大数据分布式存储之Cassandra
分布式存储需要考虑的问题
元数据管理
元数据是指数据本身的标识,通过元数据能很快的找到数据存储的位置,比如在分布式文件系统中,元数据是指文件的路径名+文件名;元数据管理包括集中式元数据管理架构和分布式元数据管理架构;集中式是指将元数据存储到一个节点上,实现简单,但具有单点故障和性能瓶颈的问题;分布式元数据架构是将元数据存储到多个节点上,虽然解决了集中式元数据管理架构的问题,但却引入了数据一致性的问题,如多节点之间的数据如何保持一致;
弹性伸缩
弹性伸缩需要考虑如下两种情况:
- [li]某一节点宕机或磁盘坏掉的情况下如何保障系统还能正常运行并且数据不丢失;
- 数据和计算资源的负载均衡:当前数据库集群已经无法容纳更多的数据时,如何通过加入新的数据节点分摊数据;或当前的数据库集群算力已经达到顶峰时,如何通过加入新的节点分摊算力;如何保证计算和数据均匀分布,避免某一节点成为热点或瓶颈;
性能与成本
高效而合理的存储结构应在保障数据库性能的情况下,最大程度降低系统能耗和构建/管理成本;如如何保障数据库查询不会扫描整个数据库集群?如何在算力、存储不足的情况下能不加人为干预的动态加入新的节点?
CAP理论
作为分布式存储系统的奠基石,CAP理论提出了在分布式系统架构过程中必须考虑的三个因素:
- [li]C(一致性Consistency):对写入的数据,分布式系统中的所有的备份节点是否都能得到最新的数据副本;
- A(可用性Availability):对每个读取/写入请求,都能得到相应的结果;
- P(分区容错Partition tolerance):分布式集群中任何节点的宕机都不会影响整个系统的继续运作;
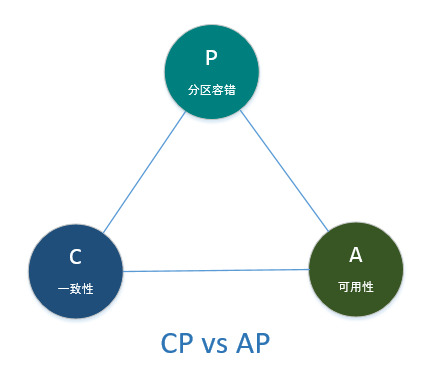
在分布式存储系统中,一致性、分区容错、可用性三者很难完全达到,只能满足其中之二,但分区容错又是必须满足的,因此CAP最终演变为了CP和AP的对决。
Cassandra
特点
-
去中心化
相对于传统的集中式元数据管理架构和Master/Slave的分布式数据库架构,Cassandra采用了P2P(Peer-to-peer对等网络)协议,通过Gossip协议来维护和同步节点信息;
每隔一秒,数据节点就会从集群中随机选择一个节点,并初始化与它的一个Gossip会话,并发送一个GossipDigestSynMessage;这个节点收到消息时,会返回一个GossipDigestAckMessage;发送者收到ACK消息时,会再次发送一个GossipDigestAck2Message并结束此轮Gossip会话;
Cassandra采用累积型故障探测(对历史数据进行累计与分析)方法判断某个节点是否下线;每个节点的存活与死亡都存在一个可信度,可信度是一个随时间变化连续的值,当可信度达到low threshold时,会被判断为逻辑死亡,其他节点不会将读写操作发送至该节点,当可信度达到moderate thresold的时候时,则被判断为物理死亡;
对等网络中分布式一致性问题:

Cassandra使用Paxos共识算法确保在分布式对等节点里达成一致结果,而不需要一个主节点协调。
在Paxos算法中,每个节点都可以担任协调者的角色,向其他副本节点提议一个新值,每个副本节点会检查该提议,如果这个提议是它看到的最新的提议,它会承诺不接受与之前任何提议关联的提议,每个副本节点都会返回它接收到的最新的提议,如果这个提议被大多数副本接受,协调者就会提交这个提议。
-
可调复制一致性级别
Cassandra可通过可调节的一致性级别满足CP和AP的需要;
写复制一致性级别(不完全列表)
| 一致性级别 | 含义 |
| ANY | 弱一致性,写数据时,只要确保这个值能写入到一个节点即保证写入成功 |
| QUORUM | 确保至少大多数副本(副本因子/2+1) |
| ALL | 强一致性,要求要写入到所有副本,如果有一个副本没有响应,则操作失败 |
如果写复制一致性级别没有设置为ALL的时候,必然会导致一些副本节点保存的数据不是最新数据,因此要使用修复功能完成节点间的数据同步:读修复和逆熵修复;
读修复是指Cassandra从多个副本读取出数据,并检测到某些副本包含过期的数据,如果有最新值的节点数量不够,就需要进行读修复来更新那些过期的副本;
逆熵修复是一种在节点上手动的修复方式,通过判断两个副本之间Merkle树是否相等来确定两个副本的数据是否一致,如果不一致,则进行修复。
读一致性级别(不完全列表)
| 一致性级别 | 含义 |
| ONE,TWO,THREE | 立即返回响应查询的第一个节点包含的记录,创建一个后台线程对这个记录与其他副本上相同的记录做比较,如果过期则进行读修复 |
| QUORUM | 查询所有节点,一旦大多数节点(副本因子/2+1)做出响应,则向客户端返回最新时间戳的值,必要时进行读修复 |
| ALL | 查询所有节点,等待所有节点做出响应,向客户端返回具有最新时间戳的值,必要时进行读修复 |
-
易操作的数据接口
Cassandra作为NoSQL技术的代表性数据库,提供了类似于SQL语言的CQL查询语言,比如创建一个user表:
CREATE TABLE user(first_name text, last_name text, PRIMARY KEY(first_name));
当需要向user表中插入一条记录时,可以使用下面的脚本:
INSERT INTO user(first_name, last_name) VALUES('Bill', 'Nguyen');
当要进行数据查询时,可以使用:
SELECT COUNT(*) FROM user;
数据分布
在早期的Cassandra版本中,将这个集群中的节点连接为一个环,并为环中的每个物理节点分配一个数据区间或范围,由一个令牌来表示,通过这个令牌来确定数据在环中的位置:
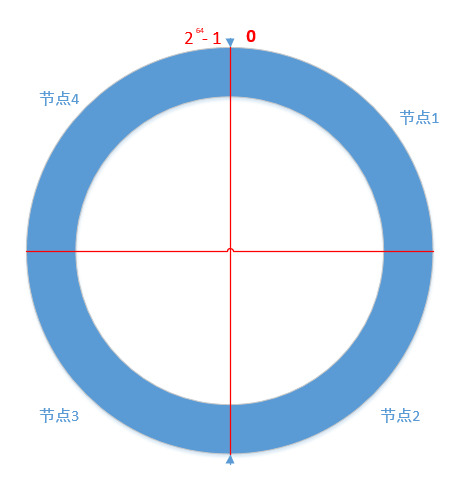
当插入数据时,会通过一个Hash函数计算得到要插入数据的Hash值,通过这个Hash值得到这个数据在环中所处的位置或区间,并确定拥有这个数据的节点;但采用这种方式会存在一个问题,即增加或替换节点会有非常大的开销,再平衡数据分布时会移动大量的数据;
因此在Cassandra后期的版本中引入了虚拟节点,即不再为物理节点分配一个令牌,而将令牌区间分解为多个小区间(每个小区间对应一个虚拟节点),这样每个物理节点就会被分配多个虚拟节点;在增加或替换节点时只需要迁移相应的虚拟节点即可。
高性能的写操作
-
写日志优先
Cassandra进行写操作时,会优先写入提交日志,提交日志是支持Cassandra持久性目标的一种失败恢复机制;
-
基于内存写的数据结构
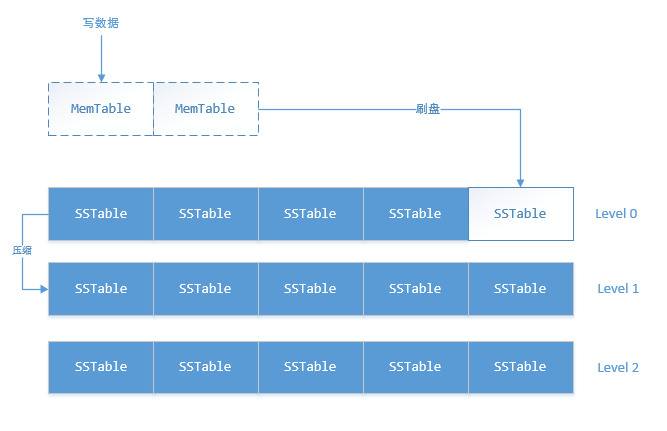
在提交日志成功之后,值会被写入到一个内存的数据结构中,这个内存结构称之为memtable,每个表都会有一个或多个独立的memtable;
当存储在memtable中的记录数量达到一个阈值的时候,memtable中的内容会被刷到磁盘里一个名为SSTable的文件中,然后再创建一个新的memtable;刷盘是非阻塞操作,与数据写入可以同时进行;在memtable刷入成功之后会删除掉对应的日志;
-
数据合并
Cassandra对数据的写操作都是以追加的方式顺序进行,并不需要任何读或者查找操作,这就会导致同一条数据的操作分布到多个SSTable中;同时SSTable是不可变的;
Cassandra的删除操作并不是立即删除,只是在值上放置一个墓碑,墓碑相当于删除标志,等到可以运行合并的时候,才真正删除Cassandra中的老数据;
合并触发的条件:每个层级下面会有多个SSTable,当某个层级的SSTable文件数量达到Threshold之后,会将该层级的SSTable与上一层级的SSTable文件合并,并写入到新的SSTable中;合并过程中,键会归并、列会组合、墓碑将会被删除。
增强式的读操作
由于对数据的更新都是顺序,势必会导致对同一条记录多次更新的数据会落入到多个SSTable或MemTable中。
为提高查询的速度,Cassandra使用BloomFilter检测记录是否存在于SSTable中,由于BloomFilter存在误报的现象(不存在的记录判断为存在),可通过增加过滤器内存大小减少误报率。

- 关于大数据时代传统商业存储的思考: 中心存储 VS 分布式存储
- 关于大数据时代传统商业存储的思考: 中心存储 VS 分布式存储
- 大数据分布式存储的部署模式:分离式or超融合
- 大数据技术思想入门(一):分布式存储特点
- 大数据分布式存储的部署模式:分离式or超融合
- cassandra的架构——Data distribution and replication(分布式存储和复制)
- Cassandra联手Spark 大数据分析将迎来哪些改变?
- 玩转Python大数据分析 《Python for Data Analysis》的读书笔记-第02页
- cassandra 获取int型数据问题
- 大数据架构和模式(三)理解大数据解决方案的架构层
- 让大数据分析更有效的5种技术措施
- 【PDF下载】金融技术峰会之蚂蚁金服大数据开放式创新实践
- cassandra nodetool repair
- 大数据集群搭建之hadoop、tomcat、jdk等工具的安装(三)
- 采用分布式存储技术做了个贴吧,拥有无数个吧,可容纳无数个贴 欢迎各路英雄批评指正!
- 四 大数据分析之 SVD理论
- java解决大数据读写问题
- 一文读懂大数据计算框架与平台
- 分布式key-value存储方案 Cassandra
- cassandra高级操作之索引、排序以及分页