一文看懂 Kubernetes API 稳定性设计
 【导读】Kubernetes 是一个灵活强大的生产级别的开源容器编排系统,与服务器,网络,存储等各基础设施和认证授权,虚拟化,大数据等各种技术领域有着密切的交互与协作,同时也在不断吸纳各种其他领域, 迅速地发展壮大。如何保证这样一个几乎"包罗万象"的系统在不断增加和扩展特性的快速迭代过程中各版本的稳定性和兼容性自然是一个至关重要的课题。本文仅就 Kubernetes 的 API 相关内容一窥 Kubernetes 的稳定性设计。
【导读】Kubernetes 是一个灵活强大的生产级别的开源容器编排系统,与服务器,网络,存储等各基础设施和认证授权,虚拟化,大数据等各种技术领域有着密切的交互与协作,同时也在不断吸纳各种其他领域, 迅速地发展壮大。如何保证这样一个几乎"包罗万象"的系统在不断增加和扩展特性的快速迭代过程中各版本的稳定性和兼容性自然是一个至关重要的课题。本文仅就 Kubernetes 的 API 相关内容一窥 Kubernetes 的稳定性设计。Kubernetes API 是 Kubernetes 系统的重要组成部分,组件之间的所有操作和通信以及外部对 Kuber-netes 的调用都是由 API Server 处理的 REST API 调用。API 的设计对于产品内部通信和外部协作。
1. API 结构与版本
Kubernetes API 是通过 HTTP 提供的编程接口,以 REST 风格组织并管理资源,支持通过 POST ,PUT ,DELETE , GET 等标准的 HTTP 方法对资源进行增删改查等操作。
1.1 资源
Kubernetes 中所有内容都被抽象为资源。所有资源都可以使用清单文件(manifest file)进行描述,使用Etcd 数据库进行存储并由 API Server 统一管理。
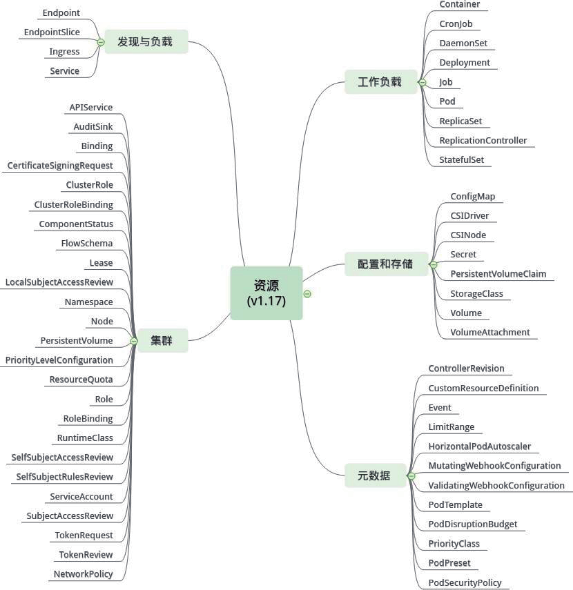
资源分为集群和命名空间两级作用域,命名空间级资源会在其命名空间删除时被删除。上图资源类别并不代表其作用域
所有资源在其资源对象模式(清单文件)中都有一个具体的表示形式,称为 Kind。同一资源的多个对象(实例)可以组成集合
可以通过 kubectl api-resources 命令查看当前 Kubernetes 环境支持的所有资源的名称,缩写,api 组,作用域及其对应的 Kind
1.2 API
Kubernetes API 大多数情况下遵循标准的 HTTP REST 规范,JSON 和 Protobuf 是其主要序列化结构,资源通过 API 接口传入 API Server 最终持久化到 Etcd 数据库。API 是由 API Server 组件提供服务,API Server 是 Kubernetes 的管理中心,是唯一能够与 Etcd 数据库交互的组件
1.2.1 API 群组
Kubernetes API 除了提供组织和管理各种资源的接口外,还包括一些系统层面的接口。目前 API 主要分为三种形式:

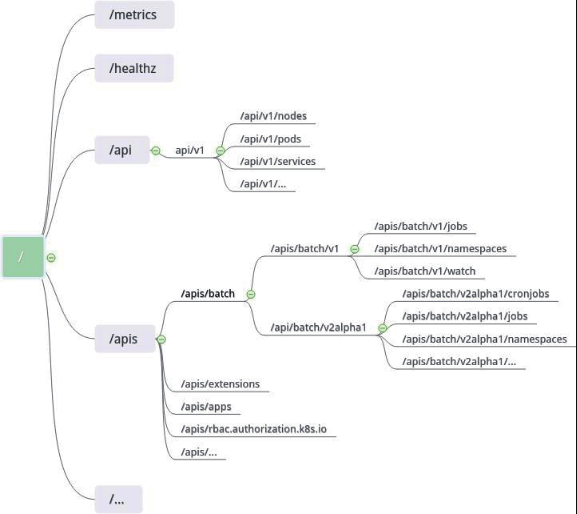
除了系统级 API 外,Kubernetes 基本上是以 API Group(API 群组)的方式组织各种 API 的,核心组 API并未使用/apis/core/v1 路径是历史原因(事实上核心组也成为遗留组)。API 群组是一组相关的 API 对象的集合,使用群组概念能够更方便的管理和扩展 API。
结构示意如下:
1.2.2 API 版本
为了在兼容旧版本的同时不断升级新的 API,Kubernetes 支持多种 API 版本,不同的 API 版本代表其处于不同的稳定性阶段,低稳定性的 API 版本在后续的产品升级中可能成为高稳定性的版本。
API 版本规则是通过基于 API level 选择版本,而不是基于资源和域级别选择,是为了确保 API 能够描述一个清晰的连续的系统资源和行为的视图,能够控制访问的整个过程和控制实验性 API 的访问。
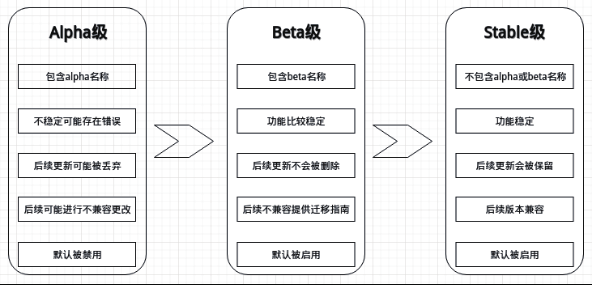
API 通过这种三级渐进式版本共存与演化策略,在不断吸纳新的功能特性并给予其足够的孵化空间的同时,保证了整体 API 的可用性和稳定性。
资源定位三元组
API Group,API Version 和 Resource(GVR 三元组)就可以唯一确定一个资源的 API 路径。如 /apis/r-bac.authorization.k8s.io/v1beta1/clusterroles 。
对于命名空间级资源则需要额外包含具体命名空间(否则将请求所有命名空间下相应资源),如/apis/apps/v1/namespaces/kube-system/deployments 。
对应到资源对象模式(清单文件)三元组则为 API Group,API Version 和 Kind(GVK),相应字段为apiVersion 和 kind ,如{"apiVersion": "app/v1","kind": "Deployment"} 。
Kubernetes 组件默认启用加密通信,并需要请求者提供凭证,为了更方便地请求 API,可以开启代理访问。
kubectl proxy --port=8888 # 开启代理访问
curl http://localhost:8888/api/pods/ # kubectl 代理会自动使用默认凭证路径
(/etc/kubernetes/ssl/)下的凭证文件(kube-proxy.xx)
可以通过 kubectl api-versions 命令查看当前 Kubernetes 环境启用的所有 API 群组及其版本。
1.3 数据持久化与无损转换
用户向 Kubernetes 发起资源构建请求时只提供了一个资源清单文件(如 deployment.yaml),但事实上Kubernetes 基于可用性和稳定性的考虑,却能够支持同时使用不同稳定性的 API 版本访问同一资源,返回不同版本的资源数据。这一灵活的特性有赖于 API Server 的资源数据无损耗转换机制。
1.3.1 数据持久化
资源数据是持久化到 Etcd 数据库中的,而从资源清单文件到持久化到 Etcd 数据库的资源数据的大致流程如下:
1. 客户端(kubectl,curl,sdk 等)得到资源清单文件(YAML 或 JSON 格式)
2. 部分支持格式转换的客户端(如 kubectl,sdk 等)会先将 YAML 格式的资源清单文件转换为 JSON 格式化,然后根据清单字段或相应参数获取 API Server 请求路径,发送到 API Server
3. API Server 对收到的资源清单文件进行准入校验和字段预处理,生成资源数据,对同资源的多个版本进行无损转换
4. API Server 将资源数据转换为指定的存储版本
5. API Server 将存储版本的资源数据按照指定编码(PROTOBUF 或 JSON)进行序列化,以 key-value的 方式存储到 Etcd 中
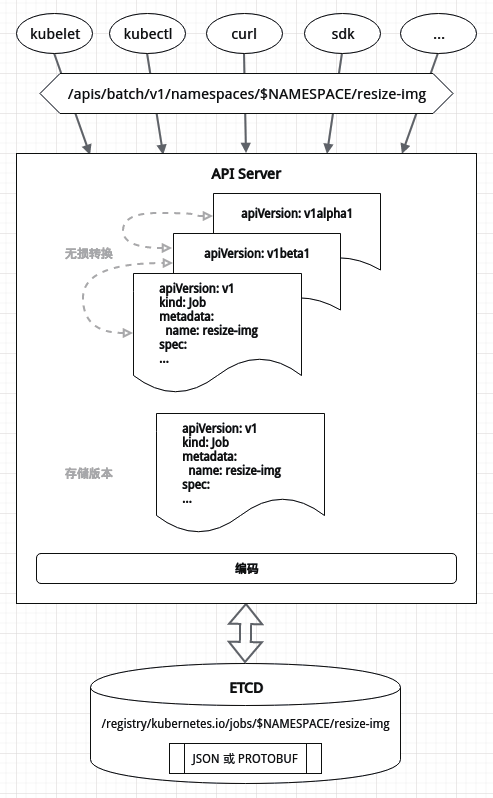
API Server 启动时可以通过--storage-versions 参数指定资源数据的存储版本(默认是最新稳定版,如v1); 通过--storage-media-type 参数指定序列化编码(默认是 application/vnd.kubernetes.protobuf)。
Etcd 数据库中的资源数据是作为 value 存储的,而对应的 key 则是按照/registry/#{k8s 对象}/#{命名空间}/#{具体实例名}的规范格式生成的。
1.3.2 无损转换
Etcd 数据库中只存储了资源的一个指定版本,但客户端传入的资源清单文件中指定的资源版本和客户端向 API Server 请求的资源版本可能并不是 Etcd 数据库中存储的版本,API Server 如何在各个版本之间进行无损转换呢?
如果一个资源存在众多版本,那么编写各种不同版本之间的转换规则无疑是非常麻烦的,因此 API Server 中维护着一个 internal 版本,需要作版本转换时,任意原版本都先转换为 internal 版本,再由 internal 版本转换到指定的目的版本,如此只要每个版本都可转换为 internal 版本,则可以支持任意版本之间的转换。
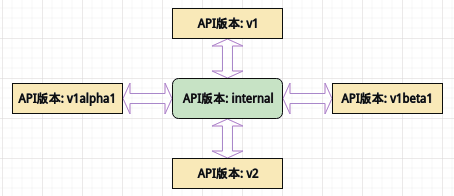
而保证版本转换过程中不出现数据丢失(即无损转换)则是依靠 annotations(注解)实现。例如从版本 A 转换到版本 B,对不同字段的处理如下:
版本 A 和 B 中均存在的字段可直接转换
版本 A 中存在而版本 B 中不存在的字段将写入注解中
版本 A 中不存在而版本 B 中存在的字段,如果存在于版本 A 的注解中则从注解中读取字段值,否则字段值置空
2. API 扩展
Kubernetes 因其平台级基础设施的特殊性,与服务器,网络,存储,虚拟化,身份认证等等绝大多数计算机软硬件技术领域存在广泛交集,这需要大量的适配与对接,此外作为底层容器编排引擎,也需要满足高度的可扩展性以面对大量的功能特性扩展需求。
常规的解决方案是修改 Kubernetes 相关 API 和控制器的源代码或者定义新的资源类型并作为新的核心资源 API 合并到 Kubernetes 官方社区代码中。但这些方无疑会迅速使得 Kubernetes 核心 API 资源变得臃肿庞杂难以维护,最终导致 API 过载,这会为项目本身维护和产品生产环境运行的稳定性带来巨大挑战。
Kubernetes 提供了两种 API 扩展机制保证核心 API 足够精简的同时满足庞杂的适配对接和特性扩展需求:
1. 自定义资源类型(CRD): 即 CustomResourceDefinitions。允许用户通过资源清单的方式定义任意全新的资源对象类型,并由 API Server 管理自定义资源的整个生命周期,用户还可以通过定义相应的控制器对自定义资源及其他相关资源进行监视,协调和管理。通常将自定义资源和自定义控制器配合工作的方式统称为 CRD 方式。
2. API Server 聚合(AA): 即 API Server Aggregattion。其前身是用户 API Server(UAS),UAS 允许用户设计一套自定义的 API Server 与 Kubernetes 主 API Server 并行生效,可以在不影响原 API Server 的前提下实现更加复杂和定制化的逻辑和功能,但这种方式对代码开发的要求会比较高。自定义 API Server 可以选择与主 API Server 进行聚合也可以独立存在,但独立存在的方式无法与 Kubernetes 很好的集成,因此自定义 API Server 普遍采用 API Server 聚合的方式。
2.1 自定义资源类型
Kubernetes 原生支持自定义资源的创建和生命周期维护,自定义资源类型一经创建便与 Pod,Job,Secret 等内建资源拥有同等地位,可以像内建资源一样创建并运行自定义资源类型的实例对象。自定义资源配合定制的控制器就可以完成如自动化网络管理,自动化存储管理,自动化证书管理,自动化应用 集群管理等广泛的特性需求。
2.1.1 自定义资源
自定义资源类型的创建
每个 API 资源都有相应的 Group 群组和资源类型,声明自定义资源就必须命名一个与已有群组不重复的新的 Group 群组,新的群组中可以有任意数量的自定义资源类型,并且这些资源类型可以与其他群组中的资源类型重名。
自定义资源类型的声明方式与 Kubernetes 的内建资源的创建方式相同,都是通过资源清单文件进行声明并应用,因为 CustomResourceDefinition 本身就是一种内建资源。一个最简单的自定义资源类型的声明清单示例如下:
# apps-crd.yaml
apiVersion: apiextensions.k8s.io/v1beta1 kind:
CustomResourceDefinition
metadata:
name: apps.foo.bar spec:
group: foo.bar version:
v1 names:
kind: App plural:
apps
scope: Namespaced
各字段解释如下:
apiVersion: CustomResourceDefinition 这一内建资源所在的群组及当前使用的 api 版本。目前为固定字段
kind: 固定字段,表示是在声明自定义资源类型
metadata.name: 自定义资源类型的全名,它由 spec.group 和 spec.names.plural 字段组合而成
spec.group: 自定义资源类型所在群组
spec.version: 自定义资源类型的群组版本
spec.names.kind: 自定义资源的类型,惯例首字母大写
spec.names.plural: 其值通常为 kind 的全小写复数,关系到自定义资源在 REST API 中的 HTTP路径
spec.names.scope: 表示自定义资源的作用范围,Kubernetes 中大部分资源都是命名空间级 (Name-spaced)
自定义资源本身是不支持多版本的,但自定义资源的群组支持多版本。也就是说每一个群组的特定版本里的所有自定义资源都不需要考虑资源版本之间的兼容问题,保证群组内各资源的整体一致性。
spec.names 中还有许多其他字段,不指定则会由 API Server 在创建自定义资源类型时自动填充。
自定义资源类型声明完成后就可以通过 kubectl create -f apps-crd.yaml 或 kubectl apply -f appscrd.yaml 命令进行创建了,创建完成后可通过 kubectl get crd apps.foo.bar -o yaml 命令进行查看。
自定义资源类型创建完成后,其 REST API 的 HTTP 访问路径为/apis/foo.bar/v1/namespaces/de-fault/apps (以 default 命名空间为例)。
自定义资源的创建
自定义资源类型创建完成后就可以创建相应的自定义资源。一个简单的自定义资源的创建清单如下:
# app.yaml apiVersion:
foo.bar/v1 kind: App
metadata: name:
demo
spec:
port: 3333
path: /app
自定义资源声明完成后就可以通过 kubectl create -f app.yaml 或 kubectl apply -f app.yaml 命令进行创建了,创建完成后可通过 kubectl get apps.foo.bar -o yaml 命令进行查看。
自定义资源创建完成后,其 REST API 的 HTTP 访问路径为/apis/foo.bar/v1/namespaces/default/apps/demo (以 default 命名空间为例)。
自定义资源 spec 下的字段只有在被特定控制器或应用按照约定的规范读取解析和处理后才具有实际意义。
终止器
自定义资源和内建资源一样都可以支持终止器(finalizer),终止器允许控制器实现异步的预删除钩子。
对于具有终止器的资源对象第一个删除请求仅仅是为 metadata.deletionTimestamp 字段设置一个值, 而不是删除它,然后触发相应控制器执行自定义处理并删除该资源对象的终止器,最后再一次发出删除请求。
每个资源对象都可以有多个终止器,删除资源对象时,只有当其所有终止器都删除后才会真正被删除。
2.1.2 自定义控制器
在 Kubernetes 中,工作负载(workload)类的资源(如 ReplicaSet,Deployment,StatefulSet,CronJob等运行容器的内建资源)是通过控制器(controller)进行管理的,这些控制器相当于一个状态机,用于控制对应 Pod 的具体状态和行为。
对于自定义资源,同样可以为其编写相应的控制器,进行资源数据的分析处理和 Pod 的状态行为控制。
自定义资源和自定义资制器的配合使用才能创建,配置和管理复杂的有状态应用,真正提供声明式 API 服务,实现新特性的添加和 Kubernetes API 的扩展。
Kubernetes 中控制器的主要工作模式如下:
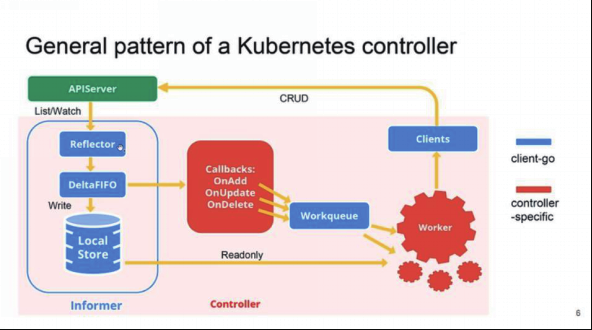
控制器代码主要包括两部分:
客户端 SDK: SDK 是 Kubernetes 官方提供的开发工具包(sdk 是 golang 编写,又称为 client-go),提供诸如 Reflector,Delta FIFO queue,Thread safe Local store,Informer,Indexer, Workqueue 等与API Server 进行交互的通用组件
控制器特定内容: 根据特定控制器提供的特定功能而编写的相应回调函数和处理逻辑。这部分是编写自定义控制器的主要内容
控制器的完整工作流如下:
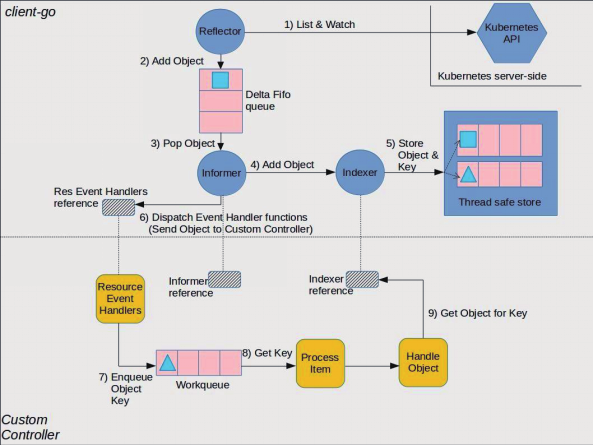
1. Reflector 反射器通过 List&Watch 机制从 API Server 获取资源(包括内建资源和自定义资源)变化
2. Reflector 将获取到的资源添加到 Delta FIFO 队列中
3. Informer 通知器从 Delta FIFO 队列中弹出资源对象
4. Informer 将得到的资源对象传递到 Indexer(索引器)
5. Indexer 为资源对象构建索引,以线程安全的方式将资源数据存储到线程安全的 Key-Value 本地存储中
6. Informer 通过 Dispatch Event Handler 事件分发处理函数将资源对象的 key 发送到自定义控制器
7. 自定义控制器通过 Resource Event Handler 资源事件处理函数将资源对象 key 发送到 Workqueue 工作队列
8. Process Item 任务处理函数从工作队列获取资源对象 key 并将其传递给 Object Handler 资源对象处理函数
9. 资源对象处理函数通过 Indexer 的引用从 Key-Value 本地存储中获取资源对象本身并进行处理
2.1.3 Operator 和 Kubebuilder
声明自定义资源并编写自定义控制器进行 Kubenetes API 扩展的方式对于代码开发有一定的要求。主要的工作内容如下:
初始化项目结构
定义自定义资源
编写自定义资源相关代码
初始化自定义控制器
编写自定义控制器相关代码(即业务逻辑)
这其中除了定义自定义资源和编写业务逻辑是需要针对具体需求单独开发外,其他内容都是通用的,可以自动化完成,因此社会和官方提供了一些 CRD 开发脚手架以帮助开发者无需了解复杂的 Kubernetes API 特性的情况下迅速构建 Kubernetes 扩展应用。目前比较流行的有两个:
Operator Framework: CoreOS 公司(目前属 redhat 旗下)开发和维护 CRD 快速开发框架。它包括 Operator SDK 和 Operator Lifecycle Manager 两部分,前者是 Operator 核心开发工具包,后者对 Operator 提供从安装,更新到运维的全生命周期管理
Kubebuilder: Kubenetes 社区兴趣小组开发和维护的 CRD 快速开发框架。提供与 Operator 类似的功能,但不支持 Operator 生命周期管理
Operator 和 Kubebuilder 的实现原理和主要功能类似,二者均使用控制器工具和控制器运行时,封装结构类似,使用难易度相当,其主要区别如下:
Operator SDK 原生支持 Ansible 和 Helm Operator; Kubebuilder 不支持
Operator SDK 集成 Operator Lifecycle Manager(OLM),提供 Operator 全生命周期管理;
Kubebuilder 不支持
Kubebuilder 使用 Makefile 帮助用户完成操作员的任务(构建,测试,运行,代码生成等); Operator SDK 当前使用内置子命令。Operator SDK 团队将来可能会迁移到基于 Makefile 的方法
Kubebuilder 使用 Kustomize 来构建部署清单; Operator SDK 使用带有占位符的静态文件
Kubebuilder 改善了对 admission 准入和 CRD 转换 webhooks 的支持; Operator SDK 尚未支持
Kubebuilder 提供了更为完善的官方文档
鉴于 Operator Framework 的影响力 ,习惯性将基于 CRD 构建的 Kubernetes 应用称为 Operator。相对于通过 Helm Charts 打包和部署 Kubenetes 应用的方式,Operator 的自动化程度更高,更加符合云原生理念,因此越来越流行,目前越来越多的常用应用推出了自己的 Operator,Kubernetes 社区推出了 OperatorHub 以供用户进行 Operator 的发布的使用。
Operator 是打包,运行和维护 Kubernetes 应用程序的一种方式。一种 Kubernetes 应用程序不仅部署在 Kubernetes 上,还旨在使用和与 Kubernetes 的设施和工具协同工作。开发团队以 Kubernetes 抽象为基础,以实现自动化的整个生命周期。它管理的软件。由于它们扩展了 Kubernetes,因此操作员可以使用大型且不断增长的社区熟悉的术语来提供特定于应用程序的 自动化。适用于程序员,运维人员可以更轻松地部署和运行基础应用程序所依赖的服务。对于 基础架构工程师和供应商,Operator 提供了一种在Kubernetes 集群上分发软件的一致方法,并且通过在发现和纠正应用程序问题之前减少支持负担和异常出现的机会。

Operator 最初由 coreOS 公司(已被 RedHat 收购)开发,逐步成为流行的一种打包,部署和管理Kubernetes/OpenShift 应用的方法。Kubernetes/OpenShift 应用是一个部署在集群上并使用 Kubernetes/OpenShift API 和 kubectl/oc 工具进行管理的应用程序。Operator 类似 于 Helm 和 Template,但是比它们都更加灵活,更加强大,更加方便。
Operator 本质上是一个自定义的控制器。它会在集群中运行一个 Pod 与 Kubernetes/OpenShift API Server 交互,并通过 CRD 引入新的资源类型,这些新创建的资源 类型与集群上的资源类型如 Pod 等交互方式是一样的。同时 Operator 会监听自定义的资源类 型对象的创建与变化,并开始循环执行,保证应用处于被定义的状态。
一直以来,部署和管理 Kubernetes 应用的方法有多种,这里列举较流行的三个:
一、Template 模板是 OpenShift 特有的应用打包方式,它描述了一组对象,同时对这些对 象的配置可以进行参数化处理,生成 OpenShift 容器平台创建的对象列表。在模板中可以设 置所有在项目中有权限创建的任何资源。
不足之处:
无法保证线上资源状态始终与参数设定的结果一致,如手动增加 rc 的副本数时,不会自动恢复到与参数设定的副本数。
在创建的时候设置参数,如果在应用运行时对参数动态更新的话,则需要使用脚本命令使用所有的参数,重新生成资源列表。参数需要额外管理,不可靠。
如果应用有创建的顺序有依赖,则无法满足。
无法根据参数的不同对资源进行条件控制。
二、对于 Kubernetes 熟悉的运维开发人员,常会使用 Helm 来实现。Helm 是 Kubernetes 生态系统中的一个软件包管理工具,与 Template 类似。
不足之处:
需要额外部署 Helm 客户端及 Tiller。
需要额外管理 helm 中的 charts 资源。
无法保证线上资源状态始终与参数设定的结果一致。
如果应用有创建的顺序有依赖,则无法满足。
三、对于熟悉各种自动化工具的运维开发,会使用自动化配置管理工具来完成工作,如 Ansible。利用Ansible 的 k8s 模块,创建各种资源,而且可以充分发挥 Ansible 强大的控制功能。
不足之处:
需要额外部署 Ansible,及对 ansible 访问集群的访问认证。
需要额外管理 ansible 的 playbook 文件。
无法保证线上资源状态始终与参数设定的结果一致。
参数更新时,需要手动执行 ansible playbook 脚本
参数更新时,需要手动执行 helm 脚本
为什么说 Operator 能够更好地解决这类方法不足问题呢?因为它不仅能够很好地满足自 定义打包的需求,同时也弥补了以上三种方式的不足。使用 Operator-sdk 能够非常方便地创 建自定义的 Operator,它支持三种类型:go、ansible、helm。
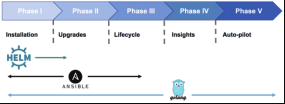
go 类型,它的实现更加灵活,可以随心所欲,扩展性也最强,构建出的 operator 镜像也不大,但是它对于编程能力要求高,同时没有 ansible 和 helm 类型拿来即用,可读性也不及 ansible 与 helm 类型。
ansible 类型,它使用 ansible 的 playbook 方式来定义应用的构建与保证应用的状态,它的实现也很灵活,依赖于 ansible 的模块,但是这使得构建出的 operator 镜像较大,一般为 600 多 M,因为它包含了ansible 应用及默认的各个模块。
helm 类型,它使用 helm 的 charts 方式来定义应用的构建与保证应用的状态,它的镜像一般为 200 多M,但是它的灵活度不及另外两种类型。当然从上图可以看到,不同类型的实现,对应用的管理深度会有所不一样。那么从日常自有应用的开发管理来说,Ansible 是一个不错的选择, 同时对于开发运维团队的技术要求也不会有新增的压力。
2.2 API Server 聚合
API 聚合机制是 Kubernetes 1.7 版本引入的特性,能够将用户扩展的 API 注册到 kube-apiserver(即Kubernetes 核心 API Server)上,仍然通过 API Server 的 HTTP URL 对新的 API 进行访问和操作。
API 聚合机制的目标是提供集中的 API 发现机制和安全的代理功能,将开发人员的新 API 动态地、无缝地注册到 Kubernetes API Server 中进行测试和使用。为了实现这个机制,Kubernetes 在 kube-apiserver 服务中引入了一个 API 聚合层(API Aggregation Layer),用于将扩展 API 的访问请求转发到用户服务的功能。
2.2.1 聚合层
API 聚合层(API Aggregation Layer)在 kube-apiserver 进程内运行。在扩展 API 注册之前,聚合层不做任何事情。要注册 API,用户必须添加一个 APIService 资源对象,用它来申领 Kubernetes API 中 的URL 路径。自此以后,聚合层将会把发给该 API 路径的所有内容(例如 /apis/myextension.mycompany.io/v1/…)代理到已注册的 APIService。
正常情况下,APIService 会实现为运行于集群中某 Pod 内的扩展 API Server。如果需要对增加的资源进行动态管理,扩展 API Server 经常需要和一个或多个控制器一起使用。聚合层支持多个自定义 API Server 对 Kubernetes 的 API 进行横向扩展。
扩展 API Server 与 kube-apiserver 之间的连接应具有低延迟。发现请求应当在五秒钟或更短的时间内从kube-apiserver 往返。可以在 kube-apiserver 上设置 EnableAggregatedDiscoveryTimeout=false 功能开关将禁用超时限制,但此开关将在将来的版本中被删除。
API 聚合功能需要通过配置 kube-apiserver 服务的以下启动参数进行启用:
--requestheader-client-ca-file=/etc/kubernetes/ssl_keys/ca.crt:客户端 CA 证书。
--requestheader-allowed-names=:允许访问的客户端 common names 列表,通过 header 中
--requestheader-username-headers 参数指定的字段获取。客户端 common names 的名称需要在 clientca-file 中进行设置,将其设置为空值时,表示任意客户端都可访问。
--requestheader-extra-headers-prefix=X-Remote-Extra-:请求头中需要检查的前缀名。
--requestheader-group-headers=X-Remote-Group:请求头中需要检查的组名。
--requestheader-username-headers=X-Remote-User:请求头中需要检查的用户名。
--proxy-client-cert-file=/etc/kubernetes/ssl_keys/kubelet_client.crt:在请求期间验证 Aggregator 的客户端 CA 证书。
--proxy-client-key-file=/etc/kubernetes/ssl_keys/kubelet_client.key:在请求期间 验证 Aggregator 的客户端私钥。
如果 kube-apiserver 所在的主机上没有运行 kube-proxy,即无法通过服务的 ClusterIP 进行访问,那么还需要设置--enable-aggregator-routing=true 。
2.2.2 扩展 API Server
API 聚合层提供了扩展 API Server 的动态注册、发现汇总、和安全代理,但是扩展 API Server 本身需要自行开发,并且需要遵循 Kubernetes 的开发规范。扩展 API Server 是以 Kubernetes 中的 Pod 的形式存在的,通常需要与一个或多个控制器一起使用。
官方提供了扩展 API Server 开发样例 sample-apiserver(https://github.com/kubernetes/sample-apiserver),可以此为模板进行开发,但开发和部署步骤 是非常繁琐的。好在可以使用第三方提供的开发框架如 apiserver-builder(https://github.com/kubernetes-incubator/apiserver-builder/blob/master/README.md) 和 service-catalog(https://github.com/kubernetes-incubator/service-catalog/blob/-master/README.md),它们都同时 提供了用于管理新资源的 API 框架和控制器框架,提供了一定的自动化支持。如使用 apiserver-builder 开发扩展 API Server 的关键步骤如下:
# 创建项目目录
mkdir $GOPATH/src/github.com/example/demo-apiserver
# 在项目目录下新建一个名为 boilerplate.go.txt,里面是代码的头部版权声明
cd $GOPATH/src/github.com/example/demo-apiserver curl -o
boilerplate.go.txt
https://github.com/kubernetes/kubernetes/blob/master/hack/boilerplate/boilerplat e.go.txt
# 初始化项目
apiserver-boot init repo --domain example.com
# 创建一个非命名空间范围的 api-resource
apiserver-boot create group version resource --group demo --version v1beta1 -- non-namespaced=true
--kind Foo
# 创建 Foo 这个 api-resource 的子资源
apiserver-boot create subresource --subresource bar --group demo --version v1beta1 --kind Foo
# 生成上述创建的 api-resource 类型的相关代码,包括 deepcopy 接口实现代码、 versioned/unversioned 类型转换代码、api-resource 类型注册代码、api-resource 类型的 Controller 代 码、api-resource 类型的 AdmissionController 代码 apiserver-boot build generated
# 直接在本地将 etcd,apiserver,controller 运行起来
apiserver-boot run local
2.2.3 APIService 注册
扩展 API Server 是作为 APIService 注册到 Kubernetes 的核心 API Server 上的,启用 API Server 的聚合功能后就可以通过 APIService 资源对象注册 API 了。APIService 资源清单文件如下:
apiVersion: apiregistration.k8s.io/v1beta1 kind:
APIService
metadata:
name: v1beta1.customapi.k8s.io spec:
service:
name: customapi namespace:
custom
group: customapi.k8s.io version:
v1beta1 insecureSkipTLSVerify: true
groupPriorityMinimum: 100
versionPriority: 100
上述清单文件中 apiVersion 和 kind 的值是固定的, metadata.name 的值是由 spec.version 和spec.group 的值拼接而来。APIService 的 API 群组为 customapi.k8s.io,版本为 v1beta1,其 API URL 则为/apis/customapi.k8s.io/v1beta1 。对应的后端扩展 API Server 为 custom 命名空间下的 customapi 服务,该服务将负载到运行扩展 API Server 的 Pod 上。
kubectl create 命令创建成功后,通过 Kubernetes API Server对/apis/customapi.k8s.io/v1beta1 路径的访问都会被 API 聚合层代理转发到后端服务 customapi.custom.svc 上。
Kubernetes 内置的资源监控组件 Metrics Server(https://github.com/kubernetes-incubator/metrics-server) 是一个典型的 API 聚合案例,可以通过它学习聚合 API Server 的开发和部署。
2.2.4 CRD 与 AA
相同
CRD 和 AA 两种方式都是在保证 API 稳定性的前提下的 API 扩展方案,均支持横向扩展, 从实现上均采用了资源+控制器的模式提供声明式 API 服务,使用上二者提供了统一的访问方式,内部差异外部请求者是无感知的。此外,通过 CRD 或 AA 创建自定义资源时,与在 Kubernetes 平台之外实现它相比,能够提供诸如 CRUD,通用元数据,通用客户端库,资源显示与字段编辑,内置认证授权模块等部分 Kubernetes原生特性的支持:
异同
尽管存在诸多共通之处,但二者的扩展维度是截然不同的,CRD 扩展的是 API 资源,直接复用 Kuber-netes 核心 API Server,属于轻量级扩展,这种方式简单易用,无论是代码开发还是部署维护都很方便快捷,但其功能特性受限于核心 API Server,无法提供注入额外的认证授权和准入机制,无法使用其他存储层等。
API Server 聚合扩展的是 API Server 本身,允许设计并运行单独的 API Server,与核心 API Server 并行生效,认证授权,准入机制和存储层等的复用都是可选的,提供了更高级的 API 功能和更大的灵活性。
通常情况下建议采用 CRD 方式扩展 API,CRD 简单够用,开发维护难度和成本都远低于 AA 方式,除非必要不要考虑 AA 方式。
更多 CRD 和 AA 方式的比较可参考官方文档(https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/custom-resources/#api-server-aggregation)。

- 争议 | 多个数据中心上SDN背景下,跨数据中心二层打通是否有必要?
- 17 个 Ceph 日常运维常见难点和故障的解决办法 | 运维进阶
- 企业终端防御体系十大措施的设计部署与安全运营 | 最佳实践
- 争议 | 基于存储网关 vs 基于存储引擎,两种存储双活实现方式各有什么优劣势?
- 「数据库架构」三分钟搞懂事务隔离级别和脏读
- 大型三甲医院基础集成信息平台架构设计案例
- 【数据库架构】Apache Couchdb 最终一致性
- 【PostgreSQL架构】为什么关系型数据库是分布式数据库的未来
- 【PostgreSQL 】PostgreSQL 12的8大改进,性能大幅度提升
- 【PostgreSQL 架构】PostgreSQL 11和即时编译查询
- 【PostgreSQL】PostgreSQL扩展:pg_stat_statements 优化SQL
- 「PostgreSQL」用MapReduce的方式思考,但使用SQL
- 「PostgreSQL技巧」Citus实时执行程序如何并行化查询
- 「云转型」 可证实的企业云转型战略
- 「首席看架构」CDC (捕获数据变化) Debezium 介绍
- 「企业微服务架构」怎么弥合不同微服务团队之间的差距
- 微服务架构系列01:容器设计原则
- Vue3+ElementPlus+Koa2 全栈开发后台系统
- 报告 - 麦肯锡全球研究院 分析时代:在数据驱动的世界中竞争
- 详解thinkphp+redis+队列的实现代码