防脱洗发水是个伪命题?8979条数据告诉你答案
最近,小Q陷入了一个脱发死循环。
照镜子隐隐若现的头皮,洗完头地上乌压压的断发,让他无时无刻不担心自己的发量,一担心怎么办呢?挠头呗!
越脱发,越担忧;越担忧,越挠头;越挠头,越脱发...

“为什么不试试防脱洗发水呢?我有好几个同事在用。”我实在不忍心小Q继续循环下去。
小Q义正言辞:“我听说那些玩意儿没什么用啊!现在产品都喜欢打概念!”
“没有调查就没有发言权,你这样下定论太主观了。要不咱们从数据的角度来论证一下,防脱洗发水是不是个伪命题?”
“有点意思!”小Q来了劲儿。
说干就干。要论证防脱洗发水是不是个伪命题,得先搞清楚谁对防脱洗发水最有发言权。
答案显而易见,买过防脱洗发水的朋友,他们对产品的评价,是最简单粗暴的论据。
所以,我们以淘宝为例,爬取5款热销洗发水评价数据,综合分析效果。
01 数据获取
目前淘宝反爬(尤其是滑块等验证)实在让人头大,但是呢,我发现爬取评价数据,并不一定需要和登录滑块硬刚,用selenium是可以绕过的。
部分代码如下,对爬取感兴趣的同学可以在文末链接下载详细代码,不感兴趣的同学直接往下滑:
import pandas as pd
from selenium import webdriver
import random
import os
import time
driver = webdriver.PhantomJS()
def get_page(driver):
result = pd.DataFrame()
for i in driver.find_elements_by_xpath('//div[@class = "rate-grid"]/table/tbody/tr'):
try:
content = i.find_element_by_xpath('td[@class = "tm-col-master"]/div[@class = "tm-rate-content"]').text
#评价日期
date = i.find_element_by_xpath('td[@class = "tm-col-master"]/div[@class = "tm-rate-date"]').text
#购买产品
sku = i.find_element_by_xpath('td[@class = "col-meta"]/div[@class = "rate-sku"]').text
#用户名
username = i.find_element_by_xpath('td[@class = "col-author"]/div[@class = "rate-user-info"]').text
append_time = None
append_content = None
except:
content = i.find_element_by_xpath('td[@class = "tm-col-master"]/div[@class = "tm-rate-premiere"]/div[@class = "tm-rate-content"]').text
#评价日期
date = i.find_element_by_xpath('td[@class = "tm-col-master"]/div[@class = "tm-rate-premiere"]/div[@class = "tm-rate-tag"]/div[@class = "tm-rate-date"]').text
#购买产品
sku = i.find_element_by_xpath('td[@class = "col-meta"]/div[@class = "rate-sku"]').text
#用户名
username = i.find_element_by_xpath('td[@class = "col-author"]/div[@class = "rate-user-info"]').text
append_time = i.find_element_by_xpath('td[@class = "tm-col-master"]/div[@class = "tm-rate-append"]/div[1]').text
append_content = i.find_element_by_xpath('td[@class = "tm-col-master"]/div[@class = "tm-rate-append"]/div[2]').text
df = pd.DataFrame({'用户名':[username],'购买产品':[sku],'评价日期':[date],'初次评价内容':[content],
'追评时间':[append_time],'追评内容':[append_content]})
result = pd.concat([result,df])
return result,driver
02 热门关注点
我们爬了5款产品,共计8979条评价,然后把评价中TOP15高频词做成词云图:

很明显,消费者对于防脱洗发水的诉求简单粗暴,效果是第一核心关注点。虽然“没用”也在TOP15高频词中,但整体而言,正面词汇更加集中,消费者并不吝给出不错、好评、好用等评价。
除效果外,味道成了消费者的“论点”,毕竟洗完头之后,洗发水是通过味道来散发魅力。
防脱洗发水,营造的防脱希望十分重要,不少消费者在收到货后,都已经开始期待头皮变得浓密。
下面,我们从情感分析的角度来切入。
03 防脱洗发水情感分析
情感打分
虽然很多人自诩是一个没有感情的杀手,但说出来的每一句话却都洋溢着“感情”。

拿刚爬到的评论数据来说,任何一个消费者在评论时都带着和产品相关的主观情感,要么觉得好,要么觉得烂,只是个体对于好和烂的感知程度不同罢了。
So,这里我们用SnowNLP这个库,为每条评价进行情感打分,通过分值来量化情感倾向。(分值在0-1之间,越靠近0负面倾向越强,越接近1则正面情感越强)
from snownlp import SnowNLP sens = [] for text in final_re['初评内容']: s = SnowNLP(text) sens.append(s.sentiments) #final_re是评价数据源 final_re['初评情感评分'] = sens
一个回车,打分完毕!
评分总览
看看5款热销防脱洗发水的平均情感评分:

尴尬,8000多条评论最终平均下来竟然是如此中性的倾向(我们暂且认为0.5是中性)。是大多数客户都无所谓,还是两极分化严重呢?
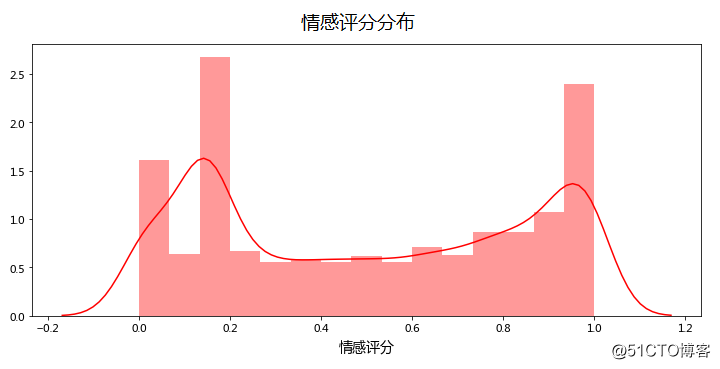
防脱洗发水的评价两极分化极其严重。28.95%的消费者给出了超0.8分的正向评价,他们极尽吹捧之能事,甚至可以说是“歌颂”防脱洗发水,感谢再“生”之恩。32.81%的消费者评价情感小于0.2,他们恨不得跳脚大骂,觉得智商受到了侮辱。
品牌情感细分
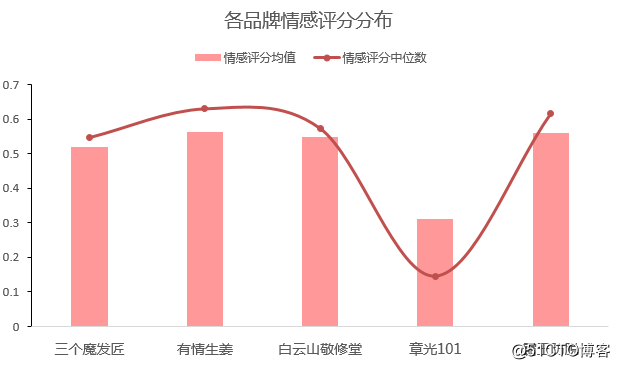
除章光101外,其他品牌情感评分均值都在0.5之上,情感以积极为主。为什么章光101平均值、中位数如此之低?这么多负面评价品牌都无动于衷吗?
数据分析要敢于直面惨淡的数据,敢于正视打脸的现实。

通过进一步观察评价内容,我们发现问题出在情感评分本身。不少消费者给出好评时,会先诉说自己被脱发折磨的多么苦不堪言,最后话锋一转开始夸洗发水。(章光101此类评价尤多)
很遗憾,snownlp这个库的脑回路转的太慢,他总是沉浸在悲痛的前奏不能自拔,给出了低分。再加上我们并未针对洗发水评价进行训练,会存在一些评分疏漏。
这里是抛砖引玉,给出评价分析,建议大家尝试更多的评分玩法
最后,小Q开始用肉眼检索评价。许久之后,甩了甩稀薄的刘海,自信的总结:
“如果剔除掉评分误判,消费者对于防脱洗发水的使用情感会更加正向。所以,从评价角度来看,我觉得防脱洗发水并不是一个伪命题,哥已经下单了!”
小Q能否成功镇守发际线?且听小Z下回分解。
注:文中爬取评价代码和数据源,已上传至github
https://github.com/seizeeveryday/DA-cases/tree/master/Hair

- 金州勇士4年3冠的成功秘诀!Python数据可视化分析告诉你答案
- 复仇者联盟谁才是绝对 C 位?Python分析9万条数据告诉你答案
- “史上最强春节档”来袭!数据告诉你这几部影片最值得看
- 十万条评论告诉你,给《流浪地球》评1星的都是什么心态? | Alfred数据室
- 5个典型实例告诉你:什么是数据可视化
- 数据结构(C语言版 第2版)课后习题答案 严蔚敏 编著
- 自学成才的数据科学家告诉你5个学习大数据的正确姿势!
- 《人在囧途》系列 - 我30岁了,转行学编程可以吗? 排除法告诉你答案
- 数据挖掘与技术第三版部分答案
- 姐告诉你:面试时26道大题的标准答案
- spring面试题集锦:注解+MVC+数据访问,附答案
- 数据告诉你:中国城市谁在腾飞?谁在衰落?
- Day 9:(3)数据的插入、修改、删除实训_参考答案
- 为什么学习游戏建模的人很难坚持下来,这篇文章告诉你答案
- 微软的22道数据结构算法面试题(含答案)
- 微博和Twitter数据告诉你,什么是大事件营销!
- 诸葛io告诉你大数据行业5个职位方向
- 精选微软等公司数据结构+算法面试100题带答案(41-60)
- 微软的22道数据结构算法面试题(含答案)
- 大数据如何学习,告诉你正确的学习姿势