Python 基础系列--开篇
学习 Python 的过程让我产生了以下改变
找回当初选择计算机的初心
开始主动学习,关注新技术
尝试编写程序提高重复工作的效率
编码侧重可读性和性能
分享己学知识和感悟,寻找志同道合的朋友
Python 能带给我的,同样也能带给你,于是我决定尝试写一些 Python 基础系列文章,带你入门 Python,达到能使用 Python 解决日常问题的目的。同时也希望 Python 这门语言能带给你学习和编码的快乐。
如果不是基于以上目的,那么你仍有理由学习编程,学习 Python,原因如下:
李开复老师说过:“人工智能将快速爆发,十年后 50% 的人类工作将被 AI 取代”。
华尔街的交易员,这个曾经很光鲜的职业很快消失了;未来的保安也会部分消失,因为摄像头的监控,加上一些机器人巡视,已经不需要保安了;司机可能也会消失,还包括一些非常高端的白领,比如说放射科医生,他们的看片能力不如机器人。
可以思考一下,自己的工作在十年后是否会被人工智能取代,如果会,如何才能体现自己的价值呢 ?不妨从现在起就要开始做一些机器不能做的事情,一些人机结合的事情,比如编程,它是一门技术,也是一门艺术,而且人工智能最亲近的语言就是 Python ,所有语言当中,Python 是最接近人类思维的,代码的风格也是人类可读的, 比其他语言更易学,易用。常言道:人生苦短,我用 Python。
如果你决定开始学习 Python,请继续往下看。
1. 关于 Python 版本选择
Python 目前有两个版本 Python2 和 Python3,最新版本分别是 Python2.7.15 和 Python3.7.0 。Python2 即将停止更新,第三方的库也会全部移植到 Python3,Python3 做了更多优化,可以说 Python3 是未来,初学者可以直接选择 Python3 来学习,其实根本不用纠结学习 Python2 和 Python3,他们的语法几乎没有差别。
2. 安装 Python 环境
官方网站: www.python.org。[由于微信不允许外部链接,请点击下面的阅读原文访问文中的链接]。
对于 linux 系统,需要从官方下载源码编译安装,假定你有 linux 系统管理经验,可自行安装,否则请换回 windows。
对于 windows 系统,如果操作系统是 32 位,下载 官方 32 位安装程序;如果是 64 位,下载 官方 64 位安装程序, 当然也可以下载官方 32 位安装程序,如果下载速度太慢,请从国内镜像下载。安装时注意勾选添加到环境变量,否则安装完成后需要手动添加,这样才能确保在任意目录下的命令行启动 Python 程序。
对于 mac 系统,从官网下载 mac 安装程序,如果下载速度太慢,请从国内镜像下载,双击运行并安装。
3. 了解 Python 的解释器
Python 是开源的,任何人,只要你够厉害,你都可以编写 Python 的解释器。
CPython:是官方版本的解释器,使用 C 语言编写,因此叫 CPython 。从官方下载的安装包安装后,我们就获得了 CPython 解释器,也是使用最广泛的解释器,本系列所有代码也都在 CPython 下执行。
IPython:不是正在意义上的解释器,仍使用 CPython,只不过加了一层外壳,使执行结果在字符界面看起来更美观,如果你喜欢交互式环境下进行数据分析,可以使用这个。CPython 用 >>> 作为提示符,而 IPython用 In [序号]: 作为提示符。
PyPy:是使用 Python 实现的 Python 解释器,提供了 JIT 编译器和 沙盒 功能,目的是做到 动态编译
因此运行速度比 CPython 要快。绝大部分 Python 代码都可以在 PyPy 下运行,但是 PyPy 和 CPython 有一些是不同的,这就导致相同的 Python 代码在两种解释器下执行可能会有不同的结果。如果你的代码要放到PyPy 下执行,就需要了解 PyPy 和 CPython 的不同点。
Jython:是使用 Java 实现 Python 解释器,可以直接把 Python 代码编译成 Java 字节码执行。
IronPython:是运行在微软 .Net 平台上的 Python 解释器,可以直接把 Python 代码编译成 .Net 的字节码。
对于初学者,使用 CPython 已经足够,其他解释器,做到了解即可。
4. 关于开发工具选择
有很多人包括我,在最开始阶段总是纠结使用哪个工具:
使用 vim 还是 emacs 还是 ue ?
使用 eclipse 还是 pycharm ?
这里我想说的是,工具它一点都不重要,也不会特别提高你编码效率,编程,耗时的是你思考的过程,而不是写代码的过程,你完全可以使用 Python 自带的 ide 或简单的记事本编写 Python 代码,然后在命令窗口执行:
python filename.py
即可。但是如果你碰巧会某个编辑工具或 开发工具,那么就使用它好了,如果没有使用过什么开发工具,那么请选择 Pycharm 社区版本(免费),它是最好的 Python 编程工具,没有之一。
5. 从科学计算器开始
编程是将问题数据化的一个过程,数据离不开数字,Python 的数字运算规则和我们在小学初中学习的四则运算规则是一样的,即使不使用 Python 来编写复杂的程序,也可以把它当作一个强大的科学计算器。初学者可以使用 Python 来代替你的计算器,先感觉下 Python 的魅力,命令窗口输入 Python 回车后进入交互式环境,如下所示:
Python 3.6.5 (v3.6.5:f59c0932b4, Mar 28 2018, 17:00:18) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>>
常见的科学计算如下
>>> 2 + 2
4
>>> 50 - 5*6
20
>>> (50 - 5*6) / 4
5.0
>>> 8 / 5 # 总是返回一个浮点数
1.6
>>> 19 / 3 # 整数除法返回浮点型
6.333333333333333
>>>
>>> 19 // 3 # 整数除法返回向下取整后的结果
6
>>> 17 % 3 # %操作符返回除法的余数
1
>>> 5 * 3 + 2.0
17.0
Python 可以使用**操作来进行幂运算:
>>> 5 ** 2 # 5 的平方
25
>>> 2 ** 7 # 2的7次方
128
在交互模式中,最后被输出的表达式结果被赋值给变量 _ 。这能使您在把Python作为一个桌面计算器使用时使后续计算更方便,例如:
>>> 1+2
3
>>> _+3
6
>>> tax = 12.5 / 100
>>> price = 100.50
>>> price * tax
12.5625
>>> price + _
113.0625
>>> round(_, 2)
113.06
Python 数字类型转换:
>>> int(1.2) #将一个浮点数据转换为整数
1
>>> int(1.6) #将一个浮点数据转换为整数
1
>>> int("4") #将一个整数字符串转换为整数
4
>>> float(2)
2.0
>>> complex(2) #将x转换到一个复数,实数部分为 x,虚数部分为 0。
(2+0j)
>>> complex(2,3) # 将 x 和 y 转换到一个复数,实数部分为 x,虚数部分为 y。x 和 y 是数字表达式
(2+3j)
>>>
常用的数学函数如下表格所示:
| 函数 | 返回值(描述) |
|---|---|
| abs(x) | 返回数字的绝对值,如abs(-10)返回10 |
| ceil(x) | 返回数字的上入整数,如math.ceil(4.1)返回5 |
| exp(x) | 返回e的x次幂(ex),如math.exp(1)返回2.718281828459045 |
| fabs(x) | 返回数字的绝对值,如math.fabs(-10)返回10.0 |
| floor(x) | 返回数字的下舍整数,如math.floor(4.9)返回4 |
| log(x) | 如math.log(math.e)返回1.0,math.log(100,10)返回2.0 |
| log10(x) | 返回以10为基数的x的对数,如math.log10(100)返回2.0 |
| max(x1,x2,…) | 返回给定参数的最大值,参数可以为序列。 |
| min(x1,x2,…) | 返回给定参数的最小值,参数可以为序列。 |
| modf(x) | 返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。 |
| pow(x,y) | x**y运算后的值。 |
| round(x[,n]) | 返回浮点数x的四舍五入值,如给出n值,则代表舍入到小数点后的位数。 |
| sqrt(x) | 返回数字x的平方根。 |
6. 使用 help 方法获取 Python 的帮助
在 Python 的世界里,一切都是对象,你可以定义一个变量,在使用这个变量时,你可能需要知道它有哪些方法,你不可能记忆所有的方法,但你可以通过 help(类名/对象名) 查看其帮助信息,以便快速选用你需要的方法。
例如,定义一个字符串,我想知道 python 提供的字符串方法有哪些,可以这样做:
>>> a="hello,world,hello,python" #定义了一个字符串
>>> type(a) #查看其变量的类型
<class 'str'>
>>> help(str) #查看 str 类的帮助信息
Help on class str in module builtins:
class str(object)
| str(object='') -> str
| str(bytes_or_buffer[, encoding[, errors]]) -> str
|
| Create a new string object from the given object. If encoding or
| errors is specified, then the object must expose a data buffer
| that will be decoded using the given encoding and error handler.
| Otherwise, returns the result of object.__str__() (if defined)
| or repr(object).
| encoding defaults to sys.getdefaultencoding().
| errors defaults to 'strict'.
|
| Methods defined here:
|
| __add__(self, value, /)
| Return self+value.
|
| __contains__(self, key, /)
| Return key in self.
......
|
| encode(...)
| S.encode(encoding='utf-8', errors='strict') -> bytes
|
| Encode S using the codec registered for encoding. Default encoding
| is 'utf-8'. errors may be given to set a different error
| handling scheme. Default is 'strict' meaning that encoding errors raise
| a UnicodeEncodeError. Other possible values are 'ignore', 'replace' and
| 'xmlcharrefreplace' as well as any other name registered with
| codecs.register_error that can handle UnicodeEncodeErrors.
|
| endswith(...)
| S.endswith(suffix[, start[, end]]) -> bool
|
| Return True if S ends with the specified suffix, False otherwise.
| With optional start, test S beginning at that position.
| With optional end, stop comparing S at that position.
| suffix can also be a tuple of strings to try.
| format(...)
| S.format(*args, **kwargs) -> str
|
| Return a formatted version of S, using substitutions from args and kwargs.
| The substitutions are identified by braces ('{' and '}').
|
| format_map(...)
| S.format_map(mapping) -> str
|
| Return a formatted version of S, using substitutions from mapping.
| The substitutions are identified by braces ('{' and '}').
|
| index(...)
| S.index(sub[, start[, end]]) -> int
|
| Return the lowest index in S where substring sub is found,
| such that sub is contained within S[start:end]. Optional
| arguments start and end are interpreted as in slice notation.
|
| Raises ValueError when the substring is not found.
|
| isalnum(...)
| S.isalnum() -> bool
|
| Return True if all characters in S are alphanumeric
| and there is at least one character in S, False otherwise.
|
| isalpha(...)
| S.isalpha() -> bool
|
| Return True if all characters in S are alphabetic
| and there is at least one character in S, False otherwise.
|
| isdecimal(...)
| S.isdecimal() -> bool
|
| Return True if there are only decimal characters in S,
| False otherwise.
|
| isdigit(...)
| S.isdigit() -> bool
|
| Return True if all characters in S are digits
| and there is at least one character in S, False otherwise.
|
| isidentifier(...)
| S.isidentifier() -> bool
|
| Return True if S is a valid identifier according
| to the language definition.
|
| Use keyword.iskeyword() to test for reserved identifiers
| such as "def" and "class".
|
| islower(...)
| S.islower() -> bool
|
| Return True if all cased characters in S are lowercase and there is
| at least one cased character in S, False otherwise.
|
| isnumeric(...)
| S.isnumeric() -> bool
|
| Return True if there are only numeric characters in S,
| False otherwise.
|
......
|
| isupper(...)
| S.isupper() -> bool
|
| Return True if all cased characters in S are uppercase and there is
| at least one cased character in S, False otherwise.
|
| join(...)
| S.join(iterable) -> str
|
| Return a string which is the concatenation of the strings in the
| iterable. The separator between elements is S.
|
| split(...)
| S.split(sep=None, maxsplit=-1) -> list of strings
|
| Return a list of the words in S, using sep as the
| delimiter string. If maxsplit is given, at most maxsplit
| splits are done. If sep is not specified or is None, any
| whitespace string is a separator and empty strings are
| removed from the result.
|
......
从上面的帮助信息中我们看到有个 split 方法可以分割字符串,可以返回一个列表,调用下试试看:
>>> a.split(",")
['hello', 'world', 'hello', 'python']
>>> type(a.split(","))
<class 'list'>
>>> help(list)
Help on class list in module builtins:
class list(object)
| list() -> new empty list
| list(iterable) -> new list initialized from iterable's items
|
| Methods defined here:
|
| __add__(self, value, /)
| Return self+value.
|
......
|
| append(...)
| L.append(object) -> None -- append object to end
|
| clear(...)
| L.clear() -> None -- remove all items from L
|
| copy(...)
| L.copy() -> list -- a shallow copy of L
|
| count(...)
| L.count(value) -> integer -- return number of occurrences of value
|
| extend(...)
| L.extend(iterable) -> None -- extend list by appending elements from the iterable
|
| index(...)
| L.index(value, [start, [stop]]) -> integer -- return first index of value.
| Raises ValueError if the value is not present.
|
| insert(...)
-- More --
这里我们看到了关于 list 这个类,Python 提供的所有方法,可以直接调用,例如统计列表中单词 hello 的个数:
>>>a="hello,world,hello,python"
>>> a.split(",").count("hello")
2
关于类中变量或方法的标识符号说明
(1)_xxx "单下划线 " 开始的成员变量叫做保护变量,意思是只有类实例和子类实例能访问到这些变量,
需通过类提供的接口进行访问;不能用'from module import *'导入。
(2)__xxx 类中的私有变量/方法名 (Python的函数也是对象,所以成员方法称为成员变量也行得通。),
" 双下划线 " 开始的是私有成员,意思是只有类对象自己能访问,连子类对象也不能访问到这个数据。
(3)__xxx__ 系统定义名字,前后均有一个“双下划线” 代表python里特殊方法专用的标识,如__init__()代表类的构造函数。
如果暂时看不懂可以先不理会这些,主要是学会使用 help(obj) 函数 来获取关于类的最专业的帮助信息,这里不联网也可以使用,不需要查搜索引擎,养成这个习惯,可以让你在编码过程中保持专注。
7. 使用浏览器查看 Python 的帮助
如果你不喜欢在字符界面查看帮助信息,你可以使用浏览器来查看,命令如下
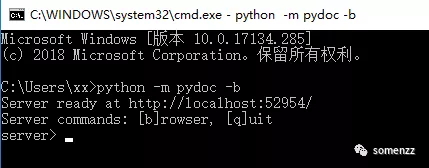 调用浏览器命令
调用浏览器命令
浏览器界面如下所示:
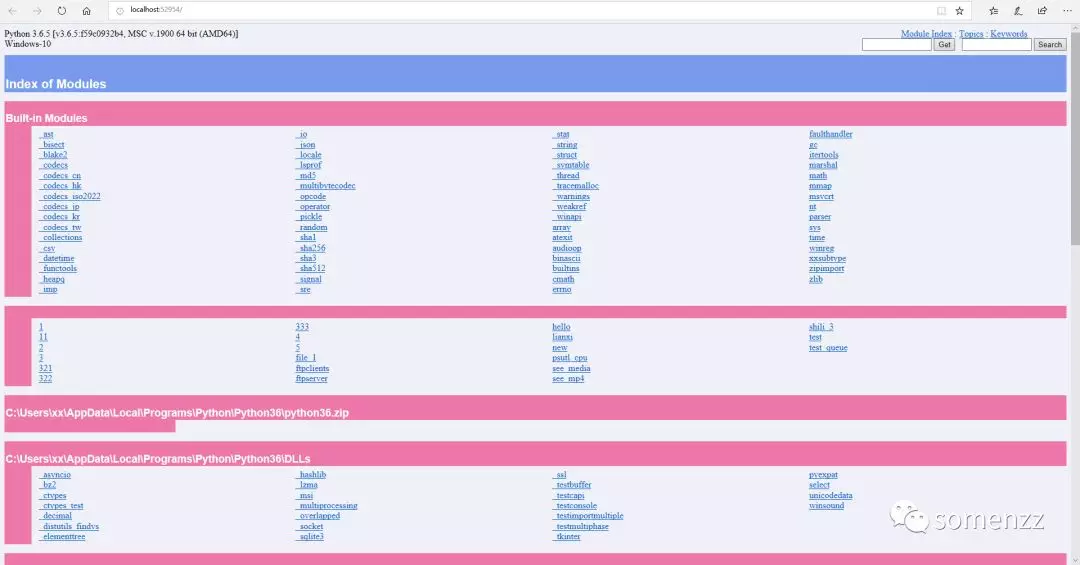
用浏览器查看 Python 的帮助文档
这里可以检索模块的帮助信息,非常方便和直观,建议你经常使用这个,而不是搜索引擎,防止某度会转移的你稀缺的注意力资源。

- Python基础系列(五)类和对象,让你更懂你的python代码
- 2使用Python语言和Numpy库来构建神经网络模型-波士顿房价预测任务实战案例(百度架构师手把手带你零基础实践深度学习原版笔记系列)
- python系列四.1(numpy基础)
- Python3 爬虫基础系列教程(亲测有效)
- 【脚本语言系列】关于Python基础知识函数缓存,你需要知道的事
- python系列一:python3基础语法
- 自动化运维Python系列(三)之基础函数和文件操作
- python基础系列(三)---set、collection、深浅拷贝
- Python入门系列教程(一)基础
- 【脚本语言系列】关于Python基础知识文件操作,你需要知道的事
- Python连载系列之Python语法基础3:Python中的字符串和数据结构
- 【脚本语言系列】关于Python基础知识容器,你需要知道的事
- 《电工实验室基础生存技能》系列教学视频第一季第一集——开篇
- 深度学习笔记 Day7 python基础知识系列(仅本人自用)
- 【脚本语言系列】关于Python基础知识映射器和过滤器,你需要知道的事
- 时间序列预测基础教程系列(5)_Python中数据可视化方法汇总
- Python基础教程系列目录,最全的Python入门系列教程!
- 编程语言系列(五)--python语言基础知识点总结
- python-面向对象(一)——开篇基础
- python学习系列之python装饰器基础(5)---多装饰器的使用