Python爬虫进阶必备 | 关于某查猫查询参数的加密逻辑分析
关于某查猫查询参数的加密逻辑分析
先上链接:
aHR0cHM6Ly93d3cucWljaGFtYW8uY29tLw==
抓包分析
找到要分析的参数,通过首页的检索栏,输入企业名称关键字点击查询就可以抓到类似下面的两个包。

上图标记出来的
mfccode就是需要分析的加密参数
同样的我留意到在上图选中的上一个请求,看着像加密的请求,接下来通过断点来分析是否为加密位置
加密定位
在这个请求上打上XHR 断点
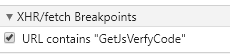
重新发起请求之后就能看到成功断上

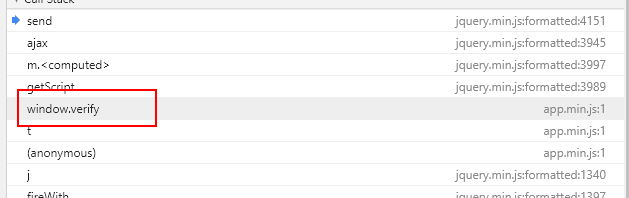
通过分析堆栈找到下图这个位置找到了加密的位置

通过断点可以找到加密生成的地方

或者在堆栈的位置找到下图这个位置也可以快速定位到加密的位置
加密分析
找到加密的位置后接下来就要分析加密的逻辑了,打上断点可以看到这里进入了一个
VM中

我们复制到美化网站中格式化后分析
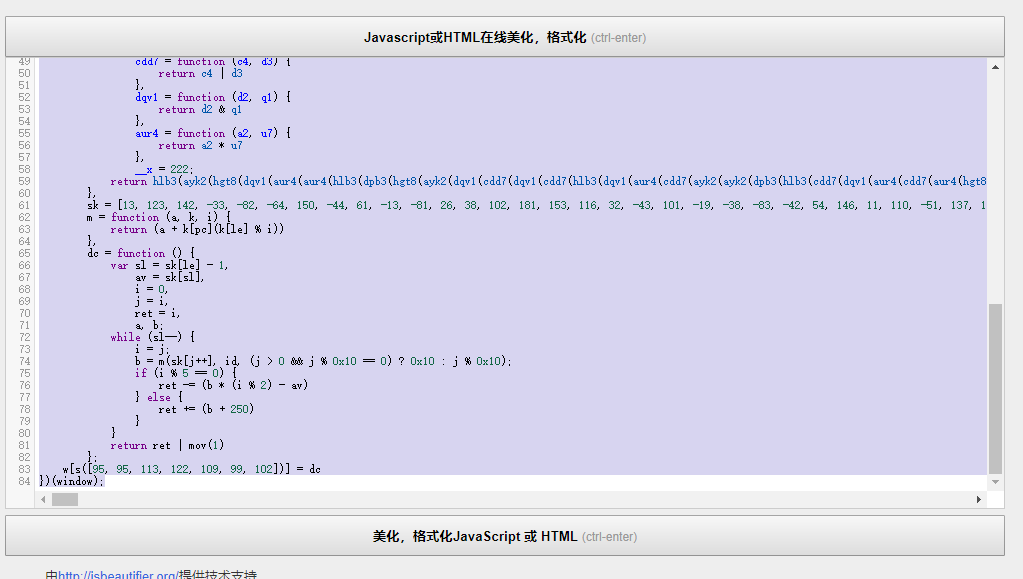
在编辑器中可以大致看到这段代码对
cookie中的
qznewsite.uid字段进行了操作
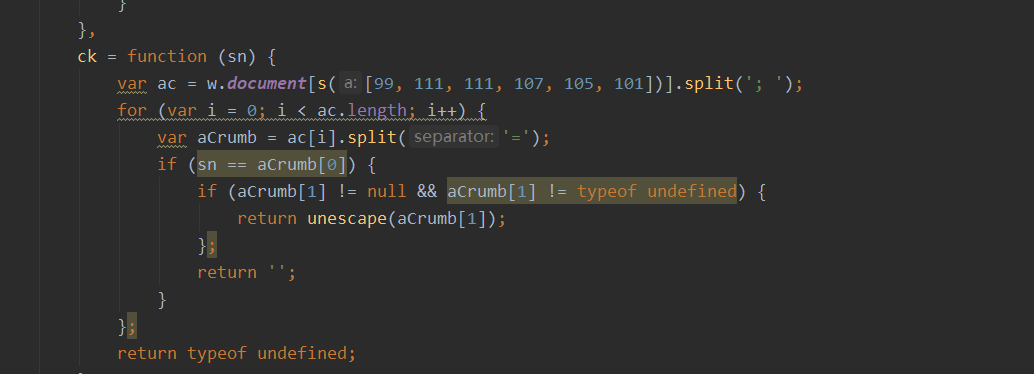
最后将
dc方法的结果返回给了
window.__qzmcf,这个和我在网页上断点的结果相对应
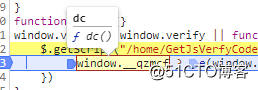
只要能跑通这段 js 就可以完成这段加密了。
经过修改可以正常运行了,主要解决的就是关于 node 中调用 window、document 的问题

但是将结果带入到 Python 代码里并没有如预期一样返回搜索结果,而是返回了登陆的界面,这个结果让我十分费解。
刚刚开始一直以为是我爬虫代码的问题,之后突然想到,这个 js 代码是由对方返回给客户端的,所以这个 js 代码应该动态的。
经过对比,发现
mov以及
sk的长数组都是动态的,或许还有其他的代码是动态的不过这间接的验证了我的猜测。
所以 js 加密的代码写死调用是没有办法完成破解的,想通这一点,我只要将返回回来的 js 代码动态的调用就可以了。
第一步、将 cookie 传入,替换为第一次访问首页返回的 cookie 即可,不过之后测试这一步貌似没有验证,直接写死也是可以的。
第二步、将服务端返回的动态调用,只要在静态的代码基础上小修一下就行了,例如声明
window,
document这些操作,之前的文章均有提及
第三步、调用
window.__qzmcf这个方法,完成加密参数的生成
完成上面的步骤之后重新调用就可以正确拿到网页的结果了。
总结
有两周没有练习 js 逆向了所以分析的逻辑有点乱,不过大致的分析流程都是类似的,这里一定要说的就是学习 js 真的不吃亏,很多地方都有用到。
这个网站就这个加密参数有点意思,改写 js 的思路值得学习。
今天就到这里,下次再会~
Love & Share

[ 完 ]


- Python爬虫进阶必备 | XX快药 sign 加密分析与加密逻辑复写
- Python爬虫进阶必备 | 某电竞加密参数分析( 什么花里胡哨,三行代码完成加密)...
- Python爬虫进阶必备 | XX快药 sign 加密分析与加密逻辑复写
- Python爬虫进阶必备 | 某电竞加密参数分析( 什么花里胡哨,三行代码完成加密)
- Python爬虫进阶必备 | XX文学加密分析实例
- Python爬虫进阶必备 | X薯中文网加密分析
- Python爬虫进阶必备 | 关于 AES 的案例分析与总结(一)
- Python爬虫进阶必备 | 某小说(XX猫)网站加密分析
- Python爬虫进阶必备 | X咕视频密码与指纹加密分析
- Python爬虫进阶必备 | XX同城加密分析
- Python爬虫进阶必备 | X天下与XX二手房密码加密分析
- Python爬虫进阶必备 | X薯中文网加密分析
- Python爬虫进阶必备 | 某小说(XX猫)网站加密分析
- Python爬虫进阶必备 | X薯中文网加密分析
- Python爬虫进阶必备 | 关于MD5 Hash 的案例分析与总结
- Python爬虫进阶必备 | X笔网密码加密分析
- Python爬虫进阶必备 | XX同城加密分析
- Python爬虫进阶必备 | 关于AES 的案例分析与总结
- Python爬虫进阶必备 | XX读书window.__DATA加密分析
- Python爬虫进阶必备 | 关于 AES 的案例分析与总结(一)