);
buffer_->state.store(BufferState::ReadyForRead);
}
};
4.7.3.1 等待
这里wait_until_h2d_ready会等待。
bool wait_until_h2d_ready() {
BufferState expected = BufferState::ReadyForWrite;
while (!buffer_->state.compare_exchange_weak(expected, BufferState::Writing)) {
expected = BufferState::ReadyForWrite;
usleep(2);
if (*loop_flag_ == 0) return false; // in case main thread exit
}
return true;
}
4.7.3.2 读取文件
read_new_file 完成了对文件的读取。
void read_new_file() {
constexpr int MAX_TRY = 10;
for (int i = 0; i < MAX_TRY; i++) {
if (checker_->next_source() == Error_t::EndOfFile) {
throw internal_runtime_error(Error_t::EndOfFile, "EndOfFile");
}
Error_t err =
checker_->read(reinterpret_cast<char*>(&data_set_header_), sizeof(DataSetHeader));
current_record_index_ = 0;
if (!(data_set_header_.error_check == 0 && check_type_ == Check_t::None) &&
!(data_set_header_.error_check == 1 && check_type_ == Check_t::Sum)) {
ERROR_MESSAGE_("DataHeaderError");
continue;
}
if (static_cast<size_t>(data_set_header_.slot_num) != total_slot_num_) {
ERROR_MESSAGE_("DataHeaderError");
continue;
}
if (err == Error_t::Success) {
return;
}
}
CK_THROW_(Error_t::BrokenFile, "failed to read a file");
}
4.7.4 小结
我们总结逻辑如下,线程一直调用 data_reader_thread_func_ 来循环读取:

另外一个逻辑视角是:
- 多线程调用 data_reader_thread_func_,其使用 read_a_batch 从数据文件之中读取数据解析为CSR。每一个embedding层 对应一个CSR。
- CSR 被放入 DataReaderWorker 的 host_sparse_buffer_。
- 随着batch不断读取,CSR 行数在不断增加,每一个slot对应了一行,所以一个batch的行数就是 batch_size * slot_num。
- 使用 cudaMemcpyAsync 把CSR从 host_sparse_buffer_ 拷贝到ThreadBuffer(位于GPU)。ThreadBuffer是 SparseTensor 类型了。
- 目前CSR数据就在 GPU 之上了。
这里简化了多GPU,多worker 的情况。

0x05 读取到embedding
我们接下来看看 DataCollector,就是流水线的第二级,就是这里的黄色框 "Copy to GPU"。其实其内部文字修改为:Copy To Embedding 更合适。
5.1 DataCollector
我们首先看看DataCollector的定义,这里省略了成员函数,主要成员变量是。
- std::shared_ptr broadcast_buffer_ : CPU 数据拷贝到 GPU 之上,GPU 上就在这里。
- std::shared_ptr output_buffer_ :这个就是 DataReaderOutput,就是 Reader 的成员变量,复制到这里是为了 collector 操作方便。
- BackgroundDataCollectorThread background_collector_ :线程主体,主要包括 ThreadBuffer 和 BroadcastBuffer,会把数据从 ThreadBuffer 拷贝到 BroadcastBuffer 之上。
- std::thread background_collector_thread_ :工作线程。
/**
* @brief A helper class of data reader.
*
* This class implement asynchronized data collecting from heap
* to output of data reader, thus data collection and training
* can work in a pipeline.
*/
template <typename T>
class DataCollector {
class BackgroundDataCollectorThread {
std::vector<std::shared_ptr<ThreadBuffer>> thread_buffers_;
std::shared_ptr<BroadcastBuffer> broadcast_buffer_;
std::atomic<bool> loop_flag_;
int counter_;
std::vector<size_t> last_batch_nnz_; // local_gpu_count * embedding number
std::vector<char> worker_status_;
int eof_worker_num_;
std::shared_ptr<ResourceManager> resource_manager_;
}
std::shared_ptr<BroadcastBuffer> broadcast_buffer_;
std::shared_ptr<DataReaderOutput> output_buffer_;
BackgroundDataCollectorThread background_collector_;
std::thread background_collector_thread_;
std::atomic<bool> loop_flag_;
std::vector<size_t> last_batch_nnz_;
std::shared_ptr<ResourceManager> resource_manager_;
};
目前具体如下,Collector 之中的 broadcast_buffer_ 和 output_buffer_ 都指向了GPU,但GPU之中尚且没有数据:

5.2 ThreadBuffer 2 BroadBuffer
5.2.1 工作线程
BackgroundDataCollectorThread 的作用是把数据从 DataReader 的
thread_buffers_拷贝到
broadcast_buffer_。
class BackgroundDataCollectorThread {
std::vector<std::shared_ptr<ThreadBuffer>> thread_buffers_;
std::shared_ptr<BroadcastBuffer> broadcast_buffer_;
std::atomic<bool> loop_flag_;
int counter_;
std::vector<size_t> last_batch_nnz_; // local_gpu_count * embedding number
std::vector<char> worker_status_;
int eof_worker_num_;
std::shared_ptr<ResourceManager> resource_manager_;
public:
BackgroundDataCollectorThread(const std::vector<std::shared_ptr<ThreadBuffer>> &thread_buffers,
const std::shared_ptr<BroadcastBuffer> &broadcast_buffer,
const std::shared_ptr<ResourceManager> &resource_manager)
: thread_buffers_(thread_buffers),
broadcast_buffer_(broadcast_buffer),
loop_flag_{true},
counter_{0},
last_batch_nnz_(
broadcast_buffer->is_fixed_length.size() * resource_manager->get_local_gpu_count(),
0),
worker_status_(thread_buffers.size(), 0),
eof_worker_num_(0),
resource_manager_(resource_manager) {}
void start() {
while (loop_flag_.load()) {
// threadbuffer是源数据,broadcast buffer是目标数据
auto ¤t_src_buffer = thread_buffers_[counter_];
auto &dst_buffer = broadcast_buffer_;
auto src_expected = BufferState::ReadyForRead; // 期望源数据是这个状态
auto dst_expected = BufferState::ReadyForWrite; // 期望目标数据是这个状态
if (worker_status_[counter_]) {
counter_ = (counter_ + 1) % thread_buffers_.size();
continue;
}
if ((current_src_buffer->state.load() == BufferState::Reading ||
current_src_buffer->state.compare_exchange_weak(src_expected, BufferState::Reading)) &&
(dst_buffer->state.load() == BufferState::Writing ||
dst_buffer->state.compare_exchange_weak(dst_expected, BufferState::Writing))) {
// 如果源数据是可读或者正在读,并且,目标数据是可写或者正在写,则可以操作
if (current_src_buffer->current_batch_size == 0) {
worker_status_[counter_] = 1;
eof_worker_num_ += 1;
current_src_buffer->state.store(BufferState::FileEOF);
}
if (static_cast<size_t>(eof_worker_num_) != thread_buffers_.size() &&
current_src_buffer->current_batch_size == 0) {
counter_ = (counter_ + 1) % thread_buffers_.size();
dst_buffer->state.store(BufferState::ReadyForWrite); // 设定目标数据的状态
continue;
}
dst_buffer->current_batch_size = current_src_buffer->current_batch_size;
if (current_src_buffer->current_batch_size != 0) {
// 进行广播操作
broadcast<T>(current_src_buffer, dst_buffer, last_batch_nnz_, resource_manager_);
current_src_buffer->state.store(BufferState::ReadyForWrite); // 设定目标数据的状态
counter_ = (counter_ + 1) % thread_buffers_.size();
} else {
memset(worker_status_.data(), 0, sizeof(char) * worker_status_.size());
eof_worker_num_ = 0;
counter_ = 0;
}
dst_buffer->state.store(BufferState::ReadyForRead); // 会通知源数据可以继续读取了
} else {
usleep(2); // 否则等待一会
}
}
}
void stop() { loop_flag_.store(false); }
};
5.2.2 拷贝操作
这里就是从源数据拷贝到目标数据,并且是逐个参数进行拷贝。这个是设备之内的拷贝。
template <typename T>
void broadcast(const std::shared_ptr<ThreadBuffer>& thread_buffer,
std::shared_ptr<BroadcastBuffer>& broadcast_buffer,
std::vector<size_t>& last_batch_nnz_,
const std::shared_ptr<ResourceManager>& resource_manager) {
int param_num = thread_buffer->param_num;
int dense_dim = thread_buffer->dense_dim;
int label_dim = thread_buffer->label_dim;
int batch_size = thread_buffer->batch_size;
int batch_size_per_gpu = batch_size / resource_manager->get_global_gpu_count();
int local_gpu_count = resource_manager->get_local_gpu_count();
#pragma omp parallel for num_threads(local_gpu_count)
for (int i = 0; i < local_gpu_count; ++i) { // 遍历本地的GPU
auto local_gpu = resource_manager->get_local_gpu(i);
CudaDeviceContext ctx(local_gpu->get_device_id());
for (int param_id = 0; param_id < param_num; ++param_id) { // 遍历嵌入层
// 从 thread_buffer 拷贝到 broadcast_buffer
auto src_sparse_tensor =
SparseTensor<T>::stretch_from(thread_buffer->device_sparse_buffers[param_id]);
auto dst_sparse_tensor =
SparseTensor<T>::stretch_from(broadcast_buffer->sparse_buffers[i * param_num + param_id]);
// 拷贝sparse参数
if (thread_buffer->is_fixed_length[param_id] &&
last_batch_nnz_[i * param_num + param_id] == src_sparse_tensor.nnz()) {
CK_CUDA_THROW_(cudaMemcpyAsync(dst_sparse_tensor.get_value_ptr(),
src_sparse_tensor.get_value_ptr(),
src_sparse_tensor.nnz() * sizeof(T),
cudaMemcpyDeviceToDevice, local_gpu->get_p2p_stream()));
} else {
sparse_tensor_helper::cuda::copy_async(dst_sparse_tensor, src_sparse_tensor,
cudaMemcpyDeviceToDevice,
local_gpu->get_p2p_stream());
last_batch_nnz_[i * param_num + param_id] = src_sparse_tensor.nnz();
}
}
// 拷贝dense参数
auto dst_dense_tensor = Tensor2<float>::stretch_from(broadcast_buffer->dense_tensors[i]);
auto src_dense_tensor = Tensor2<float>::stretch_from(thread_buffer->device_dense_buffers);
CK_CUDA_THROW_(cudaMemcpyAsync(
dst_dense_tensor.get_ptr(),
src_dense_tensor.get_ptr() + i * batch_size_per_gpu * (label_dim + dense_dim),
batch_size_per_gpu * (label_dim + dense_dim) * sizeof(float), cudaMemcpyDeviceToDevice,
local_gpu->get_p2p_stream()));
// 同步
CK_CUDA_THROW_(cudaStreamSynchronize(local_gpu->get_p2p_stream()));
}
}
逻辑如下,多了一步从 ThreadBuffer 到 BroadcastBuffer 的操作。

5.3 读取到output
目前的流程是:DataFile ---> Host buffer ----> ThreadBuffer ----> BroadcastBuffer。
现在数据已经拷贝到了 GPU 之上的 BroadcastBuffer,我们需要看看最后训练时候怎么拿到数据。
5.3.1 Train
我们首先回到 train 函数,其调用了 read_a_batch_to_device_delay_release 来从 BroadcastBuffer 拷贝数据。
bool Session::train() {
try {
// 确保 train_data_reader_ 已经启动
if (train_data_reader_->is_started() == false) {
CK_THROW_(Error_t::IllegalCall,
"Start the data reader first before calling Session::train()");
}
#ifndef DATA_READING_TEST
// 需要 reader 先读取一个 batchsize 的数据。
long long current_batchsize = train_data_reader_->read_a_batch_to_device_delay_release(); // 读取数据
if (!current_batchsize) {
return false; // 读不到就退出,没有数据了
}
#pragma omp parallel num_threads(networks_.size()) //其后语句将被networks_.size()个线程并行执行
{
size_t id = omp_get_thread_num();
CudaCPUDeviceContext ctx(resource_manager_->get_local_gpu(id)->get_device_id());
cudaStreamSynchronize(resource_manager_->get_local_gpu(id)->get_stream());
}
// reader 可以开始解析数据
train_data_reader_->ready_to_collect();
#ifdef ENABLE_PROFILING
global_profiler.iter_check();
#endif
// If true we're gonna use overlaping, if false we use default
if (solver_config_.use_overlapped_pipeline) {
train_overlapped();
} else {
for (const auto& one_embedding : embeddings_) {
one_embedding->forward(true); // 嵌入层进行前向传播,即从参数服务器读取embedding,进行处理
}
// Network forward / backward
if (networks_.size() > 1) {
// 单机多卡或多机多卡
// execute dense forward and backward with multi-cpu threads
#pragma omp parallel num_threads(networks_.size())
{
// dense网络的前向反向
size_t id = omp_get_thread_num();
long long current_batchsize_per_device =
train_data_reader_->get_current_batchsize_per_device(id);
networks_[id]->train(current_batchsize_per_device); // 前向操作
const auto& local_gpu = resource_manager_->get_local_gpu(id);
local_gpu->set_compute_event_sync(local_gpu->get_stream());
local_gpu->wait_on_compute_event(local_gpu->get_comp_overlap_stream());
}
} else if (resource_manager_->get_global_gpu_count() > 1) {
// 多机单卡
long long current_batchsize_per_device =
train_data_reader_->get_current_batchsize_per_device(0);
networks_[0]->train(current_batchsize_per_device); // 前向操作
const auto& local_gpu = resource_manager_->get_local_gpu(0);
local_gpu->set_compute_event_sync(local_gpu->get_stream());
local_gpu->wait_on_compute_event(local_gpu->get_comp_overlap_stream());
} else {
// 单机单卡
long long current_batchsize_per_device =
train_data_reader_->get_current_batchsize_per_device(0);
networks_[0]->train(current_batchsize_per_device); // 前向操作
const auto& local_gpu = resource_manager_->get_local_gpu(0);
local_gpu->set_compute_event_sync(local_gpu->get_stream());
local_gpu->wait_on_compute_event(local_gpu->get_comp_overlap_stream());
networks_[0]->update_params();
}
// Embedding backward
for (const auto& one_embedding : embeddings_) {
one_embedding->backward(); // 嵌入层反向操作
}
// Exchange wgrad and update params
if (networks_.size() > 1) {
#pragma omp parallel num_threads(networks_.size())
{
size_t id = omp_get_thread_num();
exchange_wgrad(id); // 多卡之间交换dense参数的梯度
networks_[id]->update_params();
}
} else if (resource_manager_->get_global_gpu_count() > 1) {
exchange_wgrad(0);
networks_[0]->update_params();
}
for (const auto& one_embedding : embeddings_) {
one_embedding->update_params(); // 嵌入层更新sparse参数
}
// Join streams
if (networks_.size() > 1) {
#pragma omp parallel num_threads(networks_.size())
{
size_t id = omp_get_thread_num();
const auto& local_gpu = resource_manager_->get_local_gpu(id);
local_gpu->set_compute2_event_sync(local_gpu->get_comp_overlap_stream());
local_gpu->wait_on_compute2_event(local_gpu->get_stream());
}
}
else {
const auto& local_gpu = resource_manager_->get_local_gpu(0);
local_gpu->set_compute2_event_sync(local_gpu->get_comp_overlap_stream());
local_gpu->wait_on_compute2_event(local_gpu->get_stream());
}
return true;
}
#else
data_reader_->read_a_batch_to_device();
#endif
} catch (const internal_runtime_error& err) {
std::cerr << err.what() << std::endl;
throw err;
} catch (const std::exception& err) {
std::cerr << err.what() << std::endl;
throw err;
}
return true;
}
5.3.2 read_a_batch_to_device_delay_release
read_a_batch_to_device_delay_release 是最终配置好embedding数据的地方。
long long read_a_batch_to_device_delay_release() override {
current_batchsize_ = data_collector_->read_a_batch_to_device();
return current_batchsize_;
}
我们看看 read_a_batch_to_device。这里 read_a_batch_to_device_delay_release 和 read_a_batch_to_device 是沿用旧版本命名,已经和目前状况不符合。
具体逻辑是:看看 broadcast_buffer_ 的状态是不是可以读取 ReadyForRead,如果不可以,就等一会。如果可以,就继续,即遍历GPU,逐个从broadcast拷贝到output(也是设备之间的拷贝),也对 label 和 dense 进行split。
long long read_a_batch_to_device() {
BufferState expected = BufferState::ReadyForRead;
while (!broadcast_buffer_->state.compare_exchange_weak(expected, BufferState::Reading)) {
expected = BufferState::ReadyForRead;
usleep(2);
}
long long current_batch_size = broadcast_buffer_->current_batch_size;
if (current_batch_size != 0) {
int local_gpu_count = resource_manager_->get_local_gpu_count();
#pragma omp parallel for num_threads(local_gpu_count)
for (int i = 0; i < local_gpu_count; ++i) {
auto local_gpu = resource_manager_->get_local_gpu(i);
CudaDeviceContext ctx(local_gpu->get_device_id());
// wait until last iteration finish
auto label_tensor = Tensor2<float>::stretch_from(output_buffer_->label_tensors[i]);
auto label_dense_tensor = Tensor2<float>::stretch_from(broadcast_buffer_->dense_tensors[i]);
// 遍历 sparse 参数
for (size_t param_id = 0; param_id < output_buffer_->sparse_name_vec.size(); ++param_id) {
const auto &top_name = output_buffer_->sparse_name_vec[param_id];
int idx_broadcast = i * broadcast_buffer_->param_num + param_id;
// broadcast 的是源
auto src_sparse_tensor =
SparseTensor<T>::stretch_from(broadcast_buffer_->sparse_buffers[idx_broadcast]);
if (output_buffer_->sparse_tensors_map.find(top_name) ==
output_buffer_->sparse_tensors_map.end()) {
CK_THROW_(Error_t::IllegalCall, "can not find sparse name");
}
// output是目标
auto dst_sparse_tensor =
SparseTensor<T>::stretch_from(output_buffer_->sparse_tensors_map[top_name][i]);
// 从broadcast拷贝到output
if (broadcast_buffer_->is_fixed_length[idx_broadcast] &&
last_batch_nnz_[idx_broadcast] == src_sparse_tensor.nnz()) {
CK_CUDA_THROW_(cudaMemcpyAsync(dst_sparse_tensor.get_value_ptr(),
src_sparse_tensor.get_value_ptr(),
src_sparse_tensor.nnz() * sizeof(T),
cudaMemcpyDeviceToDevice, local_gpu->get_stream()));
} else {
// 从broadcast拷贝到output
sparse_tensor_helper::cuda::copy_async(dst_sparse_tensor, src_sparse_tensor,
cudaMemcpyDeviceToDevice,
local_gpu->get_stream());
last_batch_nnz_[idx_broadcast] = src_sparse_tensor.nnz();
}
}
const int label_dense_dim = output_buffer_->label_dense_dim;
// 拷贝label和dense
if (output_buffer_->use_mixed_precision) {
auto dense_tensor = Tensor2<__half>::stretch_from(output_buffer_->dense_tensors[i]);
// 进行分块
split(label_tensor, dense_tensor, label_dense_tensor, label_dense_dim,
local_gpu->get_stream());
} else {
auto dense_tensor = Tensor2<float>::stretch_from(output_buffer_->dense_tensors[i]);
split(label_tensor, dense_tensor, label_dense_tensor, label_dense_dim,
local_gpu->get_stream());
}
}
} else {
broadcast_buffer_->state.store(BufferState::ReadyForWrite);
}
return current_batch_size;
}
5.3.3 split
label 和 dense 早已经拷贝到了GPU之上,这步做的是分成block,然后使用 GPU thread 进行操作。
template <typename TypeComp>
__global__ void split_kernel__(int batchsize, float* label_ptr, int label_dim, TypeComp* dense_ptr,
int dense_dim, const float* label_dense, int label_dense_dim) {
int idx = blockDim.x * blockIdx.x + threadIdx.x;
if (idx < batchsize * label_dense_dim) {
const int in_col = idx % label_dense_dim;
const int in_row = idx / label_dense_dim;
const int out_row = in_row;
if (in_col < label_dim) {
const int out_col = in_col;
label_ptr[out_row * label_dim + out_col] = label_dense[idx];
} else {
const int out_col = in_col - label_dim;
dense_ptr[out_row * dense_dim + out_col] = label_dense[idx];
}
}
return;
}
template <typename TypeComp>
void split(Tensor2<float>& label_tensor, Tensor2<TypeComp>& dense_tensor,
const Tensor2<float>& label_dense_buffer, const int label_dense_dim,
cudaStream_t stream) {
// check the input size
assert(label_tensor.get_dimensions()[0] == dense_tensor.get_dimensions()[0]);
assert(label_tensor.get_num_elements() + dense_tensor.get_num_elements() ==
label_dense_buffer.get_num_elements());
const int batchsize = label_tensor.get_dimensions()[0];
const int label_dim = label_tensor.get_dimensions()[1];
const int dense_dim = dense_tensor.get_dimensions()[1];
const int BLOCK_DIM = 256;
const int GRID_DIM = (label_dense_buffer.get_num_elements() - 1) / BLOCK_DIM + 1;
if (dense_dim > 0) {
split_kernel__<<<GRID_DIM, BLOCK_DIM, 0, stream>>>(
batchsize, label_tensor.get_ptr(), label_dim, dense_tensor.get_ptr(), dense_dim,
label_dense_buffer.get_ptr(), label_dense_dim);
} else if (dense_dim == 0) {
split_kernel__<<<GRID_DIM, BLOCK_DIM, 0, stream>>>(
batchsize, label_tensor.get_ptr(), label_dim, (TypeComp*)0, 0, label_dense_buffer.get_ptr(),
label_dense_dim);
} else {
CK_THROW_(Error_t::WrongInput, "dense_dim < 0");
}
return;
}
这样后续就可以训练了,后续是通过 finalize_batch 之中进行读取。
void finalize_batch() {
for (size_t i = 0; i < resource_manager_->get_local_gpu_count(); i++) {
const auto &local_gpu = resource_manager_->get_local_gpu(i);
CudaDeviceContext context(local_gpu->get_device_id());
CK_CUDA_THROW_(cudaStreamSynchronize(local_gpu->get_stream()));
}
broadcast_buffer_->state.store(BufferState::ReadyForWrite);
}
template <typename SparseType>
void AsyncReader<SparseType>::ready_to_collect() {
auto raw_device_id = reader_impl_->get_last_batch_device();
auto local_gpu = resource_manager_->get_local_gpu(raw_device_id);
CudaDeviceContext ctx(local_gpu->get_device_id());
CK_CUDA_THROW_(cudaEventRecord(completion_events_[raw_device_id], local_gpu->get_stream()));
reader_impl_->finalize_batch(&completion_events_[raw_device_id]);
}
0x06 总结
具体逻辑如下,本章节之中,各个buffer之间拷贝,是依据其状态是 ReadyForRead 和 ReadyForWrite 来完成的。最终sparse 参数的embedding是在DataReaderOutput,即后续 GPU 上的计算是从output开始的。

0xFF 参考
https://web.eecs.umich.edu/~justincj/teaching/eecs442/notes/linear-backprop.html

- [源码解析] PyTorch 分布式(15) --- 使用分布式 RPC 框架实现参数服务器
- 人脸检测源码解析——1、训练参数
- Pull解析xml,在线升级中的获取服务器版本与本地版本比较
- GPU架构解析——NVIDIA\AMD
- fabirc1.0商业正式版本源码解析10——文档翻译之Architecture
- ubuntu16.04 从源码安装tensorflow-gpu r1.4版本---2017-12-07
- 【升级版】如何使用阿里云云解析API实现动态域名解析,搭建私有服务器【含可执行文件和源码】
- 实现android注册登陆功能的客户端服务器源码与解析socket
- 用HttpListener做web服务器,简单解析post方式过来的参数、上传的文件
- MXNet 源码解读系列之一 C++端如何解析NDArray参数文件
- Django源码解析(三) Django开发服务器,WSGI规范实现.
- spark源码解析-从提交任务到jar的加载运行(基于2.1.0版本)
- layoutInflater参数解析与源码分析
- EventBus3.0以及老版本源码解析
- fabirc1.0商业正式版本源码解析2——peer命令结构
- CSS难不难之源码解析(服务器交互)
- 源码解析:Hibernate 事务 设计 (版本 3.1.3)
- Springboot:2.1.1版本启动配置文件源码解析
- 结巴分词JAVA版本源码解析(三)
- 加入数据库mysql实现android注册登陆功能的客户端服务器源码与解析socket