大数据的“批处理”和“流处理”
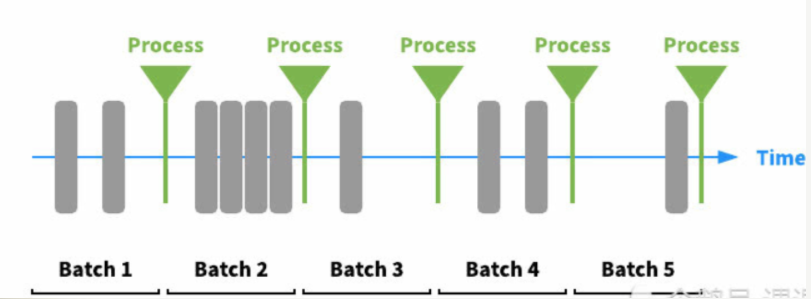
批处理
批处理的输入是在一段时间内已经采集并存储好的有边界数据(相关概念见后面附录介绍)。同样的,输出数据也一样是有边界数据。当然,每次经过批处理后所产生的输出也可以作为下一次批处理的输入。
举个例子,你在每年年初所看到的“支付宝年账单”就是一个数据批处理的典型例子:
支付宝会将我们在过去一年中的消费数据存储起来作为批处理输入,提取出过去一年中产生的交易数据,经过一系列业务逻辑处理,得到各种有趣的信息作为输出。
在许多情况下,批处理任务会被安排并以预先定义好的时间间隔来运行,例如一天、一月或者一年这样的周期时间。
由于批处理的任务一般都是将输入数据累积一段时间后一块一块的交由程序处理。所以,完成批处理任务具有高延迟性,一般可以需要花费几小时,几天甚至是几周的时间。要是在开发业务中有快速响应用户的时间需求,我们则需要考虑使用流处理 / 实时处理来处理大数据。
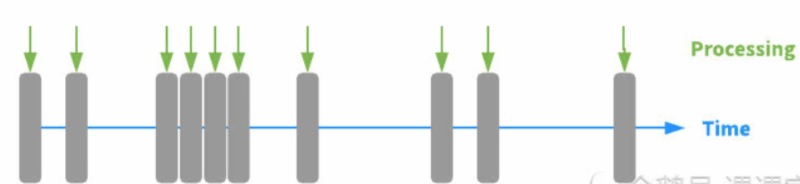
流处理
流处理的输入基本上都是无边界数据。
流处理可以理解为系统需要接收并处理一系列连续不断变化的数据。例如,旅行预订系统,处理社交媒体更新信息的有关系统等等。
流处理的特点是要足够快、低延时,以便能够处理来自各种数据源的大规模数据。流处理所需的响应时间更应该以毫秒(或微秒)来进行计算。像我们平时用到的搜索引擎,系统必须在用户输入关键字后以毫秒级的延时返回搜索结果给用户。还记得我们在介绍批处理架构中所说到的不足吗?没错,是高延迟。而流处理架构则恰恰拥有高吞度量和低延迟等特点。
现如今的开源架构生态圈中,如 Apache Kafka、Apache Flink、Apache Storm、Apache Samza 等,都是流行的流处理架构平台。
最简单的说,基本的区别在于每一条新数据在到达时是被处理的,还是需要累积一段时间后集中处理。这种区分将处理分为批处理和流处理:
批处理模式在不需要实时分析结果的情况下是一种很好的选择。尤其当业务逻辑需要处理大量的数据以挖掘更为深层次数据信息的时候。
而在需要对数据进行实时分析处理时,或者说当有些数据是永无止境的事件流时(例如传感器发送回来的数据时),我们则应该选择用流处理模式。
附录:
无边界数据和有边界数据
这个世界上的数据可以抽象成为两种,分别是无边界数据(Unbounded Data)和有边界数据(Bounded Data)。
顾名思义,无边界数据是一种不断增长,可以说是无限的数据集。这种类型的数据,我们无法判定它们到底什么时候会停止发送。例如,从手机或者从传感器发送出来的信号数据,又比如我们所熟知的移动支付领域中的交易数据。因为每时每刻都会有交易产生,所以我们不能判定在某一刻这类数据就会停止发送了。
在一些技术文章上,有时候我们会看到“流数据(Streaming Data)”这一说法,其实它和无边界数据表达的是同一个概念。
与此相反,有边界数据是一种有限的数据集。这种数据更常见于已经保存好了的数据中。例如,数据库中的数据,或者是我们常见的 CSV 格式文件中的数据。
当然了,如果我们把无边界数据按照时间窗口提取一小份出来,那这样的数据就变成了有边界数据了。所以,有边界数据其实可以看作是无边界数据的一个子集。

- JAVAWEB开发之JDBC详解(连接操作数据库、处理大数据、批处理)
- PHP 批处理 处理大数据 长时间处理
- 处理mysql数据的批处理
- 大数据架构简述(三):流处理、批处理、交互式查询
- 一个jdbc的例子(包含sql语句的批处理,事务处理,数据绑定prepare)
- 基于Java使用Flink读取CSV文件,针对批处理,多表联合两种方式Table类和Join方法的实现数据处理,再入CSV文件...
- JDBC处理大数据、大文本、二进制数据、批处理相关知识
- JDBC处理大数据、二进制数据和批处理
- JDBC处理大数据批处理
- JDBC滚动结果集、SQL注入、处理大数据、批处理、DAO模式介绍
- 一个jdbc的例子(包含sql语句的批处理,事务处理,数据绑定prepare,)
- 【云星数据---Apache Flink实战系列(精品版)】:Apache Flink实战基础003--flink特性:流处理,批处理珠联璧合
- 【Python文件处理】递归批处理文件夹子目录内所有txt数据
- J2EE进阶之JDBC分页,大文本数据存储,批处理,事物处理 十八
- 大型企业级云产品-数据统计分析系统(离线处理-流处理-批处理)
- poi 导入Excel封装 并处理数据类型
- 简单处理IP XML数据
- 数据预处理
- mysql 分组、最新数据优先于group,分页同时处理
- 大数据处理技术之数据清洗