打开我的收藏夹 -- Python爬虫篇(2)

文章目录
前言
本来以为第二篇没了,就把写了一部分的移到第一篇末尾了,所以已收藏第一篇的小伙伴可以也可以再翻翻看,是关于ts视频拼接的。
没想到,是我的路子窄了。
今天我打开了我的关注栏,从里面手动爬取了所有有爬虫专栏的博客,分析他们博客中我没见过或者不会或者需要会的知识点,整理一波走起。
时间戳
来自我的老朋友“不温不火”的一篇博客,不知道他那篇写时间戳干嘛,但是我觉得这个不错,因为之前写翻译软件的时候有被时间戳卡住过。当时没太在意,因为有个大佬的教程很快帮我解决了问题,项目催的又紧,就直接交了,没再去研究这个。
既然“冤家路窄”,这次就把它办了。
先介绍一个时间戳转换的网站,不知道什么是时间戳的小伙伴可以自己去玩一玩,网站上也有简单介绍多种语言的时间戳处理办法:
时间戳转换网站
这里我们只讲Python。
爬虫中时间戳常见场景
时间戳作为一种简单加密手段,你说会出现在什么场景?
js加密就不说了,我说过的,js加密能渲染我就渲染,不能渲染的我就请人来。
大多数的网站的验证码url地址是加上了一个时间戳的
我们可以拿到验证码就很简单了, Python生成一个时间戳 + 部分url的值 = 验证码图片的url地址
时间戳如何转换
import time time.time()
将字符串的时间转为时间戳
import time str_time = "2021-4-01 17:16:10" # 将时间字符串转成时间数组 # 第一个参数就是时间字符串; 第二个就是转换的一些字符串 time_array = time.strptime(str_time, "%Y-%m-%d %H:%M:%S") # 转换为时间戳 time_stamp = time.mktime(time_arr 20000 ay) # 可以转化为int类型
字符串格式更改
"2021-4-01 17:16:10" 改为 "2021/4/01 17:16:10"
# 先转换为时间数组
import time
str_time = "2021-4-01 17:16:10"
time_array = time.strptime(str_time, "%Y-%m-%d %H:%M:%S")
other_way_time = time.strftime("%Y/%m/%d %H:%M:%S", time_array)
时间戳转换为指定日期
time_stamp = 1861700872
# 使用localtime()转换为时间数组,在格式化自己想要的格式
import time
time_array = time.localtime(time_stamp)
other_way_time = time.strftime("%Y-%m-%d %H:%M:%S", time_array)
import datetime
time_stamp = 1861700872
datetime_array = datetime.datetime.utcfromtimestamp(time_stamp)
other_way_time = datetime_array.strftime("%Y-%m-%d %H:%M:%S")
获取三天前的时间
import time
import datetime
# 先获得时间数组格式的日期
three_day_ago = (datetime.datetime.now() - datetime.timedelta(days=3))
# 转换为时间戳
time_stamp = int(time.mktime(three_day_ago.timetuple()))
# 转换为其他形式的字符串
other_way_time = three_day_ago.strftime("%Y-%m-%d %H:%M:%S")
毫秒级时间戳的 13位整数
int(time.time() * 1000)
就喜欢这种有经验的博主写的博客,一篇文章有多少内容在目录直接一目了然,不关注他难不成来关注我?
不温不火
url去重
昨天有个小伙伴问我怎么给url去重,我说用缓存会自动去重,那是个办法,今天又学到另一个办法,后期我其比对一下哪个方法会比较好。
from pybloom_live import ScalableBloomFilter # 用于URL去重的
#使用ScalableBloomFilter模块,对获取的URL进行去重处理 urlbloomfilter=ScalableBloomFilter(initial_capacity=100, error_rate=0.001, mode=ScalableBloomFilter.LARGE_SET_GROWTH)
···伪代码··· # 查重,从new中提取URL,并利用ScalableBloomFilter查重 if new["url"] not in urlbloomfilter: urlbloomfilter.add(new["url"]) #将爬取过的URL放入urlbloomfilter中 try: dosomething except Exception as e: error_url.add(new["url"]) #将未能正常爬取的URL存入到集合error_url中
看名字就知道这是一个布隆过滤器,bloomfilter:是一个通过多哈希函数映射到一张表的数据结构,能够快速的判断一个元素在一个集合内是否存在,具有很好的空间和时间效率。(典型例子,爬虫url去重)
讲真的,我不是很明白,布隆过滤器不是用来判断某个元素不存在吗?
它说存在那不一定存在,它说不存在那肯定是不存在的。
所以布隆过滤器什么时候能用来去重了?
后来,经过我多方查证,说是:很可能存在,所以就当做是存在,好的。毕竟那点误判率在大数据面前,不重要。
网页请求的背后流程
再怎么说,目前我还是个做后端的,所以对这个流程还是比较感兴趣的。
第一步:网络浏览器通过本地或者远程DNS,获取域名对应的IP地址 第二步:根据获取的IP地址与访问内容封装HTTP请求 第三步:浏览器发送HTTP请求 第四步:服务器接收信息,根据HTTP内容寻找web资源 第五步:服务器创建HTTP请求并封装 第六步:服务器将HTTP响应返回到客户端浏览器 第七步:浏览器解析,渲染服务器返回得资源,显示给用户
HTTP
HTTP请求过程 HTTP请求 HTTP响应 HTTP方法 HTTP头
HTTP请求的一般流程:

HTTP请求(Request):

HTTP响应(Response):
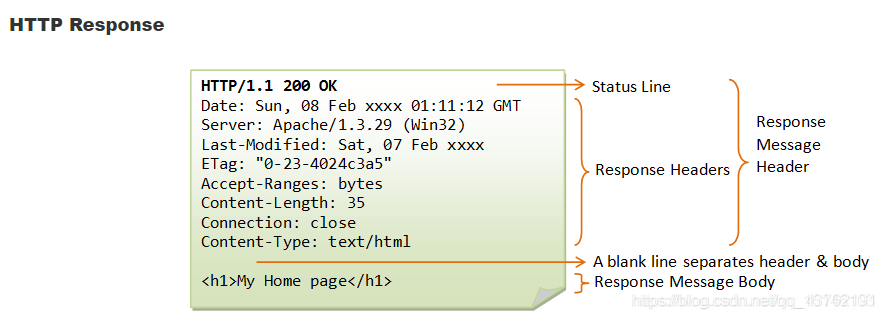
GET和POST:
GET 方法会将需要的参数附在 URL 的后面(是 URL 的一部分,即包含在 Request Line 中),以 “?” 分隔 URL和参数,多个参数之间用 “&” 连接。
豆瓣阅读的 URL 为
https://read.douban.com/?dcn=entry&dcs=book-nav&dcm=douban,其中包含了3个 key-value 参数。服务器会根据这些参数对用户所请求的资源进行筛选和过滤。尽管 RFC2616 没有对 URL 的长度进行限制,但通常服务器或浏览器都会限制 URL 的长度,如 Chrome 的 URL 长度不能超过 8KB。所以,如果要向服务器发送大量的数据 POST 是更好的选择。
另外,为了保证客户端和服务器之间的一致性,RFC2616 规定 URL 中只能使用 ASCII 中的可见字符, 所以如果 URL 中包含了中文等非 ASCII 字符, 就要对 URL 进行编码。通常采用的编码方式是百分号编码,即用 ‘%’ 分隔十六进制的 UTF-8 编码。
与 GET 方法不同,POST 方法是将数据放在消息体中,并用 Content-Type 标明采用的是何种格式。不过,RFC2616 并没有规定消息体的格式,实际上,开发者完全可以开发自己的传输格式,只要保证客户端和服务器之间能正确解析即可。另外,通过 POST 传递的数据,不会被浏览器缓存,所以 POST 方法要比 GET 方法的安全性高一点。因为这些原因,现行的网站大多都采用 POST 方法实现注册、登录等交互功能。
再了解Cookie
Cookie,有时也用其复数形式Cookies,指某些网站为了辨别用户身份、进行session跟踪而存储在用户本地终端上的数据(通常经过加密)。
由于HTTP是一种无状态的协议,服务器但从网络连接上不能知道客户身份。如果想要知道客户身份,这是就需要一张通行证,每人一个,无论谁访问都必须携带自己的通行证。这样服务器就能通过通行证来确定客户身份,这就是Cookie的工作原理。
客户端发送一个http请求到服务器端,如果是登录操作则携带我们的用户名和密码。 服务器端验证后发送一个http响应到客户端,其中包含Set-Cookie头部。 客户端发送一个http请求到服务器端,其中包含Cookie。 服务器端发送一个http响应到客户端。
看了一个连目录都不做的人,看着就难受,取关了。
字体加密的破解太高级了,等下次机缘吧。
Xpath小补充
今天群里有个小伙伴问我说Xpath怎么按行提取,说的意思不是很明白,我们估计是这两种情况:
一种是这样的:
es = el.xpath('./h1 |./h2 |./h3 |./h4 |./h5 |./h6 |./p |./p/mark |./p/span/span/span/span[2]//span/span[2]'
'|./p/strong |./p/em |./ul//li |./ol//li |./ul//li |./blockquote/p |./pre/code |./p/code '
'|./div/table/thead/tr//th |./div/table/tbody/tr//td |./hr |./p/img |./p/a')
要抓取很多种不同的标签,但是有要保持标签内容的原有排序,可以使用这种方式,将所有的标签用 “|” 的方式进行并列。
另一种情况是这样的:
(这是一个爬取票房数据库的示例,里面采用了二次Xpath的方式)
import requests
from lxml import etree
def get_html(url,times):
'''
这是一个用户获取网页源数据的函数
:param url: 目标网址
:param times: 递归执行次数
:return: 如果有,就返回网页数据,如果没有,返回None
'''
try:
res = requests.get(url = url,headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:87.0) Gecko/20100101 Firefox/87.0"
}) #带上请求头,获取数据
if res.status_code>=200 and res.status_code<=300: #两百打头的标识符标识网页可以被获取
return res
else:
return None
except Exception as e:
print(e) # 显示报错原因(可以考虑这里写入日志)
if times>0:
get_html(url,times-1) # 递归执行
def get_data(html_data, Xpath_path):
'''
这是一个从网页源数据中抓取所需数据的函数
:param html_data:网页源数据 (单条数据)
:param Xpath_path: Xpath寻址方法
:return: 存储结果的列表
'''
data = html_data.content
data = data.decode().replace("<!--", "").replace("-->", "") # 删除数据中的注释
tree = etree.HTML(data) # 创建element对象
el_list = tree.xpath(Xpath_path)
return el_list
res = get_html('http://58921.com/alltime?page=1',2)
print(res.content)
el_list = get_data(res,'//*[@id="content"]/div[3]//tr')
for el in el_list:
e = el.xpath('.//text() | .//@href')
print(e)
哇哦,刚刚发现一个爬虫博主有几百篇爬虫。。。
太多了吧,下次再说吧。。。


- python爬虫(20)使用真实浏览器打开网页的两种方法
- 【python爬虫】爬取知乎收藏夹内所有图片
- python爬虫 使用真实浏览器打开网页的两种方法总结
- 【python爬虫】爬取知乎收藏夹内所有问题名称地址保存至Mysql
- Python爬虫后保存为.html文件,在浏览器上打开时乱码
- python爬虫日志(13)selenium实现淘宝自动翻页以及在新的标签页中打开网页
- Python练手爬虫系列No.1 知乎福利收藏夹图片批量下载
- 批量爬取B站收藏夹封面 Python 爬虫 多线程
- [python爬虫] 爬取图片无法打开或已损坏的简单探讨
- Python Requests爬虫——获取一个收藏夹下所有答案的图片
- Python爬取知乎问题收藏夹 爬虫入门
- python之https爬虫出现 SSL: CERTIFICATE_VERIFY_FAILED (同时打开fiddler就会出现)
- Python爬虫: 抓取One网页上的每日一话和图
- python爬虫抓取链家租房数据
- 【Python3 爬虫】05_安装Scrapy
- python简单速成,一行代码写爬虫
- Python爬虫实现的根据分类爬取豆瓣电影信息功能示例
- python爬虫之selenium、phantomJs
- python3 [爬虫入门实战] 爬虫之使用selenium 爬取百度招聘内容并存mongodb
- 视频教程-爬虫微课5小时 Python学习路线-Python