面板数据里处理多重高维固定效应的神器, 还可用工具变量处理内生性

可有偿投稿计量经济圈,计量相关则可
邮箱:econometrics666@sina.cn
所有计量经济圈方法论丛的do文件都放在社群里,可以直接取出使用运行,也欢迎到研究小组交流访问.感谢邹恒甫教授对计量经济圈的关注和支持.

今天,我们“面板数据研究小组”将为计量经济圈的圈友引荐一个处理多重高维固定效应的方法(multiple high dimensional fixed effects)。我们经常听说面板数据相对于截面数据有更大的空间去控制异质性,尤其是那些看不见的却不随着时间变动的异质性。
比如,我们想要研究学习时长与学生学习成绩之间的关系,数据包括整个学校5000名学生在100次考试期间的学习时长和这100次考试的最终成绩,还有其他一些可能看不见的影响因素:学生个人能力和学校的校风等。
现在,我们需要做一个面板数据的回归,除了学生学习时长外,解释变量还包括每个学生的个人能力(D1)和学校的校风(D2)。如果我们直接把他们按照i.D1和i.D2这种虚拟变量形式放进去进行回归,那带给我们最大的难处是运行时间长且会导致我们的电脑系统崩溃。通俗地讲,LSDV模型(Least dummy dependent variable)的回归会带来更长的运算时间和系统内存占用。
那如果不止这两个学生的个体特征,那我们就需要用更长的时间和占据更多的电脑内存去运算。在经济学研究中,我们经常需要控制公司层面、行业类别、省市县层面的固定效应,那如果直接按照添加虚拟变量的形式进行回归,我们会等到花儿都谢了也等不到结果。更重要的是,随着样本亮的增大N—∞,然后我们那些固定效应因素,比如i.D1和i.D2的维度也会增大((每个人一个dummy),这会导致“incidental parameters”问题(伴随参数问题)。而作为伴随参数的固定效应因素的出现,其他由极大似然函数估计的参数的一致性问题就受到挑战。

感受一下曾经做过的尝试,我们就知道对于大样本的微观数据,高维固定效应确实让我们的估计出现问题。样本量过大而导致的运行问题,如果还是用之前的那一套方式,那不管多好的电脑内存都出现了卡壳现象。

我们现在就引荐一个Frisch-Waugh-Lovell定理,他实际上是通过组内估计的方式解决了这个问题(固定效应模型)。第一步:通过减去组内的均值,我们可以把这些固定效应因素(即D1和D2)去除掉;第二部:通过用去掉了组内均值的的Y 对去掉了组内均值的X做线性回归,然后我们可以得到β;第三部:用第二部回归中的残差项μ对D1和D2做回归,我们可以得到α和γ。这就是我们经常说的固定效应模型——组内估计模型。
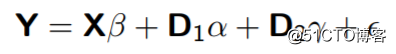

这个方法属于应用型的,里面的估计程序会涉及到矩阵运算,因此我们就不在这里具体讲解更复杂的过程。这一次,我们把相关操作命令放出来,这样你就会知道操作格式是怎样的,今后你只需要修改一下里面的参数就可以出结果。这个方法之所以能够节约运算时间和电脑内存,在于他采用的是通过iteration方式获得最终的结果。这个方法能够同时处理很多问题:多维固定效应、聚类稳健标准误、工具变量方法
GP方法得到的这个运算程序,下面的文字解释了为什么GP很具有吸引力。
GP algorithm that is commonly used to deal with multiple high-dimensional fixed effects. It uses the iteration and convergence implementation of Least Squared estimation instead of the explicit calculation of the inverse of matrices. Another valuable innovation is that it stores and retrieves each fixed effect as a column vector, which compresses the dimensions of fixed effects to ones. Hence in each iteration, the estimation of each fixed effect merely involves taking simple average of residuals by groups, after which the OLS regression is then run for other regressors along with the updated fixed effect vector as a variable. After convergence of the estimates, the fixed effects remain identifiable.
reghdfe y x1 x2 x3 x4 x5 x6, cluster(industry) absorb(year city industry) 通常的程序表达式,控制了年份、城市和行业固定效应,而且得到行业聚类标准误。
示例如下
set matsize 1000 //把Mata空间设置大一点,因为牵涉到矩阵运算
clear
sysuse auto //运用系统自带数据库
**最简单的一维固定效应
reghdfe price weight length, absorb(rep78) //把rep78这个固定效应控制起来
est store reg4 //可以把结果保存起来
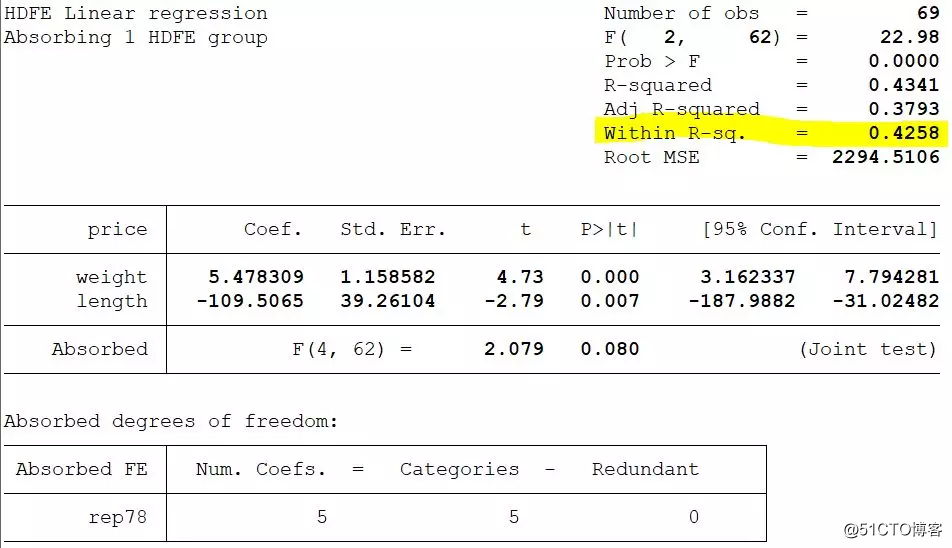
areg price weight length, absorb(rep78) //这个也可以控制一维固定效应
我们得到的结果与上面通过reghdfe得到的结果是一样的,这证明reghdfe是一个一般化的控制多重高维固定效应方法的方法。
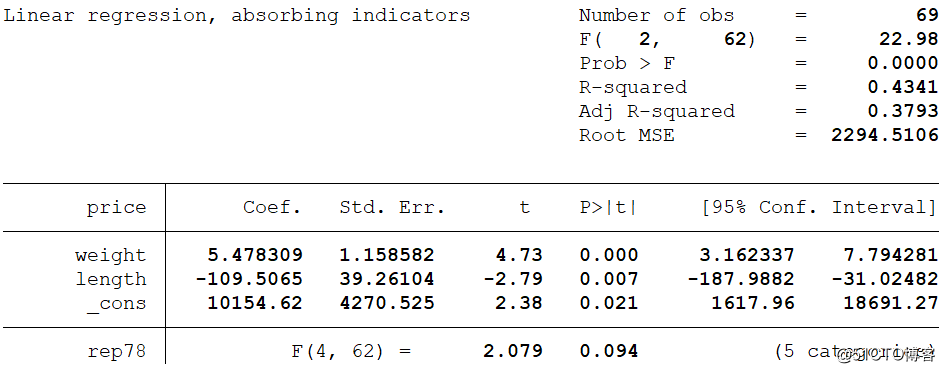
**一维固定效应但得出聚类标准误,以下两种表达式结果一样
reghdfe price weight length, absorb(rep78) vce(cluster rep78)
reghdfe price weight length, absorb(rep78) cluster(rep78)
**二维和三维固定效应
clear
webuse nlswork
reghdfe ln_w grade age ttl_exp tenure not_smsa south , absorb(idcode year)
reghdfe ln_w grade age ttl_exp tenure not_smsa south , absorb(idcode year occ)
**分类因变量存在交互行为
reghdfe ln_w i.grade#i.age ttl_exp tenure not_smsa , absorb(idcode occ)
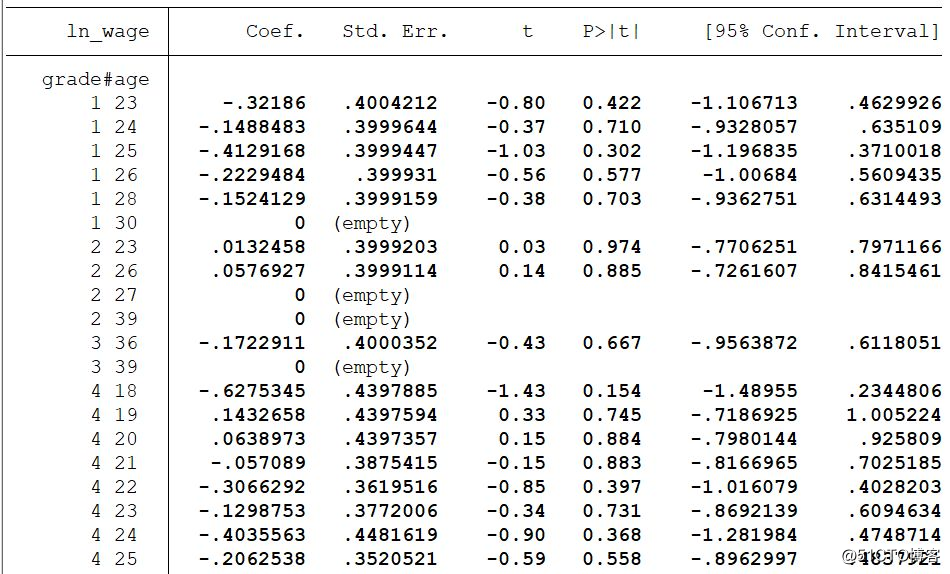
**固定效应存在交互行为
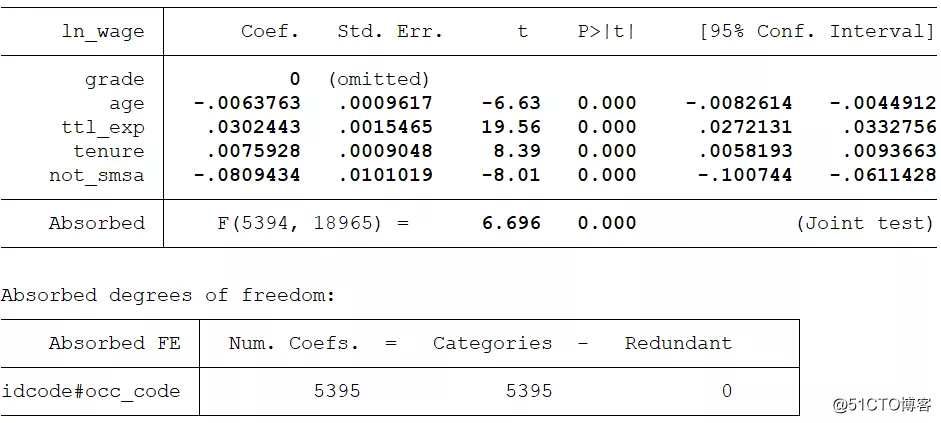
reghdfe ln_w grade age ttl_exp tenure not_smsa , absorb(idcode#occ)
**工具变量估计
clear
sysuse auto
reghdfe price weight (length=head), absorb(rep78)
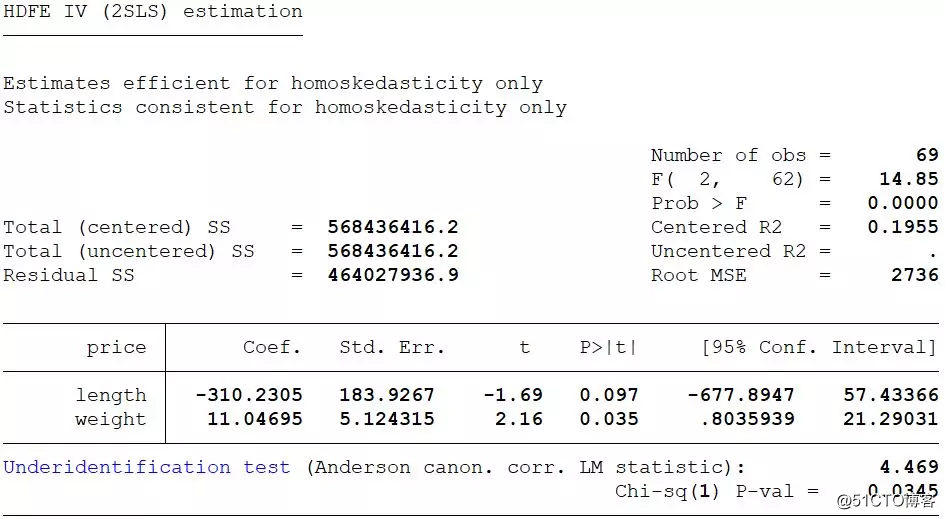

reghdfe price weight (length=head), absorb(rep78) ffirst //报告第一阶段回归
reghdfe price weight (length=head), absorb(rep78) ivsuite(ivregress) //用ivregress估计
reghdfe price weight (length=head), absorb(rep78 turn##c.price) //出现固定效应的交叉项
面板数据研究小组各种方法论丛的do file都放在咱们的社群,可以直接到社群提取使用。


- 一个JSON字符串和文件处理的命令行神器jq,windows和linux都可用
- 随机效应与固定效应&面板数据回归
- jenkins日志异常增大导致服务不可用的处理过程
- Linux下通过crontab及expect实现自动化处理 --亲测可用
- Android图片处理神器BitmapFun源码分析
- Spring Boot @ControllerAdvice 处理全局异常,返回固定格式Json
- 网络处理中TLV形式的不固定格式匹配
- 处理固定宽度下的长字符串绘制(Android)
- ORA-12520: TNS:监听程序无法为请求的服务器类型找到可用的处理程序
- 批处理技巧:循环固定目录的子目录,然后向每个子目录拷贝文件
- 用matlab来画表格(实例:处理光电效应及普朗克常数的实验报告)
- HDU 5875 N^2能过的大水题,可用单调栈,离线处理优化
- ffmpeg转码时对变帧率和固定帧率的处理
- 字符串处理:中英文混排固定长度截取问题
- sed----Linux下文本处理五大神器之一
- ADSL固定IP故障处理
- PHP实现对图片的反色处理功能【测试可用】
- 图像处理-线性滤波-1 基础(相关算子、卷积算子、边缘效应)
- CentOS7版本ifconfig命令不可用处理方法
- app微信支付宝支付后台的插件模式+回调通过spring广播处理后续业务(已亲测可用)